第1306期GraphQL 聚合层解放前后端
Posted 前端早读课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第1306期GraphQL 聚合层解放前后端相关的知识,希望对你有一定的参考价值。
前言
6月9号在杭州举行的第一届GraphQLParty,据说报名的人还挺多的超出了期望。今日早读文章由@Scott授权分享。
正文从这开始·
Scott:各位大牛,大神,大咖大家下午好,我是 Scott,也是这次杭州第一届 GraphQLParty 的发起人。
先回到会议的主题,为什么会开这么一个会议?原本这个会议报名的时候希望可以控制到 100 人之内,不要超过 120 人,结果报到 250 人还爆满了,后来没有办法,我们只能从工作经验来筛选,选择工作经验在三年以上的比较资深的工程师,和一部分 2 年经验工作经验的,还有 5 年的,10 年甚至更久的从业者。
那现场我调查一下哈,大家有了解过领域驱动的同学请举一下手好么(观众互动),不到十个人,那大家在工作中使用 GraphQL 的同学举一下手好么(观众互动),也是十个人不到的样子,这就是为什么要办这个会议(观众大笑)。
起因是这样的,我们当时想要去尝试 GraphQL 的时候,发现国内的文档,社区,会议等等关于 GraphQL 的资源都特别少,很匮乏,没有地方可以去沟通,可以去交流,后来我们只能找自己同行业的朋友去沟通发现大家其实都感觉交流匮乏,我们最后把这条路的坑都踩过了之后,觉得是不是可以自己总结的一些东西,可以单独拿出来跟大家分享。

在过去不到一年,大概十个月左右的时间里我们团队用 GraphQL 实践了一些产品,发现自己确实从中受益了,觉得说这个经验的确是可以拿出来跟大家来探讨的。
再回到大会的主题,有这么几个关键词,一个是协同,一个是效率,领域驱动是单独的 1 Part,然后还有前后端职能变化。其实这也是我自己感受最深几个词,一个技术带来的价值不仅仅是开发效率本身的提升,可能还会带来额外的价值,这些额外的价值可能是协同或者是前后端职能的变化。这也是为什么会去举办 GraphQLParty,以及定这个主题的原因,因为无论是 GraphQL 还是领域驱动,包括他们结合后的价值,这个话题在国内目前没有一家公司真正拿出来去讲,我们觉得自己可以第一个来吃这个螃蟹,然后和大家一起去推动这个事情。

今天下午一共有五场分享,有前端后端的分享,也有比较方法论的,当然会有干货湿货,我们能对讲师的要求呢,就是不要讲太高大上的东西,尽量讲比较接地气的东西。同时我们不知道行业水准怎么样,我们会先把自己做的东西,无论水平如何,都拿出来给大家看看。

然后我们这里有一些问题列了出来,这个在我们开始报名活动开放时候就已经公布出来了。今天下午大家可能会对讲师的演讲内容产生不同的疑问,你的问题可能是这里面某一个,也可能不在这个里面,但没有关系,如果你想了解 GraphQL,了解领域驱动,可能这里面都会有一些问题是你躲不过的。
大家可以带着问题听今天下午的五场分享,但能否拿到答案现在也不好说,但最终大家一定会有自己的判断。
当所有问题全部解决掉之后,对我们在场的资深从业者来说可能还会面临一个终极问题,那就是假如说今天,你们讲师们啊,都讲的都有道理,我想去用打算去推动,那么会给我的团队带来哪些收益,又会遇到哪些技术上的挑战,遇到哪些坑。技术挑战和遇到的坑一会儿由我的搭档来为大家介绍,我先为大家讲一下宋小菜自己有了多大的收益,来举一些案例。

关于案例呢,先来了解一下我们的产品背景,毕竟技术不能脱离场景,宋小菜 10 个前端工程师,其实不到 10 个,大概是 7 个,是最近几个月才招到了几个,我们一共开发和维护了 6 款 APP,1 款小程序,1 个复杂的 ERP 系统,市 调系统,报表系统等等。这看起来像是一个大团队做的事情,但其实我们最多只有十个前端来负责。那这里面就会有很多问题,比如说 APP 与 APP 之间,人与人之间的合作,我们之前使用版本不稳定的 RN,踩了很多坑,这个开发和协作成本太高,必须造轮子,或者用轮子优化开发效率,所以针对前端团队内部做了很多事情,就像 PC 端一样需要解决资源上线、打包问题、编译、版本、缓存等很多问题,我们也不例外,差不多这些就是 7 个人陆陆续续开发的内部工具,所解决的特定的问题。

举个例子:大伯伯推包系统,所解决的问题是在我们需要发布 APP 包的时候,如果一个人打的包,钉钉上传给那个小伙伴,他去上传的包有可能就会出错,而且这种故障有发生过,这种场景可能靠人肉是解决不掉的,所以我们开发大伯伯推包系统,让机器对接机器,通过机器去做这件事情,这里面有大伯伯,大表姐,大瓜子,为什么取这个名字,是因为我们希望产品能尽量接地气,再加上谐音,比如打包叫做大(打)伯(包)伯(包)。
刚才这么多问题解决掉以后,我们发现还是不行,前端团队内部效率啊,配合成本确实降下来了,但是发现团队之间的成本还降不下来,比如有这三个比较典型的问题是我们逃不过去的,并且跟前后端关系都很大。

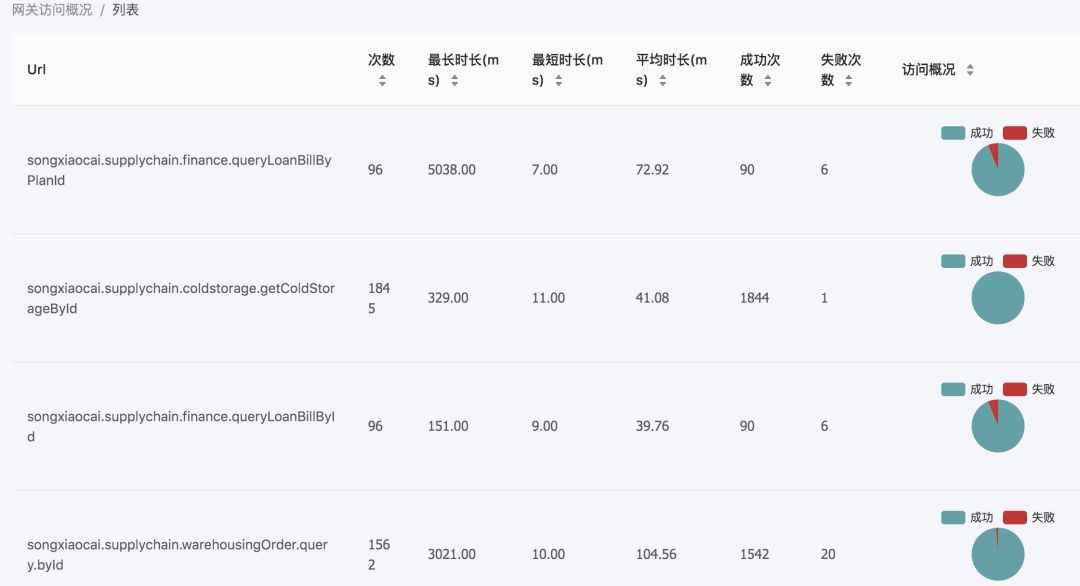
第一个是多端之间的类报表同步,大家现在开发前端,可能开发小程序,APP,PC,会有多端,对我们公司场景来说我们这个端比较杂,可能要在 ERP 要透出报表,在 App 上透出报表,在小程序上透出报表,但是面对不同权限的人报表透出的维度不一样,但本质上下面的数据源是同一份,那我们就可能开发很多个接口去对应不同的 APP,那这个问题靠前端是解决不了的。
第二个是多端之间多模块共享,这个模块不太准确,我解释一下,意思大概是比如有一个用户模块,一个订单模块、一个物流模块,每个模块里面可能会有一两个组件来组成,不一定是什么组件,但向下所需要的基本数据可能还是同一份或者同两份,只是在不同端上的 UI 呈现不一样。那我们想要让这些模块之间去共享数据很难,我们在不同端上开发一个组件就绑定一个接口,这个组件拿到另外一个里面去,套到那个模块去用的时候发现行不通了,这也是一个很大的成本。
第三个是业务变化快,产品总要升级迭代,难免 UI 设计师要找活给你干,要改版的时候,加一个字段,减一个字段,或者叠加几个字段,那么接口又要升级,或者加一个新接口,这个同样导致合作成本很高。
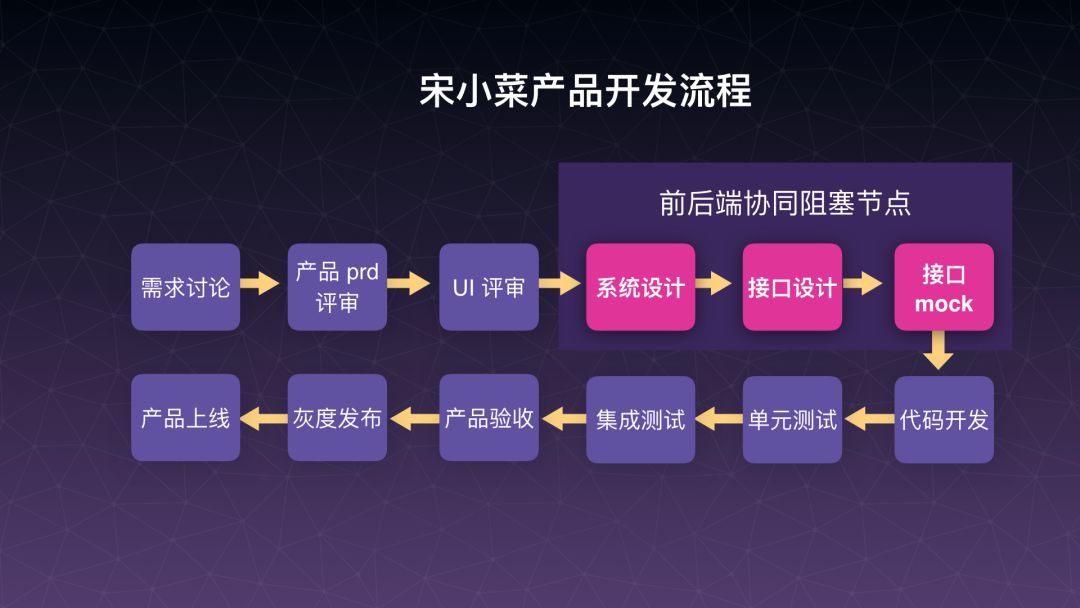
为什么会这样?是因为我们都知道啊,基本上行业内通用一个开发流程是这样的,可能大家的团队比我图示上显示的长一些,短一些都没有关系,但大家跳不过的是这几个环节,来看红色的几个,系统设计,里面涉及到 Java 服务端工程怎么搭建、骨架怎么搭建、服务怎么拆分,最后具象的时候,是服务端同学设计这个数据库和表结构,这几张表上面的字段有哪些。然后接口设计,服务端同学会给出接口的文档,比如说会给你提供五个接口,每个接口 15 个字段,才会进入到前后端对接完之后,再帮你去做一份 Mock 数据,然后前端在页面上把页面样式重构之后,再去调假的 Mock 数据,然后页面交互流程调通之后再切到正式接口,大概是这个套路。这里面有很多工具栈,很多第三方开源的工具可以用,那我们发现这里面前后端堵塞在这个点,而且堵塞很多年也解决不掉,因为接口设计控制权在服务端手里,前端不知道会给到多少接口,然后在接口评审时候,15 分钟或者一个小时,前端基本上很难理解哪个字段背后的业务含义,过后还要和服务同学反复再沟通确认,就因为在这个点的堵塞导致上面三个问题不是很好解决。

把三个问题再抽象一下,其实就是这三个:第一个是 API 的设计,服务端同学有的时候会被迫也好,被 “强奸” 也好,我必须要面向你多变的 UI 去做 API 的设计,面向这些页面服务,页面变化的时候,API 可能也要升级。第二个是 Mock 职责重合,之前也知道业界很多公司自己做了 Mock 工具和平台,我们一直也是在使用第三方的,有时候是前后端共同维护同一份 Mock 接口,有的时候是服务端去维护,但是总之要存在一个协作成本,到底谁来对它负责,这件事情,到现在也说不清楚。服务端同学给你做完 Mock 之后终于可以沉下心来做底层的业务开发,但发现临时需要调整一个字段,就把接口调整了,但是忘记去更新 Mock 文档,前端不知道这个事情,到后面俩人一对接发现字段对不上,这就是一个典型的工作流协作问题。还有一个问题,这个对于 toB 公司,或者 toC 也有这样的场景,就是报表,报表可能是一个刚需,对于管理层其实需要看到过去一周一个月公司交易的整个规模、吨位、物流情况、库存情况,不同维度的数据观测。业务打法一变报表的维度也要变,传统的报表开发就前后端各一个,服务端搞定数据库,跨表跨库查询,给出标准的字段结构,前端就是把它套到 Table 表格里面去,这个事情很简单,但是可能要排期,一天两天三天,可能产出报表的速度就很有限了。
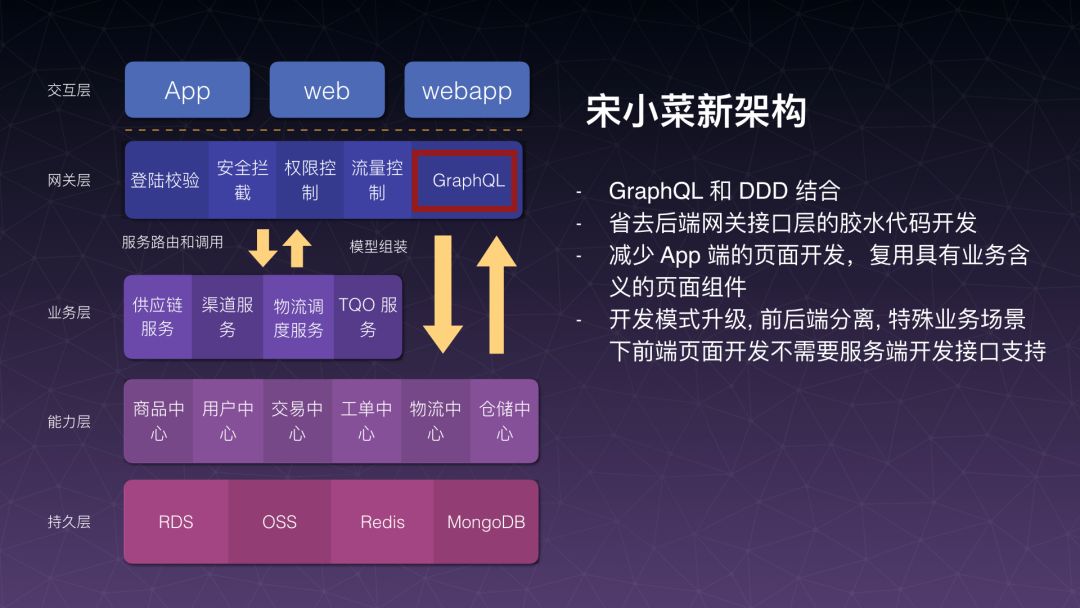
针对刚才的问题,我们先把宋小菜在自己的业务场景下,技术的解决方案拿出来给大家看一下。我们现在解决方案是在网关这一层,集成 GraphQL 的一个聚合服务,第二场架构师会来讲具体架构图,这边单独讲这一个点。我们理想中的 GraphQL 接入方式,是跟网关同层嵌入在里面做一个管道,但是现在我们的实现方式呢,考虑到快速跑通,暂时把它放在网关的下面,是为它的鉴权跟安全不想占太多开发成本,把它交给网关去做了,所以它就只做数据聚合这么一件事情。

那么通过系统改造,我们开始回答之前的问题,那就是收益有什么?2016 年 2017 年差不多 2 年多时间为了整个公司开发的报表一共 50 张报表,总的开发时间没有详细计算,但是这并不代表说整个公司只需要看这 50 张就够了,而是因为我们只有这么多人力开发这 50 张,报表开发成为一个瓶颈,当我们通过 GraphQL 在端上透出以后,包括服务端去一些拼装的动作,现在提供了可视化报表编辑的系统,这个系统面向产品经理和运营,面向服务端工程师,他们通过可视化的界面配置一下,报表就生成了。
这个系统上线以后四个月就产出 200 多张报表,把整个公司报表需求全部消化掉了。现在的情况是,产品经理跟业务方开会,业务方说:我需要看一下某个服务站一周的报表数据,我要提需求,我需要这个指标这个指标。然后会还没开完,产品经理就把报表做完直接上线了,现在报表产出就是这么一个节奏。通过做这个系统我们发现 GraphQL 可以给我们带来很大方便,我们就继续往下挖,把 GraphQL 它的价值从 APP 端继续往下沉,沉到服务端,我们就做了大舅子,前面的报表系统是大(搭)表(表)哥(格),是搭 Excel 表格的一个谐音,这边是大舅子,公司的产品啊,他们都是亲戚。
大舅子是我们今天分享的主题,刚才那个 GraphQL 的聚合服务叫大舅子,这个到现在为止实践不到 3 个月时间,跑了一些项目,目前评测下来可以节约的人力是这样,如果一个小日常小项目需要前端后端共同开发 4 天,我们可以把成本降到 3 天,那这是单个人的状况,如果人更多的时候,多人对接成本的提升通过这个系统的表现会更加的明显。

上面是从业务结果拿到的收益,除了这个收益之外还有别的收益。就会涉及到今天另外一个关键词 - 前后端的职能变化。大家心目中的前端跟服务端我不知道是怎么样的,我就说下我们现在朝着一个方向走是这样子的,前端对于页面上的数据有一定的控制权,我需要什么样的数据只有我自己知道,因为我需要对数据有控制权,要更快去输出页面,包括去走通一些业务流程,点了什么按纽,触发什么事件,就必须去理解每一个字段背后的业务含义,我要去理解每个字段背后的业务含义,就必须去理解业务。以前会说我只需要 UI,理解交互,理解产品就好了,业务我不管,反正给我们什么字段就用什么字段,我们去消费数据。现在对前端的挑战在这里,我要负责的事情有一些变化。对于服务端来说,反而很爽,因为我终于不用再面向多变的页面去设计 API,我从里面解放出来了。
那么解放出来之后会带来两个问题:
第一个问题是解放出来的时间用来做什么?
第二个问题是如果前端介入到这一层,你们还会对我(服务端)提什么要求?
对于第一个问题,既然有精力时间,我可以把胶水代码都拿掉,把 Mock 的时间,粘合数据的时间省下来去做底层的服务设计,提供更稳定的数据服务,反过来前端也会希望说服务端同学提供的接口也好,不同的领域设计也好,给我趋于稳定的设计,而不要给我多变的设计,不要因为每一次前端页面改版研发而引发后端服务改动的大地震,这是前后端的一个变化。
那我们到底怎么通过代码通过工程的方式拿到这个收益呢,接下来由我的同事陈锦辉跟大家去做具体的工程上的分享,掌声欢迎陈锦辉。

陈锦辉:大家好,我是宋小菜的前端工程师陈锦辉,刚刚 Scott 给大家讲了一下宋小菜在一段时间内实践了 GraphQL 的结果以及我们搭建基于 GraphQL 的数据聚合系统——大舅子,这是 Scott 的七大姑八大舅系统里的一个成员。这里简单介绍一下我要讲的主要内容,关于什么是 GraphQL,我会开始先做一个科普,后面演示一下现在正在试用这么一个系统,最后有哪些坑需要去踩,最后再针对 GraphQL 开开脑洞。
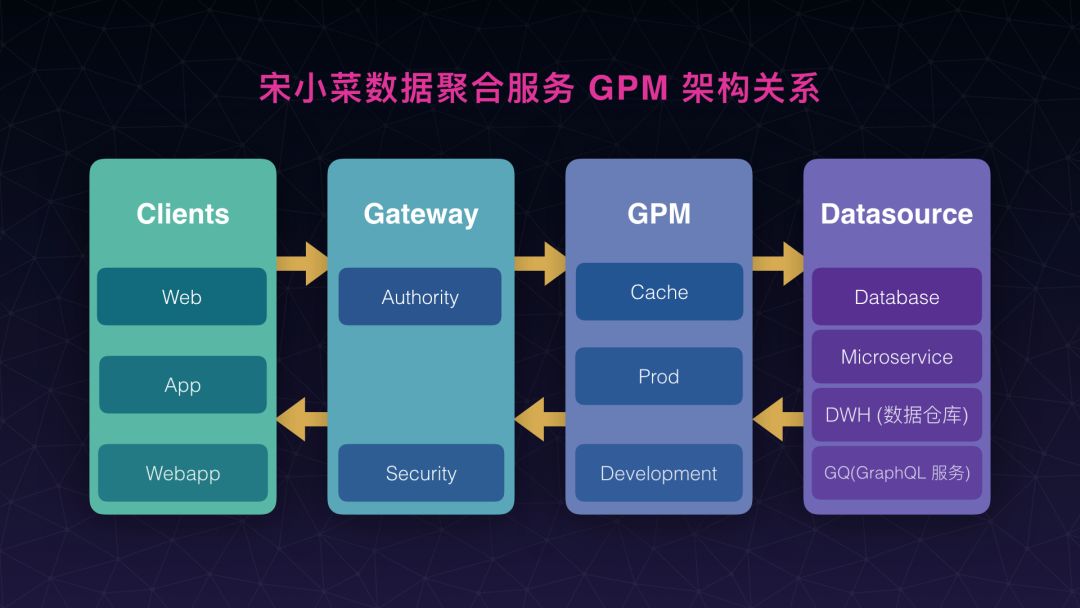
最开始先看一下大舅子的这个数据聚合系统,在我们整个系统架构里面到底处于哪一个位置。从图示中可以看出它处于我们的网关和后端数据服务的中间,刚刚 Scott 也解释过,我们网关本身已经存在了,所以它已经把如鉴权和安全一类的事情做掉了,所以我们在做数据聚合服务的时候,将这个服务放到网关后面。为什么取名叫 GPM,它全称叫 GraphQL Pipe Manager,这是对一个对后端服务提供的数据提供数据拼装的这么一个系统。
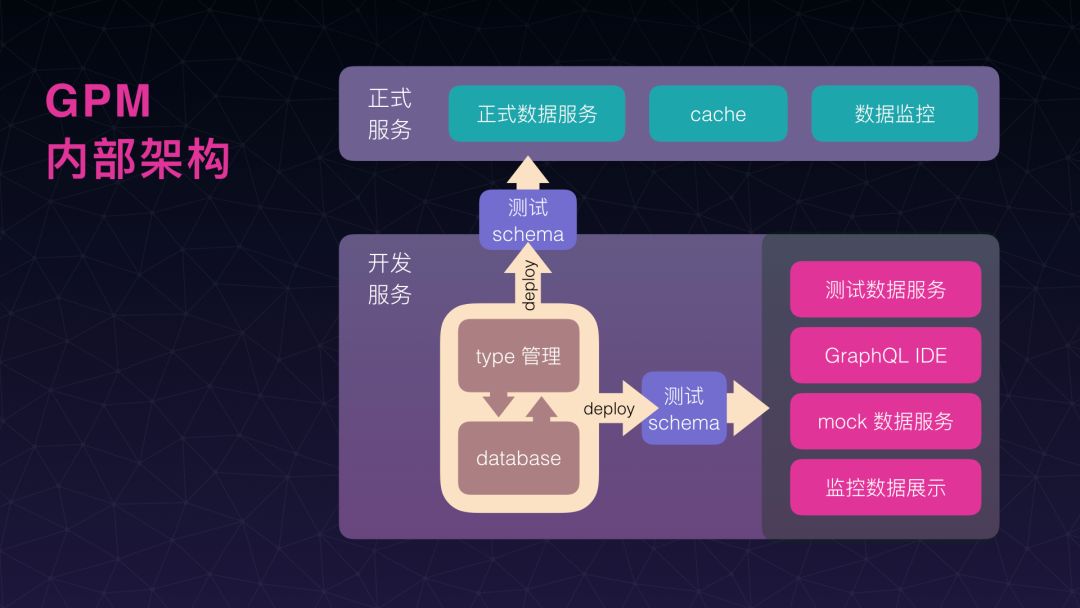
这是我们整个 GPM 内部架构大概一个结构图,分成两部分:一部分是正式的服务,可以看到正式的服务比较简单,因为要保证提供正式数据服务稳定,所以我们尽量简化它。另一部分稍微复杂一些的,是开发服务,在开发服务里面我们可以对类型进行编辑管理,然后在开发服务上进行测试,最后应用到我们的正式数据服务上。
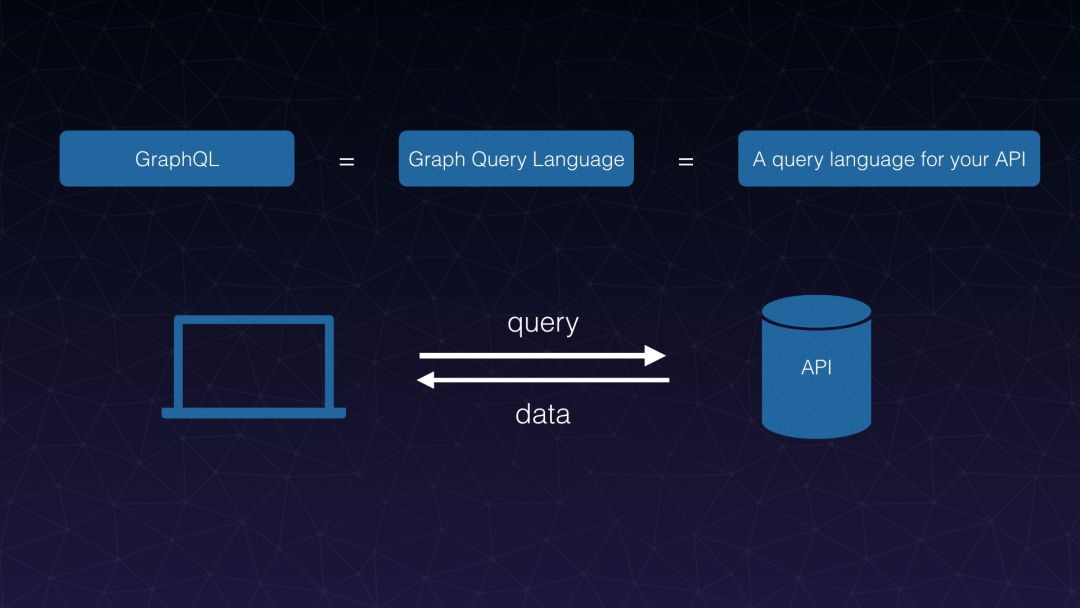
介绍完我们使用 GraphQL 的大致情况后,鉴于在场的部分同学之前可能没有接触过 GraphQL,所以我先来介绍一下什么是 GraphQL,GraphQL 全称叫 Graph Query Language,官方宣传语是“为你的 API 量身定制的查询语言”,用传统的方式来解释就是:相当于将你所有后端 API 组成的集合看成一个数据库,用户终端发送一个查询语句,你的 GraphQL 服务解析这条语句并通过一系列规则从你的“ API 数据库”里面将查询的数据结果返回给终端,而 GraphQL 就相当于这个系统的一个查询语言,像 SQL 之于 mysql 一样。

宋小菜经过一个时间不是很长的实践,发现使用 GraphQL 给我们带来五点的比较方便的地方:一个是单一入口,第二个是文档的展示和编写,第三个也是比较有特色一点,就是数据冗余可以使用 GraphQL 来避免,第四点数据聚合是这一个系统本身最主要的职能,还有最后一点就是数据 Mock,Mock 相当于比较棒的附加值。


首先说一下单一的入口这一点。传统的 RESTful API 里,不管前端还是后端都要对 API 做管理,一是版本管理,二是路径管理,非常麻烦,增加了工程管理的复杂度。但是如果使用 GraphQL,只需要一个入口就可以了。刚刚也说到 GraphQL 相当于一个数据库,它的入口只有一个,我们只需要访问这个入口,将我们要查询的语句发送给这个入口,就可以拿到相应的数据,所以说它是一个单端点+多样化查询方式的这么一个结构。


第二点是文档,这里文档虽然不能完全替代传统的文档,但是它能在一定程度上方便我们。传统的 RESTful API 文档管理,市面上有很多工具,像 Swagger、阿里开源的 RAP 以及 showdoc 等。但使用这些 API 文档管理工具的时候其实是有一定的学习成本的。像 Swagger, 可能对于老手来说使用起来不是很复杂,但是对于刚上手的开发者来说上手还是需要一点时间的。然后还有在使用这些平台的时候都会遇到让人头痛的“ API 和文档同步”的问题,很多时候需要自己去做 API 和文档同步的插件来解决。
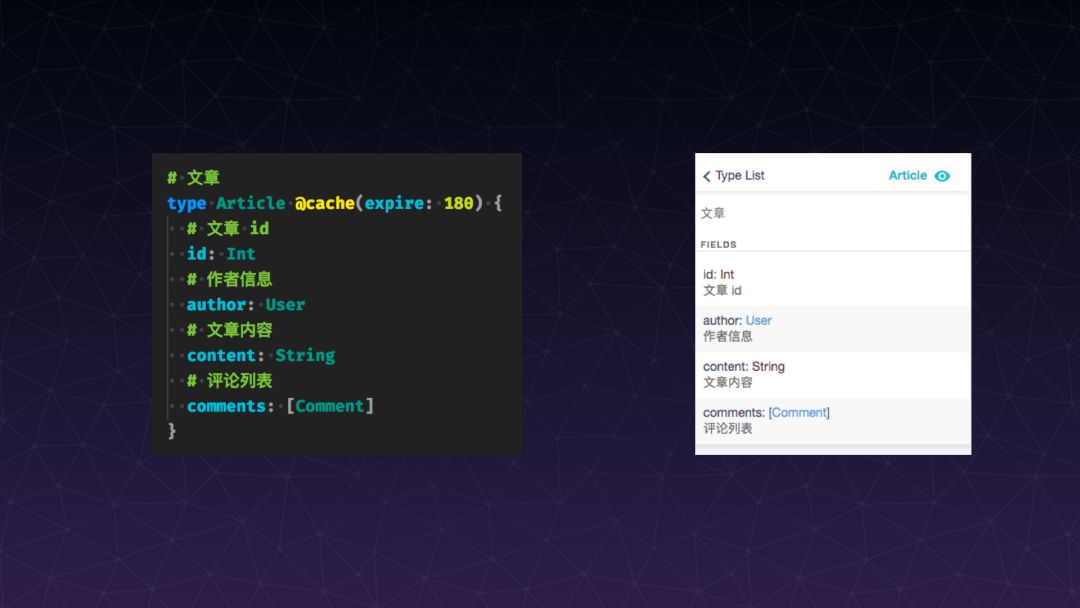
如果使用 GraphQL 就可以在一定程度上解决 API 文档的一些问题:在做 GraphQL 类型定义的时候我们可以对类型以及类型的属性增加描述 (description) , 这相当于是对类型做注释,当类型被编译以后就可以在相应的工具上面看到我们编辑的类型详情了,像示例的这一个类型 Article,它的描述是 “文章” ,它的属性有哪些,有什么含义,都会展示在大家面前,只要我们在开发的时候规范编写类型,整个文档的展示就比较规范了。
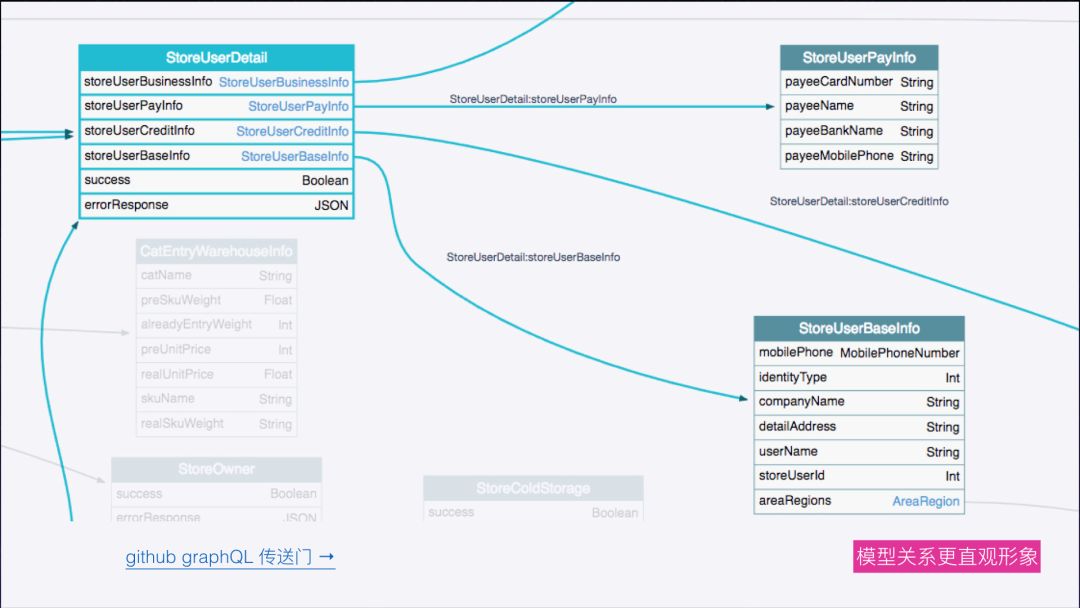
使用 GraphQL 还有一个比较棒的功能,就是每一个 GraphQL 类型 其实相当于 mongo 里面的一个 collection,或者 mongoose 里面的 Model, 而每一个类型之间关系也可以用工具很形象的表现出来。像系统上用到这么一个模型,它对应到哪些和它有关系的模型都高亮出来了。
链接: https://apis.guru/graphql-voyager/
这里演示一下,可以传送看一下,在 Github API 4.0 开放出的 GraphQL API,它将 Github 所有的对外类型都暴露出来了。可以看到每一个类型对应的定义和解释都在左面有显示出来。每一个类型都有对应的 UML 图展示,这是一个比较大并且比较复杂的 UML 关系图。我们主要平时用到一个核心的类型其实就是仓库 (repository) 类型,我们可以看到这个类型比较复杂,同时它也是比较核心的,和它有所关联的类型就非常的多,仓库类型下还有 issue 这个属性。如果我们参考 Github 开放的 API 4.0,就可以做到在 Github上面开发相关的插件。


使用 GraphQL 的第三点好处就是可以避免数据冗余。我们在传统的 RESTful 处理冗余的数据字段大约有这么三种处理方式:
一是前端选择要不要展示这些字段;
二是要么做一个中间层(BFF)去筛选这些字段,然后再返回终端来展示出来;
三则比较传统也比较麻烦,还不一定能生效,就是前端和后端去做约定,如果说这一个接口这一个字段已经不要,可以和后端商量一下把这个删掉,但是有一种情况可能造成冗余字段删不掉的,那就是后端的同学做这个接口可能是“万能接口”,也就是说这个接口在这个页面会用,在另外一个页面也能用,在这个应用会用,在另外一个应用也可能会用,多端之间存在部分数据共享,后端同学为了方便可能会写这么一个“万能”的接口来应付这种情况,久而久之,发现字段冗余到很多了,但是随便删除又可能会影响到很多地方,导致这个接口大而不能动,所以前后端都不得不忍受它。
但如果使用 GraphQL,就可以避免接口字段冗余这个问题,使用 GraphQL 的话,前端可以自己决定自己想要的返回的数据结构。刚刚我也解释过,GraphQL 实际上是一种查询语言,我们在使用时就像是在数据库里面查询数据一样,查询的某一个数据要哪些字段可以在查询语句里写好,要哪些字段就返回给我们哪些字段。

拿 PPT 上这个作为示例:我们要去拿 id 为 1 的文章,如果我只要 id 和 content,我在 query 里面指定这两个字段,那么返回的就是 id 和 content,如果除了 id 和 content 之外,我还要拿需要作者信息的时候,我只需要在 query 里面指定 author , GraphQL 就将作者的信息给返回回来。这样就能做到前端决定自己想要什么结构的数据返回的就是什么样的数据。


最重要一点当然是数据聚合,数据聚合在使用传统的 RESTful 的方式时有多种解决方案:
一种前端发针对这个页面上的多数据源单独发起数据请求,然后一一展示出来,这样可能会出现页面数据加载不同步的情况。
第二种就是开发做数据拼装的中间层(BFF),用于拼装后端提供的数据,然后返回给前端。
还有一种是宋小菜在最前期的使用一种方案,那就是后端同学编写针对页面的 API,即所谓胶水代码,来拼接各个服务的数据,返回给前端。
如果是第三种情况的话,就会有大量的工程需要我们去维护,大量的 API 需要我们去维护。但如果使用 GraphQL 的话,这些问题都不会存在,因为它是天生支持数据拼装的。
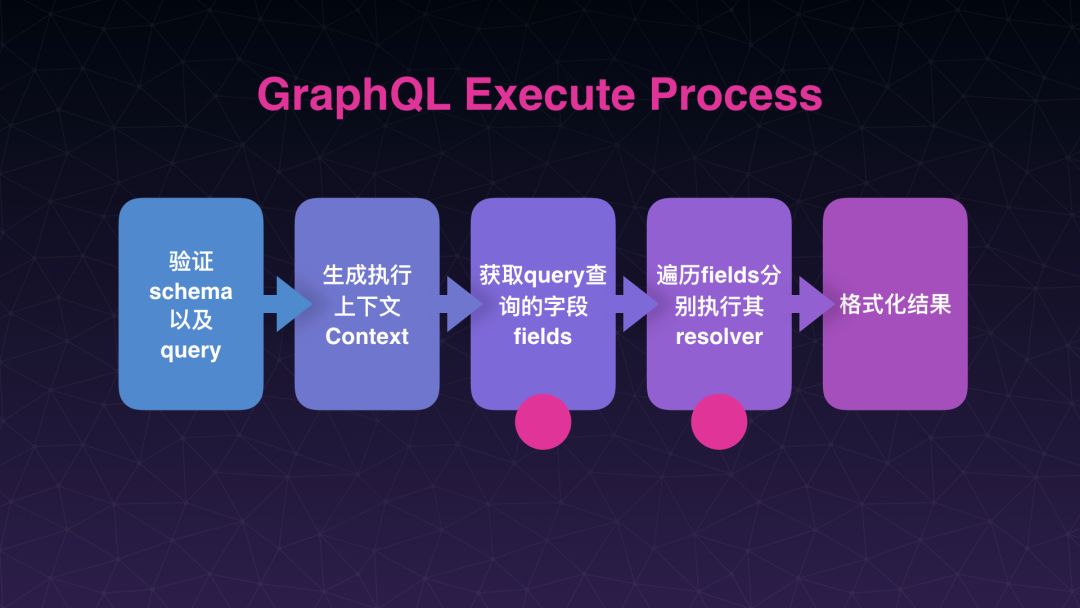
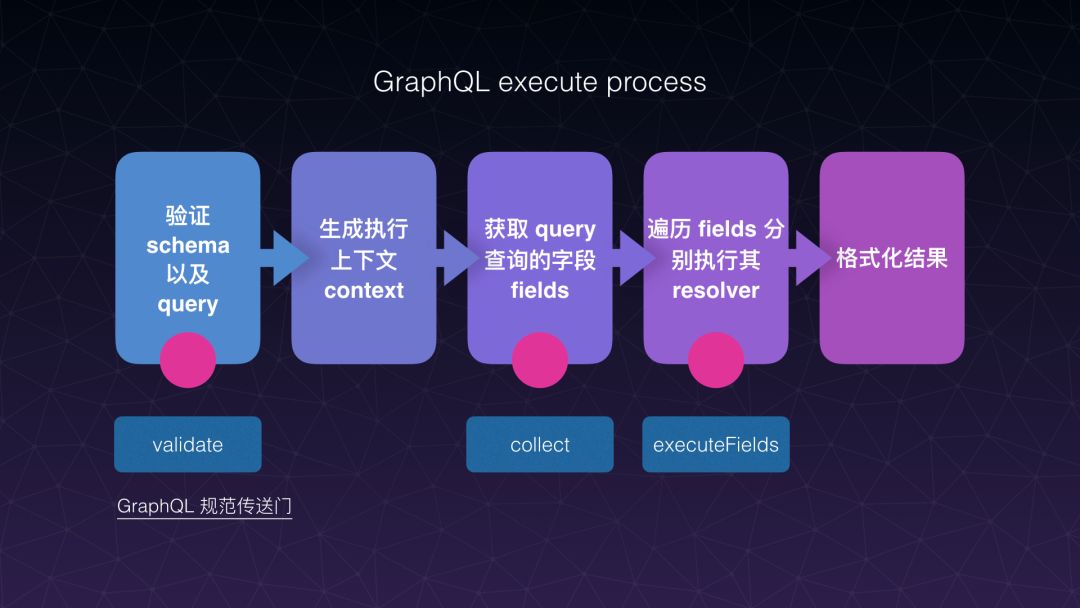
为什么它是天生支持数据拼装的呢?我来尝试着从 GraphQL 执行的原理上大概解释一下。这是个GraphQL 执行的大致流程,第一步我们去验证需要去执行 GraphQL 的标准,同时去验证将要去查询语句的合法性,第二步生成执行的上下文,关键点在第三步和第四步,第三步是获取查询语句所需要查询的字段,这里叫 fields,所有需要查询的字段可以在查询语句里通过算法拿到,这里可以解释刚刚提到的 GraphQL 怎么做到避免返回数据的冗余的。拿到所有需要查询的字段后,第四步针对每一个字段去执行它的 resolver,可以从 resolver 返回数据里面拿到字段对应的数据,最后是格式化结果并返回。
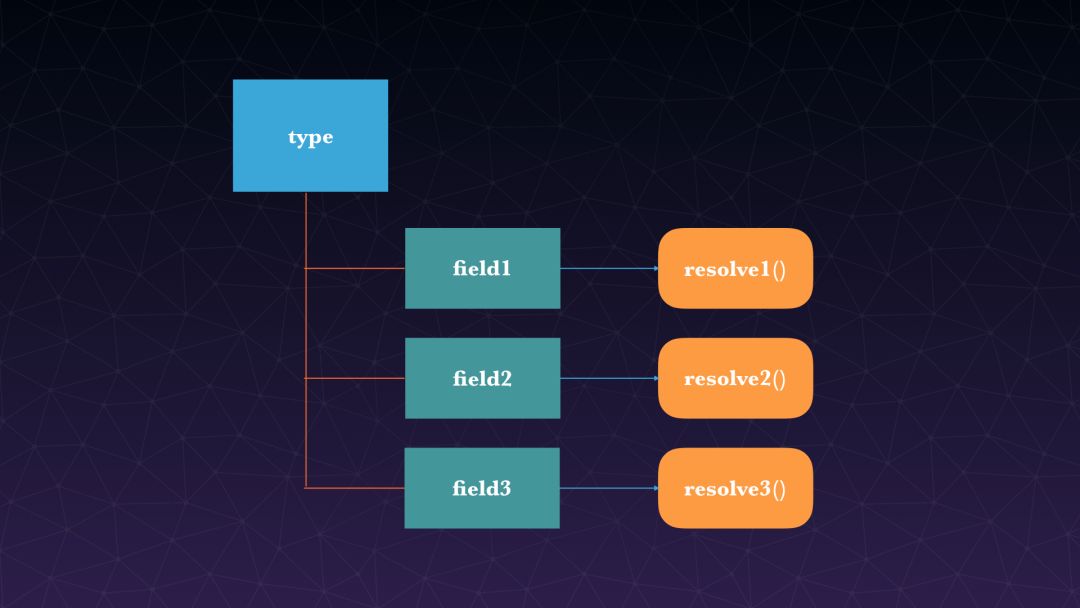

第四步我解释一下,在GraphQL里面有一个类型的概念叫类型 (type),每一个类型下面对应的是一个或多个字段,每一个字段绑定了一个 resolver,这个 resolver 的作用就是获取字段对应的数据。对应到刚刚举的例子,比如 article 这个类型,它有四个字段: id,author,content,comment。每一个字段都对应的一个 resolver。而这个 resolver 其实是可以被开发者重新定义的,如果说没有定义的话 GraphQL 会给一个默认的 resolver,像Article 的 author 字段类型是 User , User 可以从用户服务里面去获取,所以我们可以将 author 这个字段 resolver 重新定义一下,通过 UserService 获取用户信息。下面的评论(comment)也一样,我们可以通过 CommentService 获取评论数据,这样可以做到在查询这个文章的时候既获取了文章本身的数据,也通过 UserService 和 CommentService 获取到了作者信息和评论信息,然后经过拼装返回给客户端,这样就达到了使用 GraphQL 进行数据拼接的目的。

第五点是附加的一点,我们可以适当地利用 GraphQL 做数据 Mock。那么使用 GraphQL 怎么去做到 Mock 呢?

GraphQL 的类型大致可以分为两种类型:
第二种是普通类型,像刚刚示例中的文章(Article)类型,普通类型下面可能会有多个字段,每个字段对应的数据类型可能是普通类型也可能是标量类型,这种类型也可以做 Mock,如果我们对标量类型做了适当的 Mock 以后,像 Article 的 Mock 数据就会自动生成。
使用 GraphQL 做数据 Mock 还有一个方便之处在于经典 Mock 数据可以被很方便地复用。如刚刚示例中查询 Article 下面类型为 User 的 字段 author 的时候可以利用这个特性,因为用户信息(User)这个类型不仅仅会用于文章的作者也可能会用于评论的作者,所以我们针对User 类型做一个 Mock 数据,这个 Mock 数据可以会在查询文章作者和查询评论作者中同时用到,同时我们也可以在返回 Mock 数据时耍一些小花招,例如从几个用户数据中随机返回一个用户信息,或者根据查询条件返回对应的假数据等。

使用 GraphQL 做数据 Mock 有多方面的好处:
好处之一就是 Mock 数据随着类型 (type) 走,当我们修改类型以后,它的 Mock 数据也是会被同步修改,不会出现 Mock 数据和类型不同步的情况;
好处之二就是能很容易地实现 Mock 数据的细粒度,原理刚刚也解释过了,这样能够很大提高我们的开发效率。
好处之三是 Mock 数据可以复用,节约开发时间。
最后一点,那就是 Mock 数据的职责可以由前后端共同承担。或者说由前端自己来做,因为通常情况下 Mock 数据的消费者都是前端自己,为何不自产自销呢,省去大量的交流成本。
这里简单做一个演示(现场是联网操作后台,这里仅插入部分截图示意),展示一下我们开发出来的还在试用期的一个 BFF 服务—— GPM,目前它的页面还比较简陋,还在还在试用阶段。
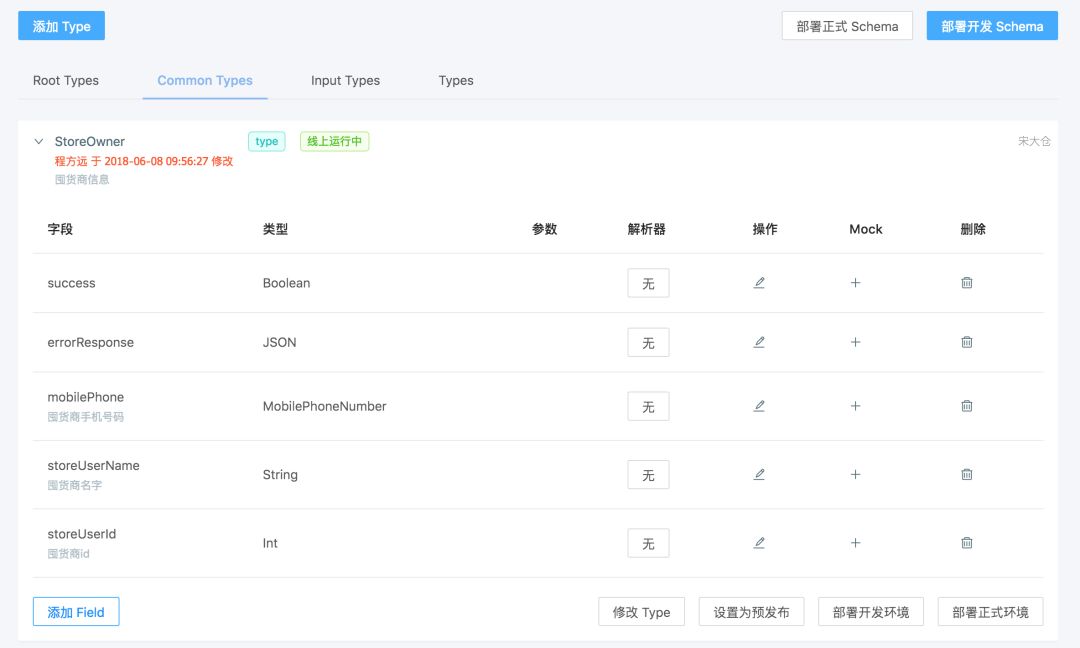
在 GPM 中每一个生成类型都会以表单的形式展现出来,当然代码的形式也会有特定的地方呈现,我们只是对每一个类型都进行可视化,如果作为一个新人来使用,只需要点击按纽添加类型,指定类型名字,填写类型描述,根据类型的实际情况设置缓存有效时间,绑定到宋小菜的哪些 APP。然后针对已经添加好的类型可以对它做字段的添加的操作,指定字段的名字、类型、描述、缓存有效时间,以及 Mock 数据。
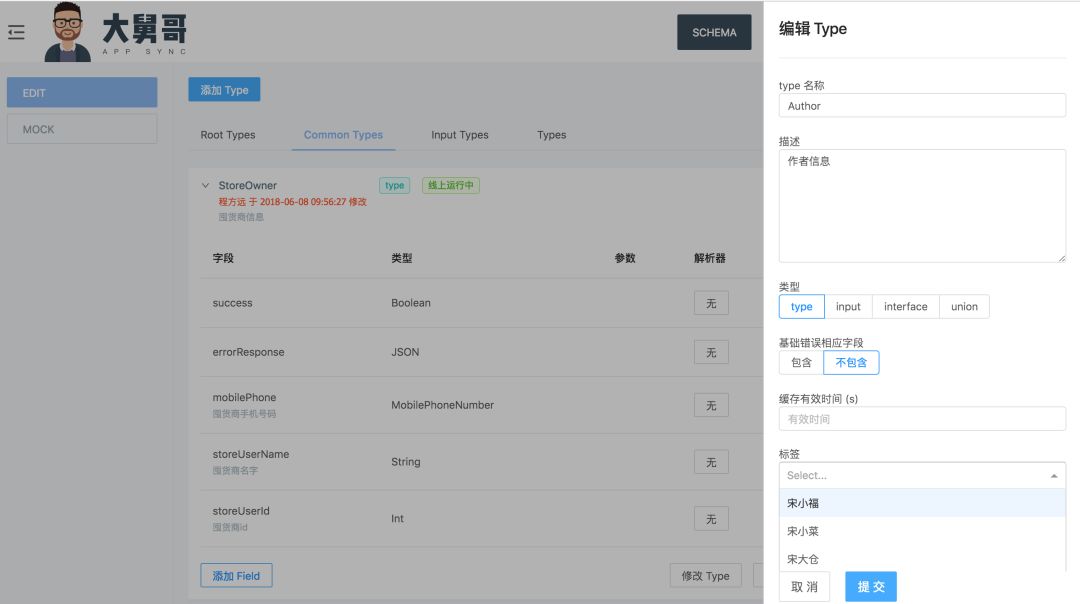
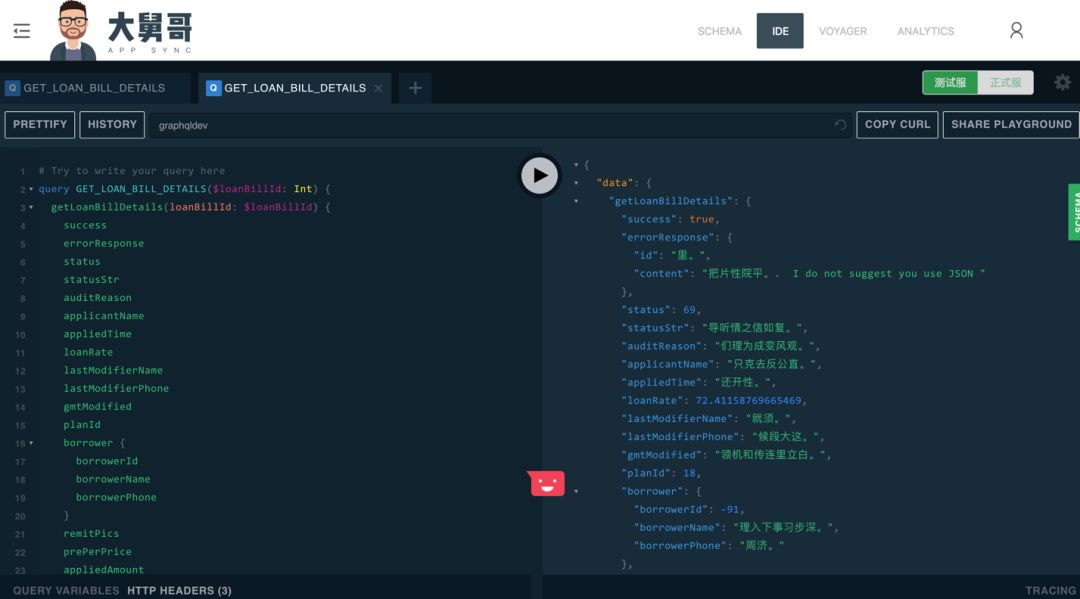
同时这一个系统可以直接在线上测试并发布类型的:我们在编辑好一个类型以后,可以部署到开发环境上,然后在 IDE 里面做调试提前查看返回数据是否正确。像刚刚说到的处理数据字段冗余是怎么做的,这里可以演示一下,在前端不想要这一个字段时,直接在查询语句里面删掉然后执行查询就能拿到不包含这个字段的数据了。我们也可以通过 IDE 获取这个查询语句结果的 Mock 数据。
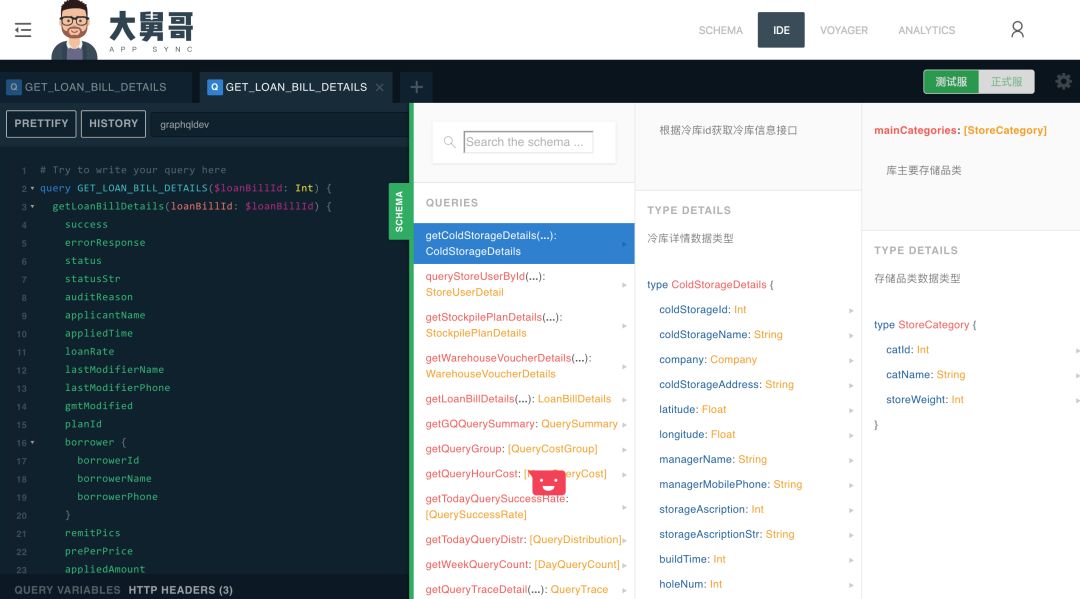
在写查询语句的时候这个 IDE 根据我们已经生产的 schema 自动帮我们提示,就像使用普通的桌面 IDE 一样,而每一个类型的文档可以从右边的弹窗里面看到。GPM 将 IDE 分为了正式服务和测试服务的 IDE, 正式 IDE 时针对线上数据做查询的。我们在测试好了新增或者修改的类型以后就可以部署正式环境上了,不用重新发布 GPM 就可以做到。
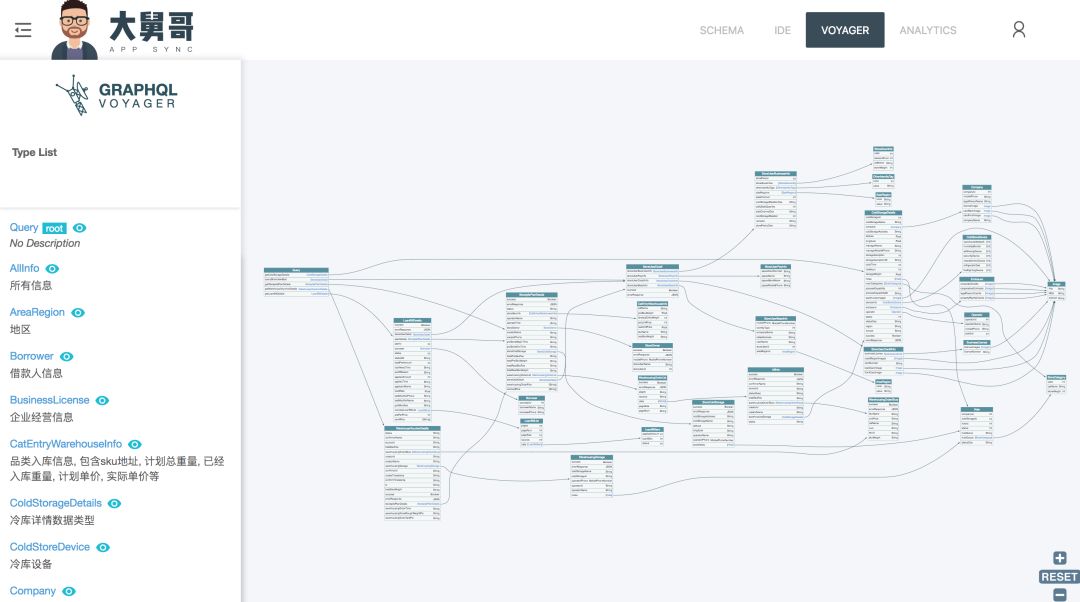
这是刚刚提到文档展示,GPM 也集成进来了,可以看到这些类型有哪些,然后这些类型到底有什么含义,类型和类型之间的关系是什么样的,都可以在这里很方便的去查看。
在 GPM 上我们还做了一些附加的功能,因为我们后端提供的微服务大多数是用使用 RSETful 的方式去调用的,所以我们特意做了一个针对 RSETful 请求的追踪,这里可以看到每一个 RSETful 访问的情况。
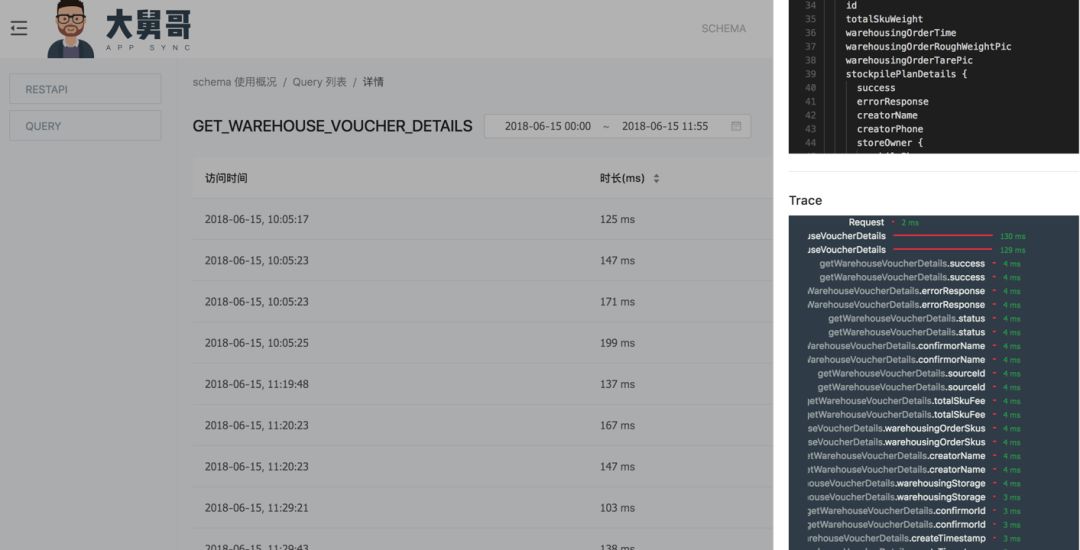
最重要的其实是对每一次 GraphQL 查询语句的追踪。可以看到,像我们执行这么一个查询语句,拿到的数据结果,执行时间,这一个查询语句的详情都能看到,同时还可以看到每一个字段查询速度如何。又比如说,像这一个接口,它绑定两个服务,一个服务是囤货单的服务,还有一个服务是供应商信息服务,这样子可以看到每一个查询字段它追踪到这种执行效率怎么样的,可以根据这个查询结果来告知后端同学做优化。
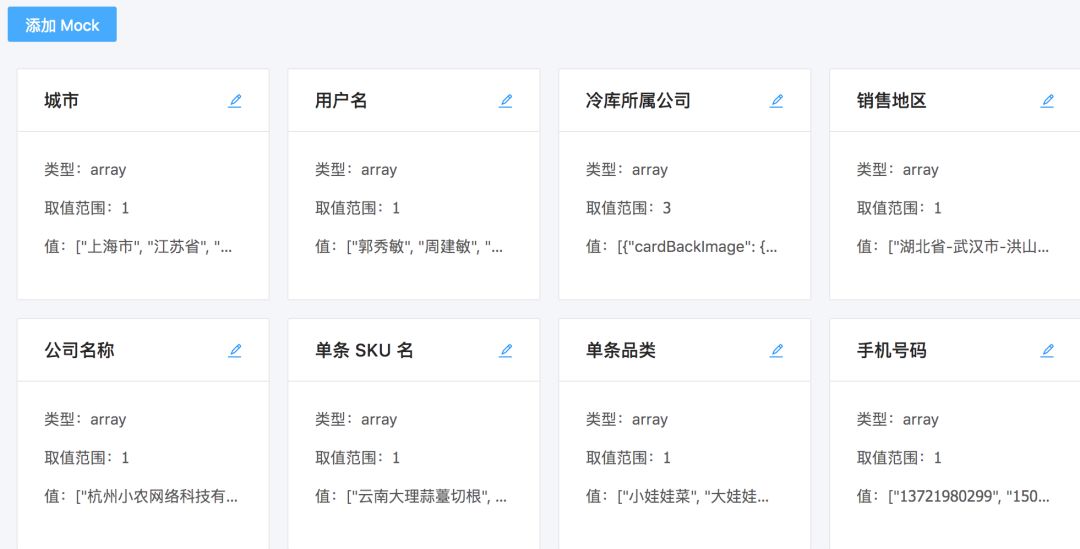
还有我们的部分自定义 Mock,这就是整个 GPM 大概的样子。因为时间的关系,我就只稍微说一下我们是怎么去实现在线编辑部署 GraphQL 的。

GPM 是使用 nodejs 搭建的,所以这个方案是针对 nodejs 的,其他语言的解决方案需要大家自己去探索了。实现这个功能有以下几个关键点。

关键点之一是替换 schema,实际上 schema 可以被修改的,只要我们使用特定的方式将每次执行的 schema 修改掉,那就做到了每次执行 graphql 时都会使用到最新的 schema 了。
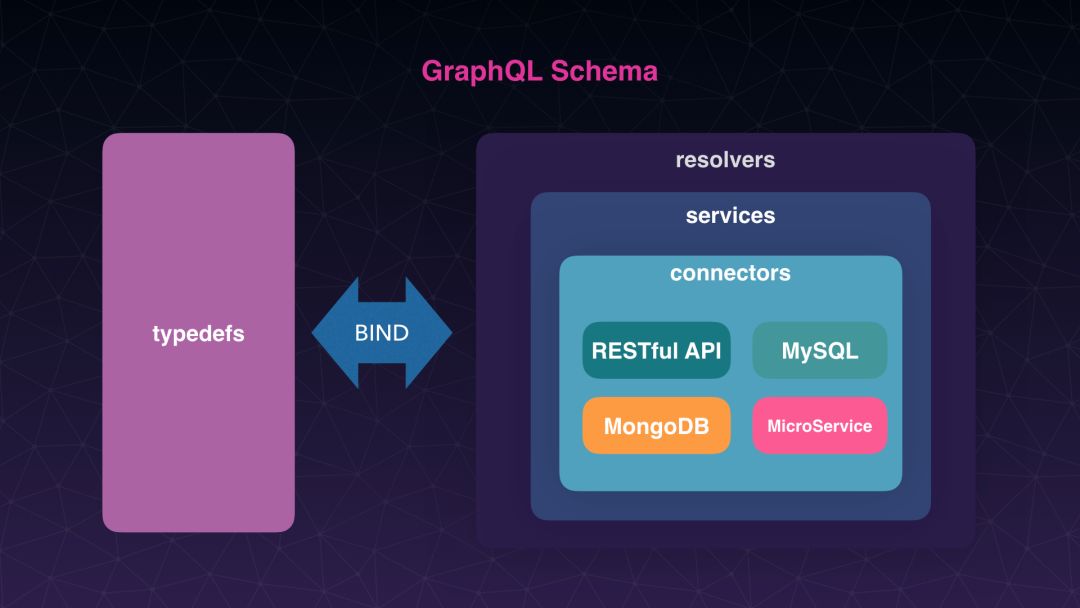
关键点之二怎么做到修改已经在使用中的 schema:我们将 GraphQL 的 schema 分为两部分:一部分是类型定义,另一部分是 resolver。前面也提到过,每个类型下面有字段,每个字段下面绑定了 resolver,我们其实可以把类型定义和 resolver 分开来,同时对 resolver 进行适当的分层。GPM 的分层结构是这样子,但这是我们自己的这种分层,其实还有其他方案,后面的讲师会讲到。 然后我们将 resolver 和 type 定义做好以后,将它使用一些开发工具将它绑定起来,就生成了这么 GraphQL 的 schema 。

在做查询时候就参考 schema 来做,type 定义本质上是 string,关键的一点就是怎么去动态生成 resolver,也就是第三个关键点,这里稍微简单讲一下。


我们首先需要去简化 resolver,resolver 本身它的形式是固定的,函数签名其实就是这样,类型下面字段名字,字段名字下面有四个参数,然后返回结果。第一个参数是父类型的查询结果,我们有可能会使用到它类型下面的一些查询的数据;第二个是指定的查询参数;第三个最就是我们刚刚提到的执行上下文(Context),我们可以在执行上下文 (Context) 里面去调用绑定的各种服务。这就是是 GPM 中 resolver 大致形式,第一步拼装参数,第二步使用执行上下文调用服务,就可以动态拿到数据,这样就可以做到动态生成 resolver。


我们在使用 GraphQL 的时候有一些无法避免的问题是需要去解决的,这里有两个绕不开的问题:
第一是安全问题
第二是慢查询的问题
当然还有其他需要解决的问题,关于安全的问题后面的讲师也会讲,时间的关系,这里就不细讲了。
慢查询在终端已经有很多用缓存去解决这个问题的方案了,像 apollo、relay。还有就是在 GraphQL 服务里面去做缓存,apollo 提供的 apollo-engine 就是这种方式,但这个要翻墙才能用,所以只能用来它作为参考。还有一种方案是宋小菜在 GPM 里面用到的:合理地利用 GraphQL 提供的指令 (directives) ,去置换 resolver,这样做到 GQ 服务数据的缓存。还有使用 dataloader 来批量处理多次重复查询,后面的讲师也会提到。


最后有一个加分项,就在做 GraphQL 的时候有一个数据收集,在 GQ生态里面有 GraphQL-extension,用起来非常好用,我们可以参考它来做一个自己的 extension 追踪 GraphQL 查询语句的执行情况,我们也可以使用第三方工具来做,如 apollo 的 trace。

最后来一起开个脑洞。
GraphQL 本身其实是一个标准,我们没有必要一定要使用官方 提供的 GraphQL 引擎,我们可以根据自己的实际情况去实现自己的GraphQL。
重新回到 GraphQL 的执行的一个流程,我们在实现自己的 GraphQL 引擎时可以做到以下优化:

相同的查询语句其实没必要每次都去做验证,这里可以节约一点点查询时间。既然是相同的查询语句它的这种字段收集其实没有必要再去做收集,可以用一些比较简单的方式去避免重复 collect fields。还有比较提升性能一点,官方的 graphql-js 去执行每一个字段的 resolver 时是循环串行执行的,有没有可能做到针对实际情况适当地并行执行 resolver。
最后做一个总结,当宋小菜在使用 GraphQL 的时候,概括起来有以下六个特点:
单一入口,单端的入口方便前端做工程管理,避免后端做烦琐的API 版本管理。
文档,这个文档可能在一定程度上能够解决文档同步的问题和前端开发阅读的问题。
数据冗余比较方便,减少前后端交流成本。
数据聚合。GraphQL 天生支持数据聚合。因为每一个类型绑定resolver,所以定义不同的 resolver,就可以拿到不同服务上的数据,可以做到不同类型数据源的数据拼装。
Mock,适当将 Mock 的职责交到前端,或者前后端一起维护,而且维护起来比较简单。所以说 Mock 方便我们开发。
动态编辑做到实时部署,敏捷开发。实时部署很快做到线上数据的响应。
Scott:回答观众的问题
对于宋小菜的前后端合作工作流,直观上可以看到这几个变化:
前端从接口设计环节,向前介入到服务端的系统设计中的库表结构评审环节,此时不仅能了解到库表的字段分布和业务含义,也能在库表设计上就提出一些建议,帮助服务端输出更友好的字段类型和结构给前端,比如 精度和维度,这两个是分开存,还是用逗号隔开,存一个 String,是有分别的;
服务端省去 Mock,省去胶水 API 的设计和维护,省去 Mock,节约的时间可以专心做底层基于业务的系统拆分,提供更稳定的数据服务,构建更健壮兼容的底层架构;
前端在接口评审之前,就可以在 GraphQL 的自定义类型 Mock 上抽象大部分的字段出来(服务端一但确定库表结构,后续改动的可能性就会很小了),此时就可以把 DOM 页面实现后,把占位符的字段就填进去了大部分,最终结构上在接口评审环节双方针对接口特殊性,再核对调整一遍就好了;
前端由于有服务端领域边界的支撑,可以针对特定领域及领域的组合,来封装更有弹性的组件,组件的扩展性可以由配置决定,而不是某一个 API 决定,这个配置向下就是 GraphQL 的聚合能力。
关于第 3 点,是需要前后端不断磨合的,关于第 4 点,我们仍然在探索尝试,最终想要表达下我们前端团队的做事的一些理念,我个人认为这一点很重要,尤其对于初创团队。团队里面,无论事情看上去是属于谁的,最终事情一定是公司的,无论一个技术推广影响到谁或者撼动了谁的所谓原来立场所代表的利益,只要对公司研发团队效率有利,有利于技术演进,有利于推动业务更快的走,那么就要果断尝试。最终,为我们所有人的行动买单的是公司,但最最终,依然是我们自己。
最后,为你推荐
以上是关于第1306期GraphQL 聚合层解放前后端的主要内容,如果未能解决你的问题,请参考以下文章