一文速学-HiveSQL解析JSON数据详解+代码实战
Posted fanstuck
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文速学-HiveSQL解析JSON数据详解+代码实战相关的知识,希望对你有一定的参考价值。
目录
前言
JSON文件存储格式十分常见,在各个数据库中以及业务场景都有关于该文件的处理方式。但是有时候处理JSON文件在不同的数据库处理方法也不同,掌握一些高效的函数可以大大简化我们处理JSON数据格式的效率。面对一些复杂的存储形式,例如JSON数组存储这种就必须采取一定的处理方式,下面是处理HiveSQL解析JSON数据的函数与方法。
一、JSON数据
君欲擅其器,必先练其力。我们要对JSON文件有个熟悉的认知。
JSON是一个标记符的序列。这套标记符包含六个构造字符、字符串、数字和三个字面名。
JSON是一个序列化的对象或数组。
- 数据为 键 / 值 (name/value)对;
- 数据由逗号(,)分隔;
- 大括号保存对象(object);
- 方括号保存数组(Array);
值可以是对象、数组、数字、字符串或者三个字面值(false、null、true)中的一个。值中的字面值中的英文必须使用小写。
如:
"code":"100"
对象由花括号括起来的逗号分割的成员构成,成员是字符串键和上文所述的值由逗号分割的键值对组成:
{“code”:20,"type":"mysql"}
数组是由方括号括起来的一组值构成:
"datesource":[
"code":"20", "type":"mysql",
"code":"20", "type":"mysql",
"code":"20", "type":"mysql"
]
二、Hive解析函数
以我们经常存储的JSON文件为实例去展示操作:
"level":"2","time":1650973942596,"type":"0"
HiveSQL自带两个函数可以处理JSON文件,但是一次只能处理一个JSON文件。
1.get_json_object
get_json_object的基础语法格式为:
get_json_object(json_string, '$.key')功能:解析json的字符串json_string,返回key指定的内容。如果输入的json字符串无效,那么返回NULL。这个函数每次只能返回一个数据项。
SELECT
GET_JSON_OBJECT('"level":"2","time":1650973942596,"type":"0"','$.level' ) as level ; 
如果要解析JSON的所有字段可以多写几条:
SELECT
GET_JSON_OBJECT('"level":"2","time":1650973942596,"type":"0"','$.level' ) as level,
GET_JSON_OBJECT('"level":"2","time":1650973942596,"type":"0"','$.time' ) as times,
GET_JSON_OBJECT('"level":"2","time":1650973942596,"type":"0"','$.type' ) as types; 
2.json_tuple
为了解决get_json_object一次解析不了整个JSON文件的问题,我们就有了json_tuple这个函数,一条便能处理一条JSON数据,基础语法为:
json_tuple(json_string, k1, k2 ...)解析json的字符串json_string,可指定多个json数据中的key,返回对应的value。如果输入的json字符串无效,那么返回NULL。
SELECT
json_tuple('"level":"2","time":1650973942596,"type":"0"','level','time','type') as (level,times,types);
但是以上这两个函数都无法处理JSON数组,需要我们使用正则替换和explode函数清洗出每条独立的JSON数据才能处理。
3.explode
explode的基础语法为:
explode(Array OR Map)功能:explode()函数接收一个array或者map类型的数据作为输入,然后将array或map里面的元素按照每行的形式输出,即将hive一列中复杂的array或者map结构拆分成多行显示,也被称为列转行函数。
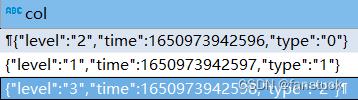
SELECT explode(array(
'
"level":"2","time":1650973942596,"type":"0"',
'"level":"1","time":1650973942597,"type":"1"',
'"level":"3","time":1650973942598,"type":"2"
'
)) 
select explode(map('level',1,'time',1650973942596,'type',0)) 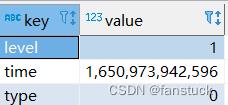
4.regexp_replace
regexp_replace就好比python里面的sub()匹配之后替换:
基础语法:
regexp_replace(string A, string B, string C)功能:将字符串A中的符合java正则表达式B的部分替换为C。
select REGEXP_REPLACE('"level":"2","time":1650973942596,"type":"0"','2','1'); 
三、Hive解析JSON数组
我们先拿到一组JSON数组:
["level":"2","time":1650973942596,"type":"0",
"level":"1","time":1650973942597,"type":"1",
"level":"3","time":1650973942598,"type":"2"]
我们想要把他们转换为一下格式,变成一下这种形式:
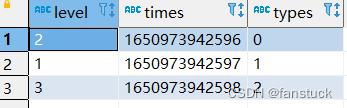
第一步:
第一步我们要将数组外面的,给替换掉,以免后续我们按;划分展开。
SELECT
REGEXP_REPLACE('["level":"2","time":1650973942596,"type":"0","level":"1","time":1650973942597,"type":"1","level":"3","time":1650973942598,"type":"2"]','\\\\\\\\,\\\\','\\\\\\\\;\\\\')

第二步:
将数组两边的[]给去掉:
select
REGEXP_REPLACE(
REGEXP_REPLACE('["level":"2","time":1650973942596,"type":"0","level":"1","time":1650973942597,"type":"1","level":"3","time":1650973942598,"type":"2"]','\\\\\\\\,\\\\','\\\\\\\\;\\\\')
,'\\\\[|\\\\]','')第三步:
按分号我们进行划分:
SELECT
split(
REGEXP_REPLACE(
REGEXP_REPLACE('["level":"2","time":1650973942596,"type":"0","level":"1","time":1650973942597,"type":"1","level":"3","time":1650973942598,"type":"2"]','\\\\\\\\,\\\\','\\\\\\\\;\\\\')
,'\\\\[|\\\\]','')
,'\\\\;')
第四步:
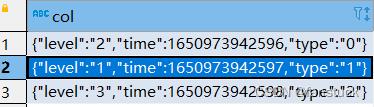
之后我们便可以使用explode进行平铺了:
select
explode(
split(
REGEXP_REPLACE(
REGEXP_REPLACE('["level":"2","time":1650973942596,"type":"0","level":"1","time":1650973942597,"type":"1","level":"3","time":1650973942598,"type":"2"]','\\\\\\\\,\\\\','\\\\\\\\;\\\\')
,'\\\\[|\\\\]','')
,'\\\\;')
) 
第五步:
最后在此表的基础之上我们再使用get_json_object或者json_tuple函数就好了:
SELECT
GET_JSON_OBJECT(track,'$.level') as level,
GET_JSON_OBJECT(track,'$.time') as times,
GET_JSON_OBJECT(track,'$.type') as types
from (
select
explode(
split(
REGEXP_REPLACE(
REGEXP_REPLACE('["level":"2","time":1650973942596,"type":"0","level":"1","time":1650973942597,"type":"1","level":"3","time":1650973942598,"type":"2"]','\\\\\\\\,\\\\','\\\\\\\\;\\\\')
,'\\\\[|\\\\]','')
,'\\\\;')
)track )track 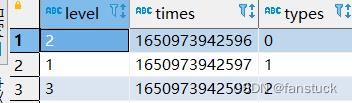
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
以上是关于一文速学-HiveSQL解析JSON数据详解+代码实战的主要内容,如果未能解决你的问题,请参考以下文章