Redis + NodeJS 实现一个能处理海量数据的异步任务队列系统
Posted androidstarjack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis + NodeJS 实现一个能处理海量数据的异步任务队列系统相关的知识,希望对你有一定的参考价值。
点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识一、引言
在最近的业务中,笔者接到了一个需要处理约十万条数据的需求。这些数据都以字符串的形式给到,并且处理它们的步骤是异步且耗时的(平均处理一条数据需要 25s 的时间)。如果以串行的方式实现,其耗时是相当长的:
总耗时时间 = 数据量 × 单条数据处理时间
T = N * t (N = 100,000; t = 25s)
总耗时时间 = 2,500,000 秒 ≈ 695 小时 ≈ 29 天
显然,我们不能简单地把数据一条一条地处理。那么有没有办法能够减少处理的时间呢?经过调研后发现,使用异步任务队列是个不错的办法。
下文将和大家分享用 Redis + NodeJS 实现一个能处理海量数据的异步任务队列系统的思路和方法,希望与大家一同交流。文章作者:jrain,腾讯应用研发工程师。
二、异步任务队列原理
我们可以把“处理单条数据”理解为一个异步任务,因此对这十万条数据的处理,就可以转化成有十万个异步任务等待进行。我们可以把这十万条数据塞到一个队列里面,让任务处理器自发地从队列里面去取得并完成。
任务处理器可以有多个,它们同时从队列里面把任务取走并处理。当任务队列为空,表示所有任务已经被认领完;当所有任务处理器完成任务,则表示所有任务已经被处理完。
其基本原理如下图所示:

首先来解决任务队列的问题。在这个需求中,任务队列里面的每一个任务,都包含了待处理的数据,数据以字符串的形式存在。为了方便起见,我们可以使用 Redis 的 List 数据格式来存放这些任务。
由于项目是基于 NodeJS 的,我们可以利用 PM2 的 Cluster 模式 [2] 来启动多个任务处理器,并行地处理任务。以一个 8 核的 CPU 为例,如果完全开启了多进程,其理论处理时间将提升 8 倍,从 29 天缩短到 3.6 天。
接下来,笔者将从实际编码的角度来讲解上述内容的实现过程。
三、使用 NodeJS 操作 Redis
异步任务队列使用 Redis 来实现,因此我们需要部署一个单独的 Redis 服务。在本地开发中为了快速完成 Redis 的安装,我使用了 Docker 的办法(默认机器已经安装了 Docker)。
1. Docker 拉取 Redis 镜像
docker pull redis:latest2. Docker 启动 Redis
docker run -itd --name redis-local -p 6379:6379 redis此时我们已经使用 Docker 启动了一个 Redis 服务,其对外的 IP 及端口为 127.0.0.1:6379。此外,我们还可以在本地安装一个名为 Another Redis DeskTop Manager[3] 的 Redis 可视化工具,来实时查看、修改 Redis 的内容。

在 NodeJS 中,我们可以使用 node-redis[4] 来操作 Redis。新建一个 mqclient.ts 文件并写入如下内容:
import * as Redis from 'redis'const client = Redis.createClient( host: '127.0.0.1', port: 6379)export default clientRedis 本质上是一个数据库,而我们对数据库的操作无非就是增删改查。node-redis 支持 Redis 的所有交互操作方式,但是操作结果默认是以回调函数的形式返回。
为了能够使用 async/await,我们可以新建一个 utils.ts 文件,把 node-redis 操作 Redis 的各种操作都封装成 Promise 的形式,方便我们后续使用。
import client from './mqClient'
// 获取 Redis 中某个 key 的内容
export const getRedisValue = (key: string): Promise<string | null> => new Promise(resolve => client.get(key, (err, reply) => resolve(reply)))
// 设置 Redis 中某个 key 的内容
export const setRedisValue = (key: string, value: string) => new Promise(resolve => client.set(key, value, resolve))
// 删除 Redis 中某个 key 及其内容
export const delRedisKey = (key: string) => new Promise(resolve => client.del(key, resolve))除此之外,还能在 utils.ts 中放置其他常用的工具方法,以实现代码的复用、保证代码的整洁。
为了在 Redis 中创建任务队列,我们可以单独写一个 createTasks.ts 的脚本,用于往队列中塞入自定义的任务。
import TASK_NAME, TASK_AMOUNT, setRedisValue, delRedisKey from './utils'
import client from './mqClient'
client.on('ready', async () =>
await delRedisKey(TASK_NAME)
for (let i = TASK_AMOUNT; i > 0 ; i--)
client.lpush(TASK_NAME, `task-$i`)
client.lrange(TASK_NAME, 0, TASK_AMOUNT, async (err, reply) =>
if (err)
console.error(err)
return
console.log(reply)
process.exit()
)
)在这段脚本中,我们从 utils.ts 中获取了各个 Redis 操作的方法,以及任务的名称 TASK_NAME (此处为 local_tasks)和任务的总数 TASK_AMOUNT(此处为 20 个)。
通过 LPUSH 方法往 TASK_NAME 的 List 当中塞入内容为 task-1 到 task-20 的任务,如图所示:


四、异步任务处理
首先新建一个 index.ts 文件,作为整个异步任务队列处理系统的入口文件。
import taskHandler from './tasksHandler'
import client from './mqClient'
client.on('connect', () =>
console.log('Redis is connected!')
)
client.on('ready', async () =>
console.log('Redis is ready!')
await taskHandler()
)
client.on('error', (e) =>
console.log('Redis error! ' + e)
)在运行该文件时,会自动连接 Redis,并且在 ready 状态时执行任务处理器 taskHandler()。
在上一节的操作中,我们往任务队列里面添加了 20 个任务,每个任务都是形如 task-n 的字符串。为了验证异步任务的实现,我们可以在任务处理器 taskHandler.ts 中写一段 demo 函数,来模拟真正的异步任务:
function handleTask(task: string)
return new Promise((resolve) =>
setTimeout(async () =>
console.log(`Handling task: $task...`)
resolve()
, 2000)
)
上面这个 handleTask() 函数,将会在执行的 2 秒后打印出当前任务的内容,并返回一个 Promise,很好地模拟了异步函数的实现方式。接下来我们将会围绕这个函数,来处理队列中的任务。
其实到了这一步为止,整个异步任务队列处理系统已经基本完成了,只需要在 taskHandler.ts 中补充一点点代码即可:
import popTask from './utils'
import client from './mqClient'
function handleTask(task: string) /* ... */
export default async function tasksHandler()
// 从队列中取出一个任务
const task = await popTask()
// 处理任务
await handleTask(task)
// 递归运行
await tasksHandler()
最后,我们使用 PM2 启动 4 个进程,来试着跑一下整个项目:
pm2 start ./dist/index.js -i 4 && pm2 logs

可以看到,4 个任务处理器分别处理完了队列中的所有任务,相互之前互不影响。
事到如今已经大功告成了吗?未必。为了测试我们的这套系统到底提升了多少的效率,还需要统计完成队列里面所有任务的总耗时。
五、统计任务完成耗时
要统计任务完成的耗时,只需要实现下列的公式即可:
总耗时 = 最后一个任务的完成时间 - 首个任务被取得的时间
首先来解决“获取首个任务被取得的时间”这个问题。
由于我们是通过 PM2 的 Cluster 模式来启动应用的,且从 Redis 队列中读取任务是个异步操作,因此在多进程运行的情况下无法直接保证从队列中读取任务的先后顺序,必须通过一个额外的标记来判断。其原理如下图:
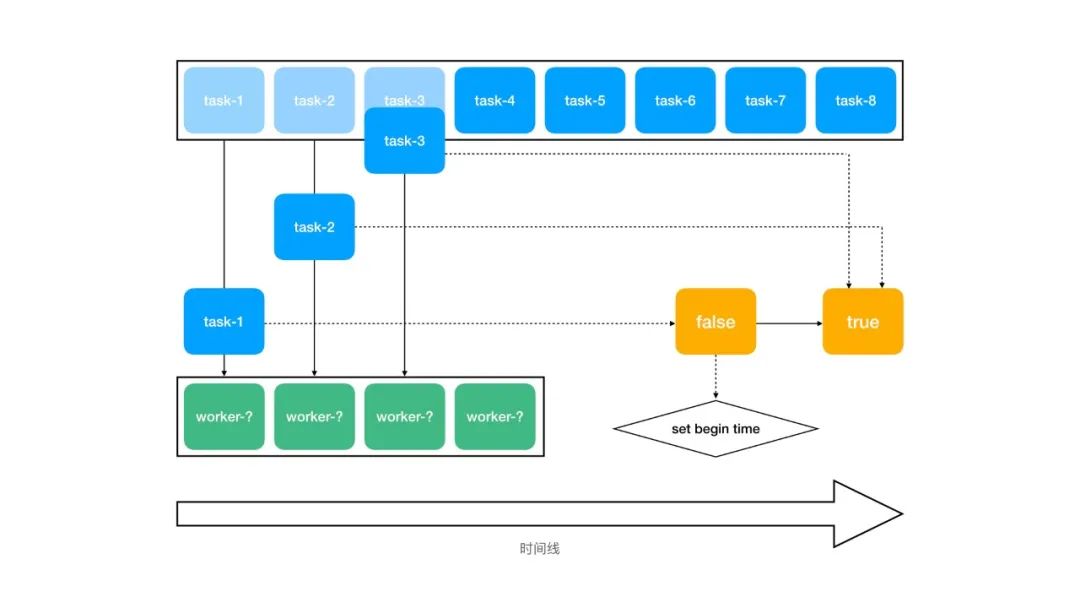
如图所示,绿色的 worker 由于无法保证运行的先后顺序,所以编号用问号来表示。
当第一个任务被取得时,把黄色的标记值从 false 设置成 true。当且仅当黄色的标记值为 false 时才会设置时间。这样一来,当其他任务被取得时,由于黄色的标记值已经是 true 了,因此无法设置时间,所以我们便能得到首个任务被取得的时间。
在本文的例子中,黄色的标记值和首个任务被取得的时间也被存放在 Redis 中,分别被命名为 local_tasks_SET_FIRST 和 local_tasks_BEGIN_TIME。
原理已经弄懂,但是在实践中还有一个地方值得注意。我们知道,从 Redis 中读写数据也是一个异步操作。由于我们有多个 worker 但只有一个 Redis,那么在读取黄色标记值的时候很可能会出现“冲突”的问题。
举个例子,当 worker-1 修改标记值为 true 的同时, worker-2 正好在读取标记值。由于时间的关系,可能 worker-2 读到的标记值依然是 false,那么这就冲突了。为了解决这个问题,我们可以使用 node-redlock[5] 这个工具来实现“锁”的操作。
顾名思义,“锁”的操作可以理解为当 worker-1 读取并修改标记值的时候,不允许其他 worker 读取该值,也就是把标记值给锁住了。当 worker-1 完成标记值的修改时会释放锁,此时才允许其他的 worker 去读取该标记值。
node-redlock 是 Redis 分布式锁 Redlock 算法的 javascript 实现,关于该算法的讲解可参考:https://redis.io/topics/distlock
值得注意的是,在 node-redlock 在使用的过程中,如果要锁一个已存在的 key,就必须为该 key 添加一个前缀 locks:,否则会报错。
回到 utils.ts,编写一个 setBeginTime() 的工具函数:
export const setBeginTime = async (redlock: Redlock) =>
// 读取标记值前先把它锁住
const lock = await redlock.lock(`lock:$TASK_NAME_SET_FIRST`, 1000)
const setFirst = await getRedisValue(`$TASK_NAME_SET_FIRST`)
// 当且仅当标记值不等于 true 时,才设置起始时间
if (setFirst !== 'true')
console.log(`$pm2tips Get the first task!`)
await setRedisValue(`$TASK_NAME_SET_FIRST`, 'true')
await setRedisValue(`$TASK_NAME_BEGIN_TIME`, `$new Date().getTime()`)
// 完成标记值的读写操作后,释放锁
await lock.unlock().catch(e => e)
然后把它添加到 taskHandler() 函数里面即可:
export default async function tasksHandler()
+ // 获取第一个任务被取得的时间
+ await setBeginTime(redlock)
// 从队列中取出一个任务
const task = await popTask()
// 处理任务
await handleTask(task)
// 递归运行
await tasksHandler()
接下来解决“最后一个任务的完成时间”这个问题。
类似上一个问题,由于任务执行的先后顺序无法保证,异步操作的完成时间也无法保证,因此我们也需要一个额外的标识来记录任务的完成情况。
在 Redis 中创建一个初始值为 0 的标识 local_tasks_CUR_INDEX,当 worker 完成一个任务就让标识加。
由于任务队列的初始长度是已知的(为 TASK_AMOUNT 常量,也写入了 Redis 的 local_tasks_TOTAL 中),因此当标识的值等于队列初始长度的值时,即可表明所有任务都已经完成。

如图所示,被完成的任务都会让黄色的标识加一,任何时候只要判断到标识的值等于队列的初始长度值,即可表明任务已经全部完成。
回到 taskHandler() 函数,加入下列内容:
export default async function tasksHandler()
+ // 获取标识值和队列初始长度
+ let curIndex = Number(await getRedisValue(`$TASK_NAME_CUR_INDEX`))
+ const taskAmount = Number(await getRedisValue(`$TASK_NAME_TOTAL`))
+ // 等待新任务
+ if (taskAmount === 0)
+ console.log(`$pm2tips Wating new tasks...`)
+ await sleep(2000)
+ await tasksHandler()
+ return
+
+ // 判断所有任务已经完成
+ if (curIndex === taskAmount)
+ const beginTime = await getRedisValue(`$TASK_NAME_BEGIN_TIME`)
+ // 获取总耗时
+ const cost = new Date().getTime() - Number(beginTime)
+ console.log(`$pm2tips All tasks were completed! Time cost: $costms. $beginTime`)
+ // 初始化 Redis 的一些标识值
+ await setRedisValue(`$TASK_NAME_TOTAL`, '0')
+ await setRedisValue(`$TASK_NAME_CUR_INDEX`, '0')
+ await setRedisValue(`$TASK_NAME_SET_FIRST`, 'false')
+ await delRedisKey(`$TASK_NAME_BEGIN_TIME`)
+ await sleep(2000)
+ await tasksHandler()
// 获取第一个任务被取得的时间
await setBeginTime(redlock)
// 从队列中取出一个任务
const task = await popTask()
// 处理任务
await handleTask(task)
+ // 任务完成后需要为标识位加一
+ try
+ const lock = await redlock.lock(`lock:$TASK_NAME_CUR_INDEX`, 1000)
+ curIndex = await getCurIndex()
+ await setCurIndex(curIndex + 1)
+ await lock.unlock().catch((e) => e)
+ catch (e)
+ console.log(e)
+
+ // recursion
+ await tasksHandler()
+
// 递归运行
await tasksHandler()
到这一步为止,我们已经解决了获取“最后一个任务的完成时间”的问题,再结合前面的首个任务被取得的时间,便能得出运行的总耗时。
最后来看一下实际的运行效果。我们循例往队列里面添加了 task-1 到 task-20 这 20 个任务,然后启动 4 个进程来跑:


运行状况良好。从运行结果来看,4 个进程处理 20 个平均耗时 2 秒的任务,只需要 10 秒的时间,完全符合设想。
六、结语
当面对海量的异步任务需要处理的时候,多进程 + 任务队列的方式是一个不错的解决方式。
本文通过探索 Redis + NodeJS 结合的方式,构造出了一个异步任务队列处理系统,能较好地完成最初方案的设想,但依然有很多问题需要改进。比如说当任务出错了应该怎么办,系统能否支持不同类型的任务,能否运行多个队列等等,都是值得思考的问题。如果读者朋友有更好的想法,欢迎留言和我交流!
参考资料:
[1] 项目仓库:
https://github.com/jrainlau/node-redis-missions-queue
[2] PM2 & Cluster 模式:
https://pm2.keymetrics.io/docs/usage/cluster-mode/
[3] Another Redis DeskTop Manager:
https://github.com/qishibo/AnotherRedisDesktopManager
[4] node-redis:
https://www.npmjs.com/package/redis
[5] node-redlock:
https://www.npmjs.com/package/redlock
写在最后的话
大家看完有什么不懂的可以在下方留言讨论,也可以私信问我一般看到后我都会回复的。最后觉得文章对你有帮助的话记得点个赞哦,点点关注不迷路
@终端研发部
每天都有新鲜的干货分享!
回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
用 Spring 的 BeanUtils 前,建议你先了解这几个坑!
lazy-mock ,一个生成后端模拟数据的懒人工具
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
字节跳动一面:i++ 是线程安全的吗?
一条 SQL 引发的事故,同事直接被开除!!
太扎心!排查阿里云 ECS 的 CPU 居然达100%
一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)
相信自己,没有做不到的,只有想不到的在这里获得的不仅仅是技术!
点“在看”支持小于哥呀,谢谢啦以上是关于Redis + NodeJS 实现一个能处理海量数据的异步任务队列系统的主要内容,如果未能解决你的问题,请参考以下文章