21天学习挑战赛—Python学习记录第一篇
Posted Goodric
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了21天学习挑战赛—Python学习记录第一篇相关的知识,希望对你有一定的参考价值。
21天学习挑战赛—Python学习记录第一篇
——
活动地址:CSDN21天学习挑战赛
————
前言
一名大学牲,参与本次21天学习挑战赛,一个是为了充实自己的暑假,不在暑假过度放松,第二个就是想要去学会 python 这门语言了。
自己的专业方向是网络安全,不过只要是计算机类都是多多少少需要掌握一两门语言吧。而 python语言,就是大部分人都会去选择的语言,同时也是我所选择的。
在这之前,也有一点点的 python 基础,会写一些简单的语法。相比其它语言,python 的语法格式还是更为简洁的,用起来也很方便,希望在后面的学习中能够对 python 有更多的理解与掌握。
————
学习计划
每周三次以上学习,每次学习记录做好笔记。并完成每周三次发博文任务。
—————
正则表达式学习
正则表达式已经内嵌在Python中,通过import re模块就可以使用。
作用:
进行检索字符串,对某些字符进行匹配等
使用场景:
爬虫爬取数据时、数据开发、文本检索和数据筛选
——
运算符优先级
各正则表达式运算符的优先级顺序:
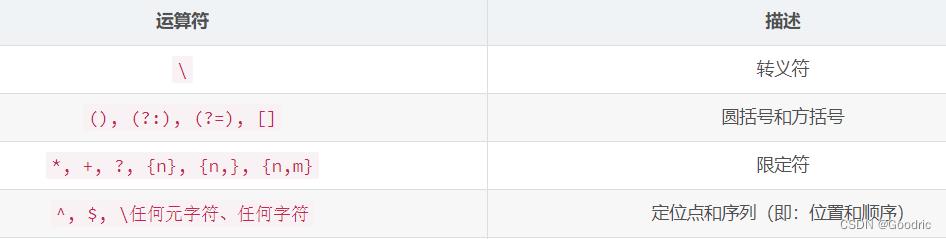
相同优先级的从左到右进行运算,不同优先级的运算先高后低
——
re模块使用
需要通过正则表达式对字符串进行匹配的时候,就要用到这个模块。
match方法基本使用:
re.match(pattern, string, flags=0)
pattern: 匹配的正则表达式。
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
例子:
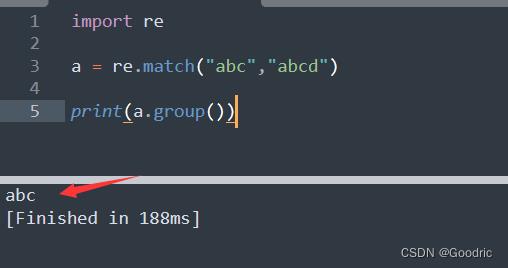
import re
a = re.match("abc","abcd")
print(a.group())
match方法进行匹配。group 方法进行提取匹配到的数据。
在match() 函数中,表示我要在 abcd 字符串中匹配 abc 字符串,然后结果就在 abcd 中匹配到了 abc 。实际中,"abc"位置表示的正则表达式可能并没有这么简单,可能有很多的运算符。
——
匹配单个字符
——
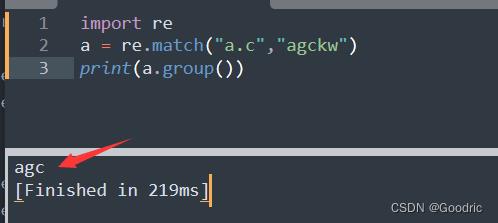
"."的用法
.: 匹配除 “\\n” 之外的任何单个字符。要匹配包括 ‘\\n’ 在内的任何字符,使用象 ‘[.\\n]’ 的模式。
测试例子:
import re
a = re.match("a.c","agckw")
print(a.group())
——
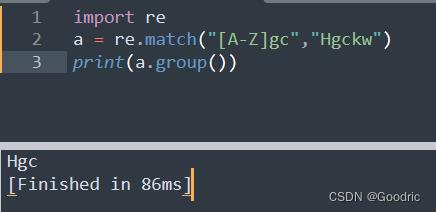
[ ] 的用法
[...]: 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’
测试例子:
import re
a = re.match("[A-Z]gc","Hgckw")
print(a.group())
——
\\d 的用法
\\d: 匹配任意数字,等价于 [0-9]。
测试例子:
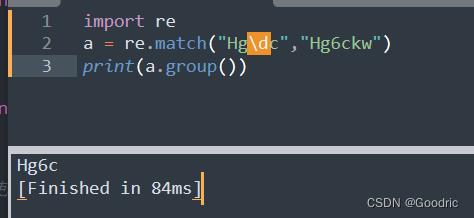
import re
a = re.match("Hg\\dc","Hg6ckw")
print(a.group())
单字符匹配的字符:
. :匹配除 “\\n” 之外的任何单个字符。要匹配包括‘\\n’在内的任何字符,请使用象‘[.\\n]’的模式。
[...]:用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’
\\w:匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]'。
\\W:匹配任何非单词字符。等价于‘[^A-Za-z0-9_]’。
\\s:匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \\f\\n\\r\\t\\v]。
\\S:匹配任何非空白字符。等价于[^ \\f\\n\\r\\t\\v]。
\\d:匹配任意数字,等价于[0-9]。
\\D:匹配一个非数字字符。等价于[^0-9]。
————
——
匹配多个字符
——
* 的用法
*: 匹配前一个字符出现0次或者无限次,即可有可无
测试例子:
import re
a = re.match("[a-z]*","abcdYFK")
print(a.group())
即匹配任意个小写字母

——
m和m,n用法
m: 匹配前一个字符出现m次
m,n: 匹配前一个字符出现从m到n次
测试例子:
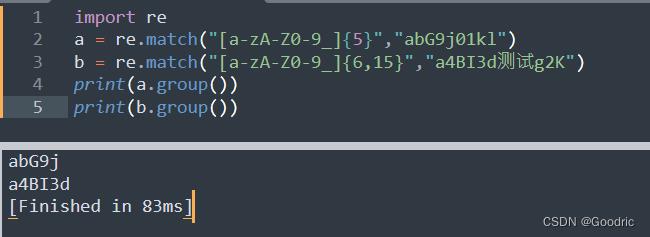
import re
a = re.match("[a-zA-Z0-9_]5","abG9j01kl")
b = re.match("[a-zA-Z0-9_]6,15","a4BI3d测试g2K")
print(a.group())
print(b.group())
*:匹配前一个字符出现0次或者无限次,即可有可无
+:匹配前一个字符出现1次或者无限次,即至少有1次
?:匹配前一个字符出现1次或者0次,即要么有1次,要么没有
m:匹配前一个字符出现m次
m,n:匹配前一个字符出现从m到n次
——
匹配开头结尾
^: 匹配字符串的开头
$: 匹配字符串的末尾。
测试例子:
import re
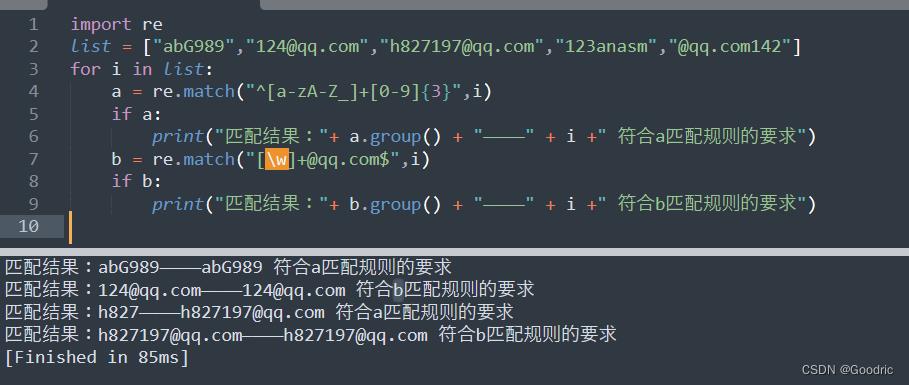
list = ["abG989","124@qq.com","h827197@qq.com","123anasm","@qq.com142"]
for i in list:
a = re.match("^[a-zA-Z_]+[0-9]3",i)
if a:
print("匹配结果:"+ a.group() + "————" + i +" 符合a匹配规则的要求")
b = re.match("[\\w]+@qq.com$",i)
if b:
print("匹配结果:"+ b.group() + "————" + i +" 符合b匹配规则的要求")
这里有a , b两个匹配要求,
a匹配规则中 ^[a-zA-Z_]+[0-9]3 要求开头是一个以上的字母,再匹配三个数字。
b匹配规则中 [\\w]+@qq.com$ 要求必须以@qq.com 结尾,前面匹配一个以上包括下划线的任何单词字符。
其中用到了
\\w: 匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]'。
+:匹配前一个字符出现1次或者无限次,即至少有1次
其它的一些运算符:
\\A:匹配字符串开始
\\z:匹配字符串结束
\\Z:匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。
\\G:匹配最后匹配完成的位置。
\\b:匹配一个单词边界,也就是指单词和空格间的位置。例如,‘er\\b’可以匹配"never"中的‘er’,但不能匹配“verb”中的‘er’。
\\B:匹配非单词边界。‘er\\B’能匹配“verb”中的‘er’,但不能匹配“never”中的‘er’。
————
注:
匹配字符的例子先到这里,不过我还学习到一个问题。
match函数只能从头开始匹配,不能从中间开始。而当返回值为none时,再次调用group()方法就会出现AttributeError: 'NoneType' object has no attribute 'group'这类报错。

——
——
re模块其它方法函数的学习与使用
——
re.search的用法
扫描整个字符串并返回第一个成功的匹配;匹配成功re.search方法返回一个匹配的对象,否则返回None。
函数语法:
re.search(pattern, string, flags=0)
pattern: 匹配的正则表达式
string: 要匹配的字符串。
flags: 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。
前面说到match函数只能从头开始匹配 ,如果字符串开始不符合正则表达式,则匹配失败。
而用 re.search 就可以从中间匹配了。
测试例子:
import re
a = re.search("[0-9]3","abc123wnf")
print(a.group())

——
re.findall 的用法
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
语法和前面的search和match类似。
re.findall(pattern, string, flags=0)
重点在可以匹配多个结果。
匹配三个数字,返回一个列表,包含所有符合的匹配结果。
测试例子:
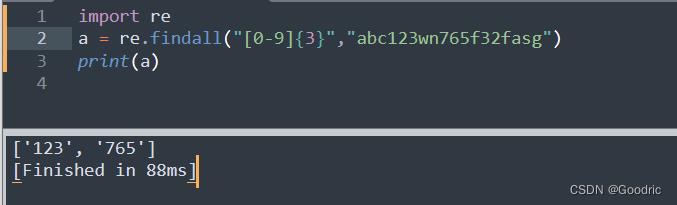
import re
a = re.findall("[0-9]3","abc123wn765f32fasg")
print(a)
以上是关于21天学习挑战赛—Python学习记录第一篇的主要内容,如果未能解决你的问题,请参考以下文章