2.2.6 WebDriver API及对象识别技术
Posted 木头编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2.2.6 WebDriver API及对象识别技术相关的知识,希望对你有一定的参考价值。
概述
在UI自动化测试中,必然会遇到环境不稳定,网络慢的情况,这时如果不做任何处理的话,代码会由于没有找到元素而报错。这时我们就要用到wait,而在Selenium中,我们可以用到一共三种等待,每一种等待都有自己的优点或缺点,如何选择最优的等待方式。
一.强制等待
使用方法:sleep(X),等待X秒后,进行下一步操作。
第一种也是使用最简单的一种办法就是强制等待sleep(X),强制让浏览器等待X秒,不管当前操作是否完成,是否可以进行下一步操作,都必须等X秒的时间。
缺点:不能准确把握需要等待的时间(有时操作还未完成,等待就结束了,导致报错;有时操作已经完成了,但等待时间还没有到,浪费时间),如果在用例中大量使用,会浪费不必要的等待时间,影响测试用例的执行效率。
优点:使用简单,可以在调试时使用。
示例:打开登录页面,等待3秒,进行登录操作,如果3秒内登录页面没有加载完,下一步操作就会报错。
二.隐式等待
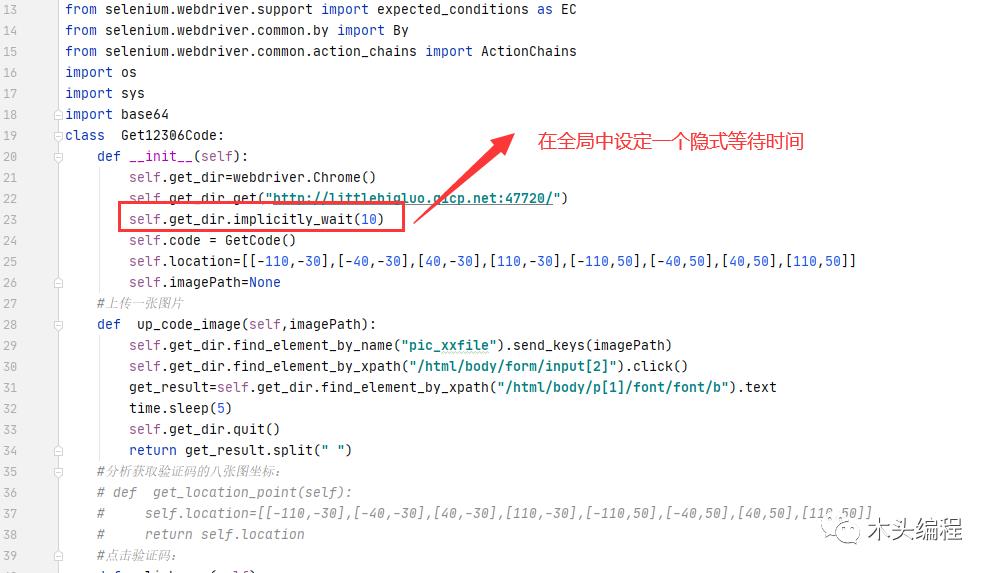
使用方法:implicitly_wait(X),在X时间内,页面加载完成,进行下一步操作。
第二种方法是隐形等待,其设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间结束,然后执行下一步操作。
缺点:使用隐式等待,程序会一直等待整个页面加载完成,才会执行下一步操作;但有时候页面想要的元素早已经加载完成了,但是因为网页上个别元素还没有加载完成,仍要等到页面全部完成才能执行下一步,使用也不是很灵活。
优点:隐性等待对整个driver的周期都起作用,所以只要设置一次即可。
示例:打开登录页面,等待页面加载完成后,如果30秒内,页面加载完成,就进行登录操作,不再继续等待,如果30秒内登录页面没有加载完,下一步操作就会报错。
三.显式等待
WebDriverWait(显示等待)
WebDriverWait是selenium提供得到显示等待模块引入路径
from selenium.webdriver.support.wait import WebDriverWait
WebDriverWait参数
driver: 传入WebDriver实例,即我们上例中的driver
timeout: 超时时间,等待的最长时间
poll_frequency: 调用until或until_not中的方法的间隔时间,默认是0.5秒
ignored_exceptions: 忽略的异常,如果在调用until或until_not的过程中抛出这个元组中的异常, 则不中断代码,继续等待,如果抛出的是这个元组外的异常,则中断代码,抛出异常。默认只有NoSuchElementException。
这个模块中,一共只有两种方法until与until_not
method: 在等待期间,每隔一段时间调用这个传入的方法,直到返回值不是False
message: 如果超时,抛出TimeoutException,将message传入异常
until
当某元素出现或什么条件成立则继续执行
until_not
当某元素消失或什么条件不成立则继续执行两个方法的method,必须是含有__call__的可执行方法。
所以我们引用selenium提供的一个模块:
from selenium.webdriver.support import expected_conditions as Ec
示例:
# -*- coding: utf-8 -*-##-------------------------------------------------------------------------------# ProjectName: PythonTest1014# FileName: WebDriverWaitTest# Author: MuTou# Date: 2020/06/12# Description:显示等待的简单实例#-------------------------------------------------------------------------------from selenium import webdriverfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.common.by import Byget_driver=webdriver.Chrome()get_driver.get("http://www.baidu.com")if "百度一下" in get_driver.title:print(True)else:print(False)# get_driver.find_element_by_id("kw").send_keys("顺丰")#如果是匿名函数的话,则实际就是调用匿名函数将WebDriverWait的第一个参数的驱动器对象传入到method当中try:#print(WebDriverWait(get_driver,5,1).until(lambda dir:dir.find_element_by_id("ghhu")))#expected_conditions表示的是预置条件,可以实现当前元素的相关信息判定::判定当前元素是否存在#当前元素是否可见、当前页面的标题、当前页面的alert框是否存在、iframe是否存在等一系列方法#判断页面的标题是否为百度一下print(EC.title_is("百度一下")(get_driver))print(EC.title_contains("百度一下")(get_driver))get_driver.execute_script("javascript:alert('hello');")(EC.alert_is_present()(get_driver)).accept()#传入的locator参数必须是一个元组类型,其内部封装就是封装驱动器对象调用find_element方法进行元素定位print(EC.presence_of_element_located((By.ID,"kw"))(get_driver))get_element=WebDriverWait(get_driver,5,1).until(EC.element_to_be_clickable((By.CLASS_NAME,"qrcode-img")))print("该对象是否可见呢?",EC.visibility_of_element_located((By.ID,"kw"))(get_driver))except:print("元素在页面上无法定位")
使用显示等待完成以下需求:
1.判断某个元素是否被加到了dom树里,并不代表该元素一定可见,如果定位到就返回WebElement
2.判断某个元素是否被添加到了dom里并且可见,可见代表元素可显示且宽和高都大于0
3.判断元素是否可见,如果可见就返回这个元素
4.判断是否至少有1个元素存在于dom树中,如果定位到就返回列表
5.判断是否至少有一个元素在页面中可见,如果定位到就返回列表
6.判断指定的元素中是否包含了预期的字符串,返回布尔值
7.判断指定元素的属性值中是否包含了预期的字符串,返回布尔值
8.判断该frame是否可以switch进去,如果可以的话,返回True并且switch进去,否则返回False
9.判断某个元素在是否存在于dom或不可见,如果可见返回False,不可见返回这个元素
10.判断某个元素中是否可见并且是enable的,代表可点击
11.等待某个元素从dom树中移除
1.WebDriverWait(driver,10).until(EC.visibility_of_element_located((By.ID,'su')))2.WebDriverWait(driver,10).until(EC.visibility_of(driver.find_element(by=By.ID,value='kw')))3.WebDriverWait(driver,10).until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'.mnav')))4.WebDriverWait(driver,10).until(EC.visibility_of_any_elements_located((By.CSS_SELECTOR,'.mnav')))5.WebDriverWait(driver,10).until(EC.text_to_be_present_in_element((By.XPATH,"//*[@]/a[8]"),u'设置'))6.WebDriverWait(driver,10).until(EC.text_to_be_present_in_element_value((By.CSS_SELECTOR,'#su'),u'百度一下'))7.WebDriverWait(driver,10).until(EC.frame_to_be_available_and_switch_to_it(locator))8.#注意这里并没有一个frame可以切换进去WebDriverWait(driver,10).until(EC.invisibility_of_element_located((By.CSS_SELECTOR,'#swfEveryCookieWrap')))9.#注意#swfEveryCookieWrap在此页面中是一个隐藏的元素WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//*[@]/a[8]"))).click()10.driver.find_element_by_xpath("//*[@]/div[6]/a[1]").click()#WebDriverWait(driver,10).until(EC.element_to_be_clickable((By.XPATH,"//*[@]/div[6]/a[1]"))).click()#WebDriverWait(driver,10).until(EC.staleness_of(driver.find_element(By.ID,'su')))11.WebDriverWait(driver,10).until(EC.element_to_be_selected(driver.find_element(By.XPATH,"//*[@]/option[1]")))
上传文件
普通上传:将本地文件的路径作为一个值放在input标签中,通过form表单提交的时候将这个值提交给服务器上传的输入框标签必须为input
#传入一个文件的绝对路径到上传输入框
dr.find_element_by_name('file').send_keys('D:\\uploadfile.txt')
插件上传:基于flash、JavaScript、Ajax等技术实现的上传功能或插件可以使用专门用于Windows操作自动化测试工具autoID编写代码,然后转成exe格式后在selenium上传本地文件上传本地文件需要导入os类:import os
autoIT:是一款实现windows GUI窗口的第三方扩展库,autoIT也是一款强大的脚本开发语言;在传统的自动化工具中(QTP(HP旗下----mercury公司)---->UFT),其脚本编程语言使用的VB、VBS、C等
autoIT上传文件编码:
ControlFocus("文件上传","","Edit1")#识别windows窗口("title","text","controlid")WinWait("[CLASS:#32770]","",10)#窗口等待十秒ControlSetText("文件上传", "", "Edit1", "C:\Users\happy\Desktop\FileUpload.html")#想输入框中输入需要上传的地址Sleep(2000)ControlClick("文件上传", "","Button1");#点击[打开]按钮
参考信息:Auto IT官方网站:https://www.autoitscript.com/site/
python对应上传文件编码:
from selenium import webdriverimport osdr = webdriver.Firefox()dr.get(需要上传文件的页面地址)dr.find_element_by_name('file').click() #点击上传文件按钮os.system(已编码并转换成.exe后缀的文件) #上传本地文件
文件下载
Firefox文件下载
from selenium import webdriver
import os
#对火狐浏览器下载进行设置
fp = webdriver.FirefoxProfile()
#设置成0代表下载到浏览器默认下载路径,设置成2则可以保存到指定的目录
fp.set_preference("browser.download.folderList",2)
#True为显示开始,Flase为不显示开始
fp.set_preference("browser.download.manager.showhenStarting",True)
#browser.download.dir指定文件下载路径,os.getcwd()返回当前目录;综合即将文件下载到脚本所在目录
fp.set_preference("browser.download.dir",os.getcwd())
#下载文件类型
fp.set_preference("browser.helperApps.neverAsk.saveToDisk","applaction/octet-stream")
dr = webdriver.Firefox(firefox_profile = fp) #将设置参数传给浏览器
dr.get("https://pypi.org/project/selenium/#files")
dr.find_element_by_xpath("//*[@]/div[3]/table/tbody/tr[3]/td[1]/span/a[1]").click()
参考信息:文件拓展名与Content-type对照表:https://tool.oschina.net/commons
在浏览器输入about:config查看火狐浏览器相关参数
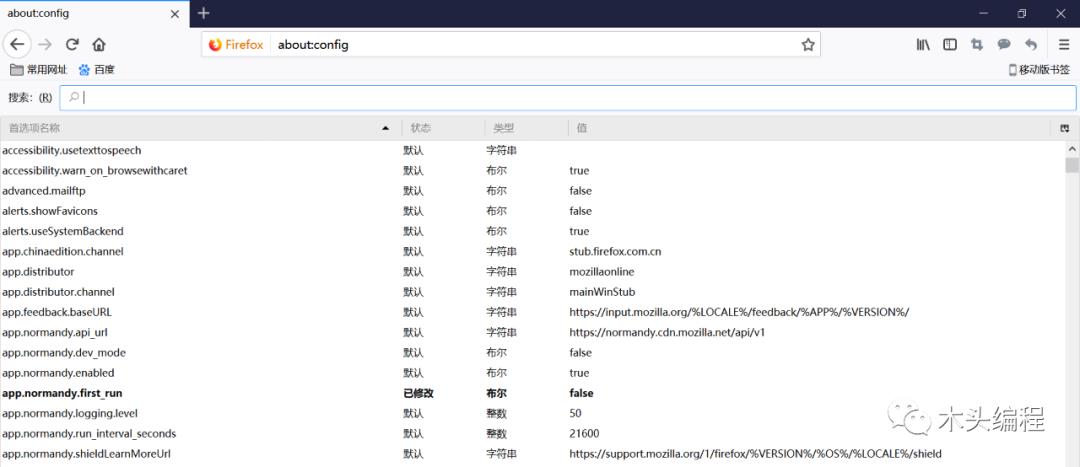
为了让Firefox浏览器能实现文件下载,需要通过FirefoxProfile()对其做一些设置。
browser.download.foladerList :设置成0代表下载到浏览器默认下载路径,设置成2则可以保存到指定的目录。
browser.download.manager.showWhenStarting :是否显示开始:True为显示开始,Flase为不显示开始。
browser.download.dir :用于指定所下载文件的目录。
os.getcwd()函数不需要传递参数。用于返回当前的目录。
browser.helperApps.neverAsk.saveToDisk :对所给文件类型不再弹出框进行询问。
Chrome文件下载
"download.prompt_for_download": False,
'download.default_directory': 'C:/Users/Administrator/Desktop/1/',#下载目录
"plugins.always_open_pdf_externally": True,
'profile.default_content_settings.popups': 0,#设置为0,禁止弹出窗口
# 'profile.default_content_setting_values.images': 2,#禁止图片加载
from selenium import webdriverimport timeoptions = webdriver.ChromeOptions()prefs = {'profile.default_content_settings.popups': 0, 'download.default_directory': 'd:\\'}options.add_experimental_option('prefs', prefs)#定义驱动位置driver = webdriver.Chrome(executable_path='F:\chromedriver\chromedriver.exe', chrome_options=options)driver.get("http://pypi.Python.org/pypi/selenium")driver.find_element_by_xpath("//a[@id='files-tab']").click()time.sleep(5)#选择下载文件driver.find_element_by_xpath("//a[contains(@href,'.tar.gz')]").click()time.sleep(30)driver.quit()
以上是关于2.2.6 WebDriver API及对象识别技术的主要内容,如果未能解决你的问题,请参考以下文章