Keras CIFAR-10分类 SVM 分类器篇
Posted 风信子的猫Redamancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras CIFAR-10分类 SVM 分类器篇相关的知识,希望对你有一定的参考价值。
Keras CIFAR-10分类(SVM 分类器)
文章目录
除了用pytorch可以进行图像分类之外,我们也可以利用tensorflow来进行图像分类,其中利用tensorflow的后端keras更是尤为简单,接下来我们就利用keras对CIFAR10数据集进行分类。
keras介绍

keras是python深度学习中常用的一个学习框架,它有着极其强大的功能,基本能用于常用的各个模型。
keras具有的特性
1、相同的代码可以在cpu和gpu上切换;
2、在模型定义上,可以用函数式API,也可以用Sequential类;
3、支持任意网络架构,如多输入多输出;
4、能够使用卷积网络、循环网络及其组合。
keras与后端引擎
Keras 是一个模型级的库,在开发中只用做高层次的操作,不处于张量计算,微积分计算等低级操作。但是keras最终处理数据时数据都是以张量形式呈现,不处理张量操作的keras是如何解决张量运算的呢?
keras依赖于专门处理张量的后端引擎,关于张量运算方面都是通过后端引擎完成的。这也就是为什么下载keras时需要下载TensorFlow 或者Theano的原因。而TensorFlow 、Theano、以及CNTK都属于处理数值张量的后端引擎。

keras设计原则
- 用户友好:Keras是为人类而不是天顶星人设计的API。用户的使用体验始终是我们考虑的首要和中心内容。Keras遵循减少认知困难的最佳实践:Keras提供一致而简洁的API, 能够极大减少一般应用下用户的工作量,同时,Keras提供清晰和具有实践意义的bug反馈。
- 模块性:模型可理解为一个层的序列或数据的运算图,完全可配置的模块可以用最少的代价自由组合在一起。具体而言,网络层、损失函数、优化器、初始化策略、激活函数、正则化方法都是独立的模块,你可以使用它们来构建自己的模型。
- 易扩展性:添加新模块超级容易,只需要仿照现有的模块编写新的类或函数即可。创建新模块的便利性使得Keras更适合于先进的研究工作。
- 与Python协作:Keras没有单独的模型配置文件类型(作为对比,caffe有),模型由python代码描述,使其更紧凑和更易debug,并提供了扩展的便利性。
安装keras
安装也是很简单的,我们直接安装keras即可,如果需要tensorflow,就还需要安装tensorflow
pip install keras
导入库
首先可以导入需要的库,这里面一次性导入需要的库
import keras
from keras.models import Sequential
from keras.datasets import cifar10
from keras.layers import Conv2D, MaxPooling2D, Dropout, Flatten, Dense, Activation
from keras.layers import BatchNormalization
from keras.layers import MaxPool2D
from keras.optimizers import adam_v2
from keras.utils.vis_utils import plot_model
from keras.utils.np_utils import to_categorical
from keras.callbacks import ModelCheckpoint
import matplotlib.pyplot as plt
import numpy as np
import os
import shutil
import matplotlib
matplotlib.style.use('ggplot')
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
控制GPU显存(可选)
这个是tensorflow来控制选择的GPU,因为存在多卡的时候可以指定GPU,其次还可以控制GPU的显存
这段语句就是动态显存,动态分配显存
config.gpu_options.allow_growth = True
这段语句就是说明,我们使用的最大显存不能超过50%
config.gpu_options.per_process_gpu_memory_fraction = 0.5
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # 忽略低级别的警告
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
# The GPU id to use, usually either "0" or "1"
os.environ["CUDA_VISIBLE_DEVICES"]="0"
config = tf.compat.v1.ConfigProto()
# config.gpu_options.per_process_gpu_memory_fraction = 0.5
config.gpu_options.allow_growth = True
session = tf.compat.v1.Session(config=config)
加载 CIFAR-10 数据集
CIFAR-10 是由 Hinton 的学生 Alex Krizhevsky 和 Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含 10 个类别的 RGB 彩色图 片:飞机( arplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。图片的尺寸为 32×32 ,数据集中一共有 50000 张训练圄片和 10000 张测试图片。
与 MNIST 数据集中目比, CIFAR-10 具有以下不同点:
- CIFAR-10 是 3 通道的彩色 RGB 图像,而 MNIST 是灰度图像。
- CIFAR-10 的图片尺寸为 32×32, 而 MNIST 的图片尺寸为 28×28,比 MNIST 稍大。
- 相比于手写字符, CIFAR-10 含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、 特征都不尽相同,这为识别带来很大困难。

num_classes = 10 # 有多少个类别
(x_train, y_train), (x_val, y_val) = cifar10.load_data()
print("训练集的维度大小:",x_train.shape)
print("验证集的维度大小:",x_val.shape)
训练集的维度大小: (50000, 32, 32, 3)
验证集的维度大小: (10000, 32, 32, 3)
可视化数据
class_names = ['airplane','automobile','bird','cat','deer',
'dog','frog','horse','ship','truck']
fig = plt.figure(figsize=(20,5))
for i in range(num_classes):
ax = fig.add_subplot(2, 5, 1 + i, xticks=[], yticks=[])
idx = np.where(y_train[:]==i)[0] # 取得类别样本
features_idx = x_train[idx,::] # 取得图片
img_num = np.random.randint(features_idx.shape[0]) # 随机挑选图片
im = features_idx[img_num,::]
ax.set_title(class_names[i])
plt.imshow(im)
plt.show()

数据预处理
x_train = x_train.astype('float32')/255
x_val = x_val.astype('float32')/255
x_train = np.reshape(x_train, (x_train.shape[0], -1)).astype('float16')
x_val = np.reshape(x_val, (x_val.shape[0], -1)).astype('float16')
# 将向量转化为二分类矩阵,也就是one-hot编码
y_train = to_categorical(y_train, num_classes)
y_val = to_categorical(y_val, num_classes)
output_dir = './output' # 输出目录
if os.path.exists(output_dir) is False:
os.mkdir(output_dir)
# shutil.rmtree(output_dir)
# print('%s文件夹已存在,但是没关系,我们删掉了' % output_dir)
# os.mkdir(output_dir)
print('%s已创建' % output_dir)
print('%s文件夹已存在' % output_dir)
model_name = 'svm'
./output文件夹已存在
SVM 支持向量机
SVM,中文名叫支持向量机。支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane) 。
在深度学习出现以前,它是数据挖掘的宠儿,SVM被认为机器学习近十几年最成功,表现最好的算法;SVM具有十分完整的数据理论证明,但同时理论也相当复杂。SVM既可以用于回归也可以用于分类问题。
SVM使用铰链损失函数(hinge loss)计算经验风险(empirical risk)并在求解系统中加入了正则化项以优化结构风险(structural risk),是一个具有稀疏性和稳健性的分类器 。SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一。
from keras import regularizers
from keras import initializers
def SVM(classes = 10, input_shape = (3*32*32,), weight_decay=5e-4):
"""
create a simple linear SVM classifier.
:param classes: output num classes
:param input_shape: input image shape
:return:
"""
model = Sequential()
model.add(Dense(classes,
input_shape=input_shape,
kernel_regularizer=regularizers.l2(weight_decay),
kernel_initializer=initializers.random_normal(stddev=1e-3),
use_bias=True,
))
return model
model = SVM()
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 30730
=================================================================
Total params: 30,730
Trainable params: 30,730
Non-trainable params: 0
_________________________________________________________________
model_img = output_dir + '/cifar10_%s.png'%(model_name) # 模型结构图保存路径
plot_model(model, to_file=model_img, show_shapes=True) # 模型结构保存为一张图片
print('%s已保存' % model_img)
./output/cifar10_svm.png已保存
这就是简单的可视化我们的模型,会保存在我们的output文件夹下

开始训练模型
首先我们可以设置我们的迭代次数和batch_size
epochs = 20 # 迭代次数
batch_size = 64 # 批大小
这一部分是设置在训练的时候的一些参数
- 首先保存最好的模型,先定义我们的model path
- 设置save_best_only=True,也就是代表只保存一遍
- monitor='val_loss’代表的是监视val_loss,着重观察val_loss,只选取最小的val_loss的模型进行保存,当然这个我们也可以换成val_acc也是可以的
checkpoint = ModelCheckpoint(output_dir + '/best_%s_simple.h5'%model_name, # model filename
monitor='val_loss', # quantity to monitor
verbose=0, # verbosity - 0 or 1
save_best_only= True, # The latest best model will not be overwritten
mode='auto') # The decision to overwrite model is made
# automatically depending on the quantity to monitor
接下来我们就可以定义我们的优化器和损失函数了,keras很简单,并且定义我们需要计算的metrics为准确率即可
adam = adam_v2.Adam(lr = 0.0001)
model.compile(loss = 'categorical_crossentropy', optimizer = adam, metrics = ['accuracy'])
最后我们使用内置的fit函数,并且加上我们所需要的超参数,就可以完成我们的训练了。
history = model.fit(x_train,y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_val,y_val),
shuffle=True,
callbacks=[checkpoint])
Epoch 1/20
782/782 [==============================] - 8s 8ms/step - loss: 8.0634 - accuracy: 0.1136 - val_loss: 8.0639 - val_accuracy: 0.1126
782/782 [==============================] - 5s 7ms/step - loss: 8.0665 - accuracy: 0.1141 - val_loss: 8.0639 - val_accuracy: 0.1120
Epoch 3/20
782/782 [==============================] - 4s 5ms/step - loss: 8.0671 - accuracy: 0.1137 - val_loss: 8.0623 - val_accuracy: 0.1114
Epoch 4/20
782/782 [==============================] - 3s 4ms/step - loss: 8.0681 - accuracy: 0.1127 - val_loss: 8.0591 - val_accuracy: 0.1106
Epoch 5/20
782/782 [==============================] - 3s 4ms/step - loss: 8.0697 - accuracy: 0.1111 - val_loss: 8.0591 - val_accuracy: 0.1094
Epoch 6/20
782/782 [==============================] - 3s 4ms/step - loss: 8.0742 - accuracy: 0.1090 - val_loss: 8.0736 - val_accuracy: 0.1072
Epoch 7/20
782/782 [==============================] - 3s 4ms/step - loss: 8.0807 - accuracy: 0.1059 - val_loss: 8.0994 - val_accuracy: 0.1048
Epoch 8/20
782/782 [==============================] - 4s 5ms/step - loss: 8.0562 - accuracy: 0.1025 - val_loss: 7.9446 - val_accuracy: 0.1014
Epoch 9/20
782/782 [==============================] - 3s 4ms/step - loss: 7.7983 - accuracy: 0.0985 - val_loss: 7.4949 - val_accuracy: 0.0984
Epoch 10/20
782/782 [==============================] - 4s 5ms/step - loss: 7.8079 - accuracy: 0.0948 - val_loss: 7.9527 - val_accuracy: 0.0957
Epoch 11/20
782/782 [==============================] - 3s 4ms/step - loss: 8.3159 - accuracy: 0.1033 - val_loss: 8.5395 - val_accuracy: 0.1062
Epoch 12/20
782/782 [==============================] - 4s 5ms/step - loss: 8.5670 - accuracy: 0.1052 - val_loss: 8.5492 - val_accuracy: 0.1060
Epoch 13/20
782/782 [==============================] - 4s 5ms/step - loss: 8.5988 - accuracy: 0.1051 - val_loss: 8.6008 - val_accuracy: 0.1062
Epoch 14/20
782/782 [==============================] - 4s 5ms/step - loss: 8.6527 - accuracy: 0.1049 - val_loss: 8.6523 - val_accuracy: 0.1056
Epoch 15/20
782/782 [==============================] - 3s 4ms/step - loss: 8.7229 - accuracy: 0.1046 - val_loss: 8.7490 - val_accuracy: 0.1050
Epoch 16/20
782/782 [==============================] - 3s 4ms/step - loss: 8.8767 - accuracy: 0.1044 - val_loss: 8.9457 - val_accuracy: 0.1049
Epoch 17/20
782/782 [==============================] - 4s 5ms/step - loss: 9.0923 - accuracy: 0.1040 - val_loss: 9.3212 - val_accuracy: 0.1046
Epoch 18/20
782/782 [==============================] - 4s 5ms/step - loss: 9.3882 - accuracy: 0.1037 - val_loss: 9.6935 - val_accuracy: 0.1039
Epoch 19/20
782/782 [==============================] - 4s 4ms/step - loss: 9.8063 - accuracy: 0.1029 - val_loss: 10.1335 - val_accuracy: 0.1030
Epoch 20/20
782/782 [==============================] - 4s 5ms/step - loss: 9.3070 - accuracy: 0.1019 - val_loss: 8.7458 - val_accuracy: 0.1000
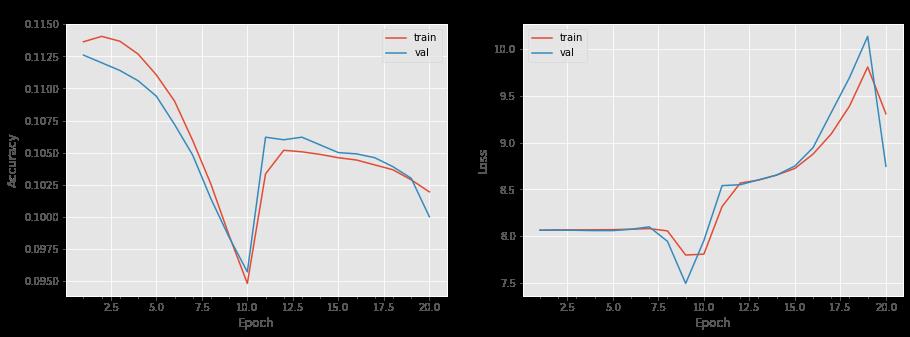
可视化准确率、损失函数
def plot_model_history(model_history):
fig, axs = plt.subplots(1,2,figsize=(15,5))
# summarize history for accuracy
axs[0].plot(range(1,len(model_history.history['accuracy'])+1),model_history.history['accuracy'])
axs[0].plot(range(1,len(model_history.history['val_accuracy'])+1),model_history.history['val_accuracy'])
axs[0].set_title('Model Accuracy')
axs[0].set_ylabel('Accuracy')
axs[0].set_xlabel('Epoch')
axs[0].set_xticks(np.arange(1,len(model_history.history['accuracy'])+1),len(model_history.history['accuracy'])/10)
axs[0].legend(['train', 'val'], loc='best')
# summarize history for loss
axs[1].plot(range(1,len(model_history.history['loss'])+1),model_history.history['loss'])
axs[1].plot(range(1,len(model_history.history['val_loss'])+1),model_history.history['val_loss'])
axs[1].set_title('Model Loss')
axs[1].set_ylabel('Loss')
axs[1].set_xlabel('Epoch')
axs[1].set_xticks(np.arange(1,len(model_history.history['loss'])+1),len(model_history.history['loss'])/10)
axs[1].legend(['train', 'val'], loc='best')
plt.show()
plot_model_history(history)
保存模型
model_path = output_dir + '/keras_cifar10_%s_model.h5'%model_name
model.save(model_path)
print('%s已保存' % model_path)
./output/keras_cifar10_svm_model.h5已保存
预测结果
res = model.evaluate(x_val,y_val)
print(':2f%'.format(res[1]*100))
313/313 [==============================] - 1s 3ms/step - loss: 8.7457 - accuracy: 0.1000
10.000000%
以上是关于Keras CIFAR-10分类 SVM 分类器篇的主要内容,如果未能解决你的问题,请参考以下文章