基于json数据对全国疫情数据可视化
Posted R传染病数据可视化
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于json数据对全国疫情数据可视化相关的知识,希望对你有一定的参考价值。
本期还是巩固练习json文件做全国地图。
library(jsonlite)
library(ggplot2)
library(plyr)
library(dplyr)
第一步:准备json文件数据
本期以省级为例。
json_data <- fromJSON("中国.json") #读取全国json地图数据:
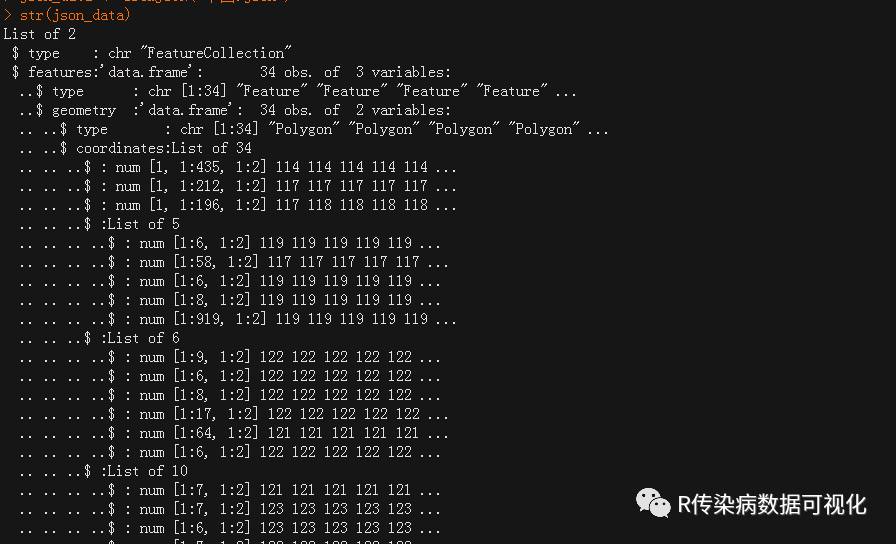
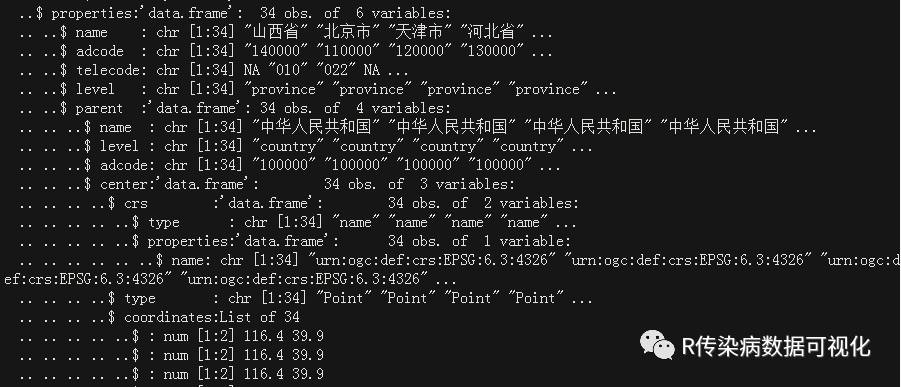
str(json_data) #研究json_data的数据结构
#上面2图是部分截图,发现json_data的数据很多,结构很复杂,有很多list组成。
#我们作图主要是需要边界经纬度、省份名称等。发现省名等信息在json_data$features$properties里,因此提取各省相关信息
province<-json_data$features$properties #提取各省份信息
province$id<-1:nrow(province) #增加id以备后期匹配
#边界经纬度信息在json_data$features$geometry$coordinates里
provincedata<-json_data$features$geometry$coordinates
str(provincedata)
#发现有34个list,而且有些为一级list,有些有二级list,那么从不同层级list里提取经纬度信息,再合并为data.frame是本期内容的挑战。经过研究,我也找到了方法如下:
mapdata1<-data.frame() #list二级
mapdata2<-data.frame() #list一级
for( i in 1:length(provincedata)){
provincemapdata<-provincedata[[i]]
if (is.null(dim(provincemapdata))==TRUE){
for(m in 1:length(provincemapdata)){
provincemapdata1<- data.frame(provincemapdata[[m]])
names(provincemapdata1)<-c("lon","lat")
provincemapdata1$id<-i
provincemapdata1$group<-as.numeric(paste0(i,".",m,1))
provincemapdata1$order<-1:dim(provincemapdata1)[1]
mapdata1<-rbind(mapdata1,provincemapdata1)
}
}else{
dim(provincemapdata)=c(length(provincemapdata)/2,2)
provincemapdata2<-data.frame(provincemapdata)
names(provincemapdata2)<-c("lon","lat")
provincemapdata2$id<-i
provincemapdata2$group<-as.numeric(paste0(i,".",1))
provincemapdata2$order<-1:dim(provincemapdata2)[1]
mapdata2<-rbind(mapdata2,provincemapdata2)
}
mydatanew<-rbind(mapdata1,mapdata2)
}
#以上是利用循环函数,先判断各个list的维度是否为NULL,根据不同判定结果使用不同方法提取各省边界点经纬度信息,并生成了分组依据group、指定了单个区边界点顺序,生成id变量便于合并
mydatanew<-arrange(mydatanew,id,order)
第二步:准备分析数据
#随机模拟13年数据,内含台港澳数据,无不需要可删掉
set.seed(125)
province$morbidity<-round(runif(34,5,25),0) #随机生成数据
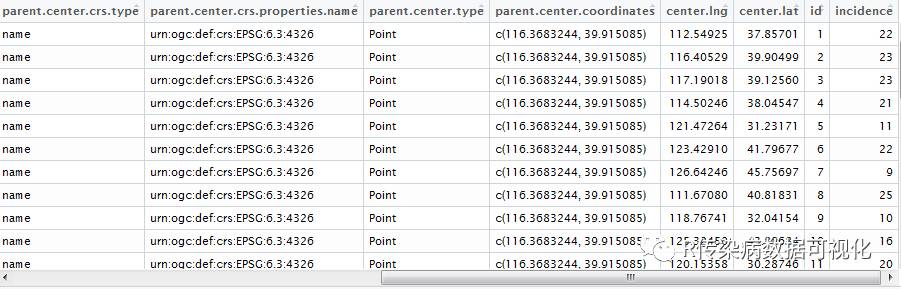
china_data<-merge(mydatanew,province[,c(-3,-4)],by="id")#合并边界点数据和各区名称与分组依据(主要是ggplot映射时作为分组变量使用)
第三步:作图
#自定义分组和颜色
china_data$group1<-cut(china_data$morbidity,breaks=c(0,10,15,20,25),
labels=c("5~10","10~15","15~20","20~25"),order=TRUE)
#随机生成的数据包含数值为5,breaks()函数是以5开始但不包含5,因此将breaks()函数的数值调整为0开始
#计算中心点,海南定位不太准,各省名称简称问题,手动进行赋值
mymapdata1<- as.data.frame(china_data[c("id", "lon", "lat", "name")])
midpos <- function(data1) mean(range(data1,na.rm=TRUE))
centers <- ddply(mymapdata1,.(name),colwise(midpos,.(lon,lat)))
centers$lon[centers$name=="海南省"] <- 109.94610
centers$lat[centers$name=="海南省"] <- 19.16312
centers$name_new <- substr(centers$name,1,2)
centers$name_new[centers$name_new=="黑龙"] <- "黑龙江"
centers$name_new[centers$name_new=="内蒙"] <- "内蒙古"
png("pic_result.png", width=30, height=20, units='cm', res = 800)
ggplot(china_data, aes(x = lon, y = lat)) +
geom_polygon(aes(group = group,fill = group1),colour="grey40",size=0.2) +
geom_text(aes(x=lon,y=lat,label=name_new),data= centers) +
coord_map("polyconic") +
scale_fill_manual(values = c("#EDF8E9", "#BAE4B3", "#74C476", "#31A354"))+
theme(
panel.grid = element_blank(),
panel.background = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
axis.title = element_blank(),
legend.position = c(0.9,0.35)
)+labs(fill = "morbidity\n(1/100 000)")
dev.off()
完整代码如下:
library(jsonlite)
library(ggplot2)
library(plyr)
library(dplyr)
json_data <- fromJSON("中国.json")
str(json_data)
province<-json_data$features$properties
province$id<-1:nrow(province)
provincedata<-json_data$features$geometry$coordinates
str(provincedata)
mapdata1<-data.frame() #list二级
mapdata2<-data.frame() #list一级
for( i in 1:length(provincedata)){
provincemapdata<-provincedata[[i]]
if (is.null(dim(provincemapdata))==TRUE){
for(m in 1:length(provincemapdata)){
provincemapdata1<- data.frame(provincemapdata[[m]])
names(provincemapdata1)<-c("lon","lat")
provincemapdata1$id<-i
provincemapdata1$group<-as.numeric(paste0(i,".",m,1))
provincemapdata1$order<-1:dim(provincemapdata1)[1]
mapdata1<-rbind(mapdata1,provincemapdata1)
}
}else{
dim(provincemapdata)=c(length(provincemapdata)/2,2)
provincemapdata2<-data.frame(provincemapdata)
names(provincemapdata2)<-c("lon","lat")
provincemapdata2$id<-i
provincemapdata2$group<-as.numeric(paste0(i,".",1))
provincemapdata2$order<-1:dim(provincemapdata2)[1]
mapdata2<-rbind(mapdata2,provincemapdata2)
}
mydatanew<-rbind(mapdata1,mapdata2)
}
mydatanew<-arrange(mydatanew,id,order)
set.seed(125)
province$morbidity<-round(runif(34,5,25),0) #随机生成数据
china_data<-merge(mydatanew,province[,c(-3,-4)],by="id")
china_data$group1<-cut(china_data$morbidity,breaks=c(0,10,15,20,25),
labels=c("5~10","10~15","15~20","20~25"),order=TRUE)
mymapdata1<- as.data.frame(china_data[c("id", "lon", "lat", "name")])
midpos <- function(data1) mean(range(data1,na.rm=TRUE))
centers <- ddply(mymapdata1,.(name),colwise(midpos,.(lon,lat)))
centers$lon[centers$name=="海南省"] <- 109.94610
centers$lat[centers$name=="海南省"] <- 19.16312
centers$name_new <- substr(centers$name,1,2)
centers$name_new[centers$name_new=="黑龙"] <- "黑龙江"
centers$name_new[centers$name_new=="内蒙"] <- "内蒙古"
png("pic_result.png", width=30, height=20, units='cm', res = 800)
ggplot(china_data, aes(x = lon, y = lat)) +
geom_polygon(aes(group = group,fill = group1),colour="grey40",size=0.2) +
geom_text(aes(x=lon,y=lat,label=name_new),data= centers) +
coord_map("polyconic") +
scale_fill_manual(values = c("#EDF8E9", "#BAE4B3", "#74C476", "#31A354"))+
theme(
panel.grid = element_blank(),
panel.background = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
axis.title = element_blank(),
legend.position = c(0.9,0.35)
)+labs(fill = "morbidity\n(1/100 000)")
dev.off()
所有数据均为模拟数据
分享的同时也是自我总结
以上是关于基于json数据对全国疫情数据可视化的主要内容,如果未能解决你的问题,请参考以下文章