Hadoop学习——Hadoop单机运行Grep实例(包含错误解决方法)
Posted 长弓同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop学习——Hadoop单机运行Grep实例(包含错误解决方法)相关的知识,希望对你有一定的参考价值。
1.概述
上一篇安装了Hadoop单机,所以今天打算先用Hadoop的mapreduce自带的Grep实例实践一下,顺带测试Hadoop是否成功安装。(不是水博客,有在努力填坑)
实践开始之前,我们需要了解一下Grep实例,Grep(缩写来自Globally search a Regular Expression and Print)是一种强大的文本搜索工具,它能使用特定模式匹配(包括正则表达式)搜索文本。在今天的实例当中我们将创建一个input文件夹,并利用这个工具从该文件夹中匹配到符合正则式“dfs[a-z.]+”的xml文件,自动创建output文件夹并将结果在该文件夹中输出。
那么让我们开始吧!
2.Grep实例实现
开始前需要检查Hadoop安装目录下是否存在output目录,如果存在则需要删除后再运行Grep实例,否则无法重复创建output导致运行失败。注意:每一次运行实例前都需要进行该操作。
首先我们需要在Hadoop安装目录下新建input目录,用来存放输入数据
先使用如下命令行,将路径移到Hadoop目录下:
cd /usr/local/hadoop接下来是非常重要的一步,我们需要登录我们的root账户(如果不知道root账户密码需要使用命令行“sudo passwd”来更改密码)
如果不进行这一步,在运行Grep实例的时候会报错说权限不够无法创建output目录(网上找了很多方法都解决不了这个问题,无论怎么给权限都会报错,所以我选择直接登录root账户来操作)
使用如下命令行并输入密码登录root账户:
su登录后,使用如下命令行来创建input目录:
mkdir input创建成功后(创建成功没有返回值),将“usr/local/hadoop/etc/hadoop”目录下的配置文件复制到input目录,命令如下:
cp ./etc/hadoop/*.xml ./input接下来执行如下命令运行Grep实例:
./bin/hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.4.jar grep ./input ./output 'dfs[a-z.]+'
实例运行中,出现如图,即为运行成功:
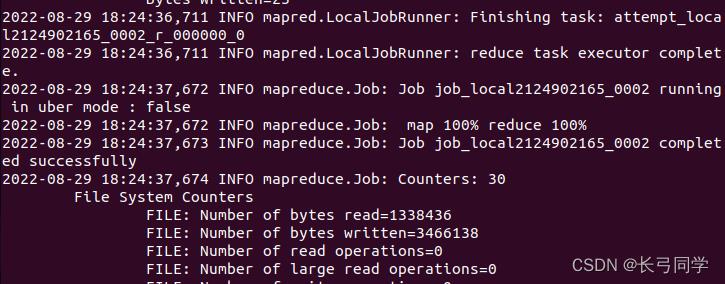
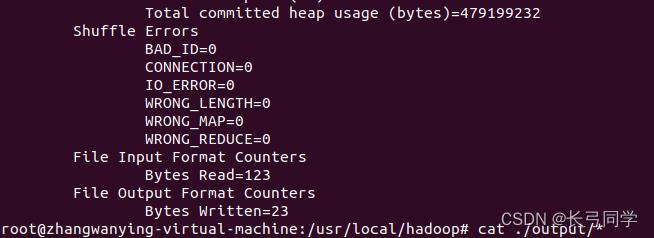
使用如下命令行,查看输出数据:
cat ./output/*可以得到如下类似结果:

结束。
以上是关于Hadoop学习——Hadoop单机运行Grep实例(包含错误解决方法)的主要内容,如果未能解决你的问题,请参考以下文章