REST 2.0 来了,它的新名字叫GRAPHQL
Posted 大前端工程师
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了REST 2.0 来了,它的新名字叫GRAPHQL相关的知识,希望对你有一定的参考价值。
GraphQL是为API调用定制的的查询语言。 虽然它与REST存在根本上的不同,但GraphQL真的可以作为REST的替代品,它拥有良好的性能、极好的开发者体验和非常强大的工具群。
通过本文,我们将介绍如何使用REST和GraphQL来处理一些常见的问题。本文一共展示三个项目。 你会看到用于提供有关流行电影和演员的信息REST和GraphQL API的代码,以及使用html和jQuery构建的简单前端应用程序。
我们将使用这些API来探讨这些技术的不同点,以便我们识别自己在这方面的优势和劣势。 不过,在开始之前,我们先来看看这些技术的发展方式。
Web的早期形态
网络的早期形态很简单。网络应用程序开始是在互联网上以提供的静态HTML文档的形式存在的。高级网站包含存储在数据库(例如SQL)中的动态内容,并使用javascript来添加交互性。绝大多数网页内容都是通过桌面电脑上的网络浏览器进行查看的——这符合那个时代的需求。
当史蒂夫·乔布斯(Steve Jobs)推出iPhone时,已经快到2007年。 除了智能手机对世界、文化和通讯的深远影响之外,它也使开发人员的生活更加复杂。 智能手机打破了开发的现状。 在短短的几年中,我们突然有台式机,iPhone,android和平板电脑。
作为应对措施,开发人员开始使用RESTful API来为不同形式和体量的应用程序提供数据。 新的开发模式看起来像这样:
GraphQL——API的革命
GraphQL是由Facebook设计的开源API的查询语言。您可以将GraphQL视为构建API的替代方法。而REST则是用于设计和实现API的概念模型,GraphQL是一种标准化语言,类型系统和规范,可在客户端和服务器之间创建强大的通信协议。使用我们拥有了一种所有设备之间通信的标准语言,大大简化了创建大型跨平台应用程序的过程。
当拥有了GraphQL,我们的图可以这样画了:
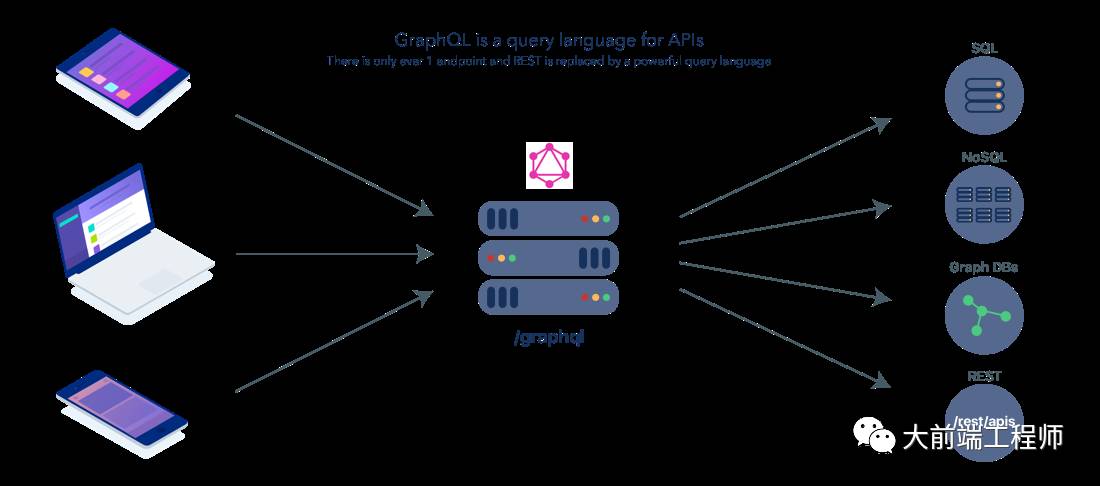
GraphQL vs. REST
在此教程的剩余部分,我建议大家跟随代码进行理解,代码可以在github的这个上找到。
代码包含以下三个部分:
一个RESTful的API
一个GraphQL的API
一个基于JQuery和HTML的客户端页面
我们特意尽可能地将项目做的简单,旨在尽可能简单地比较这些技术。如果您想继续,请打开三个终端窗口,并打开项目库中的RESTful,GraphQL和Client目录。 从这些目录中,通过npm run dev运行开发服务器。 一旦你准备好服务器,请继续阅读。
使用REST api进行查询
我们的RESTful API包含几个EndPoint:
| EndPoint | 描述 |
| /movies | 返回一个包含指向电影的链接的对象数组(例如:[{href: ‘http://localhost/movie/1’}]) |
| /movie/:id | 返回一个电影,满足id = :id |
| /movie/:id/actors | 返回一个对象数组,包含指向电影中演员的链接,电影满足id = :id |
| /actors | 返回一个对象数组,包含所有指向演员的链接 |
| /actor/:id | 返回一个演员,满足id = :id |
| /actor/:id/movies | 返回一个对象数组,包含指向演员参演电影的链接,演员满足id = :id |
假设我们是客户端开发人员,需要使用我们的电影API来构建一个包含HTML和jQuery的简单网页。要构建此页面,我们需要有关我们的电影以及其中出现的演员的信息。我们的API具有我们可能需要的所有功能,所以让我们继续获取数据。
打开一个新的终端,运行:
curl localhost:3000/movies
你会拿到这样的一个反馈:
[
{
"href": "http://localhost:3000/movie/1"
},
{
"href": "http://localhost:3000/movie/2"
},
{
"href": "http://localhost:3000/movie/3"
},
{
"href": "http://localhost:3000/movie/4"
},
{
"href": "http://localhost:3000/movie/5"
}
]
以REST风格,API返回一系列指向实际影片对象的链接。然后我们可以通过运行 curl http//localhost:3000/movie/1和第二个 curl http//localhost:3000/movie/2等等来抓取第一部电影。
如果你看看app.js,你可以看到以下函数来获取我们需要填充我们页面的所有数据:
const API_URL = 'http://localhost:3000/movies';
function fetchDataV1() {
// 1 call to get the movie links
$.get(API_URL, movieLinks => {
movieLinks.forEach(movieLink => {
// For each movie link, grab the movie object
$.get(movieLink.href, movie => {
$('#movies').append(buildMovieElement(movie))
// One call (for each movie) to get the links to actors in this movie
$.get(movie.actors, actorLinks => {
actorLinks.forEach(actorLink => {
// For each actor for each movie, grab the actor object
$.get(actorLink.href, actor => {
const selector = '#' + getMovieId(movie) + ' .actors';
const actorElement = buildActorElement(actor);
$(selector).append(actorElement);
})
})
})
})
})
})
}
你可能会注意到,这不太理想。 上面说过,我们已经对我们的API做了1 + M + M + sum(Am)往返调用,其中M是电影的数量,并且sum(Am)是所有M个电影中演员列表长度的总和。 对于具有小数据要求的应用程序,这应该是可以接受的,但它绝不会在一个大型的产品系统中运行。
结论是:我们简单的RESTful方法是不够的。为了改进我们的API,我们可能会问后台团队的人员为我们建立一个特殊的名为/moviesAndActors的EndPoint来为这个页面提供支持。一旦该端点准备就绪,我们可以用单个请求替换我们的1 + M + M + sum(Am)网络呼叫。
curl http://localhost:3000/moviesAndActors
现在返回一个应该看起来像这样的内容:
[
{
"id": 1,
"title": "The Shawshank Redemption",
"release_year": 1993,
"tags": [
"Crime",
"Drama"
],
"rating": 9.3,
"actors": [
{
"id": 1,
"name": "Tim Robbins",
"dob": "10/16/1958",
"num_credits": 73,
"image": "https://images-na.ssl-images-amazon.com/images/M/MV5BMTI1OTYxNzAxOF5BMl5BanBnXkFtZTYwNTE5ODI4._V1_.jpg",
"href": "http://localhost:3000/actor/1",
"movies": "http://localhost:3000/actor/1/movies"
},
{
"id": 2,
"name": "Morgan Freeman",
"dob": "06/01/1937",
"num_credits": 120,
"image": "https://images-na.ssl-images-amazon.com/images/M/MV5BMTc0MDMyMzI2OF5BMl5BanBnXkFtZTcwMzM2OTk1MQ@@._V1_UX214_CR0,0,214,317_AL_.jpg",
"href": "http://localhost:3000/actor/2",
"movies": "http://localhost:3000/actor/2/movies"
}
],
"image": "https://images-na.ssl-images-amazon.com/images/M/MV5BODU4MjU4NjIwNl5BMl5BanBnXkFtZTgwMDU2MjEyMDE@._V1_UX182_CR0,0,182,268_AL_.jpg",
"href": "http://localhost:3000/movie/1"
},
...
]
很好!在一个请求中,我们可以获取我们填充页面所需的所有数据。回顾我们的客户端目录中的app.js,我们可以看到这里的改进:
const MOVIES_AND_ACTORS_URL = 'http://localhost:3000/moviesAndActors';
function fetchDataV2() {
$.get(MOVIES_AND_ACTORS_URL, movies => renderRoot(movies));
}
function renderRoot(movies) {
movies.forEach(movie => {
$('#movies').append(buildMovieElement(movie));
movie.actors && movie.actors.forEach(actor => {
const selector = '#' + getMovieId(movie) + ' .actors';
const actorElement = buildActorElement(actor);
$(selector).append(actorElement);
})
});
}
我们的新应用将比上一次迭代效率更高,但仍然不完美。如果您打开http://localhost:4000 并查看我们的简单网页,您应该看到如下:
一个精明的后端开发人员可能会嘲笑这一点,并快速实现一个名为fields的特殊查询参数,该参数将使用一个字段名称数组来动态地确定在特定请求中应该返回哪些字段。
例如,我们可以使用 curl http://localhost:3000/moviesAndActors?fields=title,image来代替 curl http://localhost:3000/moviesAndActors。我们甚至可以使用一个新的参数字段actor_fields来表示在actor模型中哪些字段需要被包括,例如: curl http://localhost:3000/moviesAndActors?fields=title,image&actor_fields=name,image。
现在,这将是我们简单应用程序接近最佳的实现方式,但它引入了一个不好的习惯,我们为客户端应用程序中的特定页面创建自定义端点。当您开始构展示与您的网页不同的信息的ios应用程序或者展示与iOS应用程序不同的信息的Android应用程序时,问题会变得更加明显。
如果我们可以构建一个通用API,它可以显式地表示数据模型中的实体以及这些实体之间的关系,但不会受到1 + M + M + sum(Am)性能问题的影响,那么这不是很好吗? 好消息! 我们现在可以了!
使用GraphQL查询
使用GraphQL,我们可以直接跳过查询优化,直接通过简单直观的查询获取我们需要的所有信息,而无需更多信息:
query MoviesAndActors {
movies {
title
image
actors {
image
name
}
}
}
如果你要对GraphQL有所了解,真的要自己尝试。请打开GraphiQL(基于浏览器的GraphQL IDE),http://localhost:5000,并运行上面的查询。
我们现在做深一步的探讨。
用GraphQL思考
与REST相比,GraphQL与API在方法上存在根本的不同。其不依赖于HTTP结构(如动词和URI),而是在我们的数据之上分层直观的查询语言加上强大的类型系统。类型系统在客户端和服务器之间提供强类型的协议,查询语言提供了一种可以用于客户端开发人员获取任何给定页面所需要的数据的机制。
GraphQL提倡将数据视为信息的虚拟图表。包含信息的实体称为类型,这些类型可以通过字段相互关联。查询则是从根节点开始,遍历所构建出的虚拟图,同时抓取他们需要的信息。
这个“虚拟图”更明确地表达为一个schema。 schema是构成您的API数据模型的类型,接口,枚举和联合的集合。 GraphQL甚至包括一个方便的模式语言,我们可以用它来定义我们的API。例如,这是我们的电影API的架构:
schema {
query: Query
}
type Query {
movies: [Movie]
actors: [Actor]
movie(id: Int!): Movie
actor(id: Int!): Actor
searchMovies(term: String): [Movie]
searchActors(term: String): [Actor]
}
type Movie {
id: Int
title: String
image: String
release_year: Int
tags: [String]
rating: Float
actors: [Actor]
}
type Actor {
id: Int
name: String
image: String
dob: String
num_credits: Int
movies: [Movie]
}
类型系统为许多厉害的东西打开了大门。包括更好的工具、更好的文档和更有效的应用程序。有很多多我们可以谈论地方。但现在我们跳过这些东西,只突出几个展示REST和GraphQL之间的差异的场景。
GraphQL vs. Rest:版本
当你去google如何对一个REST API进行版本化,你会得到很多的选项。我们不会钻到这一系列的牛角尖里面去,但是我们也需要知道,这不是一个简单的问题。版本控制非常困难的原因之一,就是通常很难知道正在使用什么信息以及哪些应用程序或设备。
在REST和GraphQL中都可以很轻松地添加信息。添加任何一个字段后,它将自然地传递到您的REST客户端,并在GraphQL中被安全地忽略,直到更改查询。但是,删除和编辑信息是一个不同的场景。
在REST中,在字段层面很难知道使用了什么信息。我们可能会知道正在使用的EndPoint:/movies,但是我们不知道客户端是否要使用标题,图像或两者都要。一个可能的解决方案是添加一个查询参数字段,指定要返回的字段,但这些参数总是可选的。因此,您将经常看到版本化发生在我们引入新的EndPoint: /v2/movies。这样是可以的,但是会增加API的体量,并为开发人员增加负担,还要保持最新和全面的文档。
GraphQL中的版本控制则是非常不同的。每个GraphQL查询都需要在给出的查询中准确指出哪些字段要被请求。这是强制性的,这意味着我们确切地知道要求哪些信息,并允许我们的服务提出频率和访问者的问题。GraphQL还允许我们使用不推荐使用的字段和消息来装饰模式的原语,原因是它们不被弃用。
GraphQL vs REST: 缓存
REST中的缓存是直接有效的。事实上,缓存是REST的六大指导方针之一,被打造成成RESTful风格的设计。如果EndPoint /movies/1的返回表示可以缓存,则任何将来对/movies/1的请求都可以被缓存中的项目替换。这非常简单。
GraphQL中的缓存略有不同。缓存GraphQL API通常需要为API中的每个对象引入一些唯一的标识符。当每个对象具有唯一的标识符时,客户端可以构建使用此标识符来可靠地高速缓存,更新和淘汰对象的归一化缓存。当客户端发出引用一个对象的下游查询时,可以使用该对象的缓存版本。如果有兴趣了解更多关于如何在GraphQL中缓存的工作,这里是一篇很好的,更深入地介绍了这个主题。
GraphQL vs REST: 开发者体验
开发人员经验是应用程序开发的一个非常重要的方面,这也是我们作为工程师投入大量时间来建立良好工具的原因。这里的比较有点主观,但我觉得还是很重要的。
REST一直被尝试和实践,并且拥有丰富的工具生态系统,以帮助开发人员测试和检查RESTful API,记录文档。据说REST API规模的开发者还是要付出巨大代价。因为端点的数量很快变得压倒性,不一致也会变得更加明显,版本化仍然很困难。
GraphQL在开发人员体验方面非常擅长。该类型系统为GraphiQL IDE等强大工具打开了大门,而且文档内置于schema本身。在GraphQL中,只存在有一个端点,而且也不是依靠文档来发现可用的数据,您可以使用一种类型的安全语言并享有自动补全工具,您可以使用它来快速加快API的速度。GraphQL有与React和Redux等现代前端框架和工具相结合的设计。如果您正在考虑使用React构建应用程序,我强烈建议您尝试或客户端。
总结
GraphQL为构建高效的数据驱动应用程序提供了一些更加有意义且非常强大的工具。REST不会很快消失,它有很多需求,特别是在构建客户端应用程时。
如果你有兴趣了解更多细节,请翻阅。在你就能够了解如何在AWS上部署产品级别的GraphQL API。基于这些东西你能很快上手去改进你当前的产品逻辑和实现。
我希望你喜欢这篇文章,如果你有任何想法或意见,可以直接留言。
以上是关于REST 2.0 来了,它的新名字叫GRAPHQL的主要内容,如果未能解决你的问题,请参考以下文章