XML/HTML/JSON——数据抓取过程中不得不知的几个概念
Posted 数据小魔方
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了XML/HTML/JSON——数据抓取过程中不得不知的几个概念相关的知识,希望对你有一定的参考价值。
之前写了很多网络数据数据抓取的案例,无论是关于R语言还是Python的,里面大量使用xml\html\css\ajax\json等这些概念,可是一直没有对这些概念做详细的梳理,导致很多小伙伴儿看的摸不着头脑。
近期基础的网抓教程告一段落,从今天起,给大家梳理一些常用的web概念(当然是一个外行小白的视角来进行讲解,如有不当之处,还请见谅)。概念的梳理对于整体网抓思路的开拓至关重要。
几天主要围绕三个核心概念来进行介绍:
xml
html
json
xml的官方解释是可扩展标记语言,主要用于数据传输,而HTML则是超文本标记语言,主要用于网页显示。
从语法上来讲,xml和html可以被归为一类,他们遵循的语法一致,只是在web中充当的角色和标签名称上有差异。
<?xml version="1.0" encoding="ISO-8859-1"?>
<note> <to>George</to> <from>John</from> <heading>Reminder</heading> <body>Don't forget the meeting!</body>
</note>一个典型的xml文档如上所示,第一行是xml的文档头声明,主要包含xml的版本、字符编码信息。之后的几行时xml文档的主题内容。该xml文件包含的内容信息均以标签对进行封装,每一个值都包括在起始标签(<label>
所以上面文档的内容逻辑是:
note --to =George --from =John --heading=Reminder --body =Don't forget the meeting!你也可以把它理解成键值对形式:(key-value),只是键名都是头尾对称的。所有的<label>
而html与xml的主要区别是,它有约定俗成的固定文档结构,有预定义的一系列固定标签。
<!DOCTYPE html>
<html>
<head>
<title>我的第一个 HTML 页面</title>
</head>
<body>
<p>body 元素的内容会显示在浏览器中。</p>
<p>title 元素的内容会显示在浏览器的标题栏中。</p>
</body>一个典型的html文档如上所示,第一句同xml,仍然是html文档的头部声明,告知html的版本信息。html的固定格式体现在,每一个html的内容构成,都要包含head和body,head用于解释该html的标题、编码方式以及引用的外部文档信息,body则用于存放将呈现在浏览器中的内容信息。不仅如此,因为html文档最终是要通过浏览器渲染后,呈现给人们友好的阅览体验,html文档内部预定义了大量的固定标签,如各种表单、列表、区块、交互菜单等内容。详细的html内部标签关键词可以参阅w3c的参考手册。
http://www.w3school.com.cn/html/index.asp
单纯的html仅仅是静态文本,浏览器的渲染是基于html文档中各级标签内所定义的属性(<label style='fashion'>
<link media="all" type="text/css" rel="stylesheet" href="https://edu.hellobi.com/libs/formvalidation/css/formValidation.min.css">浏览器在调用html文档并同时按照所加载的css样式表对整个页面完成渲染,所以才有了看上去非常漂亮的网页。
可以看到html虽然与xml的语法一脉相承,但是html因为承担的角色比较特殊,它的结构体系有固定的模板,有大量常用的预定义标签,内部还需要嵌入css样式表,引用js动态脚本,看起来整个结构非常庞大。而xml则相当精简,适合用于单纯的数据存储与传输。
以上是关于xml与html的大致差异(想要了解一些深入的差异或概念,仍然需要去w3c深挖教程)。
json
JSON(javascript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。它起源于JavaScript的数据对象,之后独立成为一种web较为流行的数据交换标准。
json的语法,是非常明显的键值对结构,比较利于理解:
以上xml文档如果使用json来写,应该是这样的。
{ "note":{ "to":"George", "from":"John", "heading":"Reminder", "body":"Don't forget the meeting!" } }json的语法,是非常明显的键值对(key-value),key不允许重复,且需以双引号包括,键值对中允许嵌套,值可以为字符(使用双引号或者单引号包括)、数值、布尔型(true\false)、数组([1,2,3,5])或者null。同级元素间以“,”隔开,花括号包含的的内容被称为对象,键值对中值也允许为对象。
json在某种程度上跟xml有点像,json也是只有一套语法标准,不存在固定的文档模板或者预定义标签(或者说键名),这样xml和json都可以用于书写自定义的数据对象。
讲到这里已经可以大概看出来xml与json的区别了。两者都可以作为数据存储对象,有着类似键值对的语法结构。但是xml由于是对称标签结构,而json仅适用“{”,“[”,“<”,“>”等标点符号来作为层级和标签起始点结构,所以json省去了大量冗余字符信息,这也是网络上争吵不断的关于xml和json孰优孰略的焦点之一。
接下来从应用角度来审视一下xml和json在桌面环境中的实际应用。
在当前桌面端以及web端应用中,xml主要用于书写配置文件,json则用在web场景下的http请求参数提交或者数据返回。当然以上强调了主要,json也可以用于桌面软件配置文件,xml也可以用于网络文件传输和数据交换。
我们熟知的office平台,所有的模板文件、配色文件均以xml书写的。
<?xml version="1.0" encoding="utf-8"?>
<a:clrScheme xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main" name="Aspect"> <a:dk1> <a:sysClr val="windowText" lastClr="000000"/> </a:dk1> <a:lt1> <a:sysClr val="window" lastClr="FFFFFF"/> </a:lt1> <a:dk2> <a:srgbClr val="323232"/> </a:dk2> <a:lt2> <a:srgbClr val="E3DED1"/> </a:lt2> <a:accent1> <a:srgbClr val="F07F09"/> </a:accent1> <a:accent2> <a:srgbClr val="9F2936"/> </a:accent2> <a:accent3> <a:srgbClr val="1B587C"/> </a:accent3> <a:accent4> <a:srgbClr val="4E8542"/> </a:accent4> <a:accent5> <a:srgbClr val="604878"/> </a:accent5> <a:accent6> <a:srgbClr val="C19859"/> </a:accent6> <a:hlink> <a:srgbClr val="6B9F25"/> </a:hlink> <a:folHlink> <a:srgbClr val="B26B02"/> </a:folHlink>
</a:clrScheme>这是一个典型的office配色文档。(注意office平台的诸多配置文件都是多程序共享的,配色文件在Word、excel、ppt中是共享的)。
但是在微软的新版BI工具中,PowerBI的配色文件已经开始使用json语法来书写了。
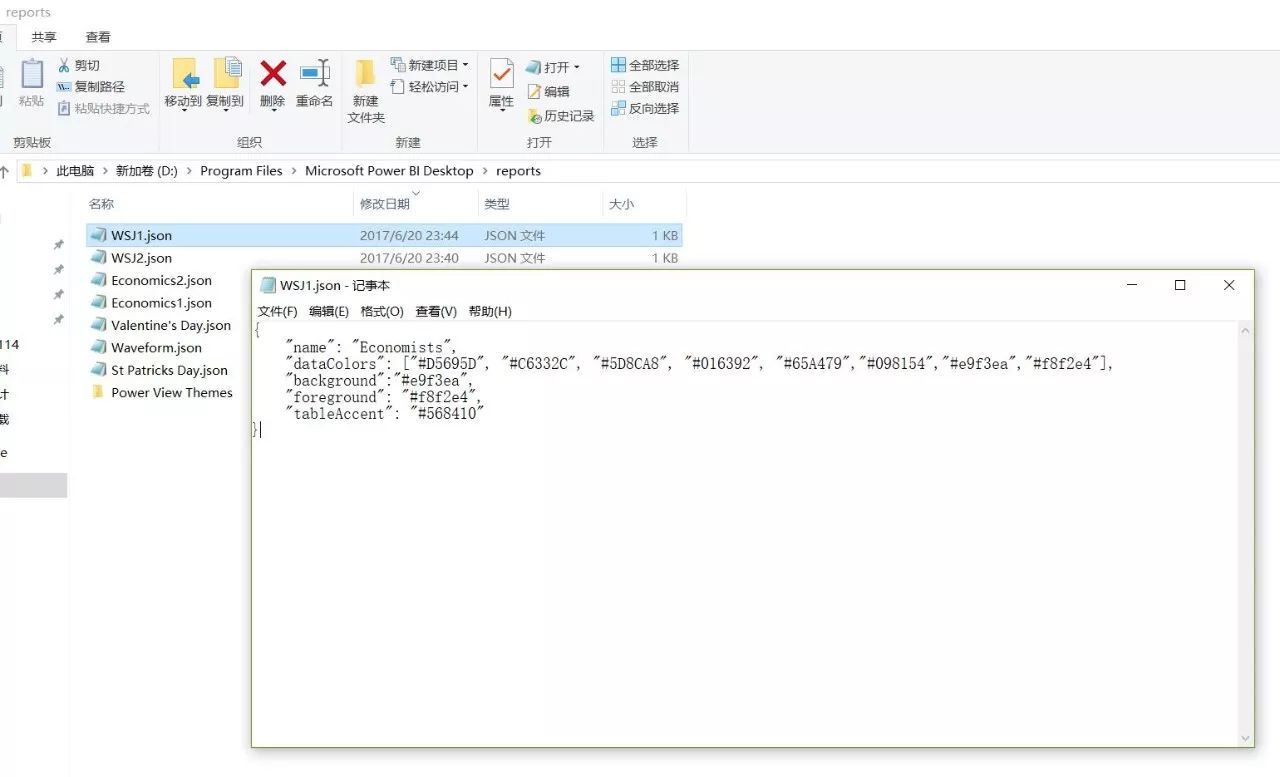
{ "name": "Economists", "dataColors": [
"#D5695D", "#C6332C", "#5D8CA8", "#016392", "#65A479", "#098154", "#e9f3ea", "#f8f2e4" ], "background": "#e9f3ea", "foreground": "#f8f2e4", "tableAccent": "#568410"
}这是一个PowerBI的配色模板文件,使用json书写的,json文件仅适用后缀名(.json)标识,没有文档头(这一点与xml有区别)。可以很明显的看到,该文件定义了五个键值对,该份配色表的名称,以及一个包含8个颜色色值的数组,背景色、前景色、表格底色。
在商务可视化场景中非常出色的BI工具Tabeau,也使用了xml作为配色模板的书写语言:
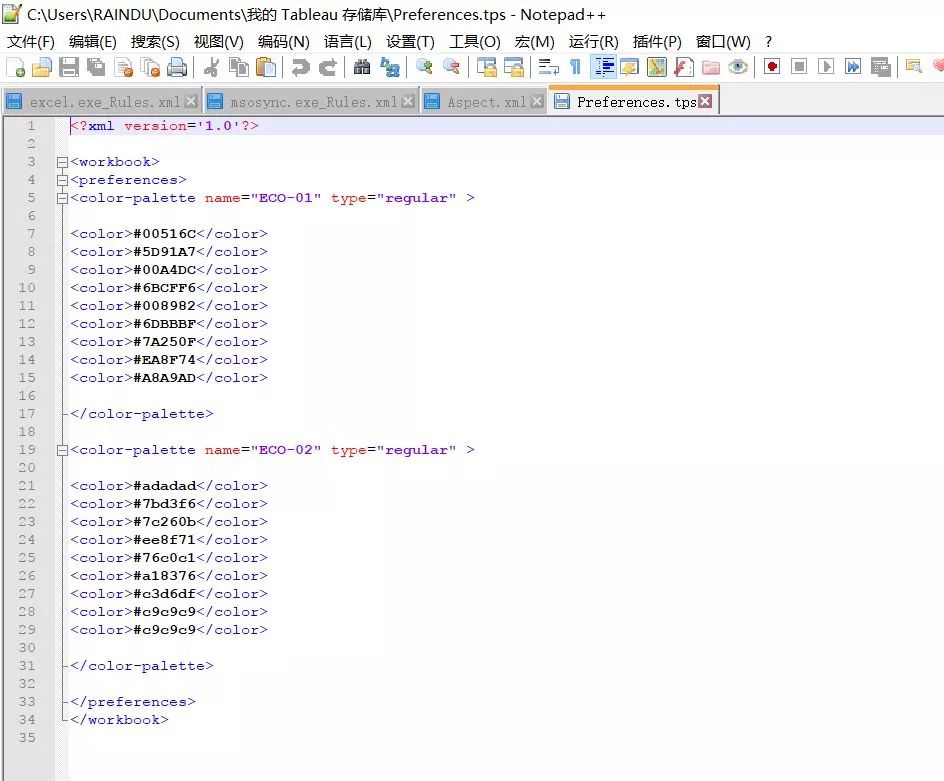
<?xml version="1.0" encoding="utf-8"?>
<workbook> <preferences> <color-palette name="ECO-01" type="regular"> <color>#00516C</color> <color>#5D91A7</color> <color>#00A4DC</color> <color>#6BCFF6</color> <color>#008982</color> <color>#6DBBBF</color> <color>#7A250F</color> <color>#EA8F74</color> <color>#A8A9AD</color> </color-palette> <color-palette name="ECO-02" type="regular"> <color>#adadad</color> <color>#7bd3f6</color> <color>#7c260b</color> <color>#ee8f71</color> <color>#76c0c1</color> <color>#a18376</color> <color>#c3d6df</color> <color>#c9c9c9</color> <color>#c9c9c9</color> </color-palette> </preferences>
</workbook>这一份配色表,定义了两套色板,主体是xml语法,但是格式化之后,非常简单易懂。
随便挑了三个软件的配置文件,结果有两个时xml写的,一个是json的。从目前的发展趋势来看,xml定义的标准比较早,属于先发优势,json则因为轻量级,冗余信息少,应用场景在逐步扩展。
以上三个场景均是在桌面端,接下来让我们从web端场景下来看一看:
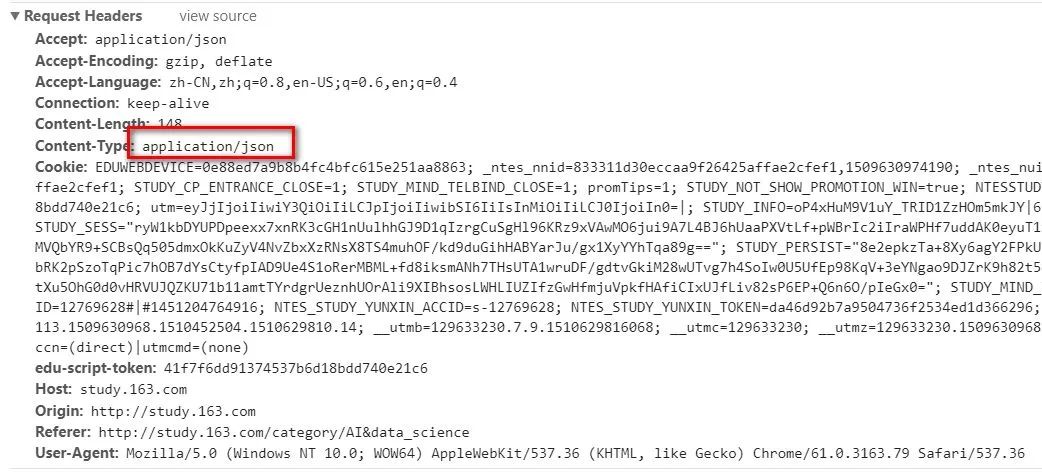
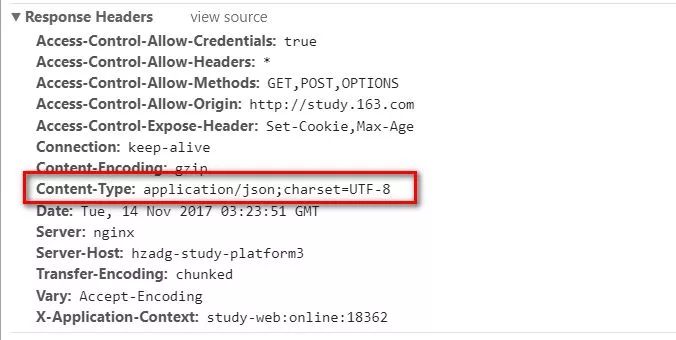
网易云课堂的课程内容信息是异步加载,它的请求提交参数和相应数据格式均为json格式的。
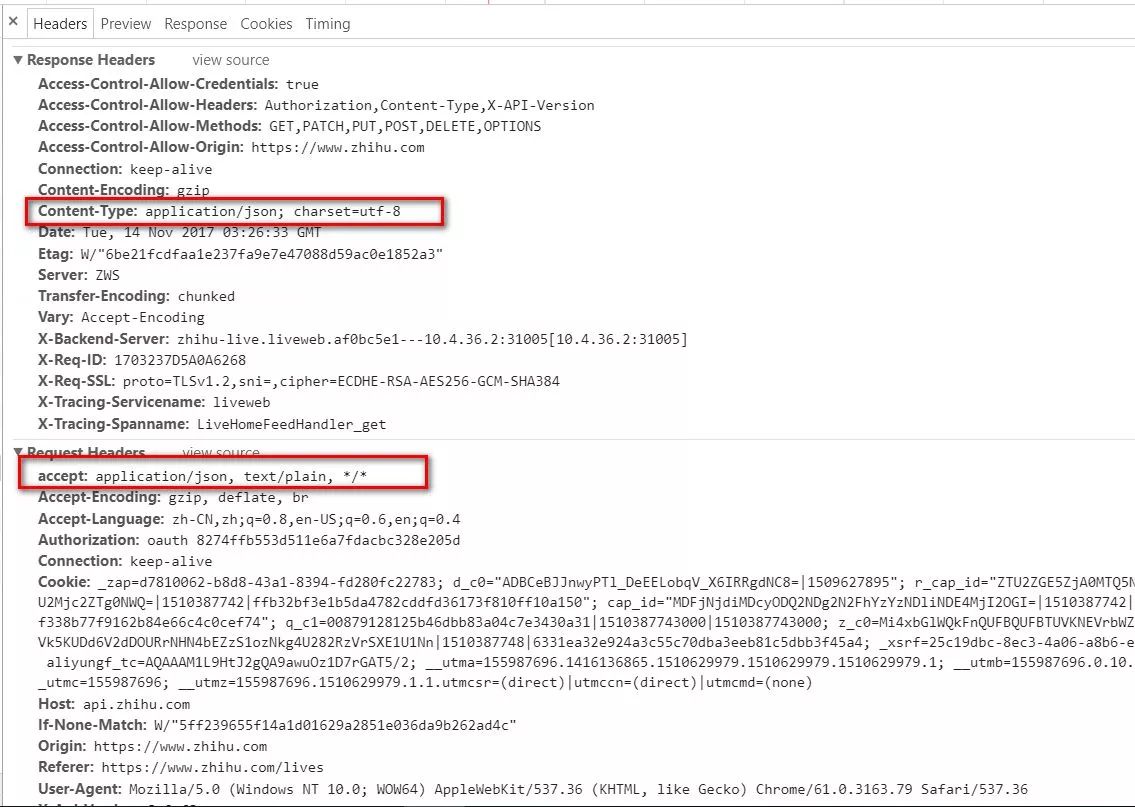
知乎live的课程信息,参数提交和相应也是首选json。
B站的视频信息列表,相应数据格式josn格式的的。
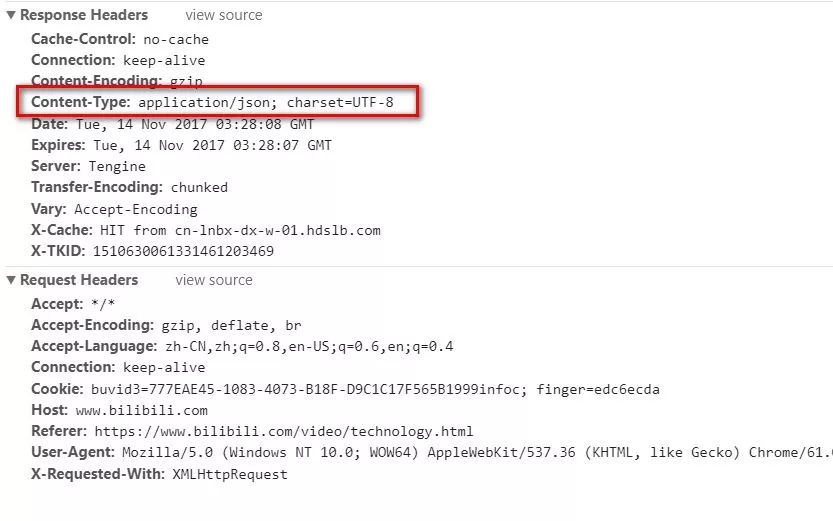
豆瓣电影短评的数据请求数据返回是html格式的(可以归为xml类,因为语法和解析工具都是一致的)。
可以看到,主流网站涉及异步加载的内容,大多都选择了json作为数据交换格式,而静态网站或者不愿意开放api的网站,仍然使用html/xml较多。但是随着今后web端ajax技术扩散程度的加深,相信json标准会有更广泛的应用。
以上我列举了xml/html和json在桌面端和web的应用案例(非随机抽的,没有任何代表性)。
说了这么多,xml和json与我们想要深入学习的网络数据抓取之间,到底什么关系呢。
xml和json在某种程度上几乎决定了你在写数据抓取程序时所使用的技术方案和处理流程。
我们知道在抓取数据的流程中,成功构造请求是第一步,涉及请求构造的篇章,我已经在之前讲过很多,无论是GET请求还是POST请求,无论是传递参数,还是传递表单。
xml/html和json则涉及到网络数据抓取的第二步——网页与数据解析。
因为xml/html是标记语言,虽然在某种程度上具有key-value的形式,但是因为标签对这种形式,无论是R语言还是Python都没法直接将它转化为关系表。所以请求到的xml/html需要使用Xpath或者css表达式进行提取,关于这两种技术,前面有专门的篇章讲解。
xml和html语法一致,所以使用的解析工具也一致。
json本身就是半结构化数据,作为流行且通用的数据交换格式,R语言和Python都有现成的接口工具可以调用,以及半结构化工具的对标容器。json还有一种应用场景即是noSQL数据库的存储结构,典型如mongoDB,不过在mongodb中,将json标准扩展为bson,增加了其作为容器的性能和兼容性。mongoDB和R与Python都有结构工具可以连接。
R语言中的jsonlite包,有现成的fromJSON()函数,可以直接将json返回值转换为list或者data.frame(是否可以取决于json内部结构是否符合关系型标准)。Python中的json包,提供了json.loads()用于加载并转换json数据为dict。
本文内容比较散,简要介绍了xml和json的概念、语法、应用场景以及与R语言和Python的常用接口转换函数。对xml及其解析工具的的掌握决定着html网页解析效率,对json的掌握则决定着调用服务器api并处理返回值的效率,所以xml和json相关内容在网络数据获取中至关重要。
好在这两种技术涉及到的技术工具,之前陆陆续续都有过简要讲解,当然这些内容每一块单列出来都足够庞大,想要深入了解需要参考专业技术书籍或者W3C的在线文档,但是因为都有现成的函数封装,我们几乎不用理解底层就可以轻松完成网页解析和数据整理。
常用xml/json/html格式化工具:
http://tool.oschina.net/codeformat/xml/
http://www.json.cn/#
https://www.bejson.com/
http://tool.chinaz.com/Tools/Unicode.aspx
http://tool.oschina.net/encode
在线课程请点击文末原文链接:
往期案例数据请移步本人GitHub:
https://github.com/ljtyduyu/DataWarehouse/tree/master/File
欢迎关注数据小魔方qq交流群
以上是关于XML/HTML/JSON——数据抓取过程中不得不知的几个概念的主要内容,如果未能解决你的问题,请参考以下文章