Mysql之索引原理
Posted 刘小豆豆豆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mysql之索引原理相关的知识,希望对你有一定的参考价值。
索引
索引的作用是做数据的快速检索,而快速检索的实现的本质是数据结构。通过不同数据结构的选择,实现各种数据快速检索。
索引的底层数据结构:
-
哈希表(Hash)
哈希表是做数据快速检索的有效利器。
哈希算法:也叫散列算法,就是把任意值(key)通过哈希函数变换为固定长度的 key 地址,通过这个地址进行具体数据的数据结构。
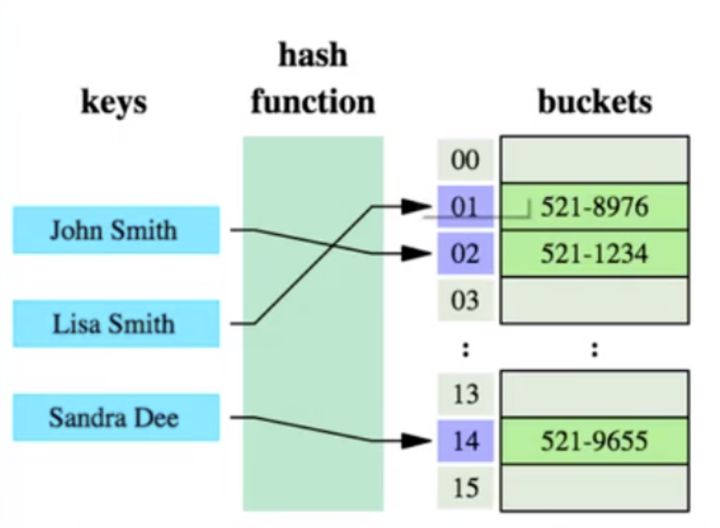
Hash索引的缺点:
使用哈希算法实现的索引虽然可以做到快速检索数据,但是没办法做数据高效范围查找,因此哈希索引是不适合作为 mysql 的底层索引的数据结构。
-
二叉查找树(BST)

二叉查找树的复杂度是LogN,但是普通的二叉查找树有个致命缺点:极端情况下会退化为线性链表,二分查找也会退化为遍历查找,时间复杂退化为 O(N),检索性能急剧下降。比如以下这个情况,二叉树已经极度不平衡了,已经退化为链表了,检索速度大大降低。
-
AVL 树和红黑树
AVL 树是个绝对平衡的二叉树,因此他在调整二叉树的形态上消耗的性能会更多。红黑树在当数据是顺序插入时,树的形态一直处于“右倾”的趋势,因此不适合作为索引。
-
B树
每个节点限制最多存储两个 key,一个节点如果超过两个 key 就会自动分裂。比如下面这个存储了 7 个数据 B 树,只需要查询两个节点就可以知道 id=7 这数据的具体位置,也就是两次磁盘 IO 就可以查询到指定数据,优于 AVL 树。

但是考虑到磁盘 IO 读一个数据和读 100 个数据消耗的时间基本一致,那我们的优化思路就可以改为:尽可能在一次磁盘 IO 中多读一点数据到内存**。这个直接反映到树的结构就是,每个节点能存储的 key 可以适当增加。**
B树的优点:
- 优秀检索速度,时间复杂度:B 树的查找性能等于 O(h*logn),其中 h 为树高,n 为每个节点关键词的个数;
- 尽可能少的磁盘 IO,加快了检索速度;
- 可以支持范围查找。
B树的缺点:由于B树中各节点之间没有指针相邻,因此B树不适合做一些数据遍历操作。
-
B+树
B树与B+树有什么不同?
-
B 树一个节点里存的是数据,而 B+树存储的是索引(地址),所以 B 树里一个节点存不了很多个数据,但是 B+树一个节点能存很多索引,B+树叶子节点存所有的数据。
-
B+树的叶子节点是数据阶段用了一个链表串联起来,便于范围查找。

通过 B 树和 B+树的对比我们看出,B+树节点存储的是索引,在单个节点存储容量有限的情况下,单节点也能存储大量索引,使得整个 B+树高度降低,减少了磁盘 IO。其次,B+树的叶子节点是真正数据存储的地方,叶子节点用了链表连接起来,这个链表本身就是有序的,在数据范围查找时,更具备效率。因此 Mysql 的索引用的就是 B+树,B+树在查找效率、范围查找中都有着非常不错的性能。
-
MySQL索引使用的数据结构主要有BTree索引 和 哈希索引 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
引擎:
MySQL的BTree索引使用的是B树中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
- MyISAM: B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
- InnoDB: 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
MyISAM 虽然数据查找性能极佳,但是不支持事务处理。Innodb 最大的特色就是支持了 ACID 兼容的事务功能,而且他支持行级锁。Mysql 建立表的时候就可以指定引擎,比如下面的例子,就是分别指定了 Myisam 和 Innodb 作为 user 表和 user2 表的数据引擎。
聚簇与非聚簇索引索引
聚簇索引:
B+树是左小右大的顺序存储结构,节点只包含id索引列,而叶子节点包含索引列和数据,这种数据和索引在一起存储的索引方式叫做聚簇索引,一张表只能有一个聚簇索引。假设没有定义主键,InnoDB会选择一个唯一的非空索引代替,如果没有的话则会隐式定义一个主键作为聚簇索引。
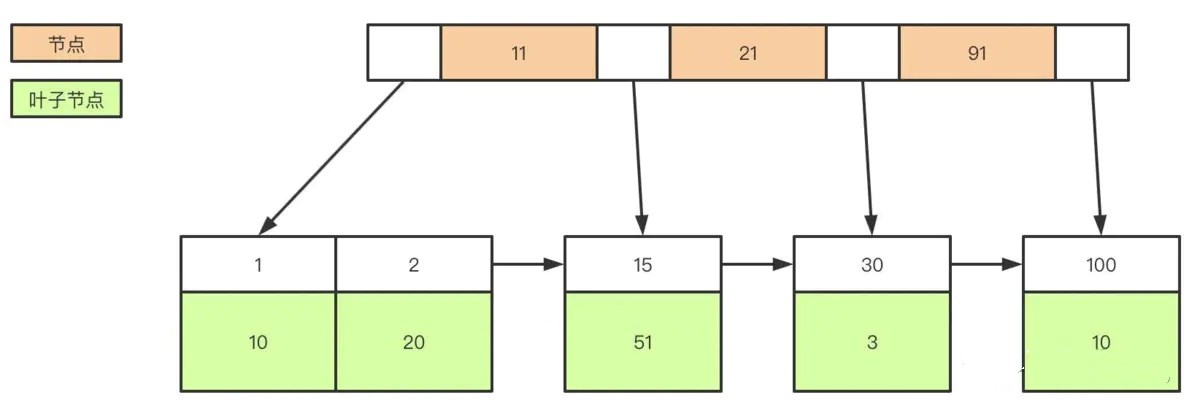
当我们为表里某个字段加索引时 InnoDB 会怎么建立索引树呢?
比如我们要给 user_name 这个字段加索引,那么 InnoDB 就会建立 user_name 索引 B+树,节点里存的是 user_name 这个 KEY,叶子节点存储的数据的是主键 KEY。注意,叶子存储的是主键 KEY!拿到主键 KEY 后,InnoDB 才会去主键索引树里根据刚在 user_name 索引树找到的主键 KEY 查找到对应的数据。

除主键外建立索引后会形成
其实很简单,因为 InnoDB 需要节省存储空间。一个表里可能有很多个索引,InnoDB 都会给每个加了索引的字段生成索引树,如果每个字段的索引树都存储了具体数据,那么这个表的索引数据文件就变得非常巨大(数据极度冗余了)。从节约磁盘空间的角度来说,真的没有必要每个字段索引树都存具体数据,通过这种看似“多此一举”的步骤,在牺牲较少查询的性能下节省了巨大的磁盘空间,这是非常有值得的。
非聚簇索引(二级索引)
将数据存储于索引分开结构,数据和索引落在不同的两个文件上,索引结构的叶子节点指向了数据的对应行,myisam通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因。
MyISAM 在建表时以主键作为 KEY 来建立主索引 B+树,树的叶子节点存的是对应数据的物理地址。我们拿到这个物理地址后,就可以到 MyISAM 数据文件中直接定位到具体的数据记录了。

MyISAM 查询性能更好,从上面索引文件数据文件的设计来看也可以看出原因:MyISAM 直接找到物理地址后就可以直接定位到数据记录,但是 InnoDB 查询到叶子节点后,还需要再查询一次主键索引树,才可以定位到具体数据。等于 MyISAM 一步就查到了数据,但是 InnoDB 要两步,那当然 MyISAM 查询性能更高。
聚簇索引适合排序场合、取出一定范围内的数据时聚簇索引更合适。
以上是关于Mysql之索引原理的主要内容,如果未能解决你的问题,请参考以下文章