reactjs自制Monkey语言编译器:解析组合表达式,ifelse语句块和间套函数调用
Posted Coding迪斯尼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了reactjs自制Monkey语言编译器:解析组合表达式,ifelse语句块和间套函数调用相关的知识,希望对你有一定的参考价值。
我们的计算机教育时常流于肤浅,在面对难度较大的基础理论时,总是喜欢侃侃而谈,说起来头头是道,看起似乎很牛逼的样子,但本质上却是大而无当,空洞无物。任何上过大学,专业是计算机的同学或许能深有体会,像操作系统,编译原理,计算机网络等学科的基础理论内容,老师在课堂上讲解总是流于表面,各种深奥的大词从老师嘴里不断飘出,搞得学生晕头转向,并且对技术理论产生严重的抗拒心理。不难理解,很多学生根本就没写过操作系统内核代码,连何谓“中断调用”都搞不清楚时,你跟他大谈各种复杂的“进程调度算法”,能有什么意义和作用呢。编译原理也是如此,为了打破这些虚有其表的假道学,我开启了一个用java开发一个实打实的C语言编译器课程,这个编译器能把C语言转换成java字节码,在java虚拟机上执行,我相信这点我绝对是国内首创。
如果看过上面课程的同学可以看到,全部课程总计110课时,我直到最后才给出了编译器如何解释执行if…else…这样复杂的代码模块。然而让我意象不到的是,原本看似极为复杂的工程实践,原来还存在着相当优美简洁的实现办法,我们这几节所讲的普拉特解析法就是典型实例,原来我需要花几千行代码,费时费力,绞尽脑汁好几天才能完成的事情,在普拉特解析法里就能轻而易举的处理掉,接下来让我们看看该算法在语法解析上的强大功能吧。
我们先增加对true 和 false 的支持。Monkey编程语言支持如下代码:
true;
false;
let foobar = true;
let barfoo = false;也就是编译器应当把”true”和”false”当做关键字看待,并把前者当做一个非零值,后者作为零值理解。我们现在代码中增加对应的数据结构,在MonkeyCompilerParser.js中添加如下内容:
class Boolean extends Expression {
constructor(props) {
super(props)
this.token = props.token
this.value = props.value
var s = "Boolean token with value of " + this.value
this.tokenLiteral = s
}
}Boolean类用来表示编译器对”true”和”false”两个字符串解读的结果。如果解读前者,那么value对应的值就是1,如果是后者,value对应的值就是0.接着我们添加解析函数代码,并在调用函数表中注册解析函数:
class MonkeyCompilerParser {
constructor(lexer) {
...
//change here
this.prefixParseFns[this.lexer.TRUE] =
this.parseBoolean
this.prefixParseFns[this.lexer.FALSE] =
this.parseBoolean
this.prefixParseFns[this.lexer.LEFT_PARENT] =
this.parseGroupedExpression
this.prefixParseFns[this.lexer.IF] =
this.parseIfExpression
this.prefixParseFns[this.lexer.FUNCTION] =
this.parseFunctionLiteral
this.initPrecedencesMap()
this.registerInfixMap()
}
....
parseBoolean(caller) {
var props = {}
props.token = caller.curToken
props.value = caller.curTokenIs(caller.lexer.TRUE)
return new Boolean(props)
}
....
}在代码中,我们在前缀调用表中注册了两个函数,当解析器解读到token 的类型为true或false时,就直接调用parseBoolean函数进行解析。在该函数中,它判断当前解读到的token是否是true,如果是,它会创建一个Boolean类,把它的value值设置成1,若不然,把value值设置成0,上面代码完成后,程序运行结果如下:
添加了代码后,编译器就能把true和false对应的含义识别出来。
我们再看看如何解析组合表达式,所谓组合表达式就是带有括号的表达式,例如:
3*(5+2);
括号具备最高优先级,编译器需要解析表达式后面带括号的部分,把解析后所得结果用来与3做加法运算。前面我们解释过,普拉特解析法是如何根据运算符优先级的不同而实现解析的,括号只不过是一种优先级比算术运算符高的符号而已,我们只需要添加几行代码就能实现括号的解析功能,首先是在前缀调用表中增加对应的解析函数,这点在前面已经完成了:
this.prefixParseFns[this.lexer.LEFT_PARENT] = this.parseGroupedExpression
接下来我们看看如何实现parseGroupedExpression,它的实现代码如下:
parseGroupedExpression(caller) {
caller.nextToken()
var exp = caller.parseExpression(caller.LOWEST)
if (caller.expectPeek(caller.lexer.RIGHT_PARENT)
!== true) {
return null
}
return exp
}一旦解析到左括号”(“时,编译器立马调用上面函数,它通过调用parseExpression解析括号里面的内容,然后判断是否存在对应的右括号,上面的代码完成后运行结果如下: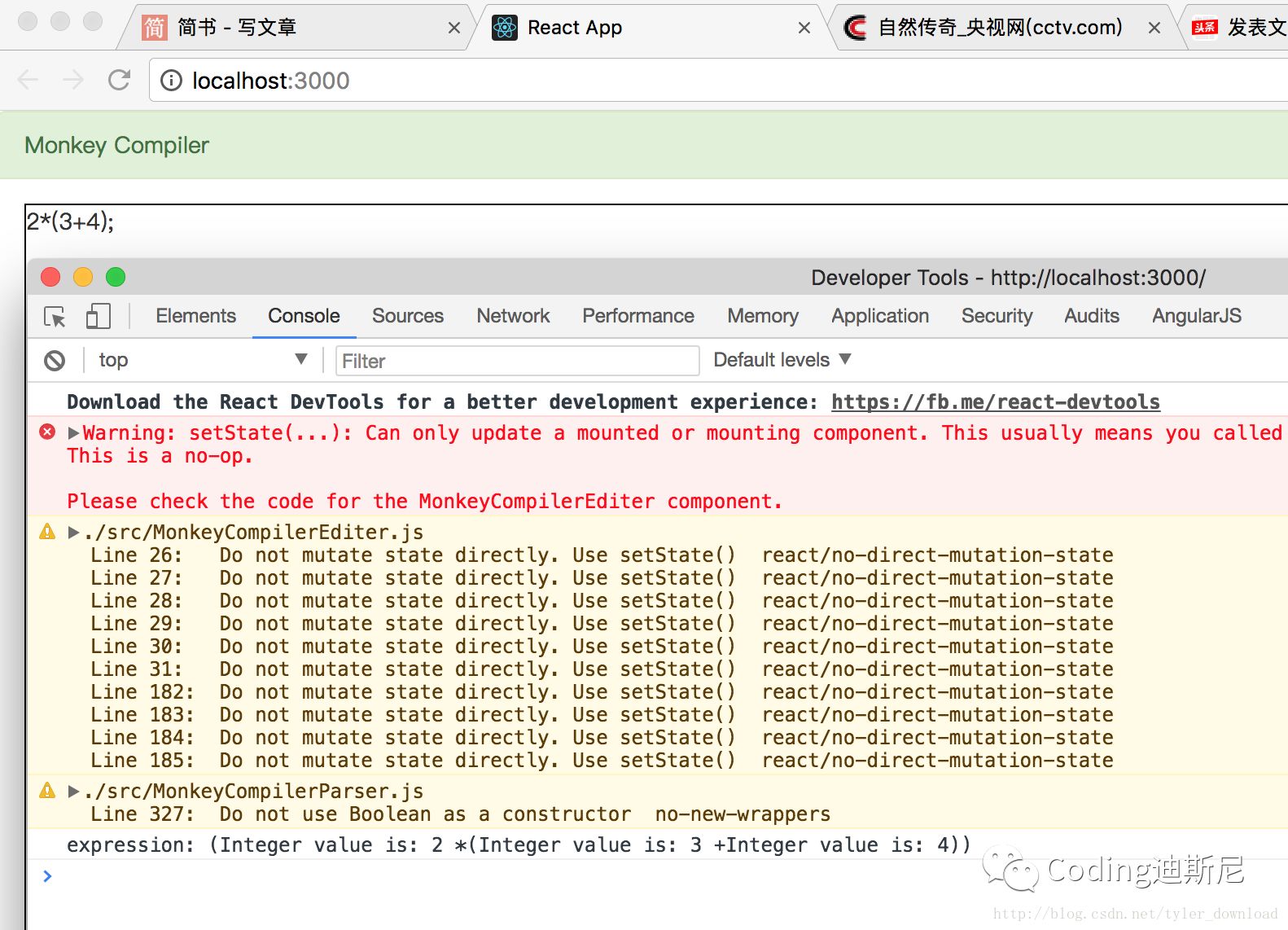
从运行结果我们看到,编译器把括号里的3+4当做一个整体进行解析,然后再用其结果与2做乘法运算。
接着,我们看看如何解析if…else…语句块。我在网易云课堂上的编译器课程《用java开发C语言编译器》中,耗费了巨大的篇幅和相当程度的代码才实现了if…else…语句块的解析功能,然而使用普拉特解析法就能而两拨千斤的搞定。对于Monkey语言,它支持如下的if..else…语句模式:
if (x > y) {
return x;
} else {
return y;
}if..else..语句的逻辑结构如下:
if (condition-expression) { consequence-statement} else {alternative-statment}前面我们说过,statement 是一个抽象概念,用来表示一系列末尾带分号的语句集合。我们现在代码中定义一个类来表示ifelse语句块:
class IfExpression extends Expression {
constructor(props) {
super(props)
this.token = props.token
this.condition = props.condition
this.consequence = props.consequence
this.alternative = props.alternative
var s = "if expression width condtion: " +
this.condition.getLiteral()
s += "\n statements in if block are: "
s += this.consequence.getLiteral()
if (this.alternative) {
s += "\n statements in else block are: "
s += this.alternative.getLiteral()
}
this.tokenLiteral = s
}
}
class BlockStatement extends Statement {
constructor(props) {
super(props)
this.token = props.token
this.statements = props.statements
var s = ""
for (var i = 0; i < this.statements.length; i++) {
s += this.statements[i].getLiteral()
s += "\n"
}
this.tokenLiteral = s
}
}代码中的condition用来表示if后面的条件表达式,consequence 表示如果if条件成立的话所要执行的语句集合,alternative用来表示else部分的语句集合。BlockStatement类用来表示ifelse语句中第一个大括号内或接着else部分的大括号内所要执行的所有语句的集合
接着我们要添加对应的解析函数的实现,继续添加如下代码:
parseIfExpression(caller) {
var props = {}
props.token = caller.curToken
if (caller.expectPeek(caller.lexer.LEFT_PARENT) !==
true) {
return null
}
caller.nextToken()
props.condition = caller.parseExpression(caller.LOWEST)
if (caller.expectPeek(caller.lexer.RIGHT_PARENT) !==
true) {
return null
}
if (caller.expectPeek(caller.lexer.LEFT_BRACE) !==
true) {
return null
}
props.consequence = caller.parseBlockStatement(caller)
if (caller.peekTokenIs(caller.lexer.ELSE) === true) {
caller.nextToken()
if (caller.expectPeek(caller.lexer.LEFT_BRACE) !==
true) {
return null
}
props.alternative = caller.parseBlockStatement(caller)
}
return new IfExpression(props)
}当编译器读取到”if”关键字时,就会调用上面的解析函数。它首先判断if后面是否跟着左括号,接着代码调用parseExpression解析在括号里面的条件表达式,根据表达式运行后的记过来判断执行哪部分代码,然后看是否有右括号与左括号配对。下一步就是看是否有左大括号,有的话编译器就解析括号里面的语句,括号里面的语句集合在一起形成一个BlocakStatment类,接下来继续判断是否跟着else部分,如果有就得判断跟着else的必须是左大括号,然后再解析括号内部的多条语句,这些语句集合成一个BlockStatment对象。上面代码完成后,编译器的功能进一步增强,它能顺利解析复杂的ifelse语句模块了:
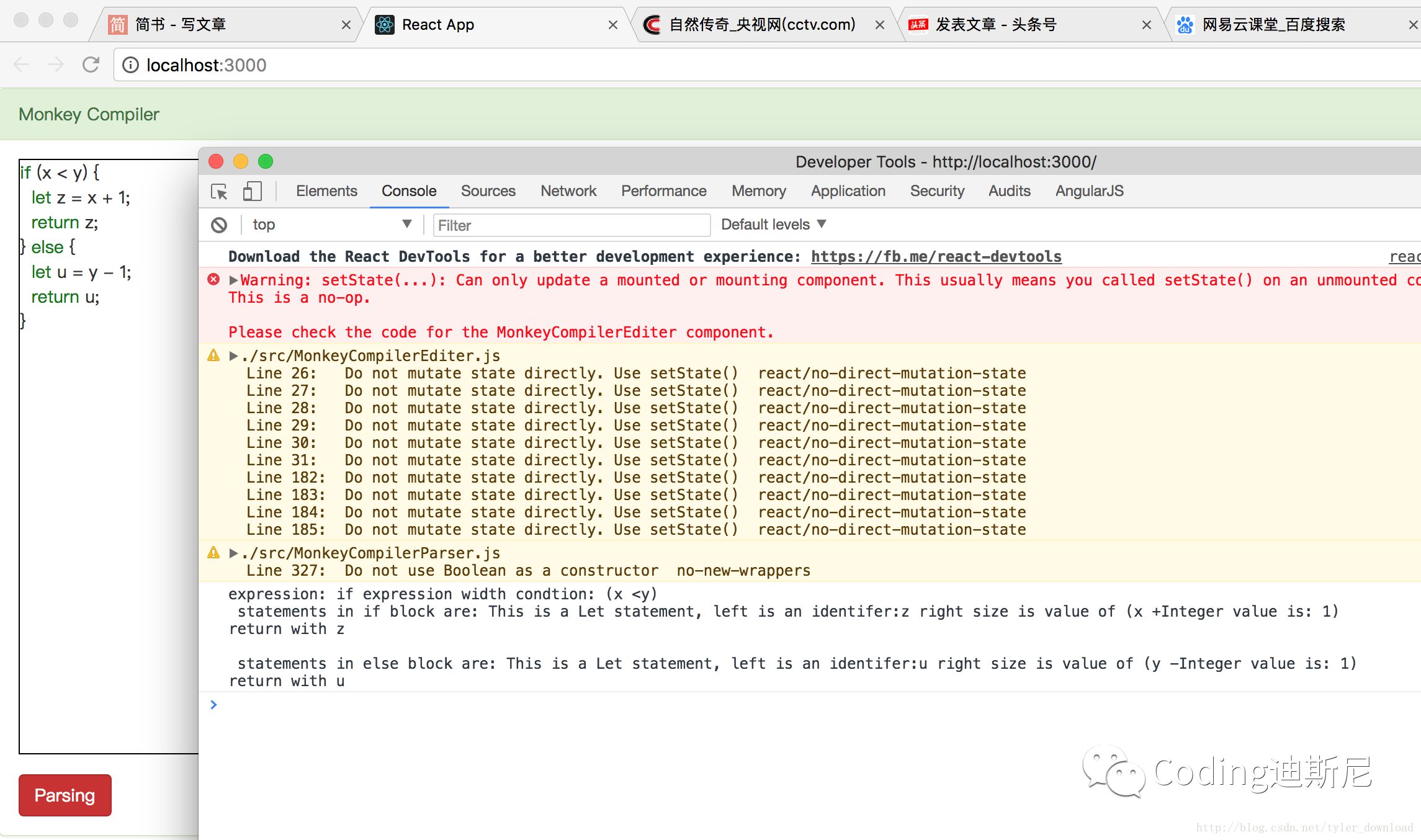
在上图中,我们在编辑框里输入了较为复杂的if else 语句模块,从控制台输出来看,语句块里面的每个代码成分都得到合理的解析。如果不使用普拉特解析法的话,要完成对应的解析功能,代码量至少要是现在代码的好几倍左右,而且设计逻辑会大大复杂,具体详情大家可以参见课程用java开发C语言编译器
if else 语句模块的解析比较复杂,仅仅通过文档阅读未必能够完全掌握,请参看视频查看更具体的代码讲解和调试演示流程,课程链接如下:
更详细的讲解和代码调试演示过程,请点击这里
接着我们看看函数定义的解析,在Monkey语言里,它是这么定义一个函数的:
fn (x,y) {
return x+y;
}其中fn是关键字,它可以直接定义一个匿名函数,后面的括号是参数列表,接下来的就是函数实现了。我们看看编译器如何实现相应解析。我们先定义相应的数据结构:
class FunctionLiteral extends Expression { constructor(props) { super(props) this.token = props.token this.parameters = props.parameters this.body = props.body var s = "It is a nameless function," s += "input parameters are: (" for (var i = 0; i < this.parameters.length; i++) { s += this.parameters[i].getLiteral() s += "\n" } s += ")\n" s += "statements in function body are : {" s += this.body.getLiteral() s += "}" this.tokenLiteral = s } }
类定义中的parameters 对应的就是函数的参数列表,body对应的就是函数体实现语句所形成的集合。接着我们要在函数调用表里设置对应的解析函数,这点我们前面已经完成了,也就是语句:
this.prefixParseFns[this.lexer.FUNCTION] =
this.parseFunctionLiteral上面代码意味着,一旦解析器发现关键字”fn”,便立马执行parseFunctionLiteral函数,我们看看它的实现:
parseFunctionLiteral(caller) {
var props = {}
props.token = caller.curToken
if (caller.expectPeek(caller.lexer.LEFT_PARENT) !== true) {
return null
}
props.parameters = caller.parseFunctionParameters(caller)
if (caller.expectPeek(caller.lexer.LEFT_BRACE) !== true) {
return null
}
props.body = caller.parseBlockStatement(caller)
return new FunctionLiteral(props)
}
//change here
parseFunctionParameters(caller) {
var parameters = []
if (caller.peekTokenIs(caller.lexer.RIGHT_PARENT)) {
caller.nextToken()
return parameters
}
caller.nextToken()
var identProp = {}
identProp.token = caller.curToken
parameters.push(new Identifier(identProp))
while (caller.peekTokenIs(caller.lexer.COMMA)) {
caller.nextToken()
caller.nextToken()
var ident = {}
ident.token = caller.curToken
parameters.push(new Identifier(ident))
}
if (caller.expectPeek(caller.lexer.RIGHT_PARENT) !==
true) {
return null
}
return parameters
}在parseFunctionLiteral的执行中,它先判断关键字”fn” 之后是不是跟着左括号,如果是,那么根据函数定义,接下来就是以逗号分隔开的参数列表,参数列表的解析由函数parseFunctionParameters负责,由于函数可以没有参数,因此在它的执行中,先判断左括号后面是不是直接跟着右括号,如果是那就直接返回。如果有参数,那么每个参数都应该是以变量字符串的形式出现,并且也逗号隔开,也就是每个参数都是一个IDENTIFIER类型的token,因此直接把他们构建成Identifier类的实例,并且代码中还判断了参数间是否是以逗号隔开的,当所有参数解析完后,还得判断以右括号结尾。
解析完输入参数后,回到parseFunctionLiteral函数,它接着判断跟着右括号后面的必须是左大括号,在大括号里面就是一系列由分号结尾的代码语句组合,这种组合使用parseBlockStatment函数来解析,这点我们前面已经解析过,上述代码完成后,解析效果如下:
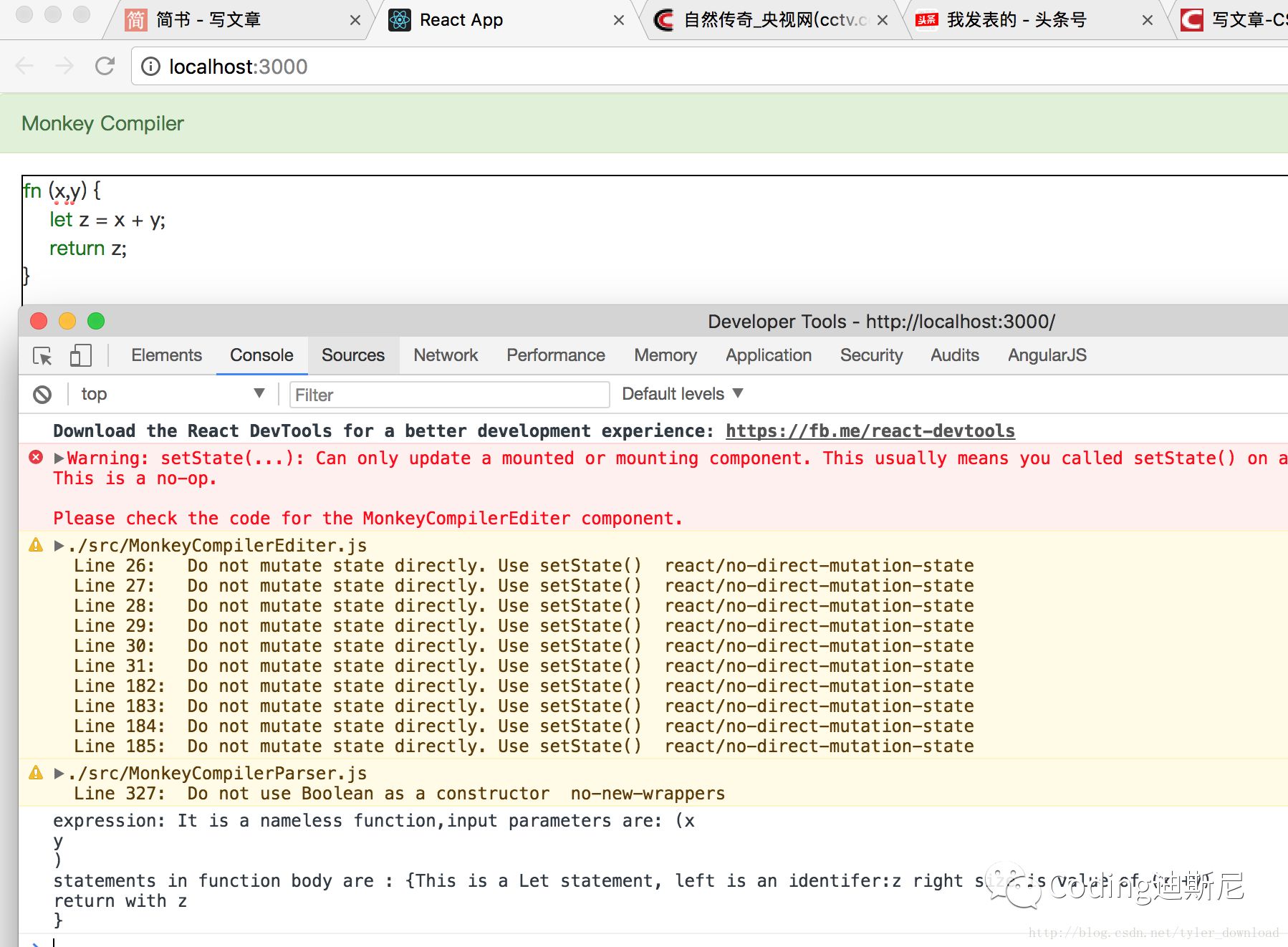
解析逻辑比较抽象复杂,为了更好的深入理解,需要通过视频查看代码调试演示过程,请点击’阅读原文‘参看视频。
最后,我们再看看函数调用如何实现,在Monkey语言中,函数调用有多种方式,例如:
add(2, 3+(1*4));
fn (x,y) {
let z = x + y;
return z;
}(1,2);
callsFunction(2, 3, fn(x,y){return x+y;});同理,我们还是根据函数调用定义相关的类对象:
class CallExpression extends Expression {
constructor(props) {
super(props)
this.token = props.token
this.function = props.function
this.arguments = props.arguments
var s = "It is a function call : " +
this.function.getLiteral()
s += "\n It is input parameters are: ("
for (var i = 0; i < this.arguments.length; i++) {
s += "\n"
s += this.arguments[i].getLiteral()
s += ",\n"
}
s += ")"
this.tokenLiteral = s
}
}在代码定义中,function对应的可以是函数名或者是函数体实现,例如add(2,3);,那么function对应的就是变量名add,如果是fn(x,y){return x+y;}(2,3),那么function对应的就是参数列表前面的整个函数实现,类定义中的arguments对应的就是函数调用是的参数列表。
函数调用的模式是,前面一个表达式也就是函数名或函数体实现,后面跟着一个左括号,然后是传入参数,因此函数调用解析的触发,必须放在后序调用表中:
registerInfixMap() {
....
this.infixParseFns[this.lexer.LEFT_PARENT] =
this.parseCallExpression
}如果解析器遇到一个变量名或者是一个函数定义,那么它会通过前序调用表,调用相应的解析函数进行解析,如果变量名或函数定义之后跟着一个左括号的话,那么解析器就知道它当前遇到了一个函数调用,于是就从上面的后序调用表中,根据左括号查找到解析函数parseCallExpression执行相应解析,我们看看它的实现:
parseCallExpression(caller, fun) {
var props = {}
props.token = caller.curToken
props.function = fun
props.arguments = caller.parseCallArguments(caller)
return new CallExpression(props)
}
//change here
parseCallArguments(caller) {
var args = []
if (caller.peekTokenIs(caller.lexer.RIGHT_PARENT)) {
caller.nextToken()
return args
}
caller.nextToken()
args.push(caller.parseExpression(caller.LOWEST))
while(caller.peekTokenIs(caller.lexer.COMMA)) {
caller.nextToken()
caller.nextToken()
args.push(caller.parseExpression(caller.LOWEST))
}
if (caller.expectPeek(caller.lexer.RIGHT_PARENT)
!== true) {
return null
}
return args
}parseCallExpression的内容不多,它主要是调用parseCallArguments来解析输入参数,后者的实现逻辑跟前面我们说过的parseFunctionParameters如出一辙,唯一不同在于,函数定义时,输入参数全是由变量字符串组成的类型为IDENTIFIER的token,但是函数调用时就不一样了,因为输入参数完全可以是一个复杂的算术表达式,例如:
add(2, 3*(4+5));所以当编译器解析函数调用是的输入参数是,必须把每个参数当做一个算术表达式来解析。上面代码完成后,运行情况如下:
根据结果可知,代码实现的解析逻辑是正确的。
解析逻辑比较抽象复杂,为了更好的深入理解,需要通过视频查看代码调试演示过程,请点击’阅读原文‘参看视频。
我们这一节实现的语法解析其实是比较复杂的,按照经典编译原理算法,要解析本节所说的代码,需要很复杂的逻辑,并且实现代码量至少是现在代码量的十倍以上,由此可见,普拉特解析法给复杂的语法解析实现带来了效率和逻辑上的极大提升,通用的JS语法静态检测工具JSLint就是依靠普拉特解析法来实现的,由此可见掌握了普拉特解析法,理解了语法解析的本质,编译原理的内核基本上就能掌握扎实了。
以上是关于reactjs自制Monkey语言编译器:解析组合表达式,ifelse语句块和间套函数调用的主要内容,如果未能解决你的问题,请参考以下文章