在可视化大屏中轻松完成机器学习建模和调参应用实例
Posted CSDN云计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在可视化大屏中轻松完成机器学习建模和调参应用实例相关的知识,希望对你有一定的参考价值。

Streamlit 是一个开源 Python 库,可帮助开发人员为其系统创建交互式图形用户界面。它专为机器学习和数据科学家团队设计。使用 Streamlit,我们可以快速创建交互式 Web 应用程序并进行部署。前端工作对数据科学家来说并不重要,他们只想要一个小的交互场所供用户完成工作,且不必担心无法进行建模算法和参数。Streamlit 帮助数据科学家更加便捷地向其他用户提供 ML 模型并在 Web 应用程序中查看预测。

Streamlit 入门
使用 pip 命令安装 Streamlit,可以在Streamlit的官方文档中找到有关安装的更多信息。

使用 Python 编辑器并创建一个新的 Python 文件。使用以下命令导入 Streamlit 库并设置页面布局。
import streamlit as st
st.set_page_config(page_title='机器学习超参数调整应用程序示例',
layout='wide') #设置页面布局,页面展开到全宽要在本地系统中运行 Streamlit 应用程序,需要在控制台中运行以下命令以确保您位于具有上述文件的同一目录中。
$ streamlit run your_app_name.py在终端中看到一个链接;打开该链接将重定向到 Streamlit 应用程序。更改源文件时,在左上角看到重新运行选项。单击它,它会根据新代码更新应用程序。
现在我们知道如何运行 Streamlit,我们使用它来建立一个分类模型。

分类模型的预处理步骤
首先,导入必要的库来帮助构建随机森林分类模型。
import streamlit as st # 导入streamlit以构建应用程序
import numpy as np # 进行数组操作
import pandas as pd # 加载数据集并执行预处理步骤
# scikit learn构建随机森林模型
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score,classification_report,plot_confusion_matrix
import plotly.graph_objects as go # 绘制可视化首先使用 pandas 将 CSV 文件加载到 pandas DataFrame 中,并将数据集的一些行显示到我们的应用程序中。不要忘记将 CSV 文件重命名为Dataset。该数据集来自kaggle的心脏疾病分类数据集,不幸的是该数据集已被删除,如果需要数据集,请联系原文作者云朵君获取。
下面是该数据集每个字段的介绍。可稍作了解即可。
age:年龄
sex 性别 1=male 0=female
cp 胸痛类型;4种取值情况
1:典型心绞痛
2:非典型心绞痛
3:非心绞痛
4:无症状
trestbps 静息血压
chol 血清胆固醇
fbs 空腹血糖 >120mg/dl :1=true;0=false
restecg 静息心电图(值0,1,2)
thalach 达到的最大心率
exang 运动诱发的心绞痛(1=yes;0=no)
oldpeak 相对于休息的运动引起的ST值(ST值与心电图上的位置有关)
slope 运动高峰ST段的坡度
1:upsloping向上倾斜
2:flat持平
3:downsloping向下倾斜
ca The number of major vessels(血管) (0-3)
thal A blood disorder called thalassemia ,一种叫做地中海贫血的血液疾病(3 = normal;6 = fixed defect;;7 = reversable defect)
target 生病没有(0=no;1=yes)
st.write("""
# 机器学习超参数调整应用程序示例
### **(心脏疾病分类模型)**""")
df = pd.read_csv('dataset.csv')#加载数据到pandas数据框
#显示数据集
st.subheader('Dataset')
st.markdown('**心脏疾病** 数据集为例。')
st.write(df.head(5)) #显示数据集的前五行。write 函数将输入字符串写入您的应用程序;您可以使用多个“#”创建不同的标题,并使用 **()** 以粗体书写单词。在浏览器中重新运行 Streamlit;您应该会看到您的网络应用程序,如下图所示。
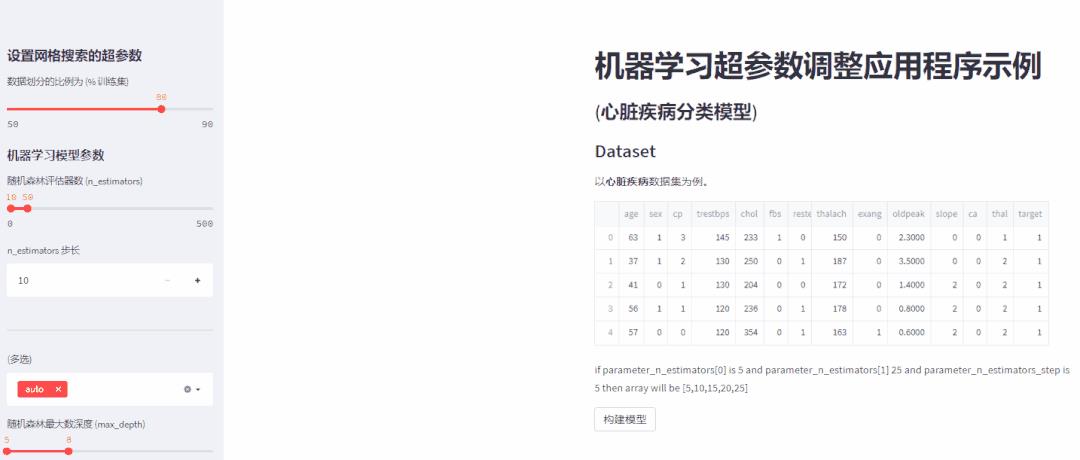
创建一个触发构建函数的按钮,它将根据给定的输入超参数构建分类模型。
if st.button('构建模型'):
#一些处理步骤
dataset = pd.get_dummies(df,
columns=['sex', 'cp', 'fbs', 'restecg',
'exang', 'slope', 'ca', 'thal'])
model(dataset)当构建模型有效时(意味着单击该按钮),它将执行一些基本的预处理步骤,例如为数据集的分类数据创建虚拟列。之后将调用模型函数。
def model(df):
Y = dataset['target']
X = dataset.drop(['target'], axis = 1)
# 数据集的划分,其中split_size在后面定义
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=split_size)
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)此函数将pandas DataFrame数据框作为输入。Y是目标变量,它有 0(没有心脏病)和 1(有心脏病)二分类。X 由数据框中的所有自变量组成。我们将数据分成训练和测试两部分。在这里,用户将定义测试大小,该大小存储在 split_size 中。在下一行中,我们初始化了标准缩放器和训练数据;测试数据在训练数据所训练的缩放器(sc)上进行缩放,以确保没有数据泄漏。

创建侧边栏
我们制作一个侧边栏,它将从用户那里获取随机森林分类器超参数的值。下面的代码将在函数之外编写。
st.sidebar.header('设置网格搜索的超参数')
# 在侧边栏中创建标题
split_size = st.sidebar.slider(
'数据划分的比例为 (% 训练集)', 50, 90, 80, 5)要将 Streamlit 组件附加到侧边栏中,我们必须在代码中使用侧边栏。Streamlit 中的滑块可以渲染范围或单个整数。上面代码中,50是最小值,90是最大值,80是默认值,5是步长值。
st.sidebar.subheader('机器学习模型参数')
parameter_n_estimators = st.sidebar.slider(
'随机森林评估器数 (n_estimators)',
0, 500, (10,50), 50)
parameter_n_estimators_step = st.sidebar.number_input('n_estimators 的步长', 10)n_estimator 是指随机森林中树的数量。使用滑块获得可以在 gridsearchcv 中使用的树数量的范围,默认范围为(10,50)。
st.sidebar.write('---')
parameter_max_features =st.sidebar.multiselect(
'(你可以选择多个选项)',
['auto', 'sqrt', 'log2'],
['auto'])在上面的行中,multiselect 允许来自给定选项的多个值,max_feature 超参数的默认值是 auto。
parameter_max_depth = st.sidebar.slider(
'Maximum depth', 5, 15, (5,8), 2)
parameter_max_depth_step=st.sidebar.number_input(
'max_depth 的步长', 1,3)max_depth 是随机森林中根到树的叶节点之间可能的最长路径。这里使用滑块获得了一系列 max_depth。
st.sidebar.write('---')
parameter_criterion = st.sidebar.selectbox('criterion', ('gini', 'entropy'))上面的代码给出了节点分裂的标准之一。
下面一行还返回一个介于 2 到 10 之间的值,用于交叉验证中的folds数。
st.sidebar.write('---')
parameter_cross_validation=st.sidebar.slider(
'交叉验证拆分的次数', 2, 10)另外定义一些其他的超参数。
st.sidebar.subheader('其他参数')
parameter_random_state = st.sidebar.slider(
'随机数种子', 0, 1000, 42, 1)
parameter_bootstrap = st.sidebar.select_slider(
'构建树时的Bootstrap示例 (bootstrap)',
options=[True, False])
parameter_n_jobs = st.sidebar.select_slider(
'并行运行的线程数 (n_jobs)',
options=[1, -1])estimators 和 max_depth为必须参数,用其创建一个 numpy 数组。可以用下面的代码行来实现。定义 param_grid (不用于网格搜索的参数值字典)。
n_estimators_range = np.arange(parameter_n_estimators[0], parameter_n_estimators[1]+parameter_n_estimators_step, parameter_n_estimators_step)
"""
if parameter_n_estimators[0] is 5
and parameter_n_estimators[1] 25
and parameter_n_estimators_step is 5
then array will be [5,10,15,20,25]
"""
max_depth_range =np.arange(parameter_max_depth[0],
parameter_max_depth[1]+parameter_max_depth_step,
parameter_max_depth_step)
param_grid = dict(max_features=parameter_max_features,
n_estimators=n_estimators_range,max_depth=max_depth_range)现在我们的应用程序应该如下图所示。


随机森林分类器
现在完成上面定义的模型函数。
rf = RandomForestClassifier(random_state=parameter_random_state,
bootstrap=parameter_bootstrap,
n_jobs=parameter_n_jobs)
grid = GridSearchCV(estimator=rf, param_grid=param_grid, cv=parameter_cross_validation)
grid.fit(X_train,Y_train)
st.subheader('模型的性能')
Y_pred_test = grid.predict(X_test)我们使用 RandomForestClassifier() 初始化模型,并将一些超参数传递给它,这些超参数由用户通过侧边栏给出。在此之下,我们将搜索空间定义为超参数值网格,GridSearchCV 评估网格中的每个位置。选择随机森林作为本次分类任务的模型;param_grid 由不同的参数组成,没有像 cv 那样的 folds。最后,使用训练完成的模型预测了测试数据的输出类别。
st.write('给定模型的accuracy 评分')
st.info(accuracy_score(Y_test, Y_pred_test))accuracy_score() 返回我们模型在测试数据上的准确性,我们将使用 st.info() 在我们的应用程序上显示它。
st.write("最佳参数是 %s,评分为 %0.2f" % (
grid.best_params_, grid.best_score_))grid.best_params_ 将返回从 param_grid 的参数中给出最佳结果的参数。
st.subheader('模型参数')
st.write(grid.get_params())上述函数将返回用于构建模型的所有参数。

构建3D可视化工具
#-----处理网格数据-----#
grid_results=pd.concat(
[pd.DataFrame(grid.cv_results_["params"]),
pd.DataFrame(grid.cv_results_["mean_test_score"],
columns=["accuracy"])],
axis=1)我们将使用参数和精度创建 pandas DataFrame,将它们 concat 连接起来,并存储在 grid_results 变量中。使用 2 个参数 max_depth 和 n_estimators 对数据进行分组。因为我们想要开发这 2 个参数与精度的 3D 图。
grid_contour = grid_results.groupby(['max_depth','n_estimators']).mean()
grid_reset = grid_contour.reset_index()
grid_reset.columns = ['max_depth', 'n_estimators', 'accuracy']
grid_pivot = grid_reset.pivot('max_depth', 'n_estimators')
x = grid_pivot.columns.levels[1].values
y = grid_pivot.index.values
z = grid_pivot.values现在为绘图创建 x、y 和 z 索引;x 轴是估计器的数量,y 轴是最大深度,z 轴代表模型的精度。
#定义布局和轴
layout = go.Layout(
xaxis=go.layout.XAxis(
title=go.layout.xaxis.Title(
text='n_estimators')
),
yaxis=go.layout.YAxis(
title=go.layout.yaxis.Title(
text='max_depth')
) )
fig = go.Figure(data= [go.Surface(z=z, y=y, x=x)], layout=layout )
fig.update_layout(title='Hyperparameter tuning',
scene = dict(
xaxis_title='n_estimators',
yaxis_title='max_depth',
zaxis_title='accuracy'),
autosize=False,
width=800, height=800,
margin=dict(l=65, r=50, b=65, t=90))
st.plotly_chart(fig)这里使用 plotly 库来绘制模型的 3d 图。plotly 可以使用 plotly_chart() 函数与 Streamlit 一起使用,我们必须在此函数中传递 fig。现在使用 scikit-learn 内置的函数分类报告打印两个类的精度precision、召回率recall和 f1-score。可以使用类名和不同的分数访问每个元素,将它们作为键传递。使用 st. write() 将它们写入应用程序。
st.subheader("Classification Report")
#它将以字典的形式返回输出
clf=classification_report(Y_test, Y_pred_test, labels=[0,1],output_dict=True)
st.write("""
### 类别 0(没有心脏病) :
Precision : %0.2f
Recall : %0.2f
F1-score : %0.2f"""%(clf['0']['precision'],clf['0']['recall'],clf['0']['f1-score']))
st.write("""
### 类别 1(有心脏病) :
Precision : %0.3f
Recall : %0.3f
F1-score : %0.3f"""%(clf['1']['precision'],clf['1']['recall'],clf['1']['f1-score']))
st.subheader("Confusion Matrix")
plot_confusion_matrix(grid, X_test, Y_test,display_labels=['没有心脏病','有心脏病'])
st.pyplot()有了以上几行代码,我们就完成了我们的模型功能。现在我们的应用程序可以使用了;保存所有更改并重新运行应用程序;之后,设置超参数的范围并点击构建;应该将 3D 图形如下图所示。


写在最后
只需在机器学习项目中添加几行代码,就可以在 Streamlit 的帮助下构建如此出色的前端应用程序。从真正意义上讲,Streamlit 让机器学习从业者的工作变得更轻松。本文为了演示,使用了一个非常简单的机器学习项目,但从数据处理、超参数调整、模型构建及预测到结果可视化、模型评价整个机器学习管道都有设计,希望对你有所帮助,记得点个赞和在看呀。
参考资料
[1]Streamlit 的官方文档: https://docs.streamlit.io/
[2]有关超参数调整和不同技术的更多信息: https://machinelearningmastery.com/hyperparameter-optimization-with-random-search-and-grid-search/
[3]Scikit 学习文档: https://scikit-learn.org/stable/user_guide.html

以上是关于在可视化大屏中轻松完成机器学习建模和调参应用实例的主要内容,如果未能解决你的问题,请参考以下文章