为GraphQL Server自动生成DataLoader!
Posted 嘶吼专业版
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为GraphQL Server自动生成DataLoader!相关的知识,希望对你有一定的参考价值。
dataloader-codegen是一个经过验证的javascript库,用于通过一组资源(例如HTTP端点)自动生成DataLoader,你可以在GitHub上下载!

大规模管理GraphQL DataLoader
本文的示例以Yelp为讲解样本来进行讲解,Yelp使用GraphQL为React Webapp提供数据。 GraphQL服务器被部署为一个公共网关,它封装了分布在数百个服务中的数百个内部HTTP端点。
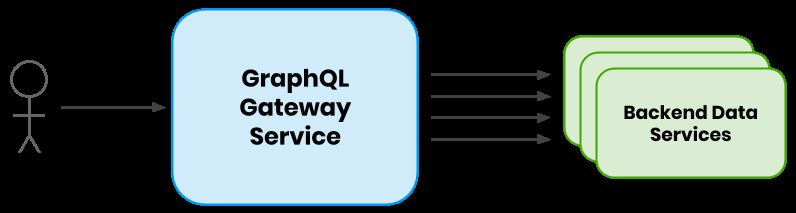
GraphQL请求图
DataLoader
目前,DataLoader在许多GraphQL服务器中提供了重要的缓存/优化层。如果你还不熟悉这种模式,请查看Marc-André Giroux 撰写的文章,其中详细介绍了该模式。
简单来说,Data Loader是一个简单但功能强大的工具,能够在许多常见数据库格式之间导出和导入数据。如果你希望将MS SQL Server,CSV或MS Access转换为mysql,这可以有效满足你特定需求。最新的Data Loader版本支持MySQL,Oracle,MS Access,Excel,FoxPro,DBF,MS SQL Server,CSV和分隔或平面文件。现在,你可以使用此工具轻松将Oracle转换为MySQL或MS SQL Server,且该工具具有多项独特的高级功能。
如果不使用DataLoader会发生什么情况
如果没有DataLoader,Yelpy GraphQL请求可能会执行以下操作:
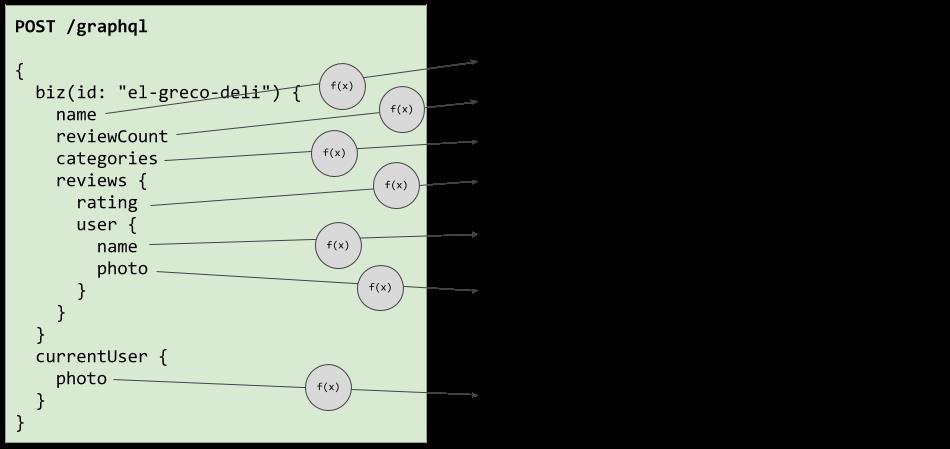
没有DataLoader的解析器逻辑
如上所示,我们可以看到解析器方法简单地发出一个独立的上游请求以获取其数据。
如果没有DataLoader提供的批处理和缓存功能,我们可以想象陷入一种棘手的情况,即我们发出过多的请求而自己却意外地进行了DoS。
使用DataLoader会发生什么情况
让我们用DataLoaders封装这些HTTP端:
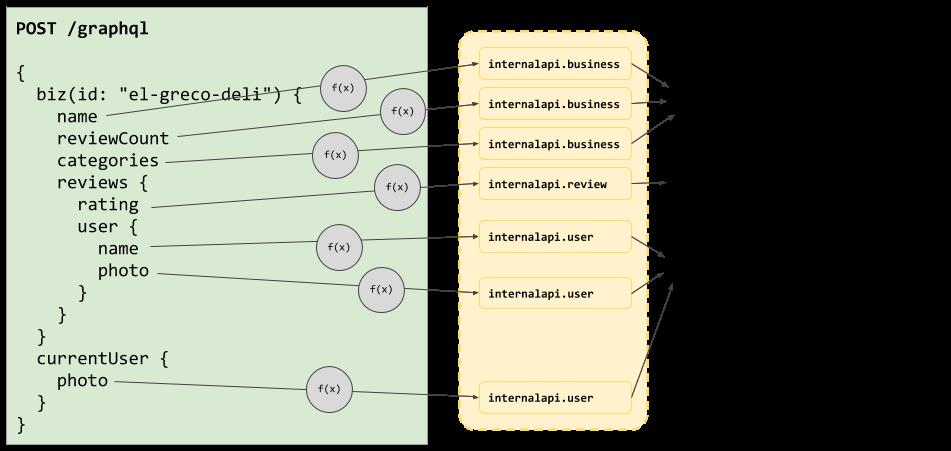
使用DataLoader的解析器逻辑
在这个运行环境中,解析器会与DataLoaders对话,而不是直接发出网络请求。此时,内置的批处理和缓存逻辑使我们可以大大减少正在进行的内部API调用的次数!
这种方法与叶子节点解析器进行自己的数据获取调用的模式非常匹配,详细信息请点此。
扩大规模
一般来说,这种模式效果很好。不过当我们超出封装的端点范围时,可能会在管理DataLoader层时遇到一些挑战:
1. 我从哪里获得数据?
2. DataLoader接口是什么样子的?如何保持类型安全?
3. 如何为该端点实现DataLoader?
从哪里获得数据?
端点提供的数据很好理解,所有资源均由swagger规范定义,这允许开发人员浏览所有可用的端点及其公开的数据。Swagger 是最流行的 API 开发工具,它遵循 OpenAPI Specification(OpenAPI 规范,也简称 OAS)。 Swagger 可以贯穿于整个 API 生态,如 API 的设计、编写 API 文档、测试和部署。 Swagger 是一种通用的,和编程语言无关的 API 描述规范。
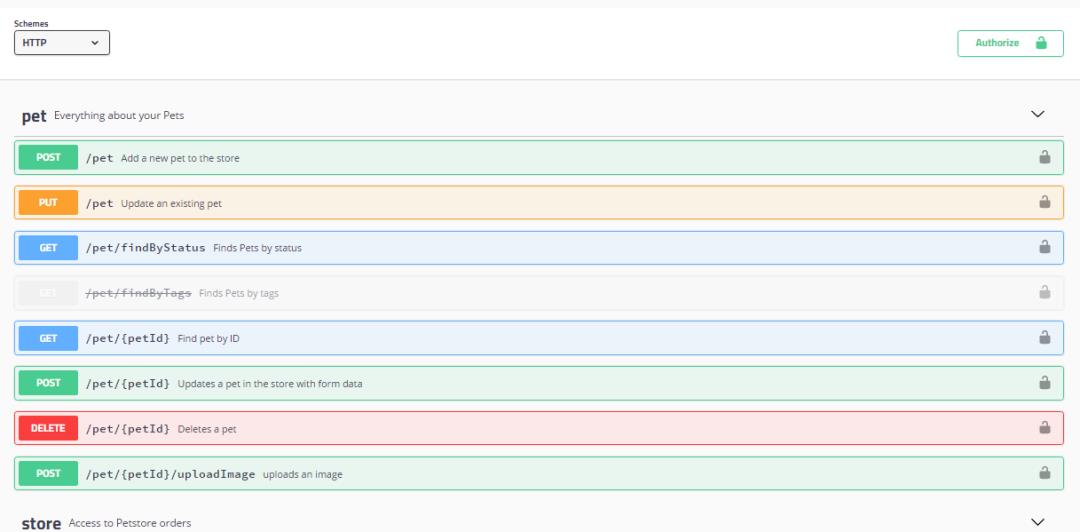
使用Swagger UI浏览API端点
在实现解析器方法时,这使你很容易知道从何处获取数据,只需调用相应的生成方法即可。
端点和DataLoader的比较
添加DataLoader会引入一个间接层,如果我们要手动定义DataLoader并要求开发人员调用它们,他们将如何知道要调用哪个DataLoader?
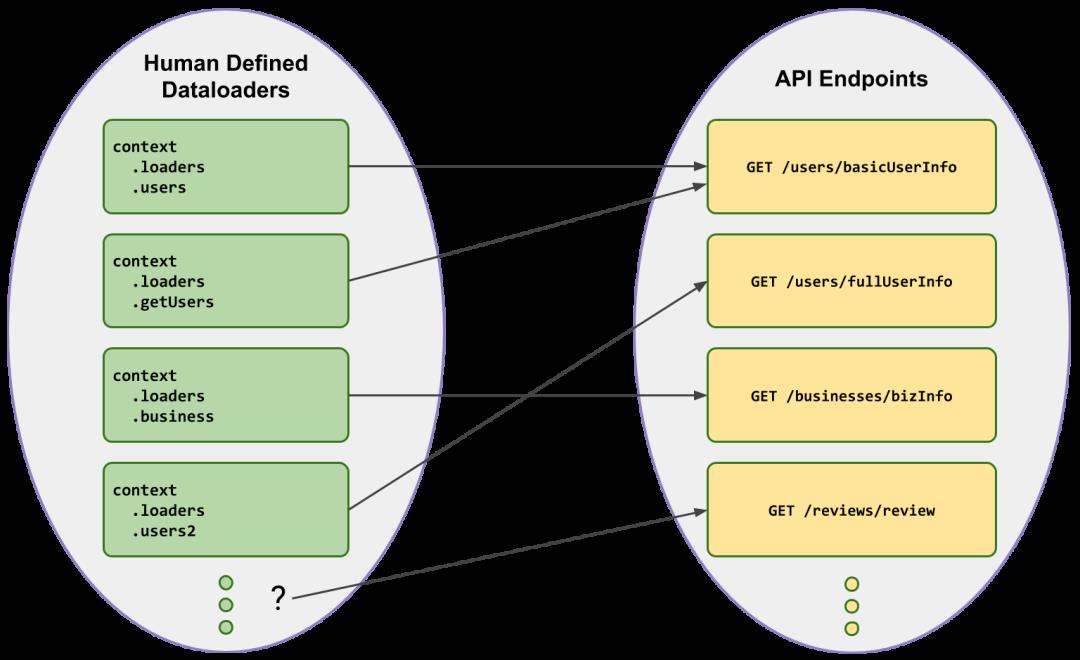
人工定义的DataLoader
创建一个像用户这样的好名字的DataLoader可能很诱人,但是可以封装我们提供用户信息的端点是哪一个?另外,我们是否最终会意外地将相同的端点封装两次,这会损失某些批处理功能。
所以,依赖于DataLoader的人为定义的结构,该结构不同于现有的端点集,这会带来风险,并有可能丢失批处理行为。
我们可以通过断言dataloader的形状是到我们资源的1:1映射来解决这个问题:
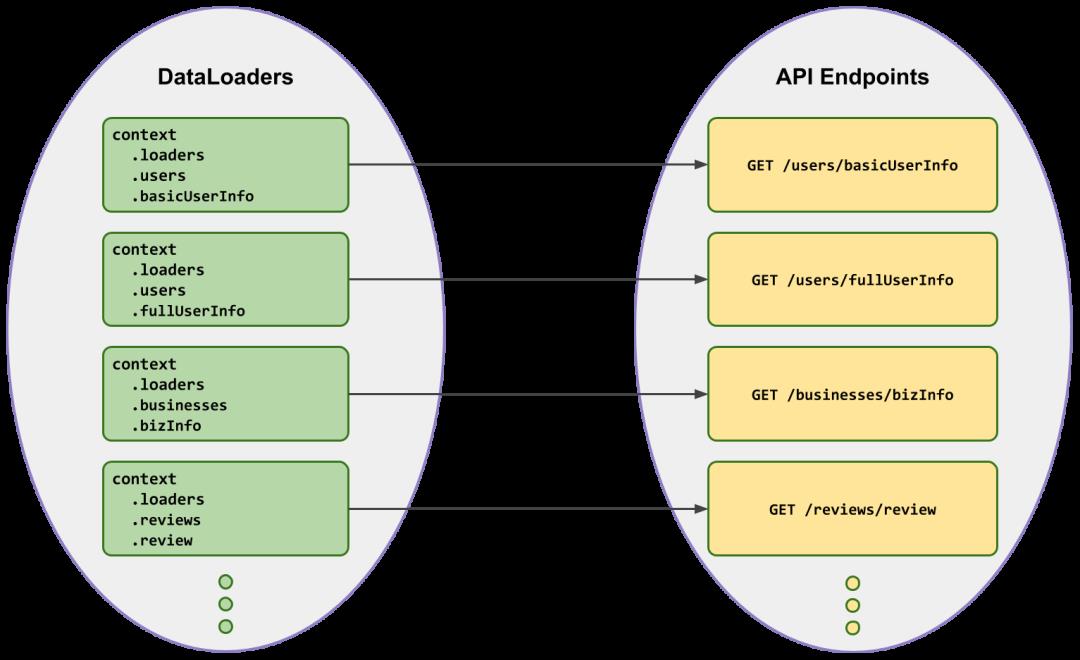
具有1:1映射到资源的DataLoader
通过确定DataLoader对象的形状(和方法名称)与底层资源进行1:1映射,可以在确定要使用哪个DataLoader时使事情变得可预测。
在此,我们建议开发人员从已经熟悉的,有据可查的底层资源出发,而不是从DataLoader进行思考。
DataLoader接口是什么样的?如何保持类型安全?
资源具有各种形状和大小,有些端点使用批处理接口,有些端点不保证排序,有些端点的响应对象是嵌套的,需要解封……
因此弄清楚DataLoader的参数/返回类型并正确转换接口,是DataLoader开发者面临的另一个有趣的挑战。
例如,考虑以下返回用户列表的批处理资源:
getBasicUserInfo({
user_ids: Array,
locale: string,
include_slow_fields: ?boolean}) => Promise
在我们的解析器中,只需要一次抓取一个用户对象,我们应该能够从相应的DataLoader请求单个用户对象。
这意味着我们需要通过以下方式映射DataLoader的接口:
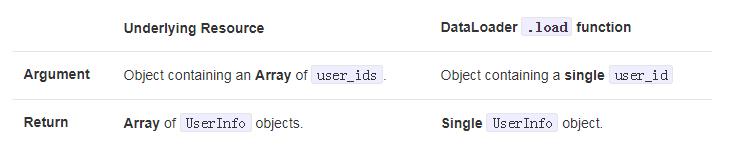
通过这种方法,用于调用资源的DataLoader版本的接口如下所示:
getBasicUserInfo.load({
user_id: number,
locale: string,
include_slow_fields: ?boolean,}) => Promise
一致且正确地实现接口转换逻辑是很困难的,细微的、意想不到的差异会给开发人员带来很大麻烦。
记住类型
如果服务器代码库使用静态类型TypeScript或者在Yelp的示例中使用Flow,我们还必须为DataLoader定义类型签名。在上述示例中,它看起来如下所示:
DataLoader<
{|
user_id: number,
locale: string,
include_slow_fields: ?boolean,
|},
UserInfo,>
转换类型以匹配实现逻辑并使它们保持同步,这会为DataLoader开发者带来了另一个问题。
如何为该端点实现DataLoader?
在许多端点上编写DataLoader会导致许多命令式样板代码,这些代码需要了解如何实现端点。
这是通过上面的getBasicUserInfo端点为DataLoader实施的内容,如下所示:
new DataLoader(keys => {
let results;
try {
results = userApi.getBasicUserInfo({
user_ids: keys,
include_slow_fields: false,
locale: 'en_US',
});
} catch (err) {
return Promise.reject(err);
}
// Call a bunch of helper methods to tidy up the response
results = reorderResultsByKey(results, 'id');
results = ...
return results;}
可以看出我们完全在在作弊!此处的keys参数直接表示user_id的列表,而不是资源的参数对象的列表。为了简化实现DataLoader的过程,我们可能会做出这样的决定。
除了调用底层资源,我们可能还需要处理:
1. 错误处理;
2. 从keys中找出资源的参数;
3. 正在规范化的响应形状;
4. 任何其他额外的逻辑,例如,请求日志记录。
当对不同的端点复制和粘贴数百次时,这可能会变得非常乏味。而且,由于每个端点的实现可能略有不同,因此每个DataLoader的实现也可能会有所不同。
由于不能保证DataLoader接口是可预测的,因此开发人员必须了解DataLoader是如何实现的,以及它与底层资源有何不同才能使用它。
处理多个参数
现在考虑使用上面的getBasicUserInfo DataLoader ,里面是不包括include_slow_fields的,而仅使用user_ids作为密钥。
如果要提供底层资源的全部灵活性,则需要更改getBasicUserInfo DataLoader以使用上面建议的签名:
DataLoader<
{|
user_id: number,
locale: string,
include_slow_fields: ?boolean,
|},
UserInfo,>
在我们的批处理函数内部,keys现在变成了一个对象列表,看起来像这样:
[
{ user_id: 3, include_slow_fields: false, locale: 'en_US' },
{ user_id: 4, include_slow_fields: true, locale: 'en_US' },
{ user_id: 5, include_slow_fields: false, locale: 'en_US' },]
我们需要合并这些对象,以便可以批量调用userApi.getBasicUserInfo,编写看起来像这样的逻辑可能很诱人:
userApi.getBasicUserInfo({
user_ids: keys.map(k => k.user_id),
include_slow_fields: ???,
locale: ???,})
如何设置include_slow_fields或locale?
我们不能天真地假设keys [0] .include_slow_fields的值,因为这是不安全的,对.load的第二次调用没有请求“slow_fields”,但是会接收到它,从而降低了整个请求的速度,这是非常糟糕的!
在本文的示例中,我们必须对userApi.getBasicUserInfo进行两次调用,并相应地对请求进行分块:
userApi.getBasicUserInfo({ user_ids: [3, 5], include_slow_fields: false, locale: 'en_US' });
userApi.getBasicUserInfo({ user_ids: [4], include_slow_fields: true, locale: 'en_US' });
Load DataLoader的开发者在合并keys输入时必须小心,以确保.load响应的正确性。
总结
我们可能希望在GraphQL中调用数百个内部HTTP API端点,事实证明,手动编写DataLoader层是一个很复杂的问题,原因如下:
1. 实现DataLoader批处理函数逻辑需要了解底层资源,并且很难正确实现。
2. 无法保证DataLoader / loader的名称的形状完全映射到端点,因此很难找到它们。
3. 由于(2)的原因,我们冒着为相同端点复制DataLoader 的风险;
4. DataLoader的输入/返回类型是手动输入的,需要额外的功能和自定义类型;
5. DataLoader的接口与它封装的端点是分离的,并且可以不同。
6. 如果端点向上更改,则必须手动更新DataLoader实现。
鉴于端点的实现方式存在一定的差异,因此看起来这可能是代码生成的工作……
dataloader-codegen
dataloader-codegen是我们用来自动生成GraphQL Server中使用的DataLoader的工具。该工具目前已公开发布。你可以在GitHub上查看项目:https://github.com/Yelp/dataloader-codegen。

https://github.com/Yelp/dataloader-codegen
它通过传递一个描述一组资源的配置文件来工作,如下所示:
resources:
getUserInfo:
docsLink: https://yelpcorp.com/swagger-ui/getUserInfo
isBatchResource: true
batchKey: user_ids
newKey: user_id
getBusinessInfo
docsLink: https://yelpcorp.com/swagger-ui/businessInfo
isBatchResource: false
...
这样,我们可以在构建时生成我们的DataLoader:

通过让工具完成编写DataLoader的工作,我们可以解决上述问题。特别是,dataloader-codegen为我们提供了以下功能:
1. 生成的DataLoader实现;
2. 预测DataLoader接口;
3. 1:1映射到DataLoader的资源;
4. DataLoader的类型安全性可以被保留下来。
以下就是一个传递生成DataLoader的无效属性的流程:
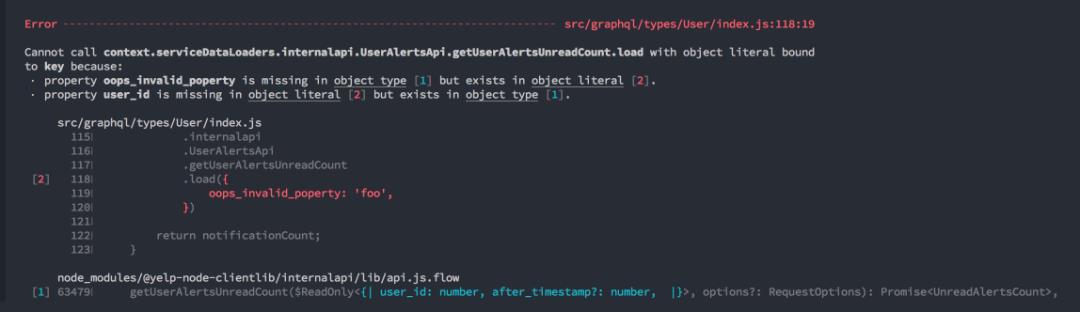
总体而言,dataloader-codegen使我们能够删除服务器中的许多样板代码,节省时间,并减少处理DataLoader的麻烦。
有关dataloader-codgen的工作方式以及如何在项目中使用它的更多信息,请在GitHub上查看。
参考及来源:https://engineeringblog.yelp.com/2020/04/open-sourcing-dataloader-codegen.html
以上是关于为GraphQL Server自动生成DataLoader!的主要内容,如果未能解决你的问题,请参考以下文章
Apollo Server:Eject 内置“上传”类型以使用 graphql-codegen 生成 TS 类型
在 apollo-server 中将网关上的联合类型转换为服务 GraphQL 中的标量类型
是否可以为 Apollo Server 附带的 GraphQL Playground 定义 HTTP 标头?
Prisma v2:生成一个 .graphql 文件来编辑?