Elasticsearch:Apache spark 大数据集成
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:Apache spark 大数据集成相关的知识,希望对你有一定的参考价值。
Elasticsearch 已成为大数据架构中的常用组件,因为它提供了以下几个特性:
- 它使你可以快速搜索大量数据。
- 对于常见的聚合操作,它提供对大数据的实时分析。
- 使用 Elasticsearch 聚合比使用 Spark 聚合更容易。
- 如果你需要转向快速数据解决方案,在查询后从文档子集开始比对所有数据进行全面重新扫描要快。
用于处理数据的最常见的大数据软件现在是 Apache Spark (http://spark.apache.org/),它被认为是过时的 Hadoop MapReduce 的演变,用于将处理从磁盘移动到内存。
在本中,我们将看到如何将 Elasticsearch 集成到 Spark 中,用于写入和读取数据。 最后,我们将看到如何使用 Apache Pig 以一种简单的方式在Elasticsearch 中写入数据。
安装 Spark
要使用 Apache Spark,我们需要安装它。 这个过程非常简单,因为它的要求不是需要 Apache ZooKeeper 和 Hadoop 分布式文件系统 (HDFS) 的传统 Hadoop。 Apache Spark 可以在类似于 Elasticsearch 的独立节点安装中工作。
要安装 Apache Spark,我们将执行以下步骤:
1)从 https://spark.apache.org/downloads.html 下载二进制发行版。 对于一般用途,我建议你使用以下请求下载标准版本:
wget https://www.apache.org/dyn/closer.lua/spark/spark-3.3.0/spark-3.3.0-bin-hadoop3.tgz2)现在,我们可以使用 tar 提取 Spark 分发包,如下所示:
tar xzvf spark-3.3.0-bin-hadoop3.tgz3)现在,我们可以通过执行测试来测试 Apache Spark 是否正常工作,如下:
$ cd spark-3.3.0-bin-hadoop3
$ ./bin/run-example SparkPi 10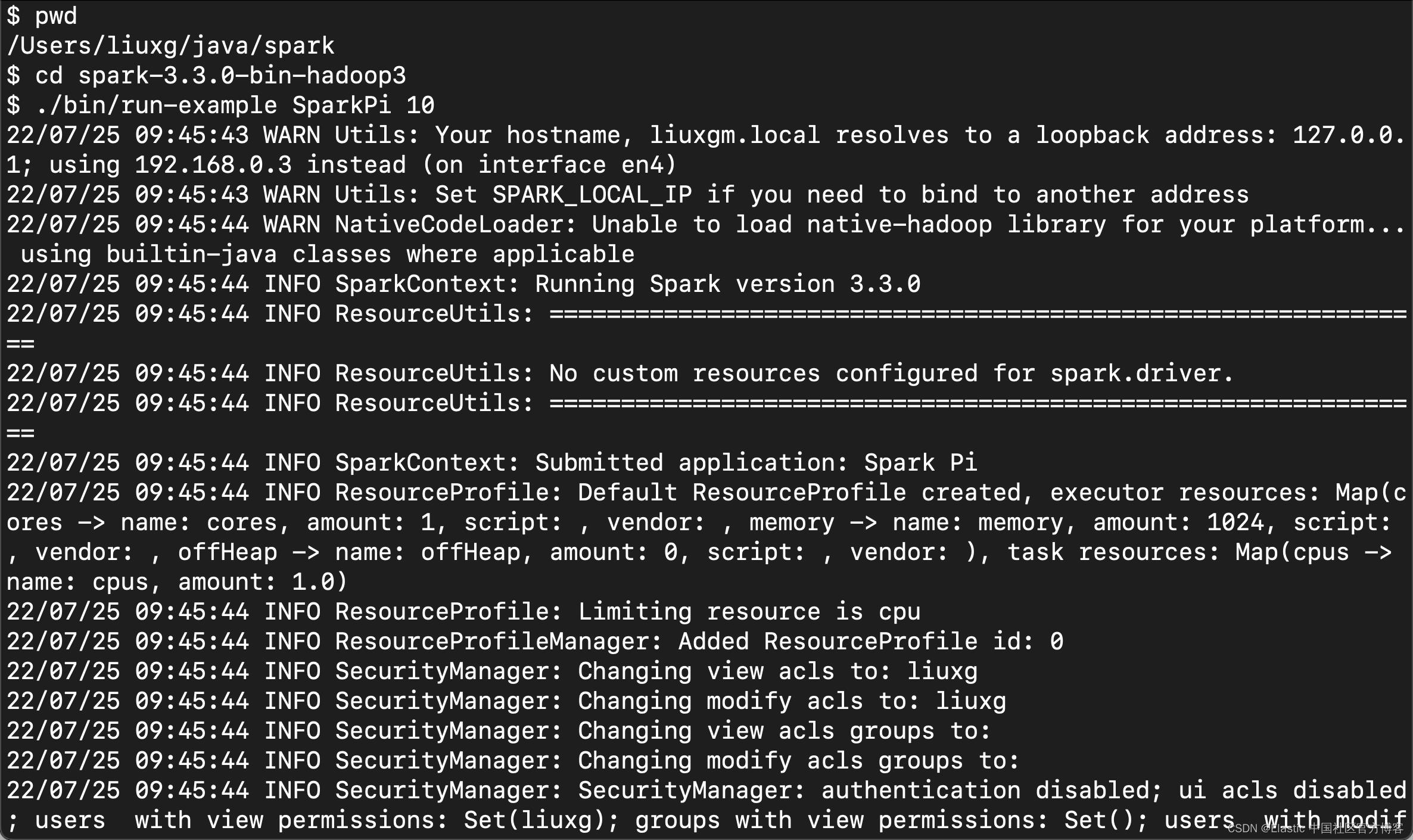
如果我们看到类似上面的输出,则标明我们的安装是成功的。
我们甚至可以之前启动 Spark Shell:
./bin/spark-shell 
现在,可以插入要在集群中执行的命令行命令。
安装 Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参阅如下的文章:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
- Elasticsearch:设置 Elastic 账户安全
在今天的展示中,我将使用最新的 Elastic Stack 8.3.2 来进行展示。为了演示的方便,我们在安装 Elasticsearch 时,可以选择不启动 HTTPS 的访问。为此,我们可以参照之前的文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单” 中的 “如何配置 Elasticsearch 只带有基本安全” 一节来进行安装。当我们安装好 Elasticsearch 及 Kibana 后,我们只需使用用户名及密码来进行访问。为了说明问题的方便,我们的超级用户 elastic 的密码设置为 password。
使用 Apache spark 摄入数据到 Elasticsearch
现在我们已经安装了 Apache Spark 及 Elasticsearch,我们可以将其配置为与 Elasticsearch 一起工作并在其中写入一些数据。现在我们已经安装了 Apache Spark,我们可以将其配置为与 Elasticsearch 一起工作并在其中写入一些数据。
1)我们需要下载 Elasticsearch Spark .jar 文件,如下:
wget https://repo1.maven.org/maven2/org/elasticsearch/elasticsearch-hadoop/8.3.2/elasticsearch-hadoop-8.3.2.zip
tar xzf elasticsearch-hadoop-8.3.2.zip或者,你也可以使用如下的方法来进行下载 elasticsearch-hadoop 安装包:
wget -c https://artifacts.elastic.co/downloads/elasticsearch-hadoop/elasticsearch-hadoop-8.3.2.zip
tar xzf elasticsearch-hadoop-8.3.2.zip2)在 Elasticsearch 中访问 Spark shell 的一种快速方法是复制 Spark 的 jar 目录中所需的 Elasticsearch Hadoop 文件。 必须复制的文件是 elasticsearch-spark-20_2.11-8.3.2.jar。
$ pwd
/Users/liuxg/java/spark/spark-3.3.0-bin-hadoop3/jars
$ ls elasticsearch-spark-20_2.11-8.3.2.jar
elasticsearch-spark-20_2.11-8.3.2.jar从上面的版本信息中,我们可以看出来 Scala 的版本信息是 2.11。 这个在我们下面 IDE 的开发环境中一定要注意。
要使用 Apache Spark 在 Elasticsearch 中存储数据,我们将执行以下步骤:
1)在 Spark 的根目录中,通过运行以下命令启动 Spark shell 以应用 Elasticsearch 配置:
./bin/spark-shell \\
--conf spark.es.index.auto.create=true \\
--conf spark.es.net.http.auth.user=$ES_USER \\
--conf spark.es.net.http.auth.pass=$ES_PASSWORD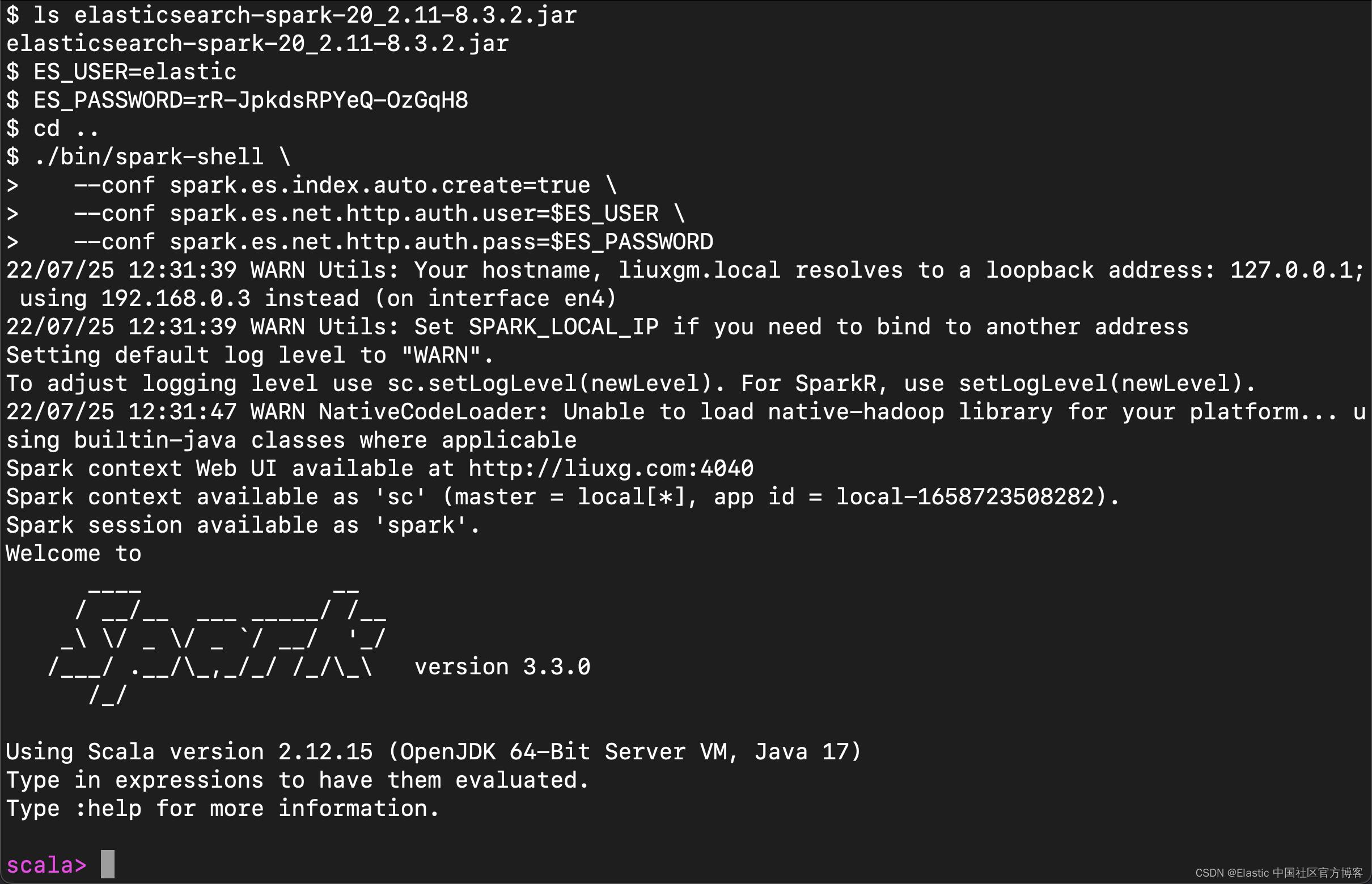
ES_USER 和 ES_PASSWORD 是保存 Elasticsearch 集群凭据的环境变量。
2)在使用 Elasticsearch 特殊的韧性分布式数据集 (Resilient Distributed Dataset - RDD) 之前,我们将导入 Elasticsearch Spark 隐式,如下:
import org.elasticsearch.spark._3)我们将创建两个要索引的文档,如下所示:
val numbers = Map("one" -> 1, "two" -> 2, "three" -> 3)
val airports = Map("arrival" -> "Otopeni", "SFO" -> "SanFran")4)现在,我们可以创建一个 RDD 并将文档保存在 Elasticsearch 中,如下所示:
sc.makeRDD(Seq(numbers, airports)).saveToEs("spark")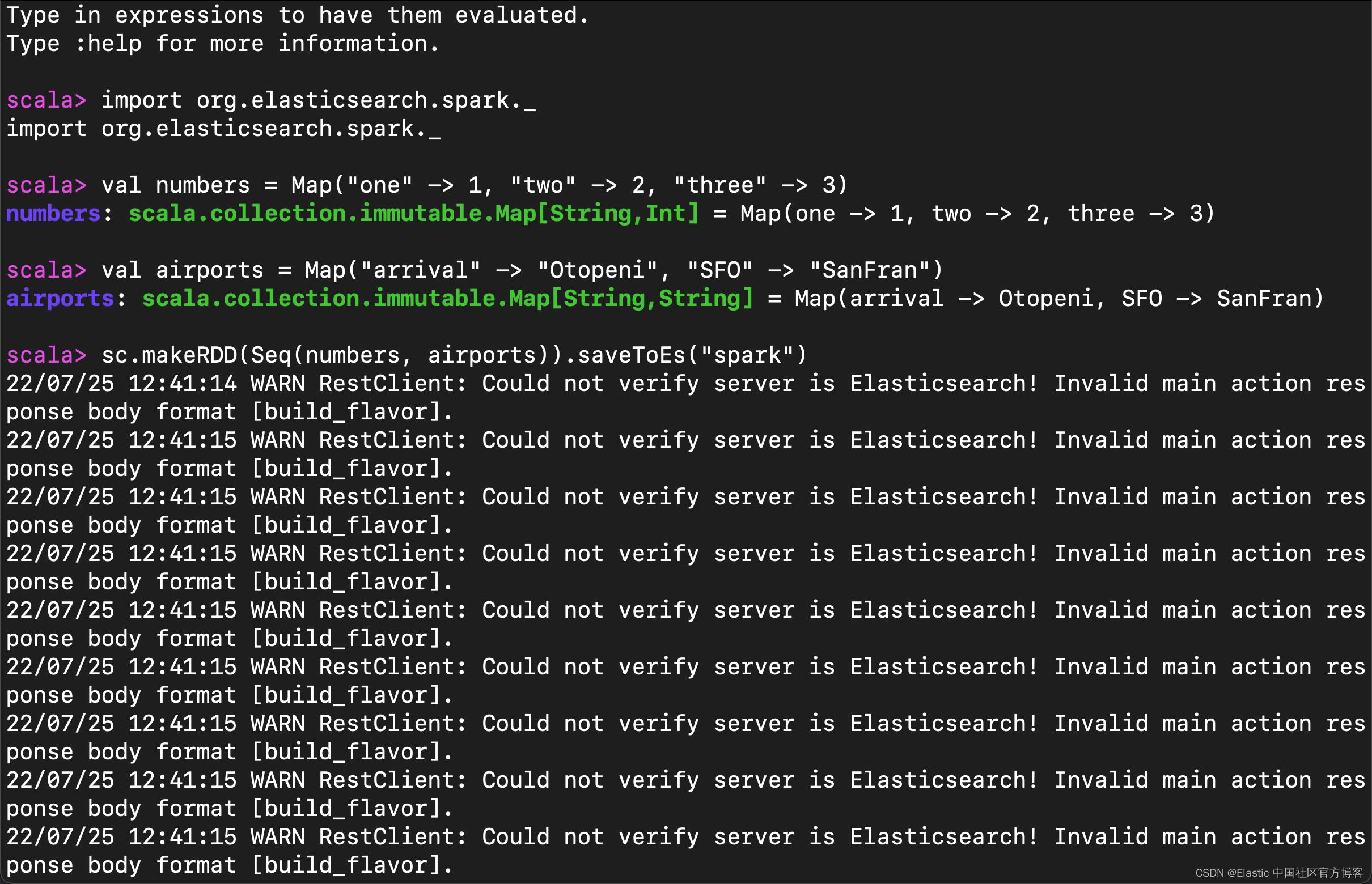
我们回到 Kibana 的界面进行查看:
GET spark/_search
从上面的输出中我们可以看出来有两个文档已经成功地写入到 Elasticsearch 中了。
上面是如何工作的?
通过 Spark 在 Elasticsearch 中存储文档非常简单。 在 shell 上下文中启动 Spark shell 后,sc 变量可用,其中包含 SparkContext。 如果我们需要将值传递给底层 Elasticsearch 配置,我们需要在 Spark shell 命令行中进行设置。
有几种配置可以设置(如果通过命令行传递,加 spark.前缀); 以下是最常用的:
- es.index.auto.create:如果索引不存在,则用于创建索引。
- es.nodes:这用于定义要连接的节点列表(默认本地主机)。
- es.port:用于定义要连接的 HTTP Elasticsearch 端口(默认 9200)。
- es.ingest.pipeline:用于定义要使用的摄取管道(默认无)。
- es.mapping.id:这个用来定义一个字段来提取ID值(默认无)。
- es.mapping.parent:这用于定义一个字段以提取父值(默认无)。
简单文档可以定义为 Map[String, AnyRef],并且可以通过 RDD(集合上的特殊 Spark 抽象)对它们进行索引。 通过 org.elasticsearch.spark 中可用的隐式函数,RDD 有一个名为 saveToEs 的新方法,允许你定义要用于索引的对索引或文档:
sc.makeRDD(Seq(numbers, airports)).saveToEs("spark")使用 meta 来写入数据
使用简单的 map 来摄取数据并不适合简单的工作。 Spark 中的最佳实践是使用案例类(case class),这样你就可以快速序列化并可以管理复杂的类型检查。 在索引期间,提供自定义 ID 会非常方便。 在下面,我们将看到如何涵盖这些问题。
要使用 Apache Spark 在 Elasticsearch 中存储数据,我们将执行以下步骤:
1)在 Spark 根目录中,通过运行以下命令启动 Spark shell 以应用 Elasticsearch 配置:
./bin/spark-shell \\
--conf spark.es.index.auto.create=true \\
--conf spark.es.net.http.auth.user=$ES_USER \\
--conf spark.es.net.http.auth.pass=$ES_PASSWORD2)我们将导入所需的类,如下所示:
import org.elasticsearch.spark.rdd.EsSpark3)我们将创建案例类 Person,如下:
case class Person(username:String, name:String, age:Int)4)我们将创建两个要被索引的文档,如下所示:
val persons = Seq(Person("bob", "Bob",19), Person("susan","Susan",21))5)现在,我们可以创建 RDD,如下:
val rdd=sc.makeRDD(persons)6)我们可以使用 EsSpark 对它们进行索引,如下所示:
EsSpark.saveToEs(rdd, "spark2", Map("es.mapping.id" -> "username"))
我们回到 Kibana 中来进行查看:
GET spark2/_search
从上面的输出中,我们可以看到有两个文档被成功地写入到 Elasticsearch 中,并且它们的 id 是 Person 中的 username。
通过 IDE 写入到 Elasticsearch 中
在这个练习中,我们使用 IDE 工具来进行展示。在这里,你可以选择自己喜欢的 IDE 来进行。我选择 Intelij 来展示。你需要安装 Scala 插件。我们来创建一个叫做 SparkDemo 的项目。它的 build.sbt 如下:
build.sbt
name := "SparkDemo"
version := "0.1"
scalaVersion := "2.11.12"
// https://mvnrepository.com/artifact/org.apache.spark/spark-core
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.3"
// https://mvnrepository.com/artifact/org.apache.spark/spark-sql
libraryDependencies += "org.apache.spark" %% "spark-sql" % "2.4.3"请注意上面的 2.11.12 scalaVersion。在上面,我们介绍了,elasticsearch-spark 在目前位置是使用 scala 2.11 版本来开发的。我们可以选择一个 Scala 的发行版本。我们需要使用到 spark-core 及 spark-sql 两个包。我们到地址 https://mvnrepository.com/artifact/org.apache.spark 来进行查看:
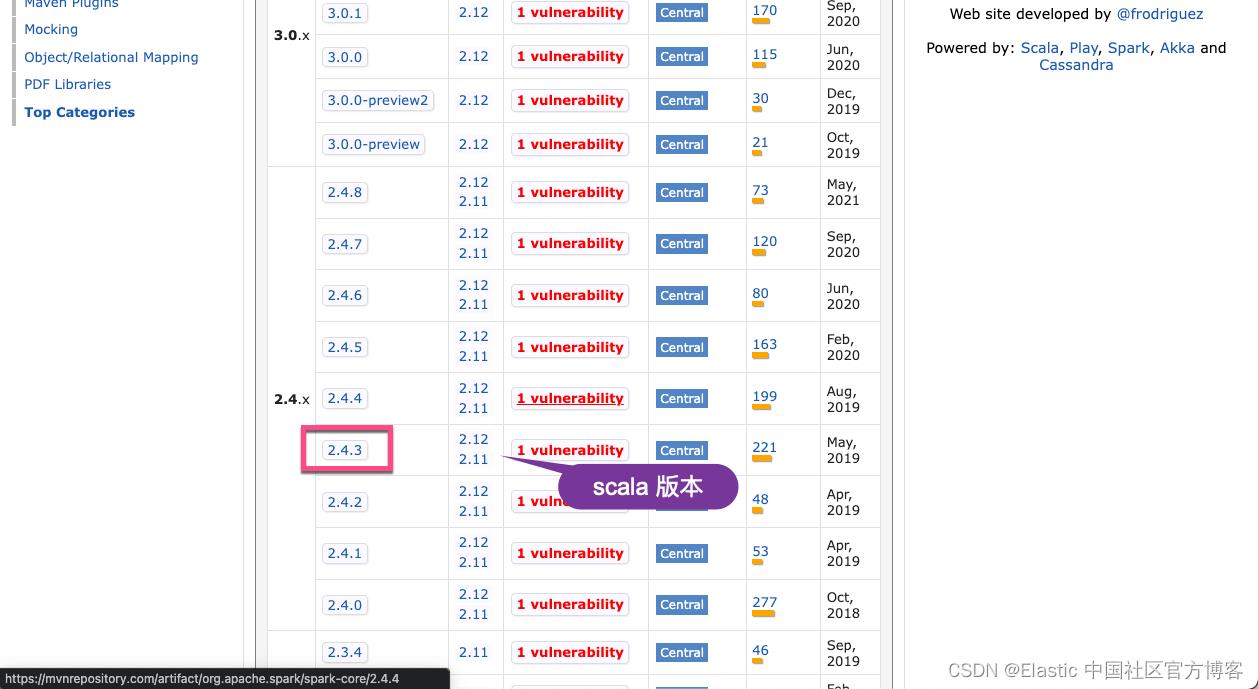

在上面,我们可以查看到 spark-core 的想要的版本依赖。依照同样的方法,我们可以找到 spark-sql 的依赖配置。
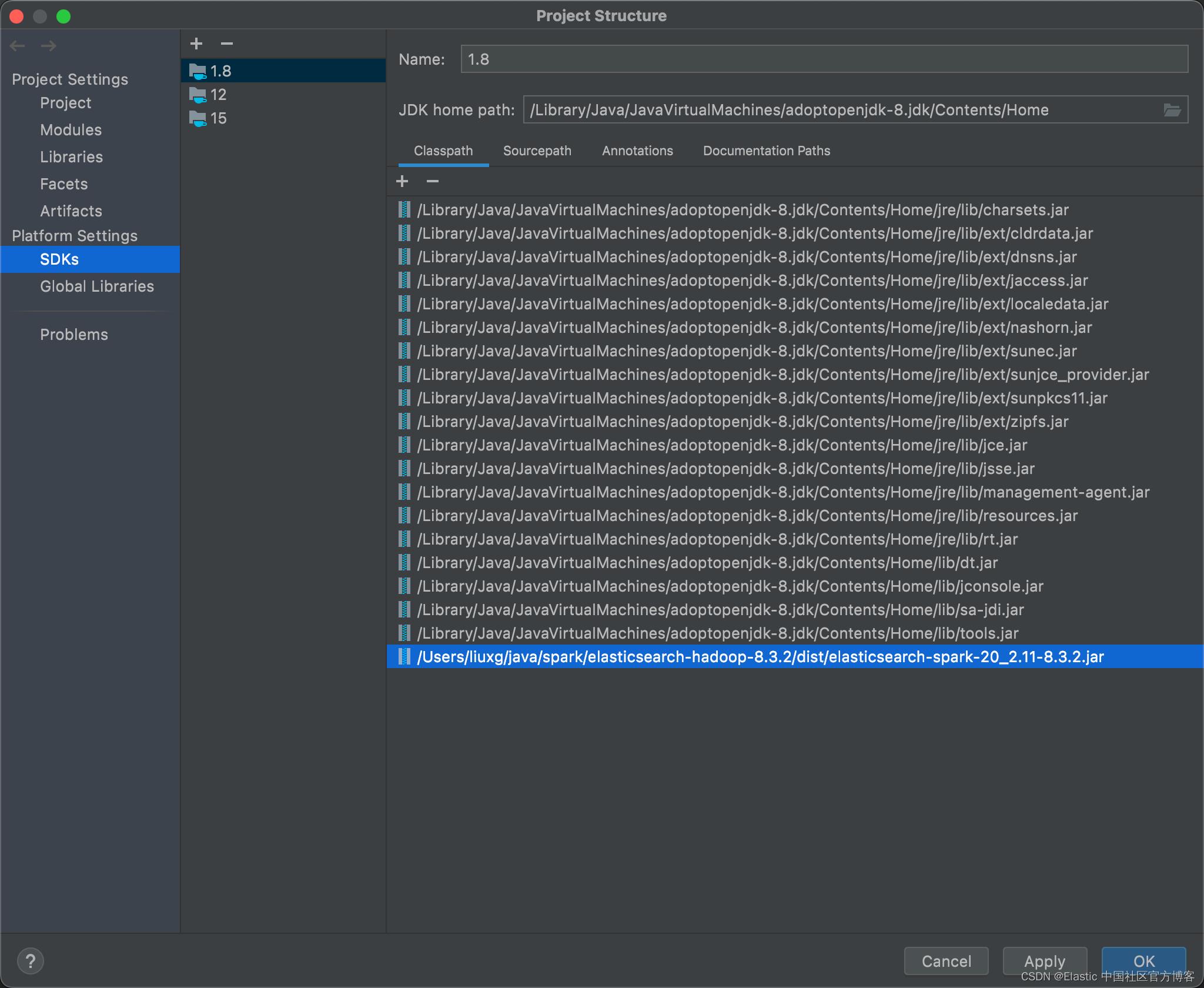
为了能够访问 Elasticsearch,我们也可以在 IDE 中直接加载我们之前下载的 elasticsearch-spark-20_2.11-8.3.2.jar 安装包:
我们接下来创建如下的 scala 文件:
SparkDemo.scala
import org.apache.spark.sql.SparkSession
import org.elasticsearch.spark.sql._
object SparkDemo
def main(args: Array[String]): Unit =
SparkDemo.writeToIndex()
def writeToIndex(): Unit =
val spark = SparkSession
.builder()
.appName("WriteToES")
.master("local[*]")
.config("spark.es.nodes","localhost")
.config("spark.es.port","9200")
.config("spark.es.nodes.wan.only","true") // Needed for ES on AWS
.config("spark.es.net.http.auth.user", "elastic")
.config("spark.es.net.http.auth.pass", "password")
.getOrCreate()
import spark.implicits._
val indexDocuments = Seq (
AlbumIndex("Led Zeppelin",1969,"Led Zeppelin"),
AlbumIndex("Boston",1976,"Boston"),
AlbumIndex("Fleetwood Mac", 1979,"Tusk")
).toDF
indexDocuments.saveToEs("albumindex")
case class AlbumIndex(artist:String, yearOfRelease:Int, albumName: String)请注意在上面我们定义 elastic 用户的密码为 password。你需要根据自己的配置进行相应的修改。运行上面的代码。运行完后,我们可以在 Kibana 中进行查看:
GET albumindex/_search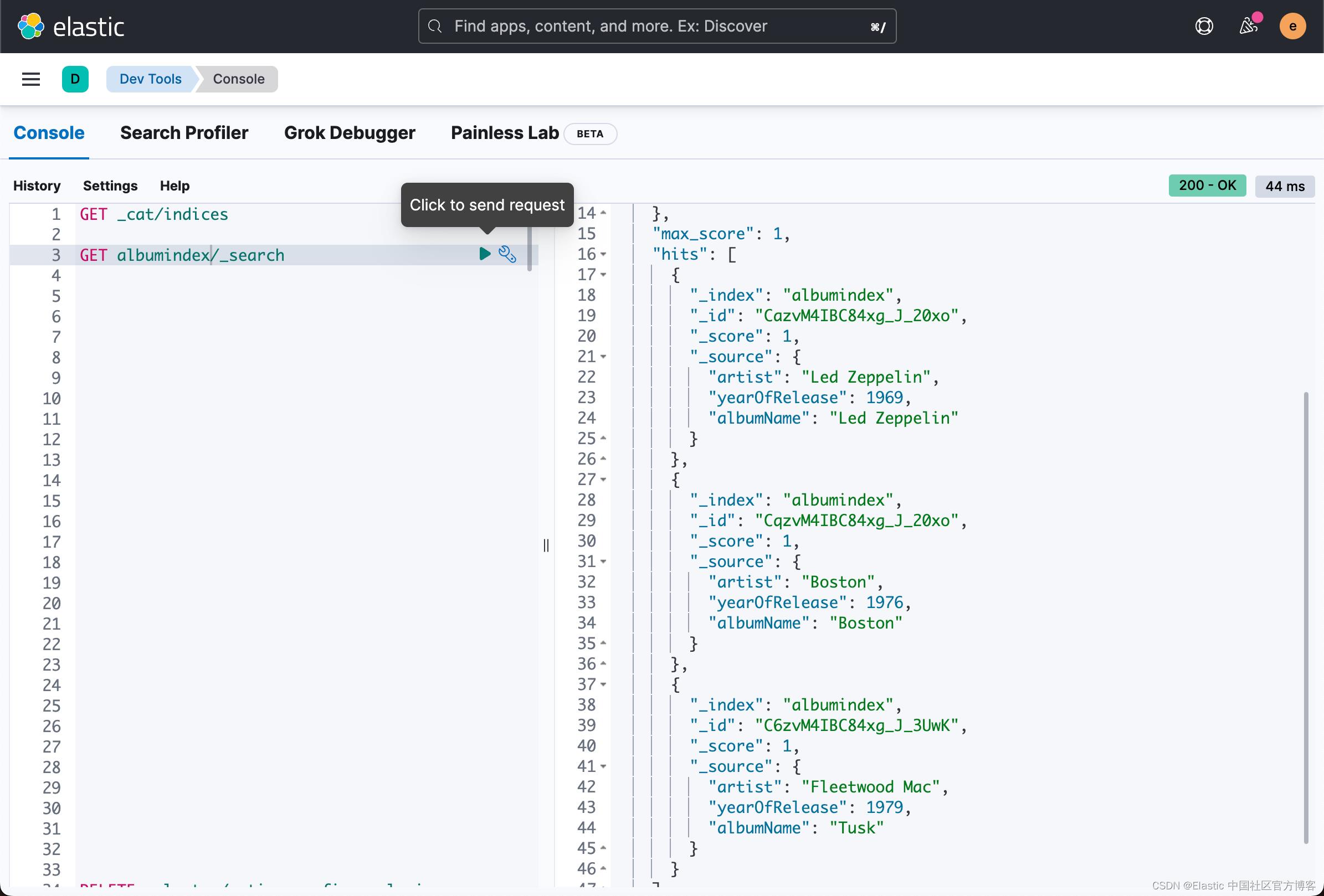
本质上,这个代码和我们在上面通过命令行来操作所生成的结果是一模一样的。它是通过 AlbumIndex 这个 case class 进行写入的。
把 JSON 文件写入到 Elasticsearch 中
我们接下来创建一个如下的 JSON 文件:
$ pwd
/Users/liuxg/java/spark
$ cat sample_json
[ "color": "red", "value": "#f00" , "color": "green", "value": "#0f0" , "color": "blue", "value": "#00f" , "color": "cyan", "value": "#0ff" , "color": "magenta", "value": "#f0f" , "color": "yellow", "value": "#ff0" , "color": "black", "value": "#000" ]如上所示,上面是一个非常简单的 JSON 文件。我们接下来改写我们上面书写的 SparkDemo.scala 文件:
SparkDemo.scala
import org.apache.spark.sql.SparkSession
import org.elasticsearch.spark.sql._
object SparkDemo
def main(args: Array[String]): Unit =
// Configuration
val spark = SparkSession
.builder()
.appName("WriteJSONToES")
.master("local[*]")
.config("spark.es.nodes", "localhost")
.config("spark.es.port", "9200")
.config("spark.es.net.http.auth.user", "elastic")
.config("spark.es.net.http.auth.pass", "password")
.getOrCreate()
// Create dataframe
val frame = spark.read.json("/Users/liuxg/java/spark/sample_json")
// Write to ES with index name in lower case
frame.saveToEs("dataframejsonindex")
运行上面的应用,并在 Kibana 中进行查看:
GET dataframejsonindex/_search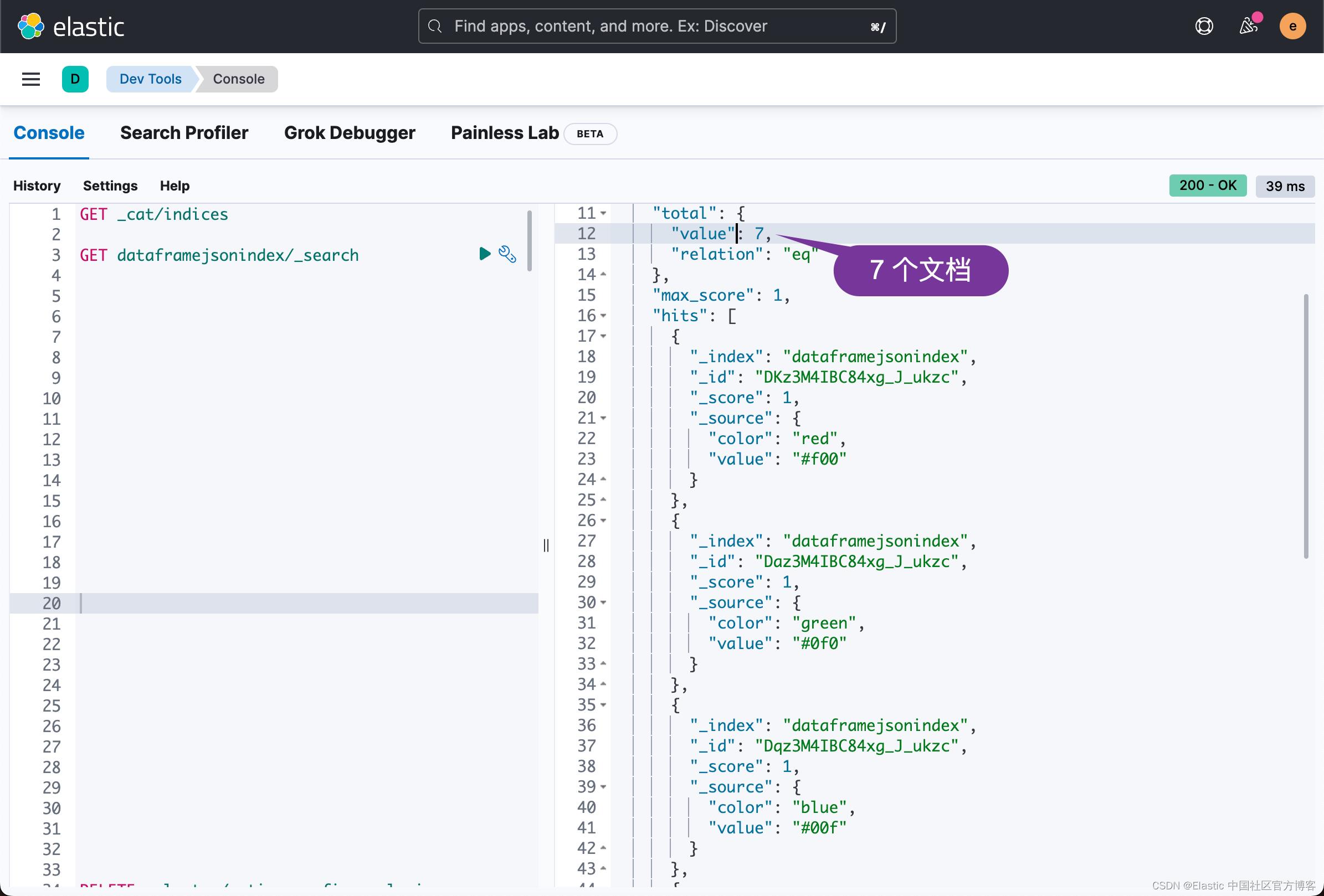
如上所示,我们可以看到有7个文档已经被成功地写入到 Elasticsearch 中。
写入 CSV 文档到 Elasticsearch 中
如法炮制,我们也可以把 CSV 文件写入到 Elasticsearch 中。我们首先创建如下的一个 CSV 文件:
cities.csv
LatD, LatM, LatS, NS, LonD, LonM, LonS, EW", City, State
41, 5, 59, "N", 80, 39, 0, "W", "Youngstown", OH
42, 52, 48, "N", 97, 23, 23, "W", "Yankton", SD
46, 35, 59, "N", 120, 30, 36, "W", "Yakima", WA
42, 16, 12, "N", 71, 48, 0, "W", "Worcester", MA
43, 37, 48, "N", 89, 46, 11, "W", "Wisconsin Dells", WI
36, 5, 59, "N", 80, 15, 0, "W", "Winston-Salem", NC
49, 52, 48, "N", 97, 9, 0, "W", "Winnipeg", MB
39, 11, 23, "N", 78, 9, 36, "W", "Winchester", VA
34, 14, 24, "N", 77, 55, 11, "W", "Wilmington", NC
39, 45, 0, "N", 75, 33, 0, "W", "Wilmington", DE
48, 9, 0, "N", 103, 37, 12, "W", "Williston", ND
41, 15, 0, "N", 77, 0, 0, "W", "Williamsport", PA
37, 40, 48, "N", 82, 16, 47, "W", "Williamson", WV
33, 54, 0, "N", 98, 29, 23, "W", "Wichita Falls", TX
37, 41, 23, "N", 97, 20, 23, "W", "Wichita", KS
40, 4, 11, "N", 80, 43, 12, "W", "Wheeling", WV
26, 43, 11, "N", 80, 3, 0, "W", "West Palm Beach", FL
47, 25, 11, "N", 120, 19, 11, "W", "Wenatchee", WA
41, 25, 11, "N", 122, 23, 23, "W", "Weed", CA
31, 13, 11, "N", 82, 20, 59, "W", "Waycross", GA
44, 57, 35, "N", 89, 38, 23, "W", "Wausau", WI
42, 21, 36, "N", 87, 49, 48, "W", "Waukegan", IL
44, 54, 0, "N", 97, 6, 36, "W", "Watertown", SD
43, 58, 47, "N", 75, 55, 11, "W", "Watertown", NY
42, 30, 0, "N", 92, 20, 23, "W", "Waterloo", IA
41, 32, 59, "N", 73, 3, 0, "W", "Waterbury", CT
38, 53, 23, "N", 77, 1, 47, "W", "Washington", DC
41, 50, 59, "N", 79, 8, 23, "W", "Warren", PA
46, 4, 11, "N", 118, 19, 48, "W", "Walla Walla", WA
31, 32, 59, "N", 97, 8, 23, "W", "Waco", TX
38, 40, 48, "N", 87, 31, 47, "W", "Vincennes", IN
28, 48, 35, "N", 97, 0, 36, "W", "Victoria", TX
32, 20, 59, "N", 90, 52, 47, "W", "Vicksburg", MS
49, 16, 12, "N", 123, 7, 12, "W", "Vancouver", BC
46, 55, 11, "N", 98, 0, 36, "W", "Valley City", ND
30, 49, 47, "N", 83, 16, 47, "W", "Valdosta", GA
43, 6, 36, "N", 75, 13, 48, "W", "Utica", NY
39, 54, 0, "N", 79, 43, 48, "W", "Uniontown", PA
32, 20, 59, "N", 95, 18, 0, "W", "Tyler", TX
42, 33, 36, "N", 114, 28, 12, "W", "Twin Falls", ID
33, 12, 35, "N", 87, 34, 11, "W", "Tuscaloosa", AL
34, 15, 35, "N", 88, 42, 35, "W", "Tupelo", MS
36, 9, 35, "N", 95, 54, 36, "W", "Tulsa", OK
32, 13, 12, "N", 110, 58, 12, "W", "Tucson", AZ
37, 10, 11, "N", 104, 30, 36, "W", "Trinidad", CO
40, 13, 47, "N", 74, 46, 11, "W", "Trenton", NJ
44, 45, 35, "N", 85, 37, 47, "W", "Traverse City", MI
43, 39, 0, "N", 79, 22, 47, "W", "Toronto", ON
39, 2, 59, "N", 95, 40, 11, "W", "Topeka", KS
41, 39, 0, "N", 83, 32, 24, "W", "Toledo", OH
33, 25, 48, "N", 94, 3, 0, "W", "Texarkana", TX
39, 28, 12, "N", 87, 24, 36, "W", "Terre Haute", IN
27, 57, 0, "N", 82, 26, 59, "W", "Tampa", FL
30, 27, 0, "N", 84, 16, 47, "W", "Tallahassee", FL
47, 14, 24, "N", 122, 25, 48, "W", "Tacoma", WA
43, 2, 59, "N", 76, 9, 0, "W", "Syracuse", NY
32, 35, 59, "N", 82, 20, 23, "W", "Swainsboro", GA
33, 55, 11, "N", 80, 20, 59, "W", "Sumter", SC
40, 59, 24, "N", 75, 11, 24, "W", "Stroudsburg", PA
37, 57, 35, "N", 121, 17, 24, "W", "Stockton", CA
44, 31, 12, "N", 89, 34, 11, "W", "Stevens Point", WI
40, 21, 36, "N", 80, 37, 12, "W", "Steubenville", OH
40, 37, 11, "N", 103, 13, 12, "W", "Sterling", CO
38, 9, 0, "N", 79, 4, 11, "W", "Staunton", VA
39, 55, 11, "N", 83, 48, 35, "W", "Springfield", OH
37, 13, 12, "N", 93, 17, 24, "W", "Springfield", MO
42, 5, 59, "N", 72, 35, 23, "W", "Springfield", MA
39, 47, 59, "N", 89, 39, 0, "W", "Springfield", IL
47, 40, 11, "N", 117, 24, 36, "W", "Spokane", WA
41, 40, 48, "N", 86, 15, 0, "W", "South Bend", IN
43, 32, 24, "N", 96, 43, 48, "W", "Sioux Falls", SD
42, 29, 24, "N", 96, 23, 23, "W", "Sioux City", IA
32, 30, 35, "N", 93, 45, 0, "W", "Shreveport", LA
33, 38, 23, "N", 96, 36, 36, "W", "Sherman", TX
44, 47, 59, "N", 106, 57, 35, "W", "Sheridan", WY
35, 13, 47, "N", 96, 40, 48, "W", "Seminole", OK
32, 25, 11, "N", 87, 1, 11, "W", "Selma", AL
38, 42, 35, "N", 93, 13, 48, "W", "Sedalia", MO
47, 35, 59, "N", 122, 19, 48, "W", "Seattle", WA
41, 24, 35, "N", 75, 40, 11, "W", "Scranton", PA
41, 52, 11, "N", 103, 39, 36, "W", "Scottsbluff", NB
42, 49, 11, "N", 73, 56, 59, "W", "Schenectady", NY
32, 4, 48, "N", 81, 5, 23, "W", "Savannah", GA
46, 29, 24, "N", 84, 20, 59, "W", "Sault Sainte Marie", MI
27, 20, 24, "N", 82, 31, 47, "W", "Sarasota", FL
38, 26, 23, "N", 122, 43, 12, "W", "Santa Rosa", CA
35, 40, 48, "N", 105, 56, 59, "W", "Santa Fe", NM
34, 25, 11, "N", 119, 41, 59, "W", "Santa Barbara", CA
33, 45, 35, "N", 117, 52, 12, "W", "Santa Ana", CA
37, 20, 24, "N", 121, 52, 47, "W", "San Jose", CA
37, 46, 47, "N", 122, 25, 11, "W", "San Francisco", CA
41, 27, 0, "N", 82, 42, 35, "W", "Sandusky", OH
32, 42, 35, "N", 117, 9, 0, "W", "San Diego", CA
34, 6, 36, "N", 117, 18, 35, "W", "San Bernardino", CA
29, 25, 12, "N", 98, 30, 0, "W", "San Antonio", TX
31, 27, 35, "N", 100, 26, 24, "W", "San Angelo", TX
40, 45, 35, "N", 111, 52, 47, "W", "Salt Lake City", UT
38, 22, 11, "N", 75, 35, 59, "W", "Salisbury", MD
36, 40, 11, "N", 121, 39, 0, "W", "Salinas", CA
38, 50, 24, "N", 97, 36, 36, "W", "Salina", KS
38, 31, 47, "N", 106, 0, 0, "W", "Salida", CO
44, 56, 23, "N", 123, 1, 47, "W", "Salem", OR
44, 57, 0, "N", 93, 5, 59, "W", "Saint Paul", MN
38, 37, 11, "N", 90, 11, 24, "W", "Saint Louis", MO
39, 46, 12, "N", 94, 50, 23, "W", "Saint Joseph", MO
42, 5, 59, "N", 86, 28, 48, "W", "Saint Joseph", MI
44, 25, 11, "N", 72, 1, 11, "W", "Saint Johnsbury", VT
45, 34, 11, "N", 94, 10, 11, "W", "Saint Cloud", MN
29, 53, 23, "N", 81, 19, 11, "W", "Saint Augustine", FL
43, 25, 48, "N", 83, 56, 24, "W", "Saginaw", MI
38, 35, 24, "N", 121, 29, 23, "W", "Sacramento", CA
43, 36, 36, "N", 72, 58, 12, "W", "Rutland", VT
33, 24, 0, "N", 104, 31, 47, "W", "Roswell", NM
35, 56, 23, "N", 77, 48, 0, "W", "Rocky Mount", NC
41, 35, 24, "N", 109, 13, 48, "W", "Rock Springs", WY
42, 16, 12, "N", 89, 5, 59, "W", "Rockford", IL
43, 9, 35, "N", 77, 36, 36, "W", "Rochester", NY
44, 1, 12, "N", 92, 27, 35, "W", "Rochester", MN
37, 16, 12, "N", 79, 56, 24, "W", "Roanoke", VA
37, 32, 24, "N", 77, 26, 59, "W", "Richmond", VA
39, 49, 48, "N", 84, 53, 23, "W", "Richmond", IN
38, 46, 12, "N", 112, 5, 23, "W", "Richfield", UT
45, 38, 23, "N", 89, 25, 11, "W", "Rhinelander", WI
39, 31, 12, "N", 119, 48, 35, "W", "Reno", NV
50, 25, 11, "N", 104, 39, 0, "W", "Regina", SA
40, 10, 48, "N", 122, 14, 23, "W", "Red Bluff", CA
40, 19, 48, "N", 75, 55, 48, "W", "Reading", PA
41, 9, 35, "N", 81, 14, 23, "W", "Ravenna", OH 我们重新修改上面的 SparkDemo.scala 文件:
SparkDemo.scala
import org.apache.spark.sql.SparkSession
import org.elasticsearch.spark.sql._
object SparkDemo
def main(args: Array[String]): Unit =
// Configuration
val spark = SparkSession
.builder()
.appName("WriteCSVToES")
.master("local[*]")
.config("spark.es.nodes", "localhost")
.config("spark.es.port", "9200")
.config("spark.es.net.http.auth.user", "elastic")
.config("spark.es.net.http.auth.pass", "password")
.getOrCreate()
// Create dataframe
val frame = spark.read.option("header", "true").csv("/Users/liuxg/java/spark/cities.csv")
// Write to ES with index name in lower case
frame.saveToEs("dataframecsvindex")
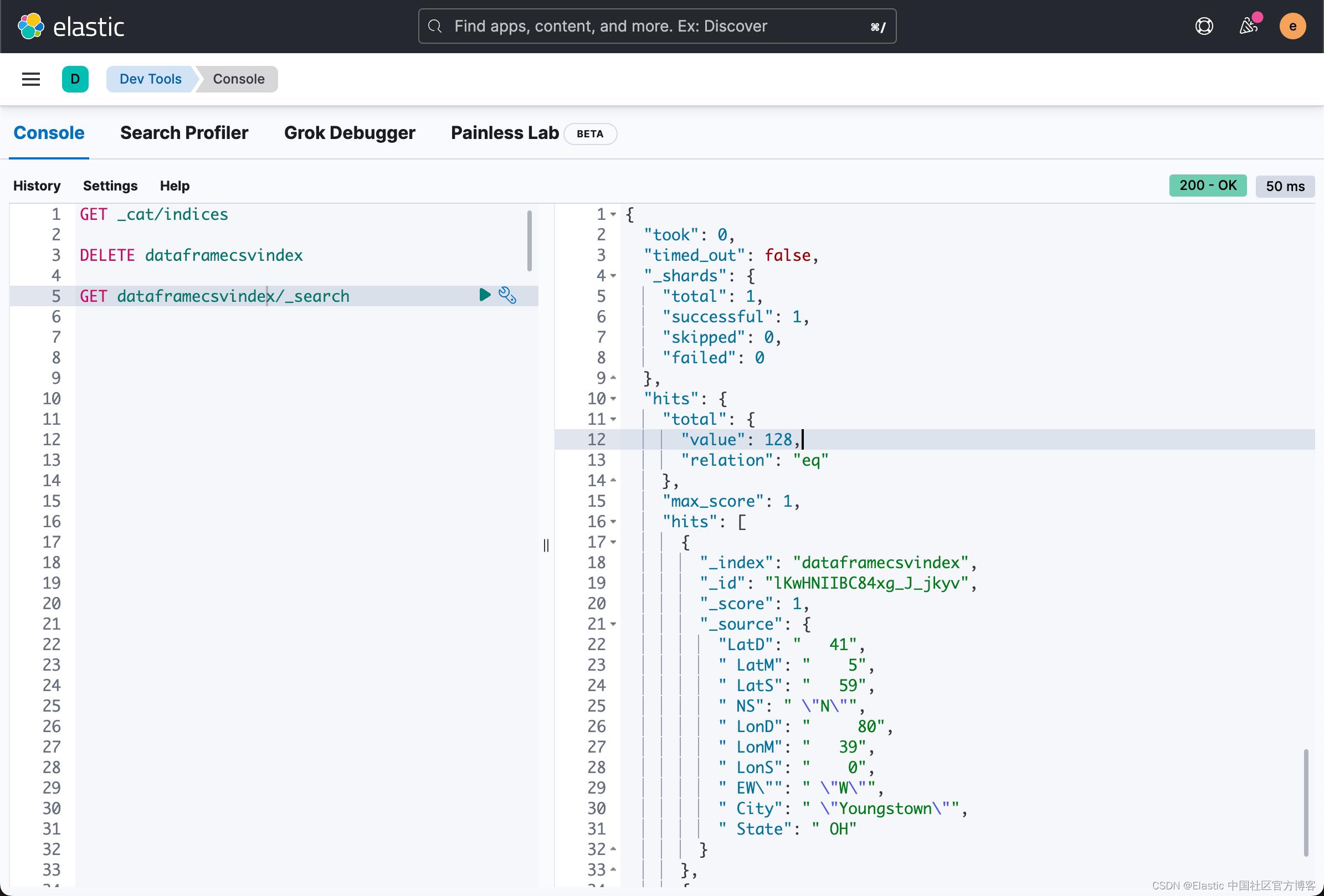
从上面,我们可以看出来 csv 格式的文件已经被成功地写入了。共有 128 个文档被写入。
参考:
【1】Apache Spark support | Elasticsearch for Apache Hadoop [8.3] | Elastic
以上是关于Elasticsearch:Apache spark 大数据集成的主要内容,如果未能解决你的问题,请参考以下文章
Spark启动时报错localhost: failed to launch: nice -n 0 /home/chan/spark/spark-2.4.3-bin-hadoop2.7/bin/spar