技术博客 | 用 GraphQL 快速搭建服务端 API
Posted GlowInc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术博客 | 用 GraphQL 快速搭建服务端 API相关的知识,希望对你有一定的参考价值。
今天的文章中会简单介绍下 GraphQL 和我们在服务器端使用的第三方库-- Graphene-Python, 以及我们选择这个技术的原因。并通过一些简单的例子展现如何快速上手 GraphQL 。

GraphQL的介绍
▶什么是GraphQL
简单来说,GraphQL 是一种查询语言,它被设计出来的初衷是用于提供 API。
与 RESTful 设计不同,GraphQL 一般仅暴露出一个接口供使用,而具体一个请求中需要什么数据,数据怎么样组织完全由 API 的使用者(客户端)来指定。 当然,哪些数据可以被查询,数据的类型是怎么样的,则是由服务端给定的。 指定的方式就是传入一段关于想要的结果(或操作)的描述,服务端保证返回符合要求的结果或报错。
这篇文章不是重点介绍 GraphQL 本身,就不展开讲了,如果想深入了解可以访问 graphql.org。
对于完全没有接触过 GraphQL 的读者,我们举个例子帮助理解:
考虑现有数据实体 Starship 和 Crew ,它们的对象类型如下:

code 1.1
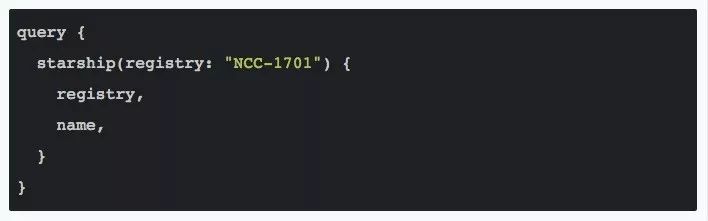
我们就可以得到查询结果
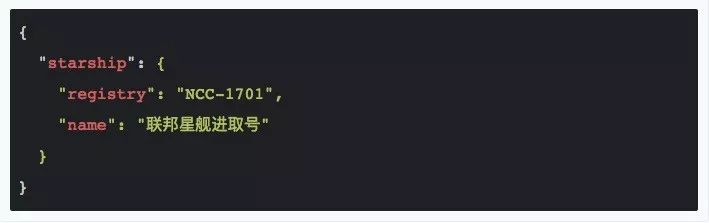
来看看更完整的例子:
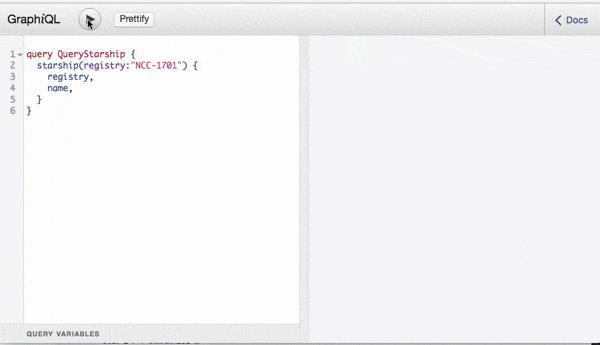
Glow 的服务器语言是 Python 。所以我们就选用了比较出名的 Graphene-Python 。
主要看中的是 Graphene 成名较早有一定数量的用户,以及配套的、适用于 Glow 技术栈的集成组件(比如 Graphene-SQLAlchemy 和 Flask-GraphQL )。
为什么选择GraphQL
GraphQL 本身的概念和使用都比较直观,对于开发者来说,比起怎么使用它更终要的事情是了解自身需求并觉得是否需要使用 GraphQL 以及如何使用。那么对于 Glow 的开发团队,它吸引我们的地方在哪呢?
▶强类型
▶更容易支持客户端的版本更迭
▶良好的“自说明性”
给 API 撰写文档是费时费力的工作,其实文档往往要解决的问题很简单:告诉别人我这个查询请求了怎样的数据,我预期会接收到怎样的结果。虽然在 RESTful API 里,我们可以通过路径命名笼统知道这个请求的作用,但使用 GraphQL 就可以在通过查询语句清晰、具体地描述这个请求的输入和输出。
比如在 code 1.2 中,这句语句查询了 registry=NCC-1701 的星舰,并且返回结果里包含该星舰的 registry 和 name 字段,一目了然。
开始在服务器端使用GraphQL
▶安装


▶设计ObjectType并编写Query
下面我们就以 Starship 和 Crew 为例,演示如何比较完整地实现 GraphQL 的服务端。
参考 code 1.1 的定义,简述一下我们的数据实体,我们有「Starship(联邦星舰)」和「Crew (船员)」,有名字、编号、种族等字段。Starship 可以有一组 Crew 即字段crew: [Crew] ,每个元素都是一个 Crew 。
那么在安装完所有依赖并在 .py 文件中 import 必要的库后,我们定义如下对象类型:
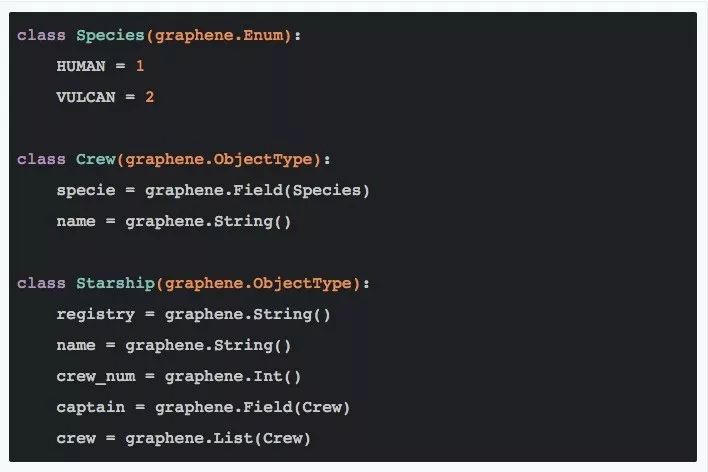
code 2.1
定义非常直观,即使没有接触过 GraphQL 和 Graphene-Python 的读者想必也能明白这几行代码定义了些什么。graphene 库提供了各种基本数据类型的定义(称为 Scalars)供我们使用。枚举型的字段可以通过继承 graphene.Enum 来实现,枚举型的处理稍微有点特殊,请通过这里了解更多诸如枚举变量的比较、展示的细节。
稍微要注意的是,指定字段类型时,必须用这些数据类型定义的实例,比如 grephene.Int() 。而用 graphene.Field 或 graphene.List 来指定类型或者,则需要传入类型的类本身,比如graphene.Field(Species)。
另外可以看到 Starship 的 captain 字段是另个一 ObjectType :Crew ,定义时也必须用 graphene.Field 将其封装为一个 Field 而不能直接使用 ObjectType 。
完成数据实体的定义以后,需要定义 Schema 。 GraphQL 的 Schema 是所有操作(即 Query 和 Mutation )的根类型, GraphQL 服务器会根据 Schema 来决定如何提取数据并验证数据。在我们的例子中,现在仅提供 Query 以支持一个查询操作:
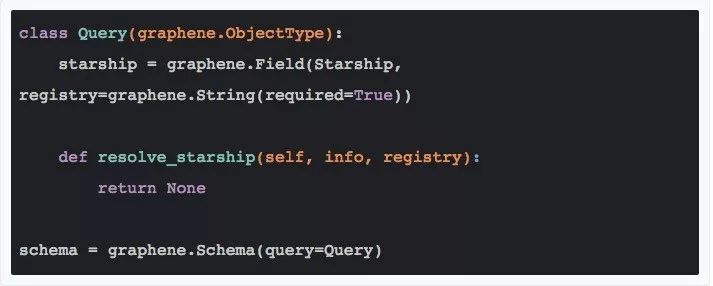 code 2.2
code 2.2
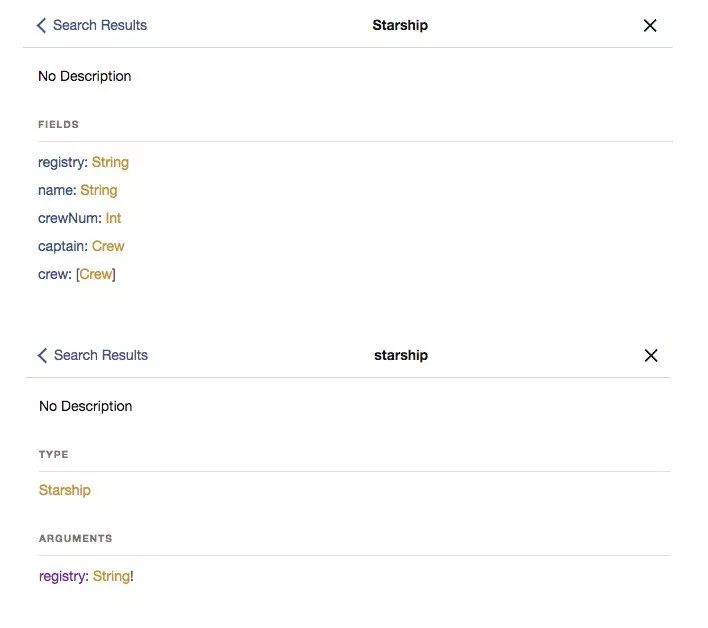
fig 2.1
结合 code 2.2 和 fig 2.1 ,客户端可以知道:
哪些字段是服务端会提供的::
registry、name、crewNum、crew以及他们的数据类型自己应该如何查询 Starship :通过字符串类型的
registry来指定哪艘星舰
读者们会发现,在 code 2.1 中我们定义的字段名都是下划线风格( snake_case )的,如 crew_num (当然这也是 Python 的变量命名规范),但客户端查询到的字段名就变成了像 crewNum 这样的驼峰风格。这是 Graphene-Python 默认的行为,我们可以用snake_field = graphene.String(name='snake_field') 的方式来强制指定字段名。不过考虑到客户端多半是基于 javascript 的,通常不会修改该默认行为。
后面的工作、也是关键的部分,就是如何实现 resolve_starship 这个方法了。简单来说,只要接入现有的查询逻辑(比如数据库查询,RPC 调用等)即可,这里不展开了。下面要讲到 SQLAlchemy 的集成,会提到怎样通过集成来减少实现 resolve 的工作量。
▶SQLAIchemy集成
在快速开发过程当中大家可能遇到这样的问题,就是一套数据需要反复定义多次,从数据库的 SQL ,到 DAO 层,再到 API 层甚至客户端。这些工作让人感觉非常重复,因为大部分时候从上到下字段名、类型都是一样的。那下面就看下如何通过 GraphQL + SQLAlchemy 来减少重复劳动。
根据之前的描述,我们现定义 SQLAlchemy 的表及其对应映射类如下:
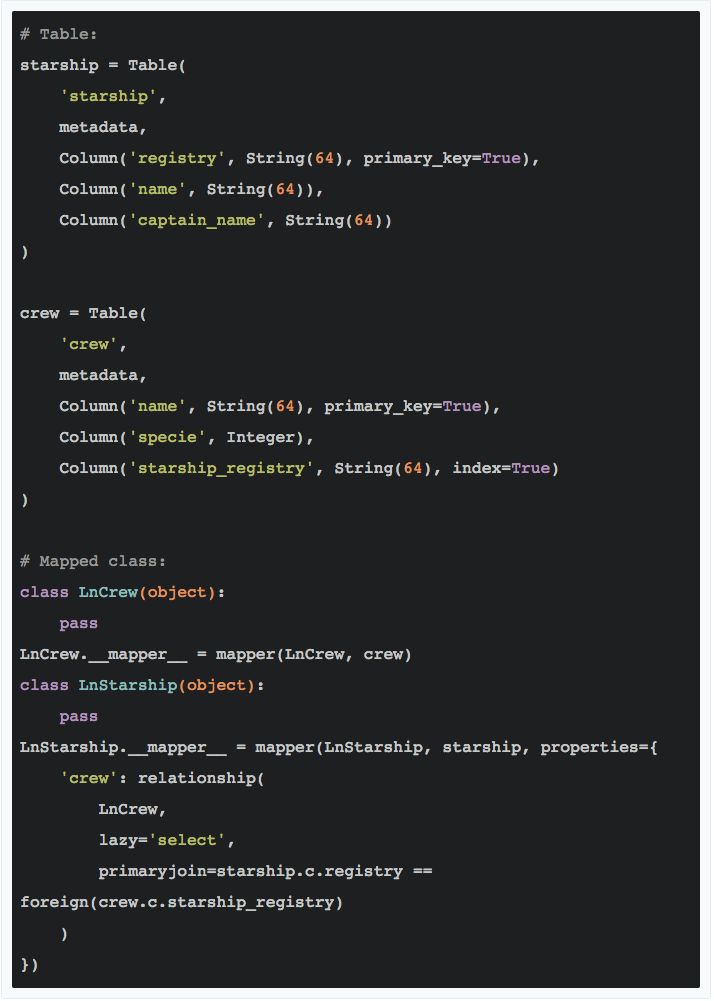
Code 2.3
实际上定义 SQLAlchemy 的表和映射类的方式有很多种,这里只是其中一种方法。注意到两个映射类 LnCrew 和 LnStarship 内部其实什么都没做,当它们和数据表建立映射关系后查询出的实例中会自动填充上数据库表中定义的各字段。而 LnStarship 的表本身没有 crew 属性,但在建立映射时我们将它指定为一种关系并通过primaryjoin=starship.c.registry == foreign(crew.c.starship_registry) 和 LnCrew 关联起来。
到了这一步,熟悉 SQLAlchemy 的读者肯定能想到 code 2.2 中的 resolve_starship 方法可以很方便地这么来实现:
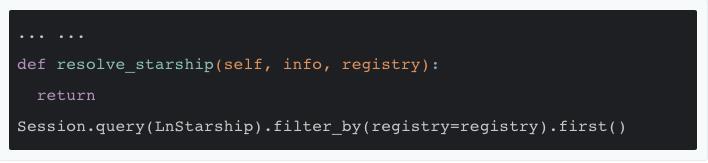
code 2.4
其中 Session 是 SQLAlchemy 的 Session 对象,整个数据库查询的语法也都是 SQLAlchemy 的语法,这里不加赘述。但这么实现完了似乎心有不甘,好像还是有一些字段在数据库表里定义了,在 GraphQL 的对象类型 code 2.1 里被重复定义了?
所以,下一步就是借助 Graphene-SQLAlchemy 的能力,进一步减少重复工作。现在我们把 code 2.1 和中的映射类和对象类型进行改造:
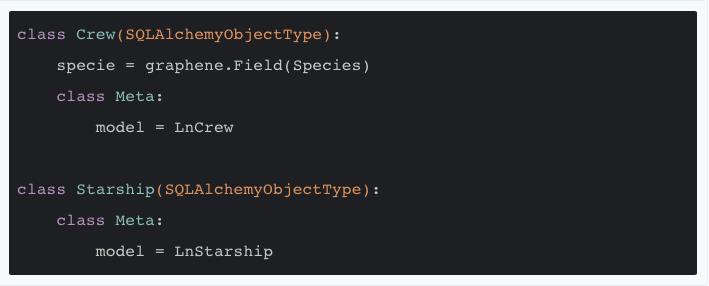
code 2.5
改动主要包括:
令 GraphQL 的对象类型继承自 SQLAlchemyObjectType ,并在类中定义 Meta 类指定相关的 SQLAlchemy 映射类作为模型;
移除所有重复的字段定义 (✌️);
保留数据库定义与 GraphQL 对象类型定义不完全相同的字段,如 Crew 的 specie 在数据库中用整型表示,但这里仍将其定义为枚举型 Sepcies 。
让我们看一下查询语句和运行结果:
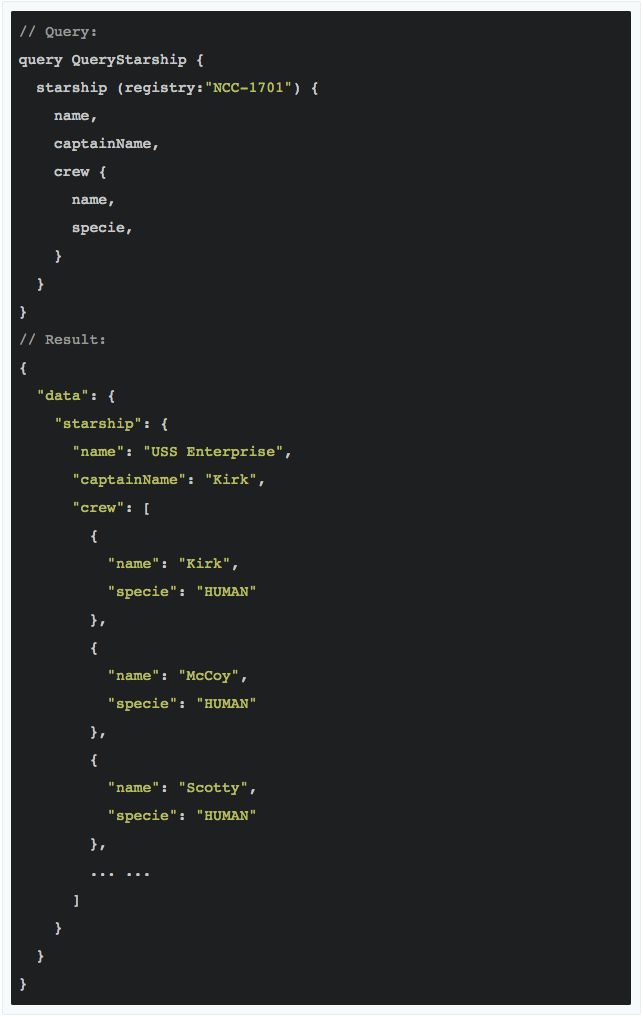
由于 Graphene-SQLAlchemy 的存在,继承自 SQLALchemyObjectType 的对象类型的属性都可以简单地通过数据库类型来推导,在不需要另外定义的情况下,Starship 的 name, captainName 甚至是复合列表属性 crew 也能正常查询。
可以看到 crew 里每个元素的 specie 属性最后是以字符串常量的形式返回的,这归功于我们在 code 2.5 中专门指定了里 specie 的类型,如果不指定,该字段就会默认成为数据库定义的整数。
另外,只要谨慎选择 code 2.3 中 LnStarship.crew 这一关系的加载方式(如我们现在使用的 lazy='select'),就可以避免无谓的数据库查询。比如现有一个查询星舰的语句不需要 crew 属性,那整个执行过程当中,都不会发生 Crew 那张表的 select 。这一点也是 GraphQL 带来的好处之一。
▶Flask集成
完成了定义和底部数据层的集成,下面要做的就是将 GraphQL Scchem 接入一个服务让客户端可以访问,如果 web 应用使用 Flask ,那可以非常简单地通过 Falsk-GraphQL 来完成,仅需 2 行代码:
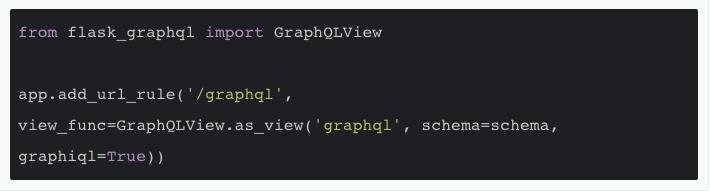
code 3.1
其中 app 就是 Flask APP ,'/graphql' 是指定的 url 入口,GraphQLView.as_view 会产生一个 Falsk 的 view function (实在不知道怎么翻译好),负责提供所有响应请求的方法,schema 当然就是我们之前定义好的 GraphQL Schema ,graphiql 参数指定了是否使用浏览器 GraphQL 交互 IDE - GraphiQL ,也就是我在 fig 1.1 ,fig 2.1 中展示的工具。
▶剩下的工作
到这里我们的实现还不完全,比如 Starship 的字段 crewNum 就没有。因为这是一个可推导字段,所以把它设计成「不存在数据库中」而是「根据真正 crew 的长度来实时计算」的一个量。请有兴趣的读者自己思考一下如何实现,有几种实现方式,每种方式的优劣是什么,各自对数据库负载和代码结构都有怎样的影响。
另外也请有兴趣自己动手试试的读者一定要熟悉 GraphiQL 的使用,可以有效提高开发的效率。现在都不需要自己启动服务,GraphiQL 的作者为我们提供了快速体验的入口:https://graphql.github.io/swapi-graphql/。
进入页面后点击右上 Docs 了解整个 Schema 的详情。
这有一个地方值得注意,该例中的 Schema 使用了 Relay (http://docs.graphene-python.org/en/latest/relay/)的一些概念,比如 nodes (http://docs.graphene-python.org/en/latest/relay/nodes/)和 connection(http://docs.graphene-python.org/en/latest/relay/connection/),如果觉得有些迷惑可以先阅读一下相关资料,我们也会在后续文章中介绍。
一些坑和需要注意的地方
使用 GraphQL 开发服务端 API 的过程总体比较顺利,但也有不少需要当心的地方和坑,最后为读者们稍微介绍下。
▶错误处理
▶处理带文件的请求
GraphQL 的请求本质是一个 body 里装了一个查询语句的 POST 请求,所以需要一些额外的处理才能支持 multipart 请求,比如使用中间件,客户端的网络接口也需要自定义。所以我们采取的方法是把上传图片独立到单独的 API,GraphQL 请求中已经是一个可用的 url 了。
当然这么做也有不好的地方,比如会改动用户的使用体验、需要额外的 UI/UX 在应对各种错误,但基本是一个比较平衡工作量和效果的方案。
▶SQLAIchemy集成带来的掌控性的缺失
将数据库定义完全绑定到 GraphQL Schema 固然可以减少很多工作量,但如果我们需要一个更高级、更定制化的查询,那就还是要自己实现 resolve 方法。同时开发者对于 SQLAlchemy 的 session 的生命周期、具体数据库查询语句的执行的掌握也可能变弱,造成一些潜在的性能问题。这点就需要我们在开发、测试的时候多留心。
个人经验是我会在开发过程中打开 SQLAlchemy engine 的 echo 属性,然后监控查询操作产生的每一句 SQL 语句,以了解实际产生的语句是否合理、是否产生了额外的数据库查询等。
▶监控的细分
GraphQL 提供的只是一套支持查询语句的 API ,而具体查询什么都是由客户端指定的。那就有可能有攻击者通过编写一些特殊的查询语句对服务器进行攻击,这些语句通常都是层数很深或请求数据的量很大,给服务器短时间内造成巨大负担达到拒绝服务的攻击效果。一般解决方法是限制查询的深度以及数据获取大小,同时对请求的发起者要有必要的身份认证。
另外由于服务端能提供的字段名称是完全告知客户端的,如果一个不小心也会泄露隐私数据,尤其是使用 SQLAlchemy 集成的时候,如果把数据库最底层的字段全都直接暴露给外部是非常危险的。SQLAlchemyObjectType 的 Meta 类支持通过 exclude_fields 属性指定不向客户端开放的字段。另外在对敏感数据做定义时,需要团队内部做好隐私审查。
结语
了解更多
试试回复这些关键词:
招聘 | 下载 | 技术博客1
| 技术博客2 | 技术博客3 | 技术博客4 | Glow |
以上是关于技术博客 | 用 GraphQL 快速搭建服务端 API的主要内容,如果未能解决你的问题,请参考以下文章