从设计到实现:Replication | 分布式文件系统读书笔记
Posted 中兴大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从设计到实现:Replication | 分布式文件系统读书笔记相关的知识,希望对你有一定的参考价值。
我们在系统学习新知识时,往往会发现理论学习和应用实现之间存在一个断层。学习理论时,我们被设计思想所牵引,看不到实现细节;分析实现时,我们又为纷杂的细节所困扰,理不清设计思想。为了解决这个问题,我们从本期开始推送《从设计到实现:分布式文件系统读书笔记》系列,由中兴大数据资深工程师整合一线工作经验,在gfs论文和分布式文件系统具体实现之间架起一道桥梁。
文 | 何文鑫
为什么会有这个读书笔记?
首先说一下为什么会有“从设计到实现”这个读书笔记系列。
我发现,很多人(包括我)在观察分布式系统时,往往是割裂地在看:当我阅读一篇分布式论文时,我是在看设计,我会了解设计的缘由、取舍,但我看不到实现。当我看代码时,我又看到的是各种纷繁复杂的细节,看不到高层设计。
因此,我需要有一个地方,记录分布式系统的设计如何落地到实现层面。我会把gfs论文中提到的分布式文件系统设计一点点抠出来,然后对应到具体的HDFS实现,并记录在此。同时,我也会尝试使用一种新的语言实现gfs的设计,看能否简化设计的实现。erlang可能是应用在此领域比较合适的语言,可以尝试。
如何观察一个分布式系统?
大体上可以从三个层面去观察一个分布式系统(Distributed System):
业务 - application
设计 - design
实现 - implementation
业务(application)
业务(application)关注系统能够向最终用户提供哪些服务。一般来说,分布式系统内部的复杂性,使其对外提供的服务模型相对简单:文件系统提供文件的读写,KV存储提供Key-Value对的存储。
设计(design)
设计(design)关注分布式系统如何提供扩展性(scalability),提高性能(Performance),同时保持较好的可用性(availability),使得最终用户不必关心与其交互的系统分布在单节点上还是多节点上。
分布式设计是分布式系统的核心,它决定了系统上述三个属性最终保持在哪个量级。
同时,它也影响其他两个层面。
向上,它决定了对外提供服务的质量属性:
高吞吐高延时,还是吞吐量略低延时也较低?
系统能承受的最大容量(capacity)多少?
面向何种业务负载?少量写入多次读取?还是读写均衡?
……。
向下,它决定了系统的实现难度。工程实践领域,越简单的设计越受欢迎,容易流行,也更易维护。因此,没有one-fit-all的分布式系统,不同系统总是通过针对特定场景的设计取舍来简化复杂度。
实现(implementation)
实现(implementation)关注将系统设计变为现实。分布式系统设计非常具有挑战性,而实现更具挑战性。设计上没有问题的系统,可能因为实现上的瑕疵产生意料之外的结果。因为,实现的复杂度除了受设计复杂度的影响之外,还受到实现语言的强烈影响。
实现语言能否与底层操作系统高效交互在一定程度上影响系统的性能
实现语言对网络、并发的支持程度也影响实现的复杂度
总之,如何简单、正确、高性能的实现设计,是该层面要关注的事情。
说完如何观察一个分布式系统,我们从Replication开始学习之旅,因为Partition与Replication是分布式系统设计中解决问题的主要方法,也是分布式系统的永恒话题。
为何复制?
分布式系统使用复制(replicate)将数据传输到多个节点,以便:
某个副本(replica)所在节点失效(failure)时,其他节点的副本可以继续提供服务
分散服务访问、计算压力,提升带宽、性能
复制方法的分类
复制可以分为:
同步复制(synchronous replication)
异步复制(Asynchronous replication)
同步复制
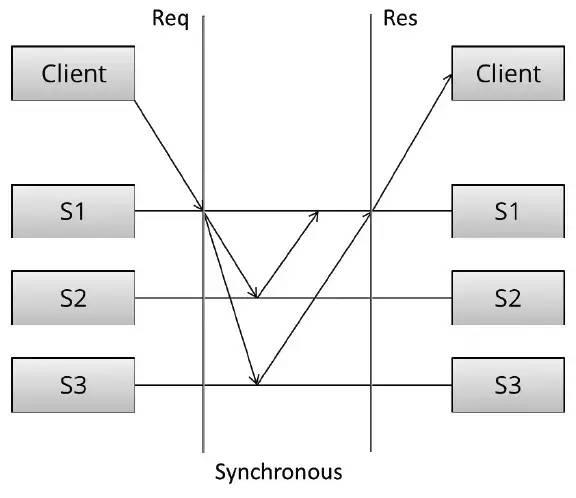
同步复制中,Client向S1写入数据,S1负责将数据复制到S2、S3。只有当S1收到S2、S3的成功回复后,S1才会给Client回复成功消息。
异步复制
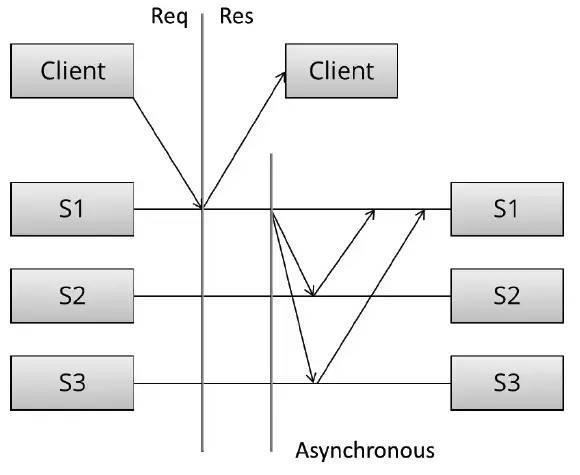
异步复制中, S1写入成功后立刻告知Client,然后才会将数据复制到S2、S3。
同步复制 vs 异步复制
从数据可靠性(Reliability)、一致性(Consistency)的角度看:
同步复制,一旦Client写入成功,即可以确保系统存在多个数据副本,数据不易丢失[可靠性✔]。此时,无论Client访问S1还是S2、S3都可以读到相同的数据[一致性✔]。
异步复制,当Client得到写入成功消息时并不能确保系统中存在多个数据副本。也就是,如果此时Client立即访问S2或者S3,会存在无法读到刚刚写入数据的可能性[一致性✘]。另外,如果S1在数据复制到其他节点前失效,可能导致数据丢失[可靠性✘]。
从网络通信、写入延时角度看:
同步复制一次写入需要完成3个节点的通信(假设数据副本数为3)才能返回,网络延时叠加,写入速度慢。
而异步复制,因为Client没有等待复制的过程,写入速度快。
总体来看:
同步复制简单、直接,所有副本完成后,写入成功,同时带来写入速度较慢的副作用。
异步复制很暴力,一个副本完成后,即算写入成功,不理会副本在后台是否复制。所以在Client看来写入迅速,不会受到节点间网络延时的影响。但之后节点间副本复制过程会比较复杂,且存在单点失效数据丢失的风险。
介于两者之间
从论文上看,某些系统并不追求强一致性(strong consistency),而更看重可用性、性能等因素。它们采用了介于同步复制与异步复制之间的复制方法,实现弱一致性(weak consistency),比如Amazon Dynamo。
与上面两种复制方法一致,Dynamo的典型副本数N也为3。
不同之处在于,用户可根据业务需要自行选择写入/读取的副本数:R=读取副本数,W=写入副本数,且R+W>N。
即,用户可以选择N中的W个节点进行数据写入,W写入成功即返回。同时,读取时从N中指定R个节点读取副本,返回较新副本。
写入节点越多,写入速度下降,但数据可靠性上升。读取节点越多,读到最新数据的概率越大。
其中,要求R+W>N,保证读写节点中必有一个重叠节点。
比如:
R = 1 , W = N : 读快, 写慢(退化为同步复制)
R = N , W = 1 : 写快, 读慢
R = N/2 and W = N/2 + 1 : 读写均衡
类Dynamo系统的默认N-R-W:
Basho's Riak (N = 3, R = 2, W = 2 default)
Linkedin's Voldemort (N = 2 or 3, R = 1, W = 1 default)
Apache's Cassandra (N = 3, R = 1, W = 1 default)
本篇介绍了几种常见的复制方式,下篇开始结合具体的gfs、HDFS实例,看看真实系统中,复制如何进行。
(to be continued...)
长按二维码关注
以上是关于从设计到实现:Replication | 分布式文件系统读书笔记的主要内容,如果未能解决你的问题,请参考以下文章