湖仓一体电商项目:3万字带你从头开始搭建12个大数据项目基础组件
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了湖仓一体电商项目:3万字带你从头开始搭建12个大数据项目基础组件相关的知识,希望对你有一定的参考价值。

文章目录
3、将配置好的zookeeper发送到node4,node5节点
4、各个节点上创建数据目录,并配置zookeeper环境变量
2、上传下载好的Hadoop安装包到node1节点上,并解压
4、配置$HADOOP_HOME/etc/hadoop下的hadoop-env.sh文件
5、配置$HADOOP_HOME/etc/hadoop下的hdfs-site.xml文件
6、配置$HADOOP_HOME/ect/hadoop/core-site.xml
7、配置$HADOOP_HOME/etc/hadoop/yarn-site.xml
8、配置$HADOOP_HOME/etc/hadoop/mapred-site.xml
9、配置$HADOOP_HOME/etc/hadoop/workers文件
10、配置$HADOOP_HOME/sbin/start-dfs.sh 和stop-dfs.sh两个文件中顶部添加以下参数,防止启动错误
11、配置$HADOOP_HOME/sbin/start-yarn.sh和stop-yarn.sh两个文件顶部添加以下参数,防止启动错误
13、在node2、node3、node4、node5节点上配置HADOOP_HOME
1、将下载好的Hive安装包上传到node1节点上,并修改名称
4、在node1节点$HIVE_HOME/conf下创建hive-site.xml并配置
5、在node3节点$HIVE_HOME/conf/中创建hive-site.xml并配置
6、node1、node3节点删除$HIVE_HOME/lib下“guava”包,使用Hadoop下的包替换
7、将“mysql-connector-java-5.1.47.jar”驱动包上传到node1节点的$HIVE_HOME/lib目录下
2、Hive中操作Iceberg格式表
1、将下载好的安装包发送到node4节点上,并解压,配置环境变量
2、配置$HBASE_HOME/conf/hbase-env.sh
3、配置$HBASE_HOME/conf/hbase-site.xml
4、配置$HBASE_HOME/conf/regionservers,配置RegionServer节点
6、复制hdfs-site.xml到$HBASE_HOME/conf/下
7、将HBase安装包发送到node3,node5节点上,并在node3,node5节点上配置HBase环境变量
8、重启Zookeeper、重启HDFS及启动HBase集群
4、复制core-site.xml、hdfs-site.xml、hbase-site.xml到Phoenix
4、修改node2,node3节点上的server.properties文件
7、准备“flink-shaded-hadoop-2-uber-2.8.3-10.0.jar”包
1、首先将Flume上传到Mynode5节点/software/路径下,并解压,命令如下:
1、选择三台clickhouse节点,在每台节点上安装clickhouse需要的安装包
5、在每台节点上启动/查看/重启/停止clickhouse服务
上篇已经大概讲述大数据组件版本和集群矩阵配置说明,有不清楚的同学,可以阅读上一篇
湖仓一体电商项目(二):项目使用技术及版本和基础环境准备_Lansonli的博客-CSDN博客
接下带大家一一搭建项目基础组件
一、搭建Zookeeper
这里搭建zookeeper版本为3.4.13,搭建zookeeper对应的角色分布如下:
| 节点IP | 节点名称 | Zookeeper |
| 192.168.179.4 | node1 | |
| 192.168.179.5 | node2 | |
| 192.168.179.6 | node3 | ★ |
| 192.168.179.7 | node4 | ★ |
| 192.168.179.8 | node5 | ★ |
具体搭建步骤如下:
1、上传zookeeper并解压,配置环境变量
在node1,node2,node3,node4,node5各个节点都创建/software目录,方便后期安装技术组件使用。
mkdir /software将zookeeper安装包上传到node3节点/software目录下并解压:
[root@node3 software]# tar -zxvf ./zookeeper-3.4.13.tar.gz 在node3节点配置环境变量:
#进入vim /etc/profile,在最后加入:
export ZOOKEEPER_HOME=/software/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效
source /etc/profile2、在node3节点配置zookeeper
进入“/software/zookeeper-3.4.13/conf”修改zoo_sample.cfg为zoo.cfg
[root@node3 conf]# mv zoo_sample.cfg zoo.cfg配置zoo.cfg中内容如下:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/opt/data/zookeeper
clientPort=2181
server.1=node3:2888:3888
server.2=node4:2888:3888
server.3=node5:2888:3888
3、将配置好的zookeeper发送到node4,node5节点
[root@node3 software]# scp -r ./zookeeper-3.4.13 node4:/software/
[root@node3 software]# scp -r ./zookeeper-3.4.13 node5:/software/4、各个节点上创建数据目录,并配置zookeeper环境变量
在node3,node4,node5各个节点上创建zoo.cfg中指定的数据目录“/opt/data/zookeeper”。
mkdir -p /opt/data/zookeeper在node4,node5节点配置zookeeper环境变量
#进入vim /etc/profile,在最后加入:
export ZOOKEEPER_HOME=/software/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#使配置生效
source /etc/profile
5、各个节点创建节点ID
在node3,node4,node5各个节点路径“/opt/data/zookeeper”中添加myid文件分别写入1,2,3:
#在node3的/opt/data/zookeeper中创建myid文件写入1
#在node4的/opt/data/zookeeper中创建myid文件写入2
#在node5的/opt/data/zookeeper中创建myid文件写入3
6、各个节点启动zookeeper,并检查进程状态
#各个节点启动zookeeper命令
zkServer.sh start
#检查各个节点zookeeper进程状态
zkServer.sh status二、搭建HDFS
这里搭建HDFS版本为3.1.4,搭建HDFS对应的角色在各个节点分布如下:
| 节点IP | 节点名称 | NN | DN | ZKFC | JN | RM | NM |
| 192.168.179.4 | node1 | ★ | ★ | ★ | |||
| 192.168.179.5 | node2 | ★ | ★ | ★ | |||
| 192.168.179.6 | node3 | ★ | ★ | ★ | |||
| 192.168.179.7 | node4 | ★ | ★ | ★ | |||
| 192.168.179.8 | node5 | ★ | ★ | ★ |
搭建具体步骤如下:
1、各个节点安装HDFS HA自动切换必须的依赖
yum -y install psmisc2、上传下载好的Hadoop安装包到node1节点上,并解压
[root@node1 software]# tar -zxvf ./hadoop-3.1.4.tar.gz3、在node1节点上配置Hadoop的环境变量
[root@node1 software]# vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.1.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#使配置生效
source /etc/profile4、配置$HADOOP_HOME/etc/hadoop下的hadoop-env.sh文件
#导入JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
5、配置$HADOOP_HOME/etc/hadoop下的hdfs-site.xml文件
<configuration>
<property>
<!--这里配置逻辑名称,可以随意写 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- 禁用权限 -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 配置namenode 的名称,多个用逗号分割 -->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<!-- namenode 共享的编辑目录, journalnode 所在服务器名称和监听的端口 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<property>
<!-- namenode高可用代理类 -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 使用ssh 免密码自动登录 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- journalnode 存储数据的地方 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal/node/local/data</value>
</property>
<property>
<!-- 配置namenode自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>6、配置$HADOOP_HOME/ect/hadoop/core-site.xml
<configuration>
<property>
<!-- 为Hadoop 客户端配置默认的高可用路径 -->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可
namenode 默认存放路径 :file://$hadoop.tmp.dir/dfs/name
datanode 默认存放路径 :file://$hadoop.tmp.dir/dfs/data
-->
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>ha.zookeeper.quorum</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
</configuration>7、配置$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<!-- 配置yarn为高可用 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 集群的唯一标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<property>
<!-- ResourceManager ID -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
<property>
<!-- 关闭虚拟内存检查 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 启用节点的内容和CPU自动检测,最小内存为1G -->
<!--<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>-->
</configuration>8、配置$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>9、配置$HADOOP_HOME/etc/hadoop/workers文件
[root@node1 ~]# vim /software/hadoop-3.1.4/etc/hadoop/workers
node3
node4
node510、配置$HADOOP_HOME/sbin/start-dfs.sh 和stop-dfs.sh两个文件中顶部添加以下参数,防止启动错误
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root
11、配置$HADOOP_HOME/sbin/start-yarn.sh和stop-yarn.sh两个文件顶部添加以下参数,防止启动错误
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
12、将配置好的Hadoop安装包发送到其他4个节点
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node2:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node3:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node4:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node5:/software/
13、在node2、node3、node4、node5节点上配置HADOOP_HOME
#分别在node2、node3、node4、node5节点上配置HADOOP_HOME
vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.1.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#最后记得Source
source /etc/profile
14、启动HDFS和Yarn
#在node3,node4,node5节点上启动zookeeper
zkServer.sh start
#在node1上格式化zookeeper
[root@node1 ~]# hdfs zkfc -formatZK
#在每台journalnode中启动所有的journalnode,这里就是node3,node4,node5节点上启动
hdfs --daemon start journalnode
#在node1中格式化namenode
[root@node1 ~]# hdfs namenode -format
#在node1中启动namenode,以便同步其他namenode
[root@node1 ~]# hdfs --daemon start namenode
#高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在node2上执行):
[root@node2 software]# hdfs namenode -bootstrapStandby
#node1上启动HDFS,启动Yarn
[root@node1 sbin]# start-dfs.sh
[root@node1 sbin]# start-yarn.sh注意以上也可以使用start-all.sh命令启动Hadoop集群。
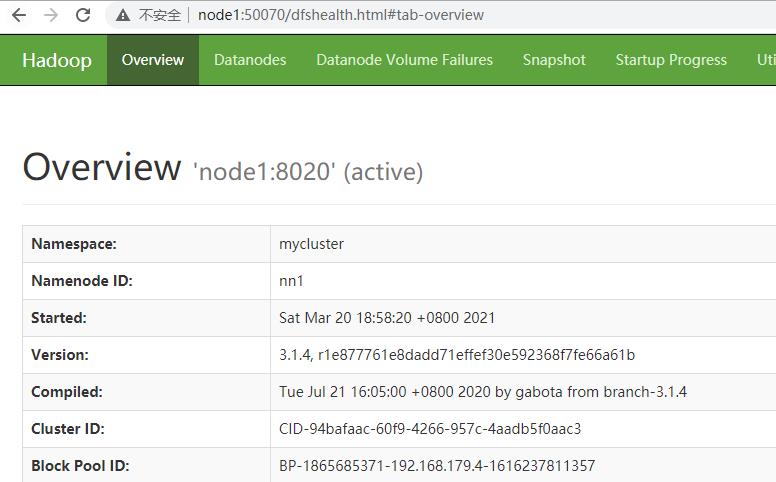
15、访问WebUI
访问HDFS : http://node1:50070
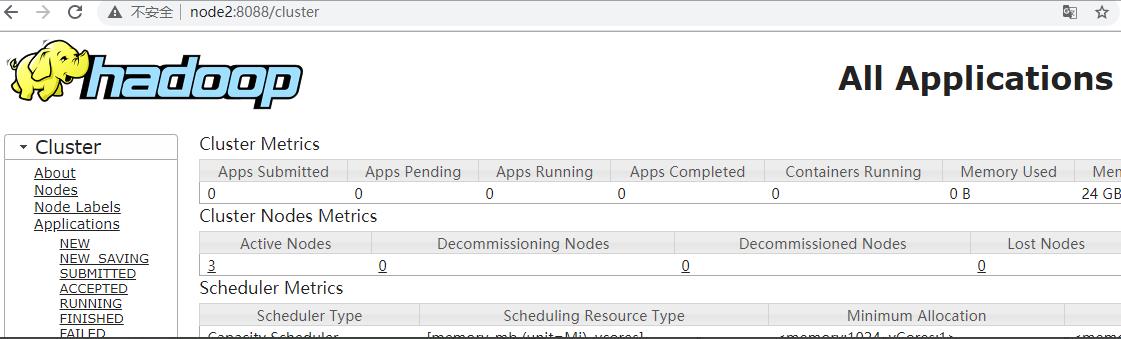
访问Yarn WebUI :http://node1:8088
16、停止集群
#停止集群
[root@node1 ~]# stop-dfs.sh
[root@node1 ~]# stop-yarn.sh
注意:以上也可以使用 stop-all.sh 停止集群。
三、搭建Hive
这里搭建Hive的版本为3.1.2,搭建Hive的节点划分如下:
| 节点IP | 节点名称 | Hive服务器 | Hive客户端 | MySQL |
| 192.168.179.4 | node1 | ★ | ||
| 192.168.179.5 | node2 | ★(已搭建) | ||
| 192.168.179.6 | node3 | ★ |
搭建具体步骤如下:
1、将下载好的Hive安装包上传到node1节点上,并修改名称
[root@node1 ~]# cd /software/
[root@node1 software]# tar -zxvf ./apache-hive-3.1.2-bin.tar.gz
[root@node1 software]# mv apache-hive-3.1.2-bin hive-3.1.2
2、将解压好的Hive安装包发送到node3节点上
[root@node1 ~]# scp -r /software/hive-3.1.2/ node3:/software/
3、配置node1、node3两台节点的Hive环境变量
vim /etc/profile
export HIVE_HOME=/software/hive-3.1.2/
export PATH=$PATH:$HIVE_HOME/bin
#source 生效
source /etc/profile
4、在node1节点$HIVE_HOME/conf下创建hive-site.xml并配置
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node2:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>5、在node3节点$HIVE_HOME/conf/中创建hive-site.xml并配置
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>6、node1、node3节点删除$HIVE_HOME/lib下“guava”包,使用Hadoop下的包替换
#删除Hive lib目录下“guava-19.0.jar ”包
[root@node1 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar
[root@node3 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar
#将Hadoop lib下的“guava”包拷贝到Hive lib目录下
[root@node1 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/
[root@node3 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/7、将“mysql-connector-java-5.1.47.jar”驱动包上传到node1节点的$HIVE_HOME/lib目录下
上传后,需要将mysql驱动包传入$HIVE_HOME/lib/目录下,这里node1,node3节点都需要传入。
8、在node1节点中初始化Hive
#初始化hive,hive2.x版本后都需要初始化
[root@node1 ~]# schematool -dbType mysql -initSchema9、在服务端和客户端操作Hive
#在node1中登录Hive ,创建表test
[root@node1 conf]# hive
hive> create table test (id int,name string,age int ) row format delimited fields terminated by '\\t';
#向表test以上是关于湖仓一体电商项目:3万字带你从头开始搭建12个大数据项目基础组件的主要内容,如果未能解决你的问题,请参考以下文章