GraphQL掠影
Posted misstakau
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GraphQL掠影相关的知识,希望对你有一定的参考价值。
在移动端使用量变多的场景下,低功耗的设备和较差的网络环境是Facebook开发GraphQL最初的原因。GraphQL通过最小化网络传输时所需要的数据量,改善了这种环境中的应用使用情况。
(1)RESTful API痛点
GraphQL是由脸书开源的,现在已经形成标准,他们用的非常欢,很快就完成了前后端的换代。为啥要用GraphQL? 介绍GraphQL 的特点前,先来说我们一直在用的RESTful API (以下简称rest)有什么痛点。因为你要开始用GraphQL,就得要现有的Rest下岗。
Rest现在已经是Web服务最主要的架构方式,他对URL的形式提出了一些规范,但实际运用中,还是很自由的,你可以/user/1 也可以/user.php?id=1 ,这两种形式都是很RESTful的。然后Rest就不管了,你可以用各种协议传输数据,当然我们最主要的还是用Http,你可以装载任何的数据,如果是API,现在装Json的比较多,以前装Xml的也不少,不过你也可以返回一个html页面,返回一张图片,这些都不破坏Rest。一般来说,我们把Rest映射到一系列资源,比如说用户、帖子、回复、图片等,那我们的API就是对这些资源进行增删改查。
这是一种异常强壮的设计,你再结合使用一些扩展性非常强的数据格式,例如Json,足可以应付各种现在和将来的需求变化。如果你开发了这么一套API,可能十年八年都不用推倒重来。
但这种资源的表达,带来几个问题:
1 数据定制的问题:我们的应用数据现在越来越丰富,已经不是10年前可以相比的了,也就是说数据的返回可能很丰富,非常大,而我这次可能只要其中一小部分,比如说我请求一个用户的数据/user/1,我只要他的名字和头像,而并不需要他几千个好友。传统的Rest,你可以加个Mask参数,例如/user/1?friend=false 这种方式无疑增大了前后端的代码复杂度,增加了开发的强度,而且也不够灵活,难道我要给每个字段都加个Mask?后端要依赖各种可能的Mask组合来生成查询也是个麻烦事儿,这种代码写出来也是难维护。
2 多次请求的问题:类似上面提到的灵活性问题,上面说我们要少要点数据,那我们这次想多要些数据。比如说我想要一个用户的所有好友,还没完,再加上每一个好友的所有好友。这在传统Rest里面,往往我们就使用多次的请求,拿到1度好友的列表,然后写个循环,依次拿到所有2度好友。这当然不够优化,于是可能你会再设计一个专门的API去一次性拿到所有2度好友。同样的问题,这增大了前后端的代码复杂度,不够灵活,万一下次我要3度好友呢?
3 异常处理的问题:这个很多朋友都会有自己的办法,有些朋友会返回特定的http response code: 4XX, 5XX,有些朋友可能会返回特定的Json消息。比如说/get/user/8527, 如果这个用户不存在,你可以返回404,你也可以返回自定义消息{msg:“user not found”}。这很多时候也不是问题,但我觉得如果使用更结构化的异常处理方式,应该会好些。
4 发出一个请求,我不知道会得到啥:结合上面几点,其实你会发现,如果你请求一个资源,例如/user/1,你并不知道结果里具体会有什么,你可能需要查阅文档,但文档可能已经过期。你可以自己实验,但你不知道是否覆盖了全部可能的情况。这是一个很痛苦的过程。
5 PUT和DELETE也是个坑:这需要前后端框架的支持,如果不支持怎么办?其实我也不知道,我这么多年一直尽量避免使用PUT和DELETE来设计API。
6 每个resource都有自己的一组URL,这会带来管理和维护的麻烦。
7 安全问题:Rest难以避免的从URL上接受各种参数(parameter),不严格的使用Get等都会造成安全的隐患。有些问题GraphQL上也有,而且我不是这方面的专家,就不细说了。
(2)新协议的优势 - 所求即所得
先来看看GraphQL的查询什么样,先来个直观的认识,下面就是一个GraphQL查询,去拿到id为2017的用户,但与/user/:id这种Rest查询的区别是,我们限定了返回结果的字段,我们只要name和age两个字段。
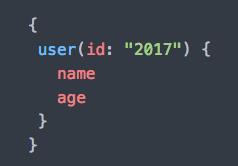
这个简单的例子可以看出我们的GraphQL可以方便的支持参数, 如果我们的客户端需要更多的数据,可以方便地扩展。
这个查询就体现出GraphQL的威力了,我们多要了个字段friends。friends可是实打实的对象集合。对于这种复杂类型,我们可以继续给它指定需要的字段,这里我们指定了 name和age。
你还可以在friends里再指定friends来拿到朋友的朋友。你可以各种嵌套来达成你的查询目的,数据也不在是单一的资源,而形成了一个图,这种图形化的查询对现代前端和数据工程师都非常有用。GraphQL不止可以给前端调用,它给后端以及数据和算法工程师的代码调用也是很好的。
当然,如此强大的查询也让很多人为它的性能担心?这得结合后端实现来解答,GraphQL是很轻功能薄的一层,也就是说它自己额外产生的延迟(Overhead)是很低的。其实绝大多数人担心的是,GraphQL会不会额外产生过多数据库的查询。我觉得这个担心是有道理的,如果你给每一个字段都上一个resolver函数,函数里直接执行数据库查询,那当然会产生非常多的查询。可目前已有的GraphQL后端实现(包括javascript, Go,Java和Scala)给你提供了非常灵活的自定义优化方式。比如说你可以结合使用Cache和Context对象来减少数据库查询次数。而且大家可以想象一下Facebook访问量和界面复杂程度,据说这东西是让他们更轻松了,为什么我们不行?问题都是可以优化和解决的。
那我们拿到的数据是什么样子的呢,这也是我最喜欢GraphQL的地方之一,调用方可以明确知道返回数据的结构,或者说里面都有什么,这是Rest API做不到的。我们来看上面那个GraphQL的返回。
这个返回结果完全是和请求同构的。那么在前端,你有什么样的view, 需要什么样的数据,你就构建什么样的请求,得到的结果你就可以直接用来生成和填充你的view。再复杂的view你也可以一次查询请求搞定,这对前端的反应速度和开发效率是个巨大的提升。
至于会不会增加后端工作量的问题,分几点来讨论:
1) 你一般不需要为GraphQL换语言,GraphQL各语言实现的进步非常快,基本都是易学易用,现在至少有十几种主流语言支持GraphQL,基本常用的语言都支持了,这个速度是非常惊人的,一般的技术需要好多年才能覆盖这么多语言。
2) 你不需要为GraphQL换框架,GraphQL和框架无关,各种主流web框架,不管你是Django, Rails还是Express,哪怕是Spring MVC,Play Framework,Finatra都不矛盾。当然,你并不真的需要框架。
3) 如果你的服务是一个单一的大型Rest, 你可以把GraphQL 直接连接到你已有的Rest项目上(好处是你可以重用你已经实现的业务逻辑代码,数据库和Cache访问代码),这都是很容易,加一两个endpoint(后面会讲这一两个是哪两个)就行了。所以你可以让GraphQL和你的Rest并行一段时间。
4) 如果你的服务已经很好的使用了微服务的构架,你也不需要重写你的服务,你可用GraphQL挡在所有后端服务前面来自由拼装你的微服务。
5) 关于优化,如果访问量大,的确需要优化GraphQL对数据库的访问,任何后端服务在大访问量面前都需要优化。不过我个人觉得GraphQL的优化相对容易做,毕竟是一个单一的访问,都共享一个单一的context对象,你可以从全局出发进行优化,你可以做的事情更多。而Rest会产生多次请求(多次请求本身就是一个不小的问题),这些请求很可能分发到不同的服务器,即便在同一个服务器你也很难控制它们到达的先后顺序。其实Rest的优化更难。
节选自
https://www.zhihu.com/people/wangbeinan/posts
https://graphql.org
https://www.howtographql.com
https://developer.github.com/v4/guides/
https://github.com/chentsulin/awesome-graphql
以上是关于GraphQL掠影的主要内容,如果未能解决你的问题,请参考以下文章