ES基本概念和原理简单介绍
Posted Firm陈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ES基本概念和原理简单介绍相关的知识,希望对你有一定的参考价值。
Elasticsearch概述:
ES是基于Lucene的搜索服务器,它提供了一个分布式多用户能力的全问搜索引擎,且ES支持RestFulweb风格的url访问。ES是基于Java开发的开源搜索引擎,设计用于云计算,能够达到实时搜索,稳定、可靠、快速。此外,ES还提供了数据聚合分析功能,但在数据分析方面,es的时效性不是很理想,在企业应用中一般还是用于搜索。ES自2016年起已经超过Solr等,称为排名第一的搜索引擎应用。
ES、Lucene、solr对比:
- Luence是Apache基于Java编写的信息搜索工具包(jar包),它包含了索引结构、读写索引工具、相关性工具、排序等功能,因此Lucene的使用需要我们进一步开发搜索引擎系统,如果数据获取、解析、分词等
- Solr是一个有HTTP接口的基于Lucene的查询服务器,是一个搜索引擎系统,系统封装了很多lucene细节,Solr可以直接利用HTTPGET/POST 请求去查询,维护修改索引。Solr利用zookeeper进行分布式管理,它的实现更加全面,官方提供的功能更多。
- Elasticsearch 是一个建立在全文搜索引擎Apache Lucene基础上的搜索引擎,采用的策略师分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。es的实时搜索性比solr更好。
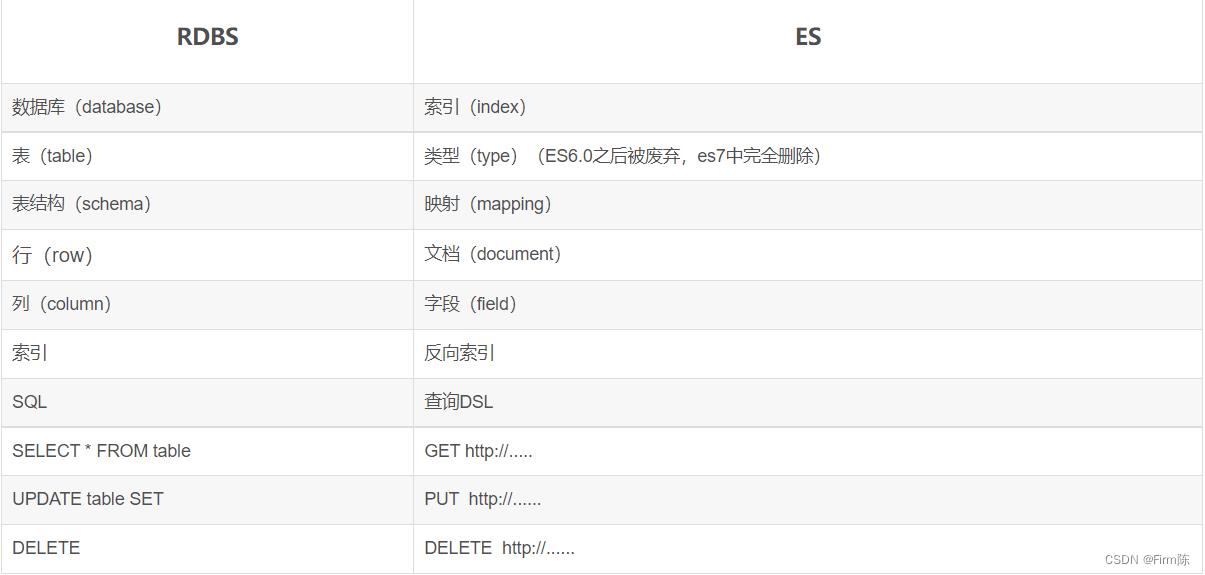
Elasticsearch基本概念:
ES中有几个基本概念:索引(index)、类型(type)、文档(document)、映射(mapping)等。我们将这几个概念与传统的关系型数据库中的库、表、行、列等概念进行对比,如下表:
倒排索引:
倒排索引操作步骤:
- 先将文档中包含的关键字全部提取出来
- 然后再将关键字与文档的对应关系保存起来
- 最后对关键字本身做索引排序。
这样在用户检索关键字时, 可以先查找关键字索引,在通过关键字与文档的对应关系查找到所在的文档。
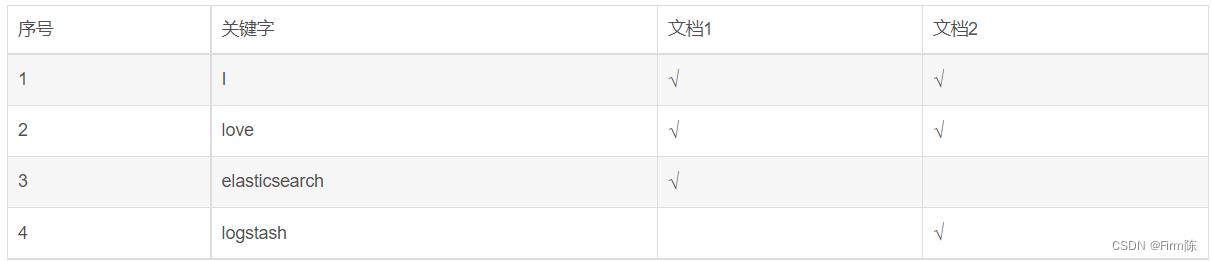
如下面的两个文档:
文档1: I love elasticsearch
文档2: I love logstash
他们对应的倒排索引为: “√” 表示文档中包含这个关键字
索引(index):
索引是ES的一个逻辑存储,对应关系型数据库中的库,ES可以把索引数据存放到服务器中,也可以sharding(分片)后存储到多台服务器上。每个索引有一个或多个分片,每个分片可以有多个副本。
类型(type):
ES中,一个索引可以存储多个用于不同用途的对象,可以通过类型来区分索引中的不同对象,对应关系型数据库中表的概念。但是在ES6.0开始,类型的概念被废弃,ES7中将它完全删除。删除type的原因:
我们一直认为ES中的“index”类似于关系型数据库的“database”,而“type”相当于一个数据表。ES的开发者们认为这是一个糟糕的认识。例如:关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES中不是这样的。
我们都知道elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同的filed最终在Lucene中的处理方式是一样的。举个例子,两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在处理中出现冲突的情况,导致Lucene处理效率下降。
去掉type能够使数据存储在独立的index中,这样即使有相同的字段名称也不会出现冲突,就像ElasticSearch出现的第一句话一样“你知道的,为了搜索····”,去掉type就是为了提高ES处理数据的效率。
除此之外,在同一个索引的不同type下存储字段数不一样的实体会导致存储中出现稀疏数据,影响Lucene压缩文档的能力,导致ES查询效率的降低
文档(document):
存储在ES中的主要实体叫文档,可以理解为关系型数据库中表的一行数据记录。每个文档由多个字段(field)组成。区别于关系型数据库的是,ES是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一标识。
映射(mapping):
mapping是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构。ES默认动态创建索引和索引类型的mapping,这就像是关系型数据中的,无需定义表机构,更不用指定字段的数据类型。当然也可以手动指定mapping类型。
ES集群核心概念:
1、集群(cluster)
一个ES集群由多个节点(node)组成, 每个集群都有一个共同的集群名称最为标识
2、节点(node)
一个es实例即为一个节点,一台机器可以有多个节点,正常使用下每个实例都应该会部署在不同的机器上。ES的配置文件中可以通过node.master、 node.data 来设置节点类型
- node.master: true/false 表示节点是否具有成为主节点的资格
- node.data: true/false 表示节点是否为存储数据
node节点的组合方式:
- 主节点+数据节点: 默认方式,节点既可以作为主节点,又存储数据
- 数据节点: 节点只存储数据,不参与主节点选举
- 客户端节点: 不会成为主节点,也不存储数据,主要针对海量请求时进行负载均衡
3、分片(shard):
如果我们的索引数据量很大,超过硬件存放单个文件的限制,就会影响查询请求的速度,ES引入了分片技术。一个分片本身就是一个完成的搜索引擎,文档存储在分片中,而分片会被分配到集群中的各个节点中,随着集群的扩大和缩小,ES会自动的将分片在节点之间进行迁移,以保证集群能保持一种平衡。分片有以下特点:
(1)ES的一个索引可以包含多个分片(shard);
(2)每一个分片(shard)都是一个最小的工作单元,承载部分数据;
(3)每个shard都是一个lucene实例,有完整的简历索引和处理请求的能力;
(4)增减节点时,shard会自动在nodes中负载均衡;
(5)一个文档只能完整的存放在一个shard上
(6)一个索引中含有shard的数量,默认值为5,在索引创建后这个值是不能被更改的。
(7)优点:水平分割和扩展我们存放的内容索引;分发和并行跨碎片操作提高性能/吞吐量;
(8)每一个shard关联的副本分片(replica shard)的数量,默认值为1,这个设置在任何时候都可以修改。
2、副本:replica
副本(replica shard)就是shard的冗余备份,它的主要作用:
- 冗余备份,防止数据丢失;
- shard异常时负责容错和负载均衡;
ES的特性:
速度快、易扩展、弹性、灵活、操作简单、多语言客户端、X-Pack、hadoop/spark强强联手、开箱即用。
分布式:横向扩展非常灵活
全文检索:基于lucene的强大的全文检索能力;
近实时搜索和分析:数据进入ES,可达到近实时搜索,还可进行聚合分析
高可用:容错机制,自动发现新的或失败的节点,重组和重新平衡数据
模式自由:ES的动态mapping机制可以自动检测数据的结构和类型,创建索引并使数据可搜索。
RESTful API:JSON + HTTP
以上是关于ES基本概念和原理简单介绍的主要内容,如果未能解决你的问题,请参考以下文章