nginx使用gzip压缩文件
Posted 我就是程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了nginx使用gzip压缩文件相关的知识,希望对你有一定的参考价值。
团队文化:进取,分享,快乐,责任!
团队愿景:做最好的产品,打造有影响力的团队!
一个热爱技术,气氛活跃,开放分享的团队,长期招聘架构师,高级java开发工程师,高级前端开发工程师数名,期待你的加入,简历投递:panjian@jd.com
为了提高页面的响应速度,可以从设置 nginx 的 gzip 和缓存这2方面入手,而为ttf,js,css等文件开启 gzip 和缓存能大大减少带宽的消耗.
HTTP 的内容编码机制
Accept-Encoding 和 Content-Encoding 是 HTTP 中用来对[采用何种编码格式传输正文]进行协定的一对头部字段. 它的工作原理是这样:
浏览器发送请求时,通过 Accept-Encoding 带上自己支持的内容编码格式列表;
服务端从中挑选一种用来对正文进行编码,并通过 Content-Encoding 响应头指明选定的格式;
浏览器拿到响应正文后,依据 Content-Encoding 进行解压.
当然,服务端也可以返回未压缩的正文,但这种情况不允许返回 Content-Encoding;
这个过程就是 HTTP 的内容编码机制.
Accept-Encoding,作为请求首部字段,可以一次性指定多种内容编码,比如:
1.gzip
由文件压缩程序gzip(GNU zip)生成的编码格式(RFC1952),采用Lempel-Ziv算法(LZ77)及32位冗余校验(Cyclic Redundancy Check,统称CRC);
文章后面会统一介绍gzip的算法;
2.compress
由UNIX文件压缩程序compress生成的编码格式,采用Lempel-Ziv-Welch算法(LZW);
3.deflate
组合使用zlib格式(RFC1950)及由default压缩算法(RFC1951)生成的编码格式;
4.identity
不执行压缩或者不会变化的默认编码格式.
Content-Encoding作为实体首部字段,采用的内容编码格式和Accept-Encoding是相对应的.
在nginx上添加以下逻辑,用来压缩字体文件,以达到节省网络带宽,提高网站速度的作用.
#字体有很多格式,为匹配字体格式的文件进行压缩设置
#就是拦截这种请求,然后压缩:www.test.com/dist/aabbccddeeffgg.ttf
location ~* ^/dist/.+\.(eot|ttf|otf|woff|svg)$ {
#不缓存
expires 0;
#增加type对应类型
types {
application/vnd.ms-fontobject eot;
font/ttf ttf;
font/opentype otf;
font/x-woff woff;
image/svg+xml svg;
}
# 开启gzip
gzip on;
# 启用gzip压缩的最小文件,小于设置值的文件将不会压缩
gzip_min_length 1k;
# 设置压缩所需要的缓冲区大小
gzip_buffers 4 16k;
#压缩版本(默认1.1,前端如果是squid2.5请使用1.0)
gzip_http_version 1.0;
#压缩等级 1-9 等级越高,压缩效果越好,节约宽带,但CPU消耗大
gzip_comp_level 3;
# 进行压缩的文件类型,默认就已经包含text/html。javascript有多种形式。其中的值可以在 mime.types 文件中找到。
gzip_types font/ttf font/opentype font/x-woff image/svg+xml;
# 是否在http header中添加Vary: Accept-Encoding,建议开启
gzip_vary on;
# 禁用IE 6 gzip , 因为IE6的某些版本对gzip的压缩支持很不好,会造成页面的假死
gzip_disable "MSIE [1-6].";
}
测试结果:
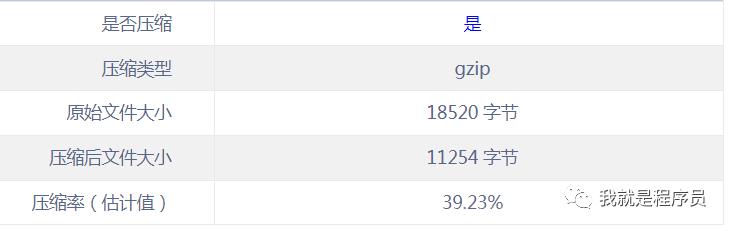
用curl测试gzip是否开启成功
curl -I -H "Accept-Encoding: gzip, deflate" "http://www.test.com/dist/aabbccddeeffgg.ttf"
gzip未开启:
TP/1.1 200 OK
Server: JDWS/1.0.0
Date: Tue, 21 Aug 2018 01:49:24 GMT
Content-Length: 18520
Connection: close
Last-Modified: Mon, 20 Aug 2018 09:40:38 GMT
Accept-Ranges: bytes
Expires: Tue, 21 Aug 2018 01:49:24 GMT
Cache-Control: max-age=0
gzip开启:
TP/1.1 200 OK
Server: JDWS/1.0.0
Date: Tue, 21 Aug 2018 01:48:10 GMT
Content-Type: font/ttf
Last-Modified: Fri, 10 Aug 2018 06:13:07 GMT
Connection: close
Vary: Accept-Encoding
Expires: Tue, 21 Aug 2018 01:48:10 GMT
Cache-Control: max-age=0
Content-Encoding: gzip
gzip压缩算法:
gzip是一种数据压缩格式,或者说是一种文件格式,用.gz结尾;
gzip可以极大的加速网站.有时压缩比率高达80%,一般最少都有40%左右;
对于要压缩的文件,使用gzip,主要分为两步:
1.使用LZ77压缩算法进行压缩,得到初始结果;
2.使用Haffman编码对初始结果进行再压缩,得到最终结果.
详细说下这两种算法:
LZ77算法
这个算法是由Jacob Ziv 和 Abraham Lempel 于 1977 年提出,所以命名为 LZ77.
整体思路:
我们认为是一段内容总会有重复的内容,后面重复的内容可以用两者之间的距离加内容长度联合替换,
而替换后的内容的所占空间一般都会比原内容小,重复越多,压缩完空间就越小.
详细实现过程:
先介绍三个概念:
1.待编码区(字符从这里进来);
2.已编码区(字符从这里出去,也叫缓冲区);
3.滑动窗口(左边是已编码区,右边是待编码区,字符会从右向左依次被读取).
| 滑动窗口 |
| 已编码区 | 待编码区 |
| | a a b| c b b a b c
再看看大概步骤:
1.字符a从待编码区进来,此时a在待编码区的最左边;
2.在待编码区查找从这个a字符在已编码区的最大匹配长度;
3.如果能找到,就输出(偏移量m,最大匹配长度n),滑动窗口向右偏移n个位置;
偏移量m就是待编码区的字符a到已编码区匹配到的字符a的移动距离;
最大匹配长度n就是待编码区有多少连续字符可以在已编码区找到匹配的,这些连续字符的长度;
4.如果找不到,就输出(0,0,a),滑动窗口向右偏移1位;
5.直到待编码区为空,就停止编码,否则继续从2开始循环.
以上面的字符串为例,举个简单易懂的例子:
第一步:a到待编码区的最左边了,在已编码区没有找到匹配的字符,输出(0,0,a), 如下图所示
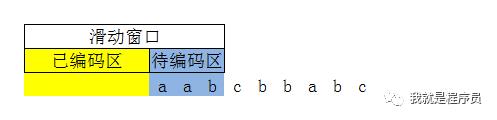
滑动窗口准备右移一位,到第二步.
第二步:开始编码,待编码区的第一个字符是a,在已编码区查找匹配字符,找到了; 继续在待编码区读到ab两个字符,在已编码区查找匹配字符,没找到; 所以本次编码待编码区的第一个字符a,输出(1,1); 第一个1代表待编码区的a到已编码区的偏移量,偏移一位,记为1; 第二个1代表本次可编码的长度,因为只有一个a,所以记为1. 如下图所示

滑动窗口准备右移一位,到第三步.
第三步:待编码区第一个字符是b,在已编码区查找匹配字符,没找到; 同第一步,输出(0,0,b). 如下图所示

滑动窗口准备右移一位,到第四步.
第四步:待编码区第一个字符是c,在已编码区查找匹配字符,没找到; 同第一步,输出(0,0,c). 如下图所示

滑动窗口准备右移一位,到第五步.
第五步:待编码区第一个字符是b,在已编码区查找匹配字符,找到了; 待编码区前两个字符是bb,在已编码区查找匹配字符,没找到; 所以本次编码待编码区的第一个字符b,输出(2,1). 如下图所示

滑动窗口准备右移一位,到第六步.
第六步:待编码区第一个字符是b,在已编码区查找匹配字符,找到了; 待编码区前两个字符是ba,在已编码区查找匹配字符,没找到; 所以本次编码待编码区的第一个字符b,输出(3,1). 如下图所示

滑动窗口准备右移一位,到第七步.
第七步:待编码区第一个字符是a,在已编码区查找匹配字符,找到了; 待编码区前两个字符是ab,在已编码区查找匹配字符,找到了; 待编码区前三个字符是abc,在已编码区查找匹配字符,找到了; 这个例子待编码区只有三个字符的长度,实际会很长,就一直找,直到找不到匹配字符为止; 所以本次编码待编码区的前三个字符abc,输出(5,3). 如下图所示

滑动窗口准备右移三位,到第八步.
第八步:待编码区没有字符了,结束
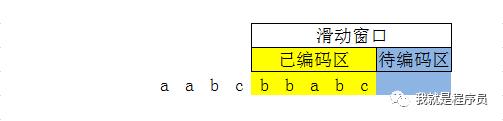
最终结果:(0,0,a)(1,1)(0,0,b)(0,0,c)(2,1)(3,1)(5,3) 通过这个结果反向解码,也能得到原文: aabcbbabc 而且解码比编码还要快很多,主要是因为少了匹配这一步.
Haffman编码
整体思路:
我们知道,普通的编码都是定长的,比如ASCII编码,每个字符编码后的长度都是固定长度,
在解码的时候也就相对简单,只需按照定长将码解开,逐个翻译成对应的字符即可;
而haffman采用的是可变长编码,目的是为了让出现次数多的字符采用更少的长度来存储,
这样就可能会大大加强压缩力度;
haffman建立了树的概念,haffman树是一种二叉树,将所有符号都对应到树的叶子节点上,
每个叶子节点都是可以唯一表示的,都是用若干个0和1组成的;
由于所有的字符最终都会落在叶子节点上,即任何字符的编码都不会是其他字符编码的前缀,
所以在解析的时候,也不会发生混淆的问题,因此haffman编码后的码,也是一种唯一可译码.
详细实现过程:
1.先读所有文件,将所有内容中所有字符出现的次数统计出来做排序;
2.我们将出现少的两个字符作为子节点,可以确定一个父节点,值就是两个子节点的次数和;
3.将上一步的父节点当做一个子节点,再重复执行第二步,直到所有节点全部用完,构成一颗大树;
4.每个数从父节点开始,默认左边的子节点是0,右边的子节点是1,
那么所有的字符对应的子节点都会有唯一的标识了;
5.用这些唯一标识来代替原来的字符,就是编码后的结果;
6.解码的时候,也是先根据所有字符的次数构成那颗大树,然后根据大树找出对应的字符即可.
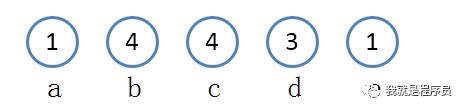
举个简单易懂的例子: 比如文件的内容是:abbbbccccddde 我们可以统计出: a出现1次; b出现4次; c出现4次; d出现3次; e出现1次;
第一步:找出所有字符出现的次数. 如下图所示
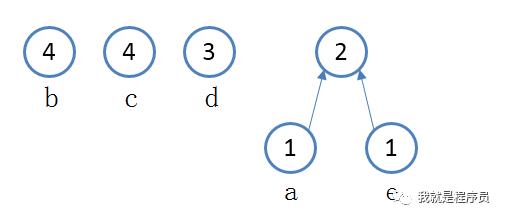
第二步:找出两个最小次数的字符,构成一颗树; a字符和e字符都只出现1次,次数最少,构成一颗树; 产生新的节点,个数为a和e次数的和,即为1+1=2. 如下图所示
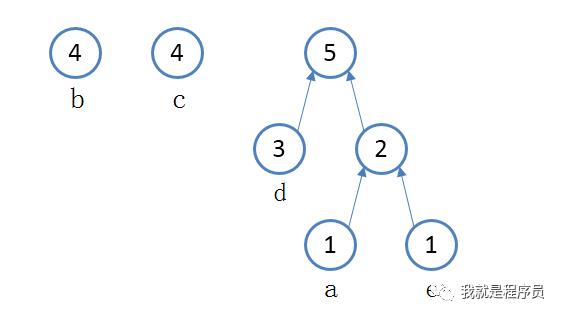
第三步:再找出剩下的节点中出现次数最小的两个节点; 找出d字符和上一步的新节点,分别一个是3次,一个是2次; 这两个节点继续壮大这颗树,再产生新的节点,次数为3+2=5次. 如下图所示
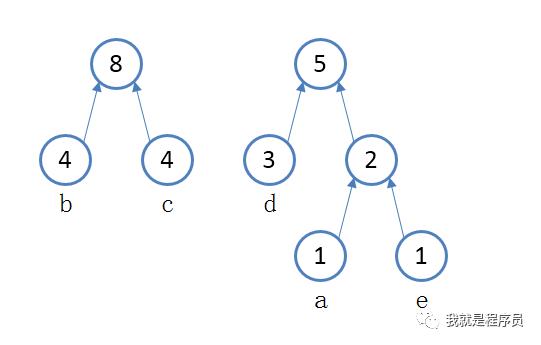
第四步:再从剩下的节点中找出最小的两个,是b和c 构成新的树,父节点是4+4=8 如下图所示
第五步:将最后两个节点合并成一颗大树; 最上面是树的根节点; 最下面是每个字符对应的子节点; 我们默认为:从根节点自上向下看开始计数,往左拐记为0,往右拐记为1; 那么从根节点到下面每个子节点的路径所对应的计数的组合,就是这个字符所要代替的01组合. 如下图所示
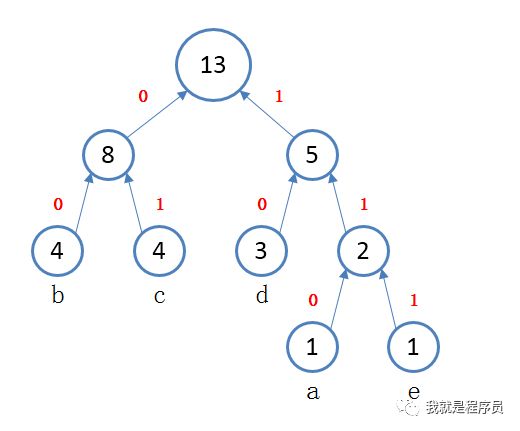
最终不难看出: a对应110 b对应00 c对应01 d对应10 e对应111 那么原内容:abbbbccccddde 就可以替换为:1100000000001010101101010111 这个就是压缩后的内容, 那么在解压的时候,再将这些10的组合依次替换成对应的字符即可.
以上是关于nginx使用gzip压缩文件的主要内容,如果未能解决你的问题,请参考以下文章