机器学习笔记:自监督学习
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记:自监督学习相关的知识,希望对你有一定的参考价值。
1 自监督学习介绍
- 利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息
- 通过这种自身的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。
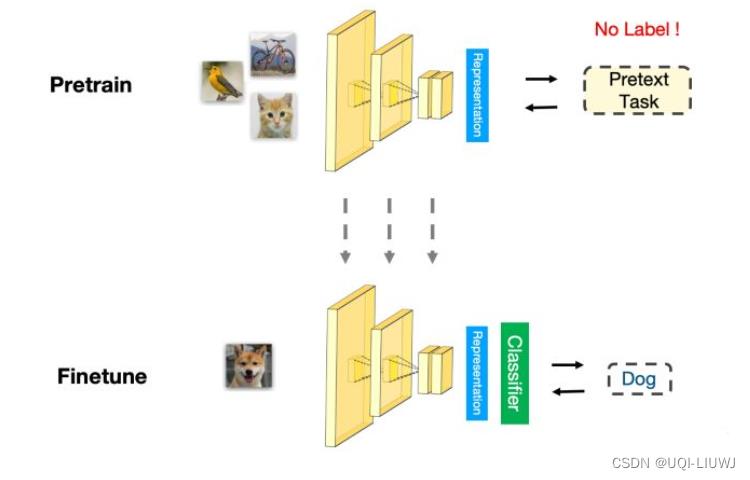
2 自监督学习分类
2.1 基于上下文(Context Based)
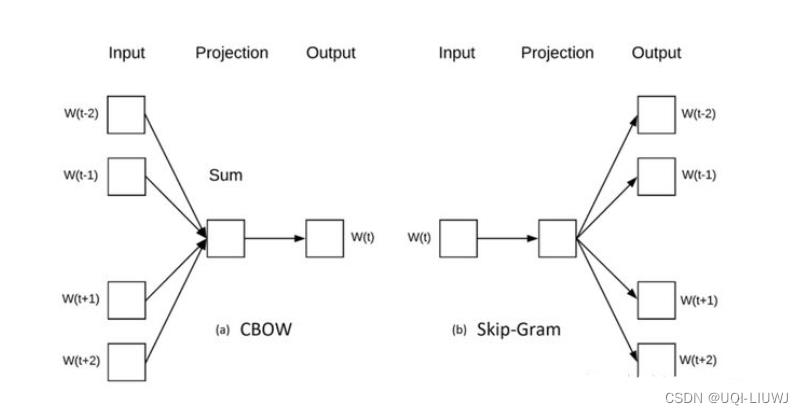
2.1.1 Word2Vec(NLP)
最经典的Skip-gram和CBOW就是一种自监督学习,根据上下文内容预测中间词/根据中间词预测上下文内容
2.1.2 Jigsaw 1.0(CV)
Unsupervised Visual Representation Learning by Context Prediction. ICCV 2015
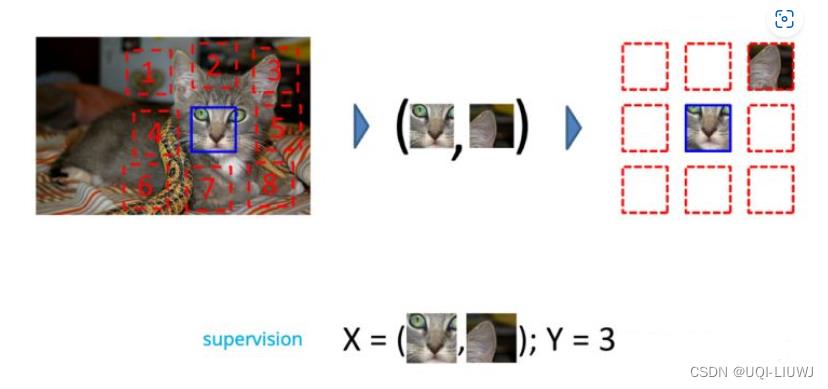
- 将一张图分成 9 个部分,然后通过预测这几个部分的相对位置来产生损失
- 如果模型能很好的完成这个任务,那么我们就可以认为模型学习到的表征是具有语义信息的
2.1.3 Jigsaw 2.0(CV)
Unsupervised learning of visual representations by solving jigsaw puzzles. ECCV 2016.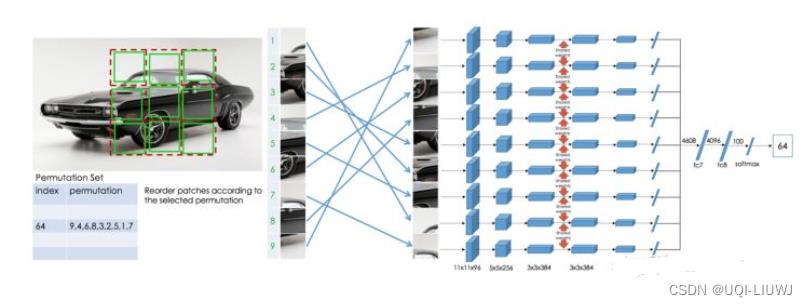
- 预测图片九块的排序方式
- 相比于之前的jigsaw,辅助任务更难(当然最后的性能也更好)
2.1.4 Inpainting(CV)
Context Encoders: Feature Learning by Inpainting. In CVPR 2016.
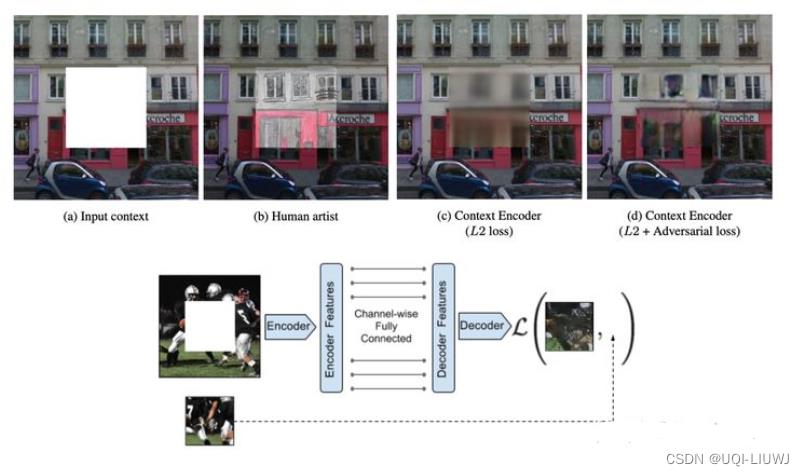
随机的将图片中的一部分删掉,然后利用剩余的部分来预测扣掉的部分
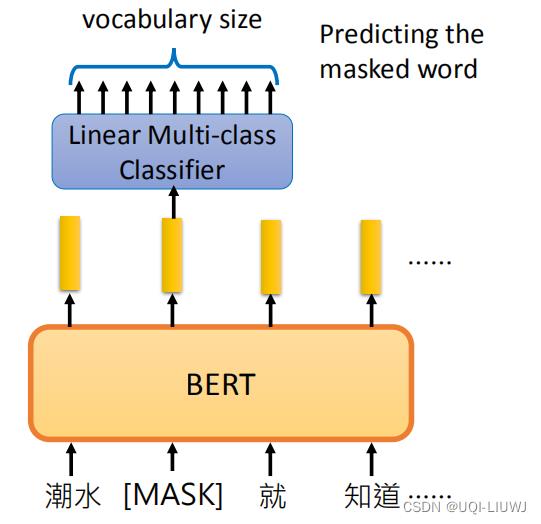
2.1.5 MLM(NLP)
和CV中的inpainting类似
2.1.6 图像上色
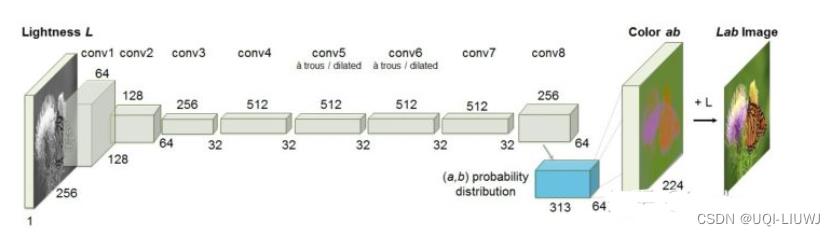
A. Colorful image colorization. ECCV 2016.
- 模型输入图像的灰度图,来预测图片的色彩
- 只有模型可以理解图片中的语义信息才能得知哪些部分应该上怎样的颜色(比如天空是蓝色的,草地是绿色的)
2.1.7 图像旋转
Unsupervised Representation Learning by Predicting Image Rotations. ICLR 2018
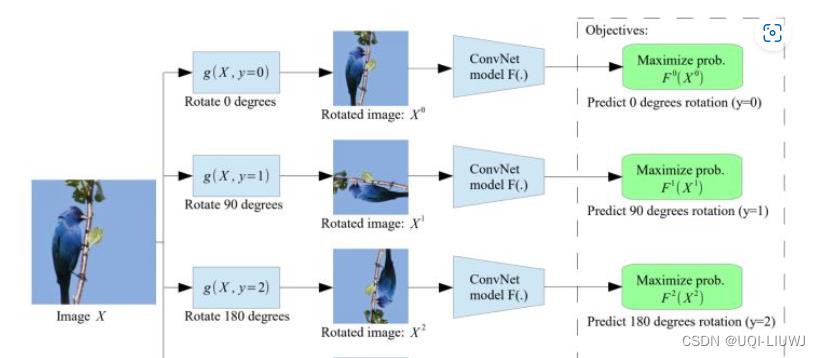
2.2 基于时序
- 2.1中涉及的方法大多是基于样本自身的信息,比如旋转、色彩、裁剪等。
- 而样本间其实也是具有很多约束关系的,这一小节的模型将利用时序约束来进行自监督学习
- 在自监督学习中,最能体现时序的数据类型就是视频了(video)。
2.2.1 基于帧的相似性
Time-Contrastive Networks: Self-Supervised Learning from Video. ICRA 2017
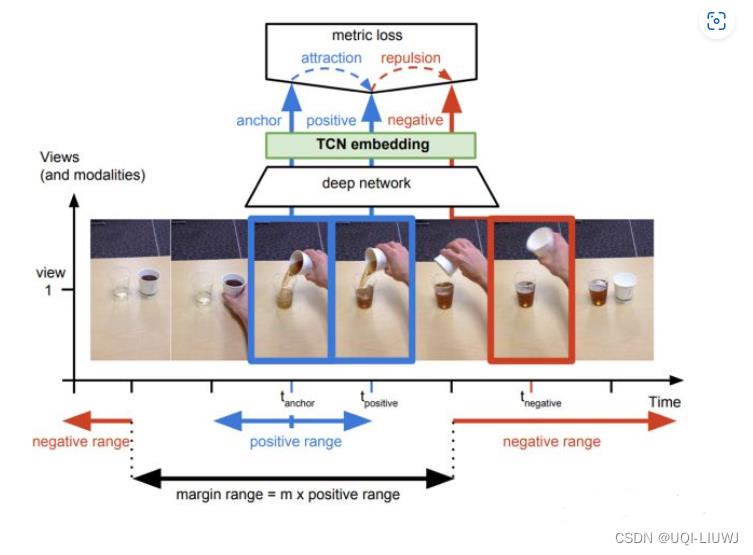
- 视频中的相邻帧特征是相似的,而相隔较远的视频帧是不相似的
- 通过构建这种相似(position)和不相似(negative)的样本来进行自监督约束。
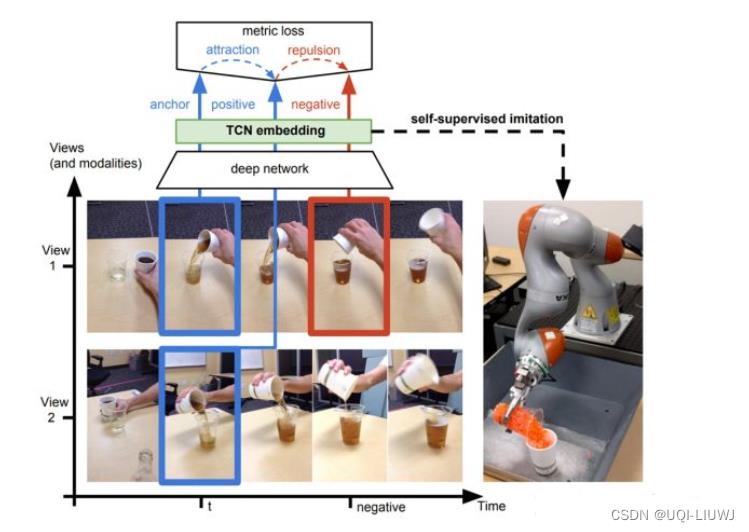
- 对于同一个物体的拍摄是可能存在多个视角(multi-view)
- 对于多个视角中的同一帧,可以认为特征是相似的,对于不同帧可以认为是不相似的。
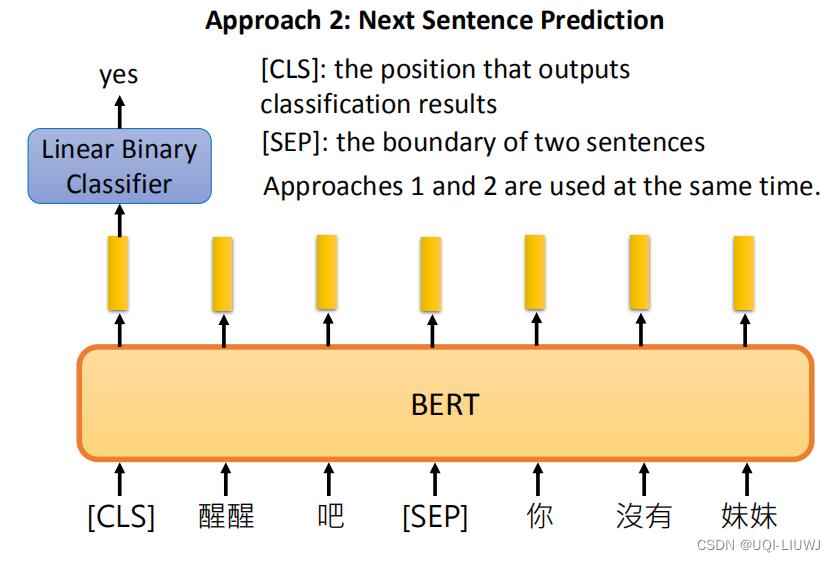
2.2.2 Next Sequence Prediction
Bert中的next sequence prediction也是一种基于时序的自监督学习
2.3 对比学习
- 构建正样本(positive)和负样本(negative),度量正负样本的距离来实现自监督学习。
- 样本(锚点,anchor)和正样本之间的相似度远远大于样本和负样本之间的相似度:
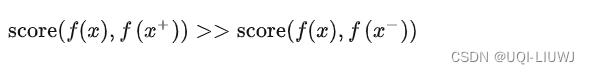
- 为了实现上一行的目标,设计了一个softmax分类器,目标是正确分类正样本和负样本
2.3.1 常用损失函数
- Noise-contrastive Estimation (NCE)
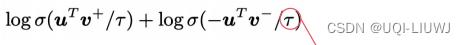
- InfoNCE
分母是由一个正样本和N-1个负样本组成
使用点积来作为score函数
这样的损失函数(InfoNCE)·会鼓励相似性度量函数(点积)将较大的值分配给正例,将较小的值分配给负例
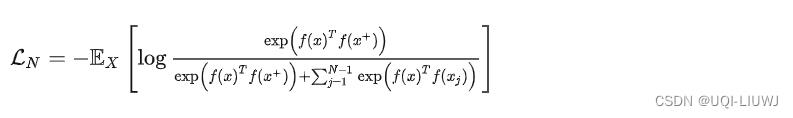
- Margin Triplet
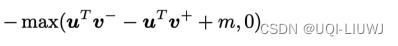
2.3.3 基于对比学习的自监督学习
2.3.3.1 Deep InfoMax (DIM)
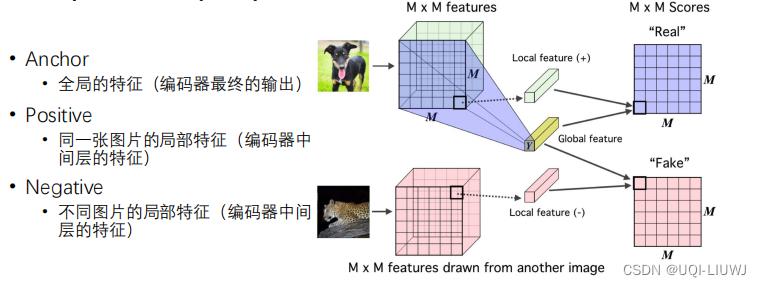
同一张图片,编码器最终的输出和中间的特征接近;最终的输出和其他图片中间的特征远离
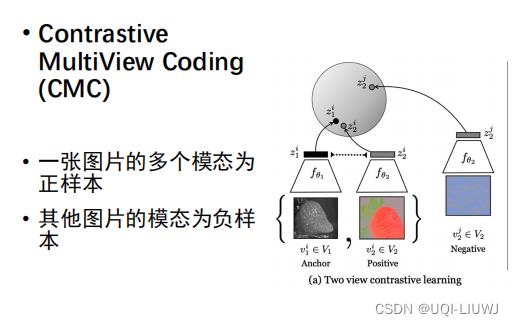
2.3.3.2 Contrastive MultiView Coding (CMC)
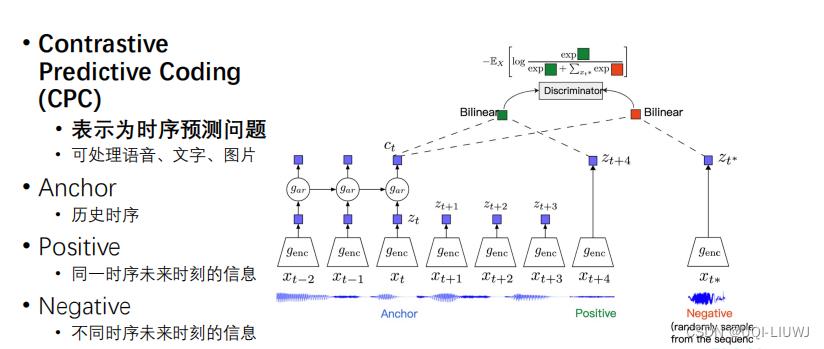
2.3.3.3 Contrastive Predictive Coding (CPC)

2.4 MOCO
上述的基于对比学习的方法,还是需要基于某一特定的对比任务 ,那么有没有更通用一点的对比学习呢》
2.4.1 Instance Discrimination Task
- 利用数据增强方法,把单个数据增强为多个
- 来自同一个数据的不同增强结果,为正样本
- 来自不同数据的增强结果,为负样本
- 训练时看见更多更复杂的负样本,能让对比学习学习得更好
- ——>Memory bank:把用过的样本存起来,下次再用(个人感觉类似于强化学习中的经验回放)
- ——>Large Batch
- 训练时看见更多更复杂的负样本,能让对比学习学习得更好
2.4.2 传统的端到端训练方法
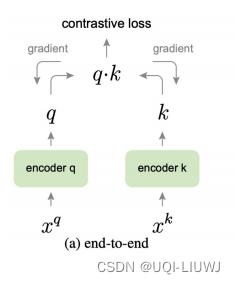
只用当前batch中的负样本
- 对于给定的一个样本
 , 选择一个正样本
, 选择一个正样本 ( 的数据增强)。
( 的数据增强)。 - 选择一批负样本 (除了 之外的图像)【batch_size个】
- 使用 loss function
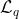 来将与正样本之间的距离拉近,负样本之间的距离推开。
来将与正样本之间的距离拉近,负样本之间的距离推开。 - 样本输入给 Encoder
 ,正样本和负样本都输入给 Encoder
,正样本和负样本都输入给 Encoder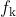 。
。 - 通过loss function 来更新2个 Encoder , 的参数。
问题在于,由于算力和计算资源的限制,batch size不能设置的过大——>效率不高
2.4.3 Memory Bank
- 把最近用过的样本表示存在候选池中,供后续batch使用
-
主要问题:表示来自于新旧不同时期的模型,导致不一致性
(inconsistency)
-
Encoder fq 的参数每一步都更新,但是某个
 可能很多步后才被采样更新一次
可能很多步后才被采样更新一次
- 每一步编码器都会进行更新,这样最新的 query 采样得到的 key 可能是好多步之前的编码器编码得到的 key
-
Encoder fq 的参数每一步都更新,但是某个
- 对于给定的一个样本 , 选择一个正样本 ( 的数据增强)。
- 采用一个较大的 memory bank 存储所有样本的representation。
- 采样其中的一部分负样本
-
使用 loss function
来将与正样本之间的距离拉近,负样本之间的距离推开。
2.4.4 MOCO 原理
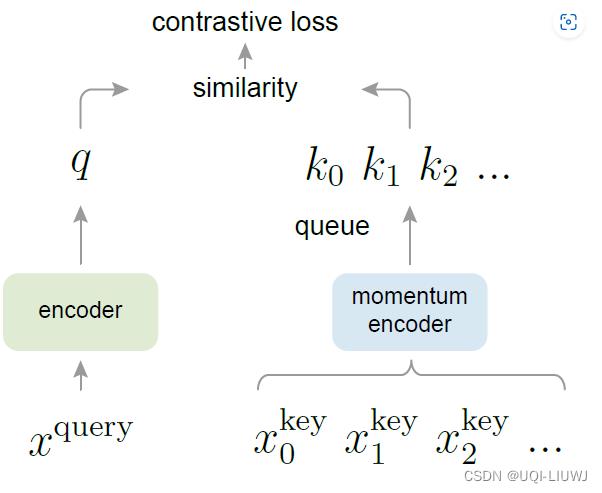
- 假设 Batch size 的大小是 N ,然后现在有个队列 Queue,这个队列的大小是 K(K>N)
- 注意这里 K 一般是 N的数倍,比如 K=3N,K=5N,...
- (代码里面 K=65536 ,即队列大小实际是65536)。
-
有两个网络, Encoder
和Momentum Encoder 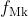 。
。 -
这两个模型的网络结构是一样的
-
初始参数也是一样的 (但是训练开始后两者参数将不再一样了)。
- 与是将输入信息映射到特征空间的网络,特征空间由一个长度为 C 的向量表示
-
-

-
虽然
和还是不是一个模型,但两个模型是很相近的;不像Memory bank那样,旧模型和新模型之间相差太大2.4.5 MOCO 伪代码解读
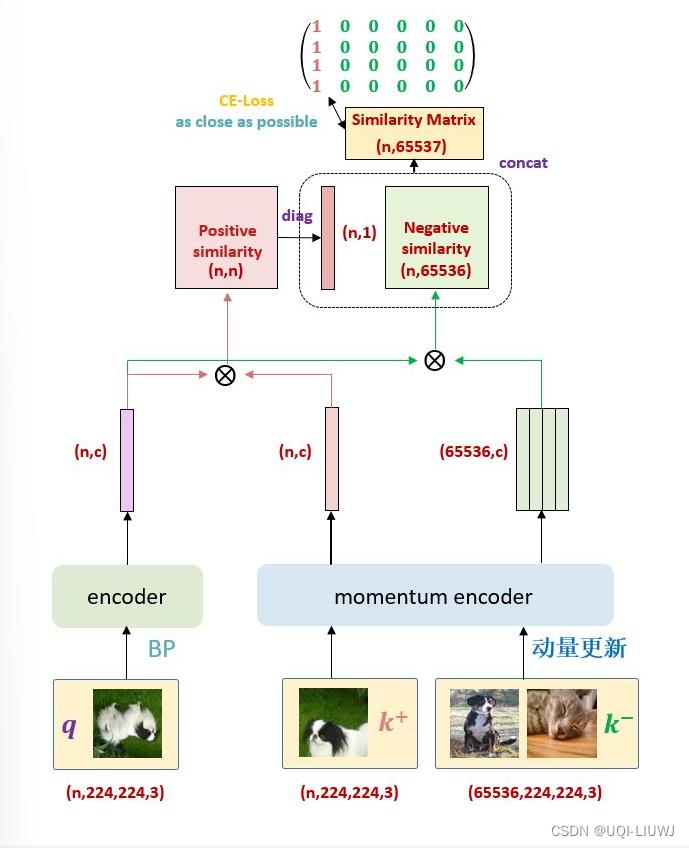
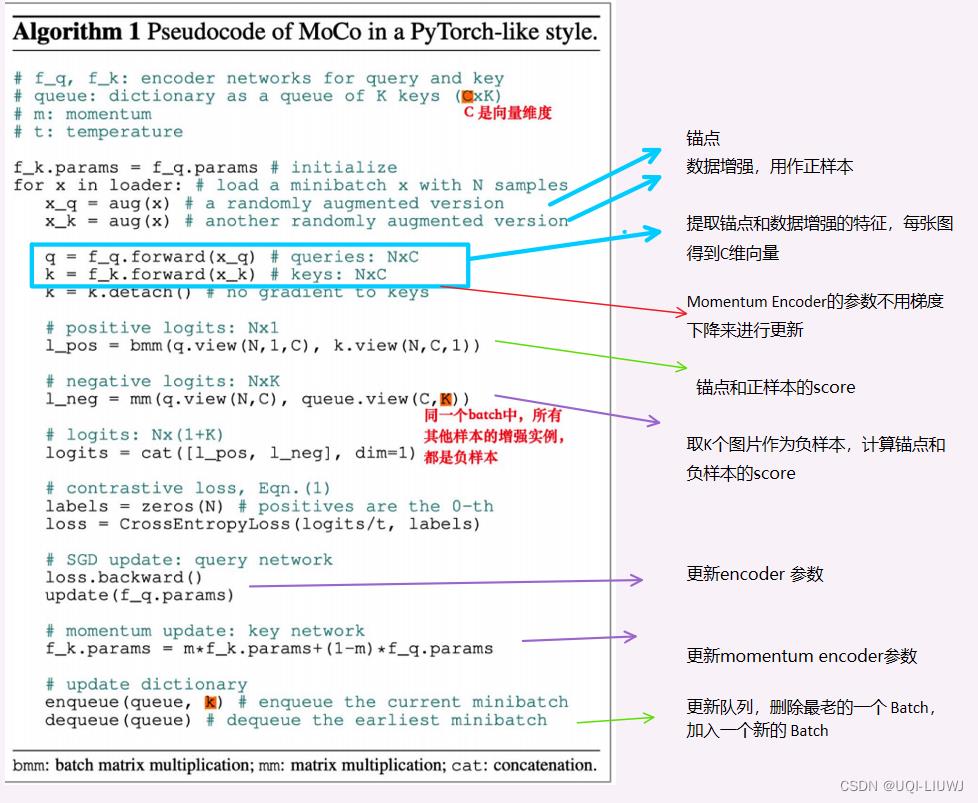
2.4.6 MOCO实验
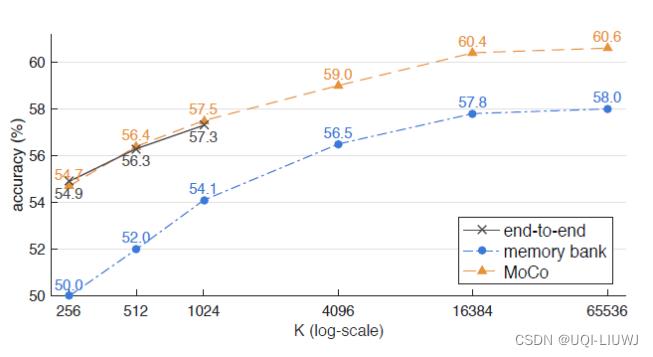
2.5 SimCLR
对比学习的通用框架
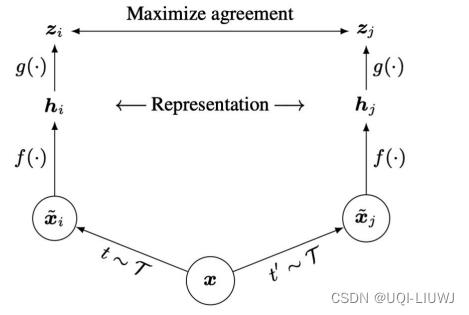
- τ和τ'是两种数据增强
- h=f(x),论文中使用的是ResNet
- z=g(h),论文中是两层MLP
- 同一张图片用不同的数据增强得到的是正样本,不同图片之间的是负样本
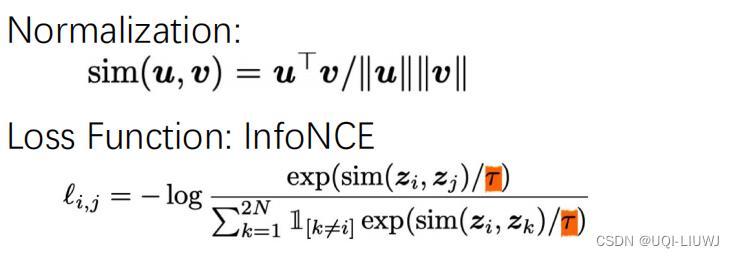
3 带来的启发
3.1 Disentanglement与自监督学习
只要是解耦(disentangled)的特征,我们都可以通过互相监督的学习表征


eg Split-Brain Autoencoders
Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction.CVPR 2017
以上是关于机器学习笔记:自监督学习的主要内容,如果未能解决你的问题,请参考以下文章