文件存储(TXT和JSON)
Posted 杨少侠Studio
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文件存储(TXT和JSON)相关的知识,希望对你有一定的参考价值。
本文参考自崔庆才老师所做《Python3网络爬虫开发实战》
https://germey.gitbooks.io/python3webspider/content/
本文共有约1000字,建议阅读时间10分钟,代码较多,请注重理论与实践相结合
觉得文章比较枯燥和用电脑观看的可以点击阅读原文即可跳转到CSDN网页
目录:
什么是文件存储?
TXT文本存储
JSON文件存储
CSV文件存储
关系型数据库存储
mysql存储
非关系型数据库存储
MongoDB存储
Redis存储
一、什么是文件存储?
包括下载图片,下载文件等等的这些操作都算是文件存储,而文件存储的形式有很多,Eg:TXT纯文本形式、JSON格式、CSV格式等等,经过上一期的街拍小姐姐抓取之后或许会有一些小伙伴对这一块内容有点疑问,这一次就给大家介绍一下。
二、TXT文本存储
1.将数据保存到TXT文本的操作非常简单,而且TXT文本几乎兼容任何平台,但是这有个缺点,那就是不利于检索。所以如果对检索和数据结构要求不高,追求方便第一的话,可以采用TXT文本存储。本节中,我们就来看下如何利用Python保存TXT文本文件。
本节目标:保存知乎发现页面的热门话题部分,将问题和打啊保存成文本形式(https://www.zhihu.com/explore)
2.基本实例
import requests
from pyquery import PyQuery as pq
url = 'https://www.zhihu.com/explore'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
response = requests.get(url,headers = headers)
doc = pq(response.text)
#print(doc.text())
items = doc('.explore-feed').items()
for item in items:
question = str(item.find('h2').text())
#print(question)
author = item.find('.author-link-line').text()
answer = pq(item.find('.content').html()).text()#.html返回<title>hello</title>
#print(answer)
file = open('F:\explore.txt','a',encoding = 'utf-8')#“a”表示以追加的方式写入文本
file.write('\n'.join([question,author,answer]))
file.write('\n'+ '=' *50 + '\n')
file.close()
3.结果输出
在相应的目录下就可以看到explore.txt的文件
4.打开方式
在刚才那个实例中open()方法的第二个参数设置成了a,这样在每次写入文本时不会清空源文件,而是在文件末尾写入新的内容,这是一种文件打开方式。关于文件的打开方式,其实还有其他几种,这里简要介绍一下。
r:以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。rb:以二进制只读方式打开一个文件。文件指针将会放在文件的开头。r+:以读写方式打开一个文件。文件指针将会放在文件的开头。rb+:以二进制读写方式打开一个文件。文件指针将会放在文件的开头。w:以写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。wb:以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。w+:以读写方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。wb+:以二进制读写格式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。a:以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。ab:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。a+:以读写方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,则创建新文件来读写。ab+:以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。如果该文件不存在,则创建新文件用于读写。
三、JSON文件存储
1. JSON,全称为javascript Object Notation, 也就是JavaScript对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。
对象与数组
对象:它在JavaScript中使用 {} 包裹起来的内容,数据结果为{key:value,key:value.......}的键值结构。在面向对象语言中,key为对象属性,value为对应的值。键名可以用整数和字符串来表示。值的类型可以是任意类型
数组:数组在JavaScript中是方括号
[]包裹起来的内容,数据结构为["java", "javascript", "vb", ...]的索引结构。在JavaScript中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引用得多。同样,值的类型可以是任意类型。实例:
[{
"name": "Bob",
"gender": "male",
"birthday": "2018-01-02"
}, {
"name": "Selina",
"gender": "female",
"birthday": "2019-01-02"
}]由中括号包围的就相当于列表类型,列表中的每个元素可以是任意类型,这个示例中它是字典类型,由大括号包围。
JSON可以由以上两种形式自由组合而成,可以无限次嵌套,结构清晰,是数据交换的极佳方式。
2.读取JSON
>>> import json
>>> str = '''
[{
"name": "Bob",
"gender": "male",
"birthday": "1992-10-18"
}, {
"name": "Selina",
"gender": "female",
"birthday": "1995-10-18"
}]
'''
>>> print(type(str))
<class 'str'>
>>> data = json.loads(str)
>>> data
[{'name': 'Bob', 'gender': 'male', 'birthday': '1992-10-18'}, {'name': 'Selina', 'gender': 'female', 'birthday': '1995-10-18'}]
>>> type(data)
<class 'list'>
<class 'list'>
>>> data[0]['name']
'Bob'
>>> data[0].get('name')
'Bob'
>>> data[0].get('age')#在原字典中该键名不存在,此时默认会返回None
>>> data[0].get('age',25)#也可以手动添加
25
在Python中,可以直接调用json库的loads()方法将json文本字符串转为JSON对象,可以通过dump()方法将JSON对象转为文本字符串
值得注意的是:json的数据需要用双引号包围,不能使用单引号!!!
>>> import json
>>> str = '''
[{
'name:'Bob'',
'gender':'male',
'birthday':'1992-10-18'
}]
'''
>>> data = json.loads(str)Traceback (most recent call last):
File "<pyshell#28>", line 1, in <module>
data = json.loads(str)
File "C:\Users\ShiEnbaby\AppData\Local\Programs\Python\Python36\lib\json\__init__.py", line 354, in loads
return _default_decoder.decode(s)
File "C:\Users\ShiEnbaby\AppData\Local\Programs\Python\Python36\lib\json\decoder.py", line 339, in decode
obj, end = self.raw_decode(s, idx=_w(s, 0).end())
File "C:\Users\ShiEnbaby\AppData\Local\Programs\Python\Python36\lib\json\decoder.py", line 355, in raw_decode
obj, end = self.scan_once(s, idx)
json.decoder.JSONDecodeError: Expecting property name enclosed in double quotes: line 3 column 1 (char 4)
从json文本中读取内容:
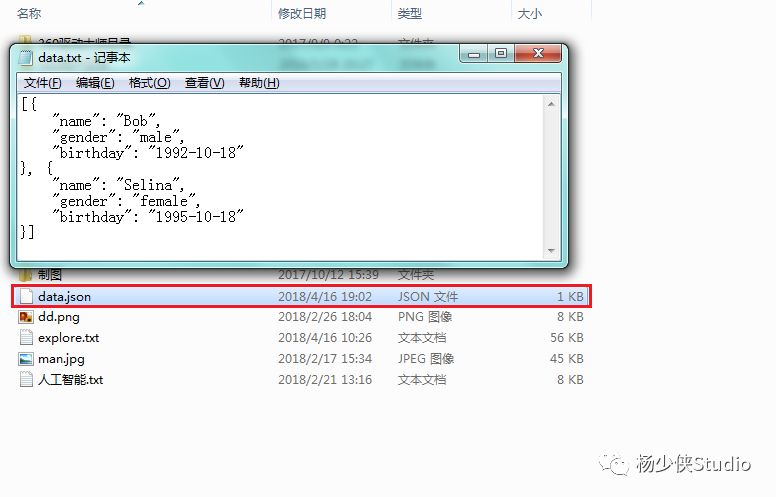
import json
>>> with open('F:\data.txt','r')as file:
str1 = file.read()
data = json.loads(str1)
print(data)
[{'name': 'Bob', 'gender': 'male', 'birthday': '1992-10-18'}, {'name': 'Selina', 'gender': 'female', 'birthday': '1995-10-18'}]
3.输出JSON
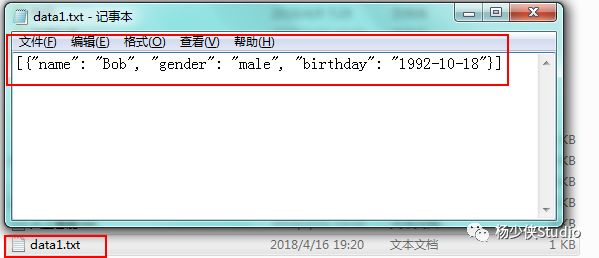
调用dumps()方法将JSON对象转化为字符串:
>>> import json
>>> with open('F:\data1.txt','w')as file:
print(type(data))
file.write(json.dumps(data))
#使用write()方法写入文本
<class 'list'>
61
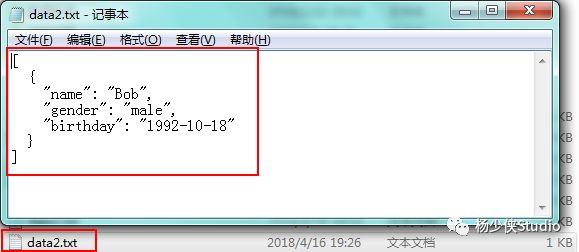
若想保存成JSON格式,可以在加一个参数indent,代表缩进字符数:
>>> import json
>>> with open('F:\data2.txt','w')as file:
print(type(data))
file.write(json.dumps(data,indent=2))
<class 'list'>
81

如果JSON中包含中文字符串会如何呢?
>>> import json
>>> data = [{
'name': '24K纯帅',
'gender': '男',
'birthday': '1992-10-18'
}]
>>> with open('F:\data2.txt','w')as file:
file.write(json.dumps(data,indent=2))
95
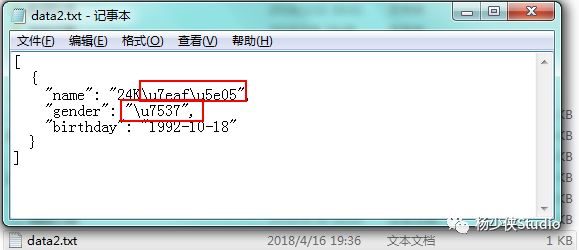
写入结果:中文字符都编程了Unicode字符,为了输出中文,需要指定ensure_ascii为False:
>>> with open('F:\data2.txt','w')as file:
file.write(json.dumps(data,indent=2,ensure_ascii = False))
点击阅读原文
可跳转到崔庆才老师知乎爬虫原文网页
以上是关于文件存储(TXT和JSON)的主要内容,如果未能解决你的问题,请参考以下文章