“CSV格式转Json格式”Shell脚本解析
Posted Linux脚本之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“CSV格式转Json格式”Shell脚本解析相关的知识,希望对你有一定的参考价值。
在日常项目开发、运维中,数据共享交换大部分文件格式是Json格式的文件。但是由于一些原因,从数据库导出的数据是逗号分隔的CSV文件。便于数据处理,需要将CSV格式的文本转换为Json格式的文本。
本文以日常数据维护中遇到的场景为例,逐步讲解如何使用Linux Shell脚本进行文本文件格式转换。主要使用gawk命令进行数据处理与格式转换。
1需求说明
本场景的数据转换有下面几条需求:
(1)将CSV格式文本转换为Json格式;
(2)将第四个时间字段“2017-03-2500:47:59”转换为“2017-03-25:00:47:59”格式;
(3)将CSV文件每行末尾的回车符“\r”去掉;
(4)将转换后的Json文件,按照第四个时间字段,分隔为一分钟一个文件。
2数据格式
2.1 CSV数据格式
待转换的CSV原始数据如下图所示:
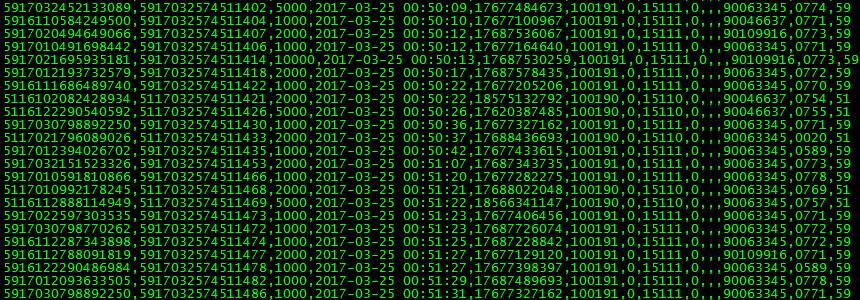
每行数据是数据库筛选出的一条记录,共有14个字段,使用半角逗号“,”分隔。CSV文本行如下:
5916122790972389,5917032574511090,1000,2017-03-25 00:47:59,17677218108,100191,0,15111,0,,,90063345,9600,59 |
2.2 Json数据格式
转换后的Json数据如下图所示:
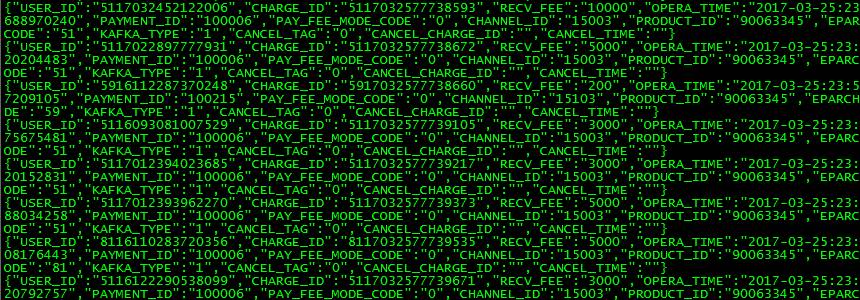
每行数据是一个Json格式文本,开始于“USER_ID”字段,结束于“CANCEL_TIME”字段。其中添加一个值固定为“1”的“KAFKA_TYPE”字段。Json文本行如下:
{"USER_ID":"5116122290538099","CHARGE_ID":"5117032577739671","RECV_FEE":"3000","OPERA_TIME":"2017-03-25:23:58:24","SERIAL_NUMBER":"176 20792757","PAYMENT_ID":"100006","PAY_FEE_MODE_CODE":"0","CHANNEL_ID":"15003","PRODUCT_ID":"90063345","EPARCHY_CODE":"0020","PROVINCE_C ODE":"51","KAFKA_TYPE":"1","CANCEL_TAG":"0","CANCEL_CHARGE_ID":"","CANCEL_TIME":""} |
3运行结果
编写“csv2json.sh”格式转换脚本,运行命令如下:
./csv2json.sh 0325.txt files/ |
参数“0325.txt”是CSV格式文件,参数“files/”是转换划分为Json小文件后存放的目录。
转换运行结果如下图:
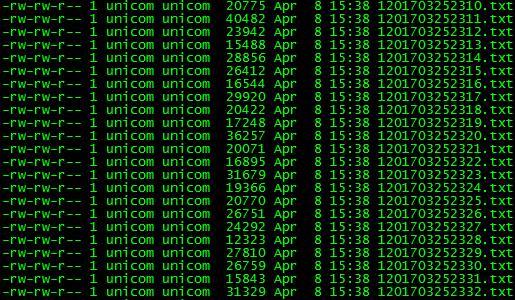
文件名“1201703252321.txt”格式说明,第一位“1”标识数据来源于哪个数据库表。后面“201703252321”表示“yyyyMMddHHmm”。
4完整脚本
脚本文件“csv2json.sh”的全部内容如下所示:
#! /bin/bash
# params like: ./csv2json.sh 0325.txt files/ # $1 --> 0325.txt # $2 --> files/ input=$1 outdir=$2 tmpinput=$input"-tmp"
# input line format # 5917022397015166,5917032574511010,1000,2017-03-25 00:47:29,17677127609,100191,0,15111,0,,,90109916,0771,59 # USER_ID,CHARGE_ID,RECV_FEE,RECV_TIME,SERIAL_NUMBER,PAYMENT_ID,PAY_FEE_MODE_CODE,CHANNEL_ID,CANCEL_TAG, # CANCEL_CHARGE_ID,CANCEL_TIME,PRODUCT_ID,EPARCHY_CODE,PROVINCE_CODE
# 生成一个完整的Json格式文件“0325.txt-tmp” lineformat="{\"USER_ID\":\"%s\",\"CHARGE_ID\":\"%s\",\"RECV_FEE\":\"%s\",\"OPERA_TIME\":\"%s\",\"SERIAL_NUMBER\":\"%s\",\"PAYMENT_ID\" :\"%s\",\"PAY_FEE_MODE_CODE\":\"%s\",\"CHANNEL_ID\":\"%s\",\"PRODUCT_ID\":\"%s\",\"EPARCHY_CODE\":\"%s\",\"PROVINCE_CODE\":\"%s\",\"KA FKA_TYPE\":\"%s\",\"CANCEL_TAG\":\"%s\",\"CANCEL_CHARGE_ID\":\"%s\",\"CANCEL_TIME\":\"%s\"}\n" cat$input|gawk-v lnformat=$lineformat-v tmpinput=$tmpinput-F',''{ if(NF==14) { userId=$1; chargeId=$2; recvFee=$3; recvTime=$4; gsub(" ",":",recvTime); serialNumber=$5; paymentId=$6; payFeeModeCode=$7; channelId=$8; cancelTag=$9; cancelChargeId=$10; cancelTime=$11; productId=$12; eparchyCode=$13; provinceCode=$14; gsub("\r","",provinceCode); kafkaType="1"; printf(lnformat,userId,chargeId,recvFee,recvTime,serialNumber,paymentId,payFeeModeCode,channelId,productId,eparchyCode,provinceC ode,kafkaType,cancelTag,cancelChargeId,cancelTime) >> tmpinput; } }' # 将Json格式文件“0325.txt-tmp”分隔为每分钟一个文件,输出到“files”目录下 cat$tmpinput|gawk-F','-v outdir=$outdir'{ idx=index($0,"OPERA_TIME"); if(idx>0) { time=substr($0,idx+13,19); gsub(/[-:]/,"",time); time=substr(time,1,12); filename="1"time".txt"; filepath=outdir""filename; print($0)>>filepath; close(filepath); } }' # 删除Json格式文件“0325.txt-tmp” rm -f $tmpinput |
该脚本主要分为三部分:
CSV格式文件转换为Json格式临时文件;Json格式临时文件分隔为每分钟一个文件;删除Json格式的临时文件。
5脚本解析
5.1 脚本传参
input=$1 outdir=$2 |
上面“$1”和“$2”表示运行脚本文件时,给脚本文件传入的两个参数。分别表示“CSV文件名”和“输出的文件目录”。
5.2 格式字符串
lineformat="{\"USER_ID\":\"%s\",\"CHARGE_ID\":\"%s\",\"RECV_FEE\":\"%s\",\"OPERA_TIME\":\"%s\",\"SERIAL_NUMBER\":\"%s\",\"PAYMENT_ID\" :\"%s\",\"PAY_FEE_MODE_CODE\":\"%s\",\"CHANNEL_ID\":\"%s\",\"PRODUCT_ID\":\"%s\",\"EPARCHY_CODE\":\"%s\",\"PROVINCE_CODE\":\"%s\",\"KA FKA_TYPE\":\"%s\",\"CANCEL_TAG\":\"%s\",\"CANCEL_CHARGE_ID\":\"%s\",\"CANCEL_TIME\":\"%s\"}\n" |
“lineformat”是用于gawk内部格式化输出函数“printf”的格式化字符串,类似C、Java等格式化输出字符串,“%s”表示字符串占位符。一共15个“%s”占位符。“\n”表示换行符。
5.3 gawk传参
-v lnformat=$lineformat-v tmpinput=$tmpinput |
在gawk语法开头,使用“-v”向gawk内部传参。一个“-v”可以传一个参数。
5.4 gawk分隔符
-F',' |
“-F”表示自定义字段分隔符,本文分隔符是逗号“,”。
5.5 gawk分隔字段数变量
if(NF==14) {…} |
“NF”是gawk内置变量,表示当前行分隔的字段个数。本文每行都是14个字段。
5.6 获取gawk分隔字段
userId=$1; chargeId=$2; recvFee=$3; |
“$1”,“$2”,“$3”分别表示分隔后的第一个字段,第二个字段,第三个字段。“$0”表示当前行的内容。
5.7 gawk内部字符串替换
gsub(" ",":",recvTime); gsub("\r","",provinceCode); gsub(/[-:]/,"",time); |
“gsub”函数表示字符串替换,第一个gsub含义是将recvTime中的空格" "替换为冒号":",第二个gsub含义是将回车符替换为空字符串。第三个gsub含义是去除时间字符串中的“-”和“:”字符,由“2017-03-25:00:47:29”格式转换为“20170325004729”格式。需要注意的是gsub函数,第三个参数作为目标字符串,替换后的值依然存储在该参数上。
5.8 格式化输出
printf(lnformat,userId,chargeId,…,cancelTime) >> tmpinput; |
“printf”是字符串格式化输出函数,第一个参数是格式化字符串,后续参数跟格式化占位符“%s”保持一致。“>> tmpinput”表示将格式化输出的内容重定向追加写入到文件“tmpinput”里。
5.9 字符串查找
idx=index($0,"OPERA_TIME"); |
“index”为gawk字符串查找函数,返回开始字符下标(最小从1开始),如果返回0表示没有匹配到。
5.10 截取子串
time=substr(time,1,12); |
“substr”为gawk字符串截取函数,第二个参数是开始位置下标,第三个参数是截取长度。
5.11 文件追加&关闭
print($0)>>filepath; close(filepath); |
“>>”表示文件追加,“close”是gawk文件关闭函数。
掌握了gawk强大的文本处理能力,能够迅速、快捷地完成各类数据处理和数据分析工作。 |
以上是关于“CSV格式转Json格式”Shell脚本解析的主要内容,如果未能解决你的问题,请参考以下文章