像写SQL一样去处理内存中的数据,SparkSQL入门教程
Posted Java鱼仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了像写SQL一样去处理内存中的数据,SparkSQL入门教程相关的知识,希望对你有一定的参考价值。
(一)概述
SparkSQL可以理解为在原生的RDD上做的一层封装,通过SparkSQL可以在scala和java中写SQL语句,并将结果作为Dataset/DataFrame返回。简单来讲,SparkSQL可以让我们像写SQL一样去处理内存中的数据。
Dataset是一个数据的分布式集合,是Spark1.6之后新增的接口,它提供了RDD的优点和SparkSQL优化执行引擎的优点,一个Dataset相当于RDD+Schema的结合。
Dataset的底层封装是RDD,当RDD的泛型是Row类型时,该类型就可以称为DataFrame。DataFrame是一种表格型的数据结构,就和传统的mysql结构一样,通过DataFrame我们可以更加高效地去执行Sql。
(二)SparkSQL实战
使用SparkSQL首先需要引入相关的依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
该依赖需要和sparkCore保持一致。
SparkSQL的编码主要通过四步:
- 创建SparkSession
- 获取数据
- 执行SQL
- 关闭SparkSession
public class SqlTest
public static void main(String[] args)
SparkSession sparkSession = SparkSession.builder()
.appName("sql")
.master("local")
.getOrCreate();
Dataset<Row> json = sparkSession.read().json("data/json");
json.printSchema();
json.show();
sparkSession.stop();
在data的目录下创建一个名为json的文件
"name":"a","age":23
"name":"b","age":24
"name":"c","age":25
"name":"d","age":26
"name":"e","age":27
"name":"f","age":28
运行项目后输出两个结果,schema结果如下:
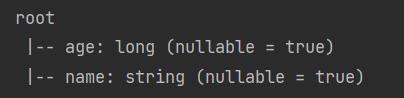
Dataset<Row>输出结果如下:
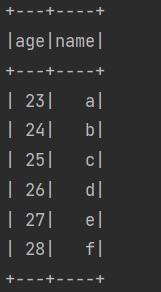
通过SparkSQL可以执行和SQL十分相似的查询操作:
public class SqlTest
public static void main(String[] args)
SparkSession sparkSession = SparkSession.builder()
.appName("sql")
.master("local")
.getOrCreate();
Dataset<Row> json = sparkSession.read().json("data/json");
json.select("age","name").where("age > 26").show();
sparkSession.stop();
在上面的语句中,通过一系列的API实现了SQL查询操作,除此之外,SparkSQL还支持直接写原始SQL语句的操作。
在写SQL语句之前,首先需要让Spark知道对哪个表进行查询,因此需要建立一张临时表,再执行SQL查询:
json.createOrReplaceTempView("json");
sparkSession.sql("select * from json where age > 26").show();
(三)非JSON格式的Dataset创建
在上一节中创建Dataset时使用了最简单的json,因为json自己带有schema结构,因此不需要手动去增加,如果是一个txt文件,就需要在创建Dataset时手动塞入schema。
下面展示读取txt文件的例子,首先创建一个user.txt
a 23
b 24
c 25
d 26
现在我要将上面的这几行变成DataFrame,第一列表示姓名,第二列表示年龄,于是就可以像下面这样操作:
public class SqlTest2
public static void main(String[] args)
SparkSession sparkSession = SparkSession.builder()
.appName("sql")
.master("local")
.getOrCreate();
SparkContext sparkContext = sparkSession.sparkContext();
JavaSparkContext sc = new JavaSparkContext(sparkContext);
JavaRDD<String> lines = sc.textFile("data/user.txt");
//将String类型转化为Row类型
JavaRDD<Row> rowJavaRDD = lines.map(new Function<String, Row>()
@Override
public Row call(String v1) throws Exception
String[] split = v1.split(" ");
return RowFactory.create(
split[0],
Integer.valueOf(split[1])
);
);
//定义schema
List<StructField> structFields = Arrays.asList(
DataTypes.createStructField("name", DataTypes.StringType, true),
DataTypes.createStructField("age", DataTypes.IntegerType, true)
);
StructType structType = DataTypes.createStructType(structFields);
//生成dataFrame
Dataset<Row> dataFrame = sparkSession.createDataFrame(rowJavaRDD, structType);
dataFrame.show();
(四)通过JDBC创建DataFrame
通过JDBC可直接将对应数据库中的表放入Spark中进行一些处理,下面通过MySQL进行展示。
使用MySQL需要在依赖中引入MySQL的引擎:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
接着通过类似JDBC的方式读取MySQL数据:
public class SqlTest3
public static void main(String[] args)
SparkSession sparkSession = SparkSession.builder()
.appName("sql")
.master("local")
.getOrCreate();
Map<String,String> options = new HashMap<>();
options.put("url","jdbc:mysql://127.0.0.1:3306/books");
options.put("driver","com.mysql.jdbc.Driver");
options.put("user","root");
options.put("password","123456");
options.put("dbtable","book");
Dataset<Row> jdbc = sparkSession.read().format("jdbc").options(options).load();
jdbc.show();
sparkSession.close();
读取到的数据是DataFrame,接下来的操作就是对DataFrame的操作了。
(五)总结
SparkSQL是对Spark原生RDD的增强,虽然很多功能通过RDD就可以实现,但是SparkSQL可以更加灵活地实现一些功能。我是鱼仔,我们下期再见。
以上是关于像写SQL一样去处理内存中的数据,SparkSQL入门教程的主要内容,如果未能解决你的问题,请参考以下文章