我们在采用GraphQL中学到了什么?
Posted 五里墩茶社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了我们在采用GraphQL中学到了什么?相关的知识,希望对你有一定的参考价值。
GraphQL并不是新生事物了。但是很多公司企业对它的使用还处于起步阶段。我们来看一看Netflix在引入GraphQL的过程中学到了些什么。
开始阅读前,科普两个术语
鸭子类型:duck typing - Duck typing in computer programming is an application of the duck test—"If it walks like a duck and it quacks like a duck, then it must be a duck"—to determine if an object can be used for a particular purpose. With normal typing, suitability is determined by an object's type.
非规范化:denormalization - Denormalization is a strategy used on a previously-normalized database to increase performance. In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data. 简单讲就是通过牺牲写的性能,添加必要的冗余数据或组合数据到数据存储中,来提高读取性能。
在之前的博客文章中,我们对营销技术团队中的一些应用程序进行了高级概述,我们构建这些应用程序是为了在推动我们的全球广告方面实现规模和智能,这些广告在纽约时报,Youtube等成千上万的网站上覆盖用户。 在这篇文章中,我们将分享我们更新前端架构的过程以及将GraphQL引入Marketing Tech系统的经验。
我们用于管理与外部发布平台交互的广告的创建和组装的主要应用程序在内部被称为Monet。 它用于增强广告制作并自动化在外部广告平台上的营销广告活动的管理。 Monet帮助推动增量转换,与我们的产品互动,总体而言,向全世界的用户展示我们的内容和Netflix品牌的丰富内容。 为此,首先,它有助于扩展和自动化广告制作并管理数百万个广告创意。其次,我们利用各种信号和聚合数据,例如了解Netflix上的内容流行度,以实现高度相关的广告。 我们的总体目标是使我们在所有外部发布渠道上的广告能够与用户产生共鸣,并且我们不断尝试提高我们这样做的有效性。
Monet and the high-level Marketing Technology flow
当我们开始时,Monet的React UI层访问了由Apache Tomcat服务器支持的传统REST API。随着时间的推移,随着应用程序的发展,我们的用例变得更加复杂。简单页面需要从各种来源中提取数据。为了更有效地将此数据加载到客户端应用程序,我们首先尝试对后端的数据进行非规范化。管理这种非规范化变得难以维护,因为并非所有页面都需要所有数据。我们很快遇到了网络带宽瓶颈。浏览器需要获取比以往更多的非规范化数据。
为了减少发送给客户端的字段数量,一种方法是为每个页面构建自定义端点;这是相当明显不是首选。我们选择GraphQL作为应用程序的中间层,而不是构建这些自定义API。我们还认为Falcor是一种可能的解决方案,因为它在许多核心用例中已经在Netflix上取得了很好的成果并且使用量很大,但强大的GraphQL生态系统和强大的第三方工具使得GraphQL成为我们用例的更好选择。此外,随着我们的数据结构越来越以图形为导向,它最终变得非常自然。添加GraphQL不仅解决了网络带宽瓶颈问题,而且还提供了许多其他优势,帮助我们更快地添加功能。
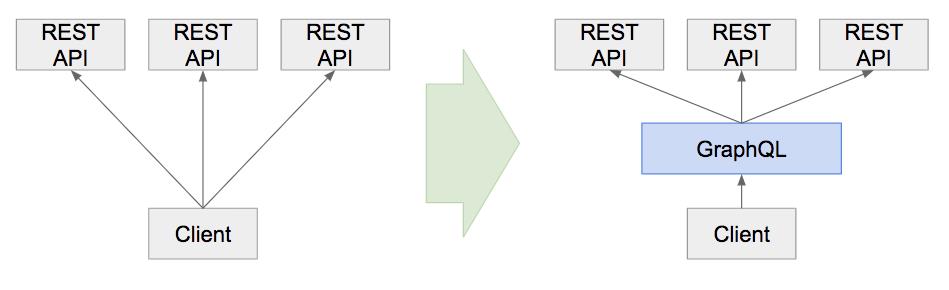
GraphQL之前和之后的架构
优点
我们已经在NodeJS上运行GraphQL大约6个月,并且它已经证明可以显著提高我们的开发速度和整体页面加载性能。 以下是自我们开始使用以来对我们有益的一些好处。
重新分配负载和有效负载优化
通常,某些机器比其他机器更适合某些任务。当我们添加GraphQL中间层时,GraphQL服务器仍然需要调用与客户端直接调用的相同的服务和REST API。现在的区别在于大多数数据在同一数据中心内的服务器之间流动。这些服务器到服务器的呼叫具有非常低的延迟和高带宽,与来自浏览器的直接网络呼叫相比,性能提升了8倍。从GraphQL服务器到客户端浏览器的数据传输的“最后一英里”虽然仍然慢,但减少到了单个网络调用。由于GraphQL允许客户端只选择它需要的数据,我们最终会获取一个明显更小的有效负载。在我们的应用程序中,之前接收10MB数据的页面现在可以接收大约200KB。页面加载变得更快,尤其是在数据受限的移动网络上,我们的应用程序使用的内存更少。这些更改确实以更高的服务器利用率来达到获取数据和聚合为代价,但是每个请求的额外少许毫秒服务器时间在更小的客户端有效负载面前可以忽略不计。
可重用的抽象
软件开发人员通常希望使用可重用的抽象而不是单一用途的方法。 使用GraphQL,我们定义一次每一段数据,并定义它与我们系统中其他数据的关系。 当消费者应用程序从多个源获取数据时,它不再需要担心与数据连接操作相关联的复杂业务逻辑。
考虑以下示例,我们只在GraphQL中定义一次实体:目录,创意素材和评论。 我们现在可以从这些定义构建多个页面的视图。 客户端应用程序(catalogView)上的一个页面声明它希望目录中所有广告素材的所有评论,而另一个客户端页面(creativeView)想要知道创意素材所属的关联目录及其所有评论。

GraphQL数据模型在用于表示来自相同底层数据的不同视图的灵活性
相同的图模型可以为这两个视图提供支持,而无需进行任何服务器端代码更改。
链式系统
许多人专注于单一服务中的类型系统,但很少跨服务。 一旦我们在GraphQL服务器中定义了实体,我们就会使用自动代码生成工具为客户端应用程序生成TypeScript类型。 我们的React组件的属性接收类型以匹配组件正在进行的查询。 由于这些类型和查询也是针对服务器模式进行验证的,因此服务器的任何重大更改都将被使用该数据的客户端捕获。 将多个服务与GraphQL链接在一起并将这些检查挂钩到构建过程中,可以在部署问题代码之前捕获更多问题。 理想情况下,我们希望从数据库层一直到客户端浏览器具有类型安全性。

从数据库到后端到客户端代码的类型安全
DI / DX - 简化开发
创建客户端应用程序时常见的顾虑是UI / UX,但开发接口和开发体验对于构建可维护应用程序同样重要。 在GraphQL之前,编写一个新的React容器组件需要维护复杂的逻辑,以便通过网络请求我们需要的数据。 开发人员需要考虑一个数据如何与另一个数据相关,如何缓存数据,是否并行或按顺序进行调用以及Redux中存储数据的位置。 使用GraphQL查询包装器,每个React组件只需要描述它所需的数据,包装器会处理所有这些顾虑。 样板代码更少,更清晰地隔离数据和UI之间的顾虑。 这种声明性数据提取模型使React组件更容易理解,并用于部分记录组件正在执行的操作。
其他好处
我们也注意到了还有一些其他较小的好处。 首先,如果任何GraphQL的查询解析失败,则成功的解析仍会将数据返回到客户端,以尽可能多地呈现页面。 其次,后端数据模型大大简化,因为我们不太关心客户端的建模,并且在大多数情况下可以简单地为原始实体提供CRUD接口。 最后,测试我们的组件也变得更容易,因为GraphQL查询可以自动转换为我们测试打桩,我们可以独立于React组件测试解析器。
成长的烦恼
我们向GraphQL的迁移是一种简单的体验。 我们为构建网络请求和转换数据而构建的大多数基础架构都可以轻松地从我们的React应用程序转移到我们的NodeJS服务器,而无需更改任何代码。 我们甚至最终删除了比我们添加的更多的代码。 但是,与任何向新技术的迁移一样,我们需要克服一些障碍。
自私的解析器
由于GraphQL中的解析器旨在作为与其他解析器无关的独立单元运行,因此我们发现它们对相同或类似的数据进行了许多重复的网络请求。 我们通过将数据提供方封装在一个简单的缓存层中来解决这种重复问题,该缓存层将网络响应存储在内存中,直到所有解析器完成。 缓存层还允许我们将对单个服务的多个请求聚合成一次性所有数据的批量请求。 解析器现在可以请求他们需要的任何数据,而无需担心如何优化获取它的过程。
添加缓存以简化解析器的数据访问
我们编织的网络多么糟糕
抽象是提高开发人员效率的好方法......直到出现问题。 毫无疑问,我们的代码中存在错误,我们不希望用中间层来混淆根本原因。 GraphQL会自动编排对其他服务的网络调用,从而对隐藏用户的复杂性。 服务器日志提供了一种调试方法,但它们仍然只是从通过浏览器的网络选项卡自然调试方法中删除了一步。 为了使调试更容易,我们将日志直接添加到GraphQL响应有效负载,该负载提供了服务器正在进行的所有网络请求。 启用调试标志后,您将在客户端浏览器中获得与浏览器直接进行网络调用时相同的数据。
打破类型限制
传递对象是OOP的全部内容,但不幸的是,GraphQL颠覆了这种范式。 当我们获取部分对象时,此数据不能用于需要完整对象的方法和组件。 当然,您可以手动转换对象并希望获得最佳效果,但是您会失去类型系统的许多好处。 幸运的是,TypeScript使用“鸭子类型(duck typing)”,因此最快的修复是调整方法来只请求他们真正需要的对象属性。 定义这些更精确的类型需要更多的工作,但总体上提供更大的类型安全性。
接下来是什么
我们仍然处于探索GraphQL的早期阶段,但到目前为止它是一次积极的体验,我们很高兴接受了它。 这项努力的关键目标之一是帮助我们在系统日益复杂的同时提高开发速度。 我们希望投资图形数据模型,以便随着时间的推移,随着更多边缘和节点的增加,我们的团队将更加高效,而不是陷入复杂的数据结构。 即使在过去的几个月里,我们发现现有的图模型已经变得足够强大,我们不需要任何图形更改就可以构建一些功能。 它确实使我们更富有成效。
随着GraphQL继续蓬勃发展和成熟,我们期待从社区可以构建和解决的所有惊人事物中学习。 在实现层面,我们期待使用一些很酷的概念,如模式拼接,这可以使与其他服务的集成更加简单,并节省大量的开发人员时间。 最重要的是,看到我们公司的更多团队看到GraphQL的潜力并开始采用它是非常令人兴奋的。
相关阅读:
以上是关于我们在采用GraphQL中学到了什么?的主要内容,如果未能解决你的问题,请参考以下文章