json库
Posted 海哥python
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了json库相关的知识,希望对你有一定的参考价值。
JSON (javascript Object Notation) is a subset of JavaScript syntax (ECMA-262 3rd edition) used as a lightweight data interchange format.
序列化
序列化 (Serialization)将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。 序列化使其他代码可以查看或修改那些不序列化便无法访问的对象实例数据。
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
一、json.dumps
将python类型对象序列化为字符串
语法
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, encoding="utf-8", default=None, sort_keys=False, **kw)
Skipkeys:默认值是False,如果dict的keys内的数据不是python的基本类型(str,unicode,int,long,float,bool,None),设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key
ensure_ascii:默认值True,如果dict内含有non-ASCII的字符,则会类似\uXXXX的显示数据,设置成False后,就能正常显示
indent:应该是一个非负的整型,如果是0,或者为空,则一行显示数据,否则会换行且按照indent的数量显示前面的空白,这样打印出来的json数据也叫pretty-printed json
separators:分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(',',':');这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
encoding:默认是UTF-8,设置json数据的编码方式。
sort_keys:将数据根据keys的值进行排序。
这样有啥用呢?
比如进行一次很消耗时间的计算,步骤依次为a>b>c>d>e。正常来说为了得到e,我们必须从a开始,依次运行直到运行到e为止得到我们需要的e。
但是通过dump,我们可以把a、b、c、d、e每个步骤的运行情况全部dump下来,这样如果程序在c出错,我们不用从a开始,只需要从c开始即可。而想实现这功能,可以使用dump,将各种对象dump保存下来
1.1 dict
import json
dict_obj = {'key1':'value1','key2':'value2'}
#打印dict_obj类型
print('dict_obj:'type(dict_obj))
#将python的dict对象 序列化为字符串
dict_str = json.dumps(dict_obj)
print('dict_str:',type(dict_str))<class 'dict'> dict_obj
<class 'str'> dict_str1.2 list
list_obj = "[1,2,3,4,4]"
print('list_obj:',type(list_obj))
#将python的list对象 序列化为字符串
list_str = json.loads(list_obj)
print('list_str:', type(list_str))list_obj: <class 'str'>
list_str: <class 'list'>1.3 int
int_obj = 1234
print('int_obj:',type(int_obj))
#将python的list对象 序列化为字符串
int_str = json.dumps(int_obj)
print('int_str:', type(int_str))int_obj: <class 'int'>
int_str: <class 'str'>二、json.loads
将字符串序列化为python类型对象
语法
json.loads(s[, encoding[, cls[, object_hook[, parse_float[, parse_int[, parse_constant[, object_pairs_hook[, **kw]]]]]]]])
2.1 dict_str
import json
dict_str = '{"k1":"v1","k2":"v2"}'
print('dict_str:',type(dict_str))
dict_obj = json.loads(dict_str)
print('dict_obj:',type(dict_obj))
#判断dict_str与dict_obj是否相同
print(dict_str == dict_obj)
#试验下转化后的dictobj字典特性
print(dict_obj['k1'])dict_str: <class 'str'>
dict_obj: <class 'dict'>
False
v12.2 int_str
int_str = "1234"
print('int_str:',type(int_str))
int_obj = json.loads(int_str)
print('int_obj:',type(int_obj))
#判断int_str与int_obj是否相同
print(int_str == int_obj)
#试验下int_obj列表特性
print(int_obj*3)int_str: <class 'str'>
int_obj: <class 'int'>
False
37022.3 list_str
list_str = "[1,2,3,4,4]"
print('list_str:',type(list_str))
list_obj = json.loads(list_str)
print('list_obj:', type(list_obj))
#判断list_str与list_obj是否相同
print(list_str==list_obj)
#检查下list_obj是否具有集合特性
print(list_obj.count(4))
print(list_obj+[1,2,3])list_str: <class 'str'>
list_obj: <class 'list'>
False
2
[1, 2, 3, 4, 4, 1, 2, 3]a = set()a.add('a')a.add('c')print(a){'a', 'c'}s = json.loads('1')print(type(s))<class 'int'>二、文件上的json操作
上面我们已经了解了dumps和loads各自的功能,现在我们在学习下dump和load,他们可以在文件(txt、json、db数据库等)上进行json操作。这里我们以字典为例:
2.1dump操作
这里我建议大家不适用json库提供dump写入文件操作,因为大家自己都很熟悉open写入操作,而且自己熟悉的open写起来很方便好用。
2.1.1 open写入txt
open写入,相当于json.dump(str,file)
import json
import os
#注意字典中的元素使用双引号
dict_obj1= {"key1":"value1","key2":"value2"}
dict_obj2 = {"key2":"value2","key3":"value"}
#将python的dict对象 序列化为字符串,并写入
with open('test.txt','w') as fp:
dict_str1 = json.dumps(dict_obj)
#换行,方便后续load
fp.write(dict_str1+"\n")
dict_str2 = json.dumps(dict_obj)
fp.write(dict_str2+"\n")2.1.2 open写入json文件
dict2_obj1 = {"china":"asian","england":"euro"}
dict2_obj2 = {"chinasss":"asian","england":"euro"}
#将python的dict对象 序列化为字符串,并写入
with open('test.json','w') as fp:
dict2_str1 = json.dumps(dict2_obj1)
dict2_str1 = json.dumps(dict2_obj1)
fp.write(dict2_str1+"\n")
fp.write(dict2_str2+"\n")2.1.3 open写入db文件
dict2_obj1 = {"china":"asian","england":"euro"}
dict2_obj2 = {"chinasss":"asian","england":"euro"}
#将python的dict对象 序列化为字符串,并写入
with open('test.db','w') as fp:
dict2_str1 = json.dumps(dict2_obj1)
dict2_str2 = json.dumps(dict2_obj1)
fp.write(dict2_str1+"\n")
fp.write(dict2_str2+"\n")2.2 文件上的load操作
在这里,load相当于open()的read方法
with open('test.db','r') as f:
#with open('test.json','r') as f:
#with open('test.txt','r') as f:
for line in f.readlines():
dd = json.loads(line)
print(dd,type(dd)){'china': 'asian', 'england': 'euro'} <class 'dict'>
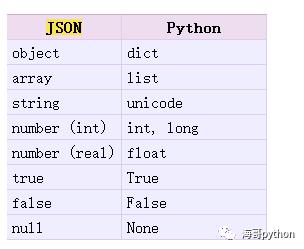
{'china': 'asian', 'england': 'euro'} <class 'dict'>python的一些基本类型通过encode之后,tuple类型就转成了list类型了,再将其转回为python对象时,list类型也并没有转回成tuple类型,而且编码格式也发生了变化,变成了Unicode编码。具体转化时,类型变化规则如下所示:
Python-->Json
Json-->Python
Json处理中文问题:
关于python字符串的处理问题,如果深入的研究下去,我觉得可以写2篇文章了(实际上自己还没整很明白),在这里主要还是总结下使用python2.7.11处理json数据的问题。前期做接口测试,处理最多的事情就是,把数据组装成各种协议的报文,然后发送出去。然后对返回的报文进行解析,后面就遇到将数据封装在json内嵌入在http的body内发送到web服务器,然后服务器处理完后,返回json数据结果的问题。在这里面就需要考虑json里有中文数据,怎么进行组装和怎么进行解析,以下是基础学习的一点总结:
第一:Python 2.7.11的默认编码格式是ascii编码,而python3的已经是unicode,在学习编解码的时,有出现乱码的问题,也有出现list或者dictionary或者tuple类型内的中文显示为unicode的问题。出现乱码的时候,应该先看下当前字符编码格式是什么,再看下当前文件编码格式是什么,或者没有设置文件格式时,查看下IDE的默认编码格式是什么。最推崇的方式当然是每次编码,都对文件编码格式进行指定,如在文件前 设置# coding= utf-8。
第二:字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码
第三:将json数据转换成python数据后,一般会得到一个dict类型的变量,此时内部的数据都是unicode编码,所以中文的显示看着很痛苦,但是对于dict得到每个key的value后,中文就能正常显示了,如下所示:

# coding= utf-8import json import sysif __name__ == '__main__': # 将python对象test转换json对象 test = {"username":"测试","age":16} print type(test) python_to_json = json.dumps(test,ensure_ascii=False) print python_to_json print type(python_to_json) # 将json对象转换成python对象 json_to_python = json.loads(python_to_json) print type(json_to_python) print json_to_python['username']
运行结果:
注意:
从文件中读取时是一行行取数据的
字典全部使用双引号,这一点要牢牢记住!!!
以上是关于json库的主要内容,如果未能解决你的问题,请参考以下文章