手写一个 Redis LruCache 缓存机制
Posted 流楚丶格念
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手写一个 Redis LruCache 缓存机制相关的知识,希望对你有一定的参考价值。
文章目录
LRU算法:最近最少使用原则
LRU算法具体概念在这不写了,这篇主要探究Lru写法
首先我们可以利用java提供的一个LinkedHashMap工具类
利用LinkedHashMap
我们要实现该算法,可以借助LinkedHashMap数据结构,LinkedHashMap继承HashMap,实现了Map。底层使用哈希表和双向链表来保存所有元素,使用LinkedHashMap可以确保元素按照顺序进行存储。
默认情况下,LinkedHashMap是按照元素的添加顺序存储,也可以启用按照访问顺序存储,即最近读取的数据放在最前面,最早读取的数据放在最后面
区别于HashMap的使用,我们在创建时候要注意两点:
构造的时候他有一个参数:accessOrder
accessOrder 表示是够根据访问次数动态调整:
- true是
- false否
然后它还有一个判断是否删除最老数据的方法removeEldestEntry,默认是返回false,即不删除数据,所以说你不重写这个方法,默认是不删除的:
例如我们进行重写,判断如果当前的size大于limit的时候就删除最老的数据
/**
* 返回true 就是满足条件的移出
* @param eldest
* @return 返回true就是满足条件的移出
*/
@Override
protected boolean removeEldestEntry(Map.Entry<String, Object> eldest)
if (this.size() > this.limit)
return true;
return false;
完整代码如下所示:
package com.test;
import java.util.LinkedHashMap;
import java.util.Map;
public class LruCache2 extends LinkedHashMap<String, Object>
private int limit;
public LruCache2(int limit)
// 1 2 3 4 false
// 1 3 4 2 true
// accessOrder 根据访问次数动态调整 1234 访问了2 就动态调整为 1342
// limit * 4 /3 避免扩容
super(limit * 4 /3, 0.75f, true);
this.limit = limit;
/**
* 返回true 就是满足条件的移出
* @param eldest
* @return 返回true就是满足条件的移出
*/
@Override
protected boolean removeEldestEntry(Map.Entry<String, Object> eldest)
if (this.size() > this.limit)
return true;
return false;
public static void main(String[] args)
LruCache2 cache = new LruCache2(5);
System.out.println(cache);
cache.put("1", 1);
System.out.println(cache);
cache.put("2", 2);
System.out.println(cache);
cache.put("3", 3);
System.out.println(cache);
cache.put("4", 4);
System.out.println(cache);
cache.put("5", 5);
System.out.println(cache);
cache.put("6", 6);
System.out.println(cache);
System.out.println(cache.get("2"));
System.out.println(cache);
cache.put("7", 7);
System.out.println(cache);
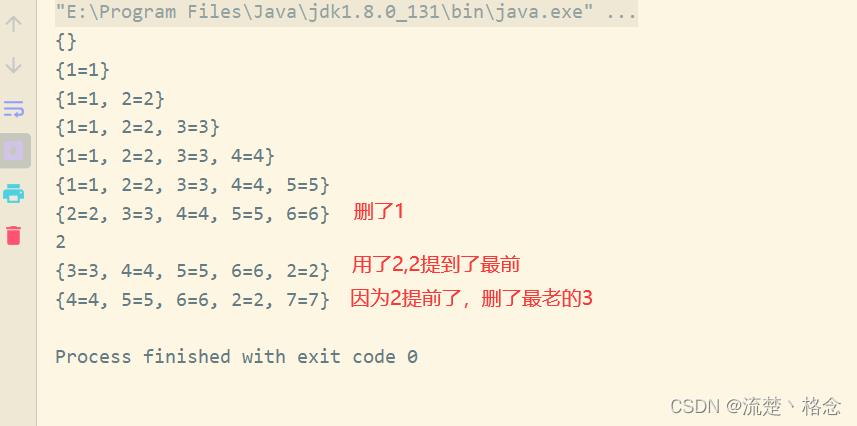
运行结果如下所示:
手写
什么?有人说:用现成没意思!

那就来手写!!!!!
分析
我们要先对这个功能进行分析再编写代码:
首先看数据结构,这里的缓存结点,要用的是双向链表结构(能指向上一个和下一个),还得能存键值信息(缓存结点的主要功能),为了方便,我们可以用内部类来实现
// node结点类
static class Node
Node prev;
Node next;
String key;
Object value;
public Node(String key, Object value)
this.key = key;
this.value = value;
然后我们要实现这个LRU类的主要功能:
主要功能:
- 增加节点:我们需要先判断key在原本map里有没有,没有就存入 ,有就更新下值,更新完了,需要移动到头结点,并且最后我们要判断限制的大小,超了移出尾部
- 删除节点:直接从链表中删除
- 获取节点:有就直接获取,没有就返回null,获取完了之后还得把他移到头结点
从这三个功能中我们能抽象出几个方法:
- 断开连接(删除断开当前结点关系,超出断开未节点)
- 更新节点到头的位置(获取完了更新,增加完了更新)
OK,开写,完整代码如下:
package com.test;
import java.util.HashMap;
import java.util.Map;
public class LruCache1
// node结点类
static class Node
Node prev;
Node next;
String key;
Object value;
public Node(String key, Object value)
this.key = key;
this.value = value;
/**
* 断开节点的连接
* @param node 要断开连接的结点
*/
public void unlink(Node node)
node.prev.next = node.next;
node.next.prev = node.prev;
// 将当前访问的结点更新到头
public void toHead(Node node)
node.prev = this.head;
node.next = this.head.next;
this.head.next.prev = node;
this.head.next = node;
int limit;
Node head;
Node tail;
Map<String, Node> map;
public LruCache1(int limit)
this.limit = Math.max(limit, 2);
this.head = new Node("Head", null);
this.tail = new Node("Tail", null);
// 一开始就得设置头 next 是尾 尾的pre是头
head.next = tail;
tail.prev = head;
this.map = new HashMap<>();
/**
* 删除节点
* @param key 删除节点的值
*/
public void remove(String key)
Node old = this.map.remove(key);
unlink(old);
/**
* 获取值
* @param key 键
* @return 值
*/
public Object get(String key)
// 有就直接获取 没有就null
Node node = this.map.get(key);
if (node == null)
return null;
// 获取完了之后还得把他移到头结点
unlink(node);
toHead(node);
return node.value;
/**
* 放值
* @param key
* @param value
*/
public void put(String key, Object value)
// key在原本map里有没有
Node node = this.map.get(key);
// 没有就存入 有就更新下值 更新完了 移动到头结点
if (node == null)
node = new Node(key, value);
this.map.put(key, node);
else
node.value = value;
unlink(node);
// 都得移动到头 所以写在外面
toHead(node);
// 判断限制的大小 超了移出尾部
if(map.size() > limit)
Node last = this.tail.prev;
this.map.remove(last.key);
unlink(last);
@Override
public String toString()
StringBuilder sb = new StringBuilder();
sb.append(this.head);
Node node = this.head;
while ((node = node.next) != null)
sb.append(node);
return sb.toString();
public static void main(String[] args)
LruCache1 cache = new LruCache1(5);
System.out.println(cache);
cache.put("1", 1);
System.out.println(cache);
cache.put("2", 2);
System.out.println(cache);
cache.put("3", 3);
System.out.println(cache);
cache.put("4", 4);
System.out.println(cache);
cache.put("5", 5);
System.out.println(cache);
cache.put("6", 6);
System.out.println(cache);
System.out.println(cache.get("2"));
System.out.println(cache);
cache.put("7", 7);
System.out.println(cache);
cache.remove("4");
System.out.println(cache);
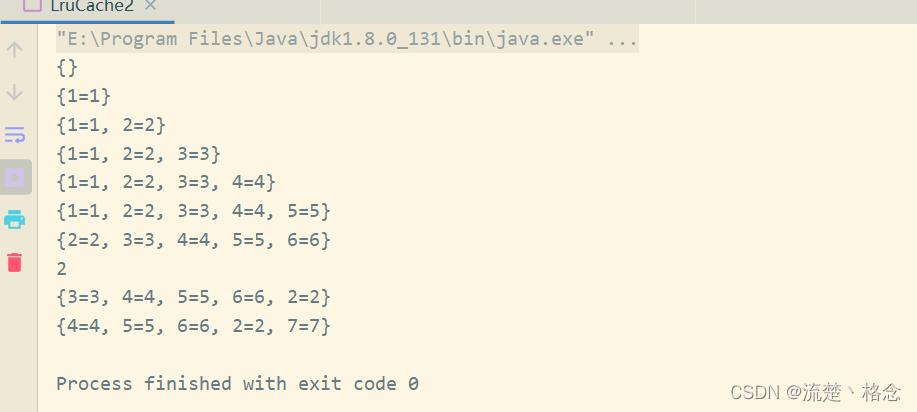
运行结果如下所示:
当前为了看链表关系更清楚,我们可以在节点上加一个toString方法,打印当前结点的时候打印详细信息:
package com.test;
import java.util.HashMap;
import java.util.Map;
public class LruCache1
// node结点类
static class Node
Node prev;
Node next;
String key;
Object value;
public Node(String key, Object value)
this.key = key;
this.value = value;
// (prev <- node -> next)
public String toString()
StringBuilder sb = new StringBuilder(128);
sb.append("(");
sb.append(this.prev == null ? null : this.prev.key);
sb.append("<-");
sb.append(this.key);
sb.append("->");
sb.append(this.next == null ? null : this.next.key);
sb.append(")");
return sb.toString();
/**
* 断开节点的连接
*
* @param node 要断开连接的结点
*/
public void unlink(Node node)
node.prev.next = node.next;
node.next.prev = node.prev;
// 将当前访问的结点更新到头
public void toHead(Node node)
node.prev = this.head;
node.next = this.head.next;
this.head.next.prev = node;
this.head.next = node;
int limit;
Node head;
Node tail;
Map<String, Node> map;
public LruCache1(int limit)
this.limit = Math.max(limit, 2);
this.head = new Node("Head", null);
this.tail = new Node("Tail", null);
// 一开始就得设置头 next 是尾 尾的pre是头
head.next = tail;
tail.prev = head;
this.map = new HashMap<>();
/**
* 删除节点
*
* @param key 删除节点的值
*/
public void remove(String key)
Node old = this.map.remove(key);
unlink(old);
/**
* 获取值
*
* @param key 键
* @return 值
*/
public Object get(String key)
// 有就直接获取 没有就null
Node node = this.map.get(key);
if (node == null)
return null;
// 获取完了之后还得把他移到头结点
unlink(node);
toHead(node);
return node.value;
/**
* 放值
*
* @param key
* @param value
*/
public void put(String key, Object value)
// key在原本map里有没有
Node node = this.map.get(key);
// 没有就存入 有就更新下值 更新完了 移动到头结点
if (node == null)
node = new Node(key, value);
this.map.put(key, node);
else
node.value = value;
unlink(node);
// 都得移动到头 所以写在外面
toHead(node);
// 判断限制的大小 超了移出尾部
if (map.size() > limit)
Node last = this.tail.prev;
this.map.remove(last.key);
unlink(last);
@Override
public String toString()
StringBuilder sb = new StringBuilder();
sb.append(this.head);
Node node = this.head;
while ((node = node.next) != null)
sb.append(node);
return sb.toString();
public static void main(String[] args)
LruCache1 cache = new LruCache1(5);
System.out.println(cache);
cache.put("1", 1);
System.out.println(cache);
cache.put("2", 2);
System.out.println(cache);
cache.put("3"以上是关于手写一个 Redis LruCache 缓存机制的主要内容,如果未能解决你的问题,请参考以下文章
redis前传自己手写一个LRU策略 | redis淘汰策略
redis前传自己手写一个LRU策略 | redis淘汰策略
使用LruCache和DiskLruCache手写一个ImageLoader
Android 【手撕Glide】--Glide缓存机制(面试)