一文快速入门 Graphql
Posted 前端小加加
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文快速入门 Graphql相关的知识,希望对你有一定的参考价值。
一张脑图总结全文:
GraphQL 与 RESTful API
GraphQL 是由 Facebook 开发并开源的。提到 GraphQL ,大家自然而然会提起 RESTful api。下面对比一下 RESTful api 和 GraphQL 的优缺点。
优点:
-
声明式的接口获取 RESTful api 返回的字段冗余, 当多个终端共用接口时,尤其明显。GraphQL 可精准的返回所需的数据结果,减少数据传输大小。
-
嵌套复杂数据仅需一次调用 RESTful 对于嵌套的复杂数据需要多次调用,而 GraphQL 只需要一次。
-
愉快地前后端联调效率 REST 每次新加字段,需频繁沟通,且需借助 swagger 生成接口文档, GraphQL 自动生成标准文档。
如果上面的优点看不懂,没关系,我们来举一个栗子,加速理解:
服务端 getUser 接口返回了 id, name 信息, 但是另外一个场景,需要额外多返回几个字段, 比如 email, adress 等。此时服务端要怎么做?有以下三种做法:
-
新开一个接口, 返回所需要的所有字段 -
请求增加一个 type ,用于区分场景,服务端根据不同 type 返回不同的字段 -
不管三七二十一, 在原有接口上增加多的字段。
如果只是 1 个,2 个场景还好,但如果后期有 n 个场景,需要返回非常多的字段,这不仅会浪费带宽,客户端数据解析也会影响响应时间,从而影响用户体验。那让后台新增一个接口可以吗?当然可以,可是这样后台需要额外维护这种“业务逻辑”。
操作类型( Operation type )
-
查询( query ) -
更新( mutation ) -
订阅( subscription )
GraphQL 实战
我一直提倡,刚开始学习一门新的技术,别看太多文档,先用它的 api, 快速做一个 demo ,跑起来之后。再开始系统学习,这样效率是最高的。所以,下面我们会实战来做一个 GraphQL .
跟着官方文档[1]简单快速创建一个栗子。
初始化项目
mkdir graphql-server-example
cd graphql-server-example
npm init --yes
npm install apollo-server graphql
touch index.js
定义 GraphQL schema
打开 index.js ,将以下代码复制粘贴进去。
const { ApolloServer, gql } = require('apollo-server');
const typeDefs = gql`
type Book {
title: String
author: String
}
type Query {
books: [Book]
}
`;
定义 resolver
我们在上面的 index.js 文件后面,继续复制粘贴
const resolvers = {
Query: {
books: () => books,
},
};
// 一般会在 resolvers 中连接数据库获取数据,但是为了简单,我们直接返回定义好的数据
const books = [
{
title: 'Harry Potter and the Chamber of Secrets',
author: 'J.K. Rowling',
},
{
title: 'Jurassic Park',
author: 'Michael Crichton',
},
];
创建一个 ApolloServer 实例
我们在上面的 index.js 文件后面,继续复制粘贴
const server = new ApolloServer({ typeDefs, resolvers });
// 启动服务
server.listen().then(() => {});
在命令行中运行 index.js
node index.js
好了, 就是这么简单,一个 graphql 就写好了。实际中的项目可能使用 egg 或者 koa 或者 express。本质的思想是一样的, 都是先定义 GraphQL schema ,再定义 resolver ,resolver 这里从不同地方取数,再之后就是传递 schema 和 resolver,创建实例。
工具 GraphiQL
上面的代码运行起来了,要去哪里调用?如果是用 RESTful api ,我们会用 postman 来测试接口是否可以跑通。同样的,GraphQL 可以用 GraphiQL 来测试。
-
按需取用: 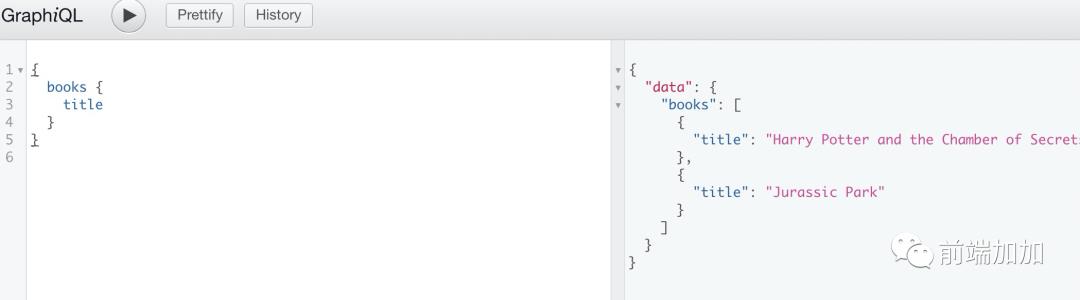
-
除了可以用来测试接口之后,它还是一个文档工具,使用 GraphiQL 可以很容易地让人感受到“代码即文档”的快乐。
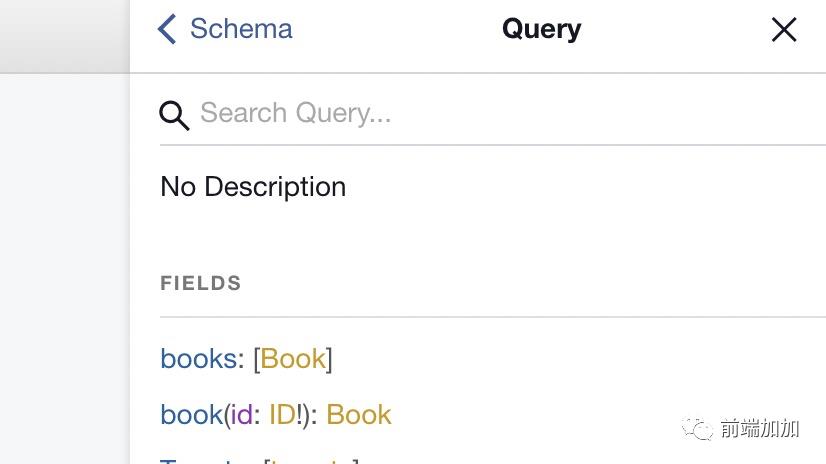
-
你可以在这里查看测试的历史
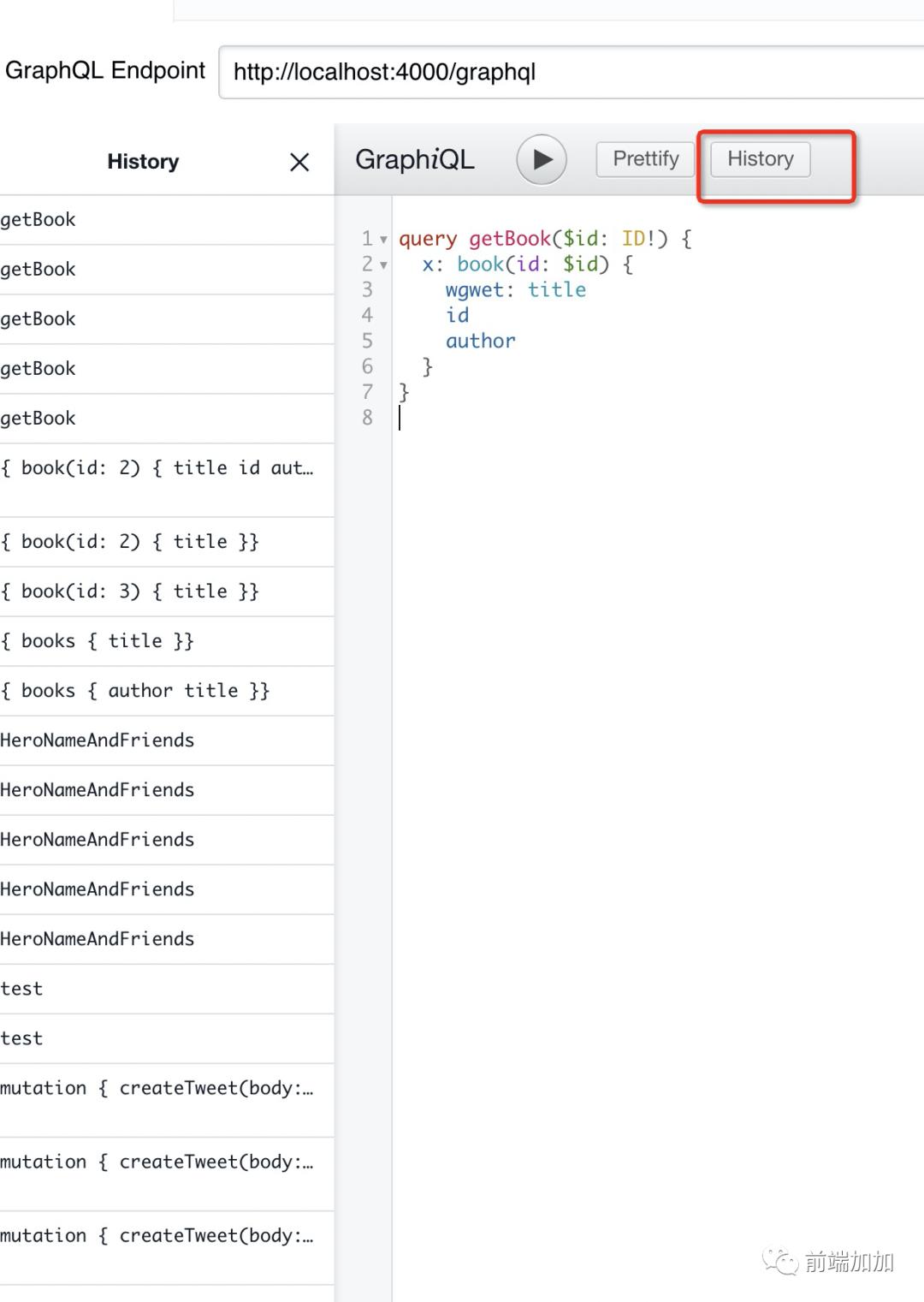
Schemas
从上面的例子看出,要先定义 Schemas, 那我们就来学习下 Schemas。如果你使用过 Typescript ,会发现它的类型跟 Typescript 特别的类似。
基本类型
Int, Float, String, Boolean, ID(唯一标识符)
其他类型
-
enum, Date, interface -
!(不可为 null) 可通过 Union types 或 implements 扩展上面的类型。
2 个特殊类型
查询(query)和变更类型(mutation)
自定义类型
查看官方文档[2]
Resolver
我们可以简单地理解成,针对我们暴露的接口,调用相应的方法去取数返回。resolver 的解析规则是, 从外到内依次处理查询块,为每一个查询块执行对应的 resolver 函数,并传递外层调用返回的结果作为第一个参数,也就是下面代码中的 obj 。
resolver 函数它接收 4 个参数
fieldName(obj, args, context, info) {
result
}
// obj:解析程序在父字段上返回的结果的对象
// args:查询中传入的参数
// context:这是特定查询中所有解析程序共享的对象,用于包含每个请求的状态,包括身份验证信息,数据加载器实例以及解析该查询时应考虑的任何其他内容
// info:此参数仅在高级情况下使用,但它包含有关查询执行状态的信息,包括字段名称,从根到字段的路径等。 它仅记录在GraphQL.js源代码中。
同样的,我们直接来看一个例子:在 index.js 中修改对应的 Schemas 和 Resolver
const books = [
{
title: "Harry Potter and the Chamber of Secrets",
author: "J.K. Rowling",
id: 1,
},
{
title: "Jurassic Park",
author: "Michael Crichton",
id: 2,
},
];
const typeDefs = gql`
type Book {
title: String
author: String
id: ID
}
type Query {
books: [Book]
book(id: ID!): Book
}
`;
const resolvers = {
Query: {
books: () => books,
book: (_, { id }) => books.find((book) => book.id == id),
},
};
由于这个 resolver 函数第一个参数是传递外层调用的返回结果,这里我们没有嵌套 resolver ,所以我们直接用第二个参数 id 获取前端传入的参数。
更多内容查看 resolver 文档[3]
然后我们在 http://127.0.0.1:4000/graphql 或者在客户端 GraphiQL 中测试

已经成功找到对应 id 的数据了,但是这里的 id 是写死的,我们说 graphql 最大的好处是声明式获取,那如何把 id 变成一个变量,让外部传入?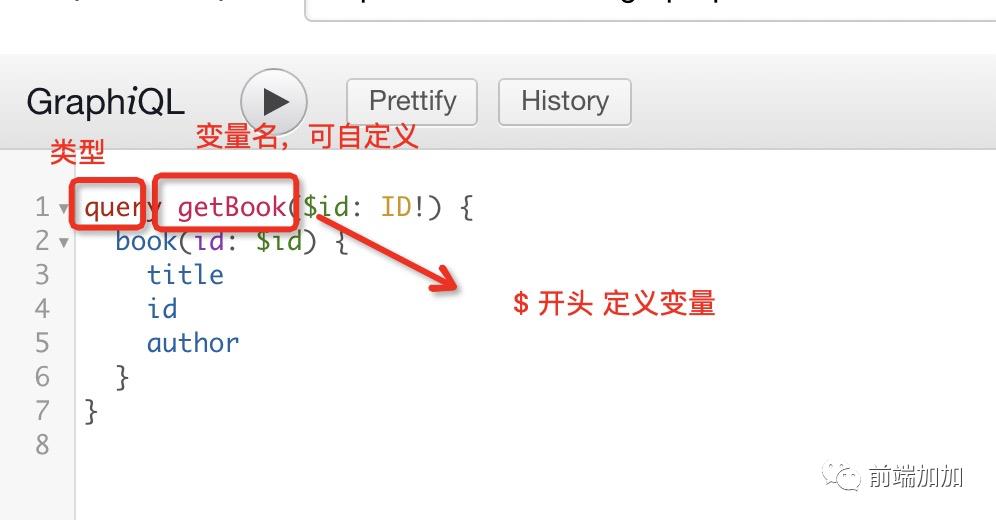
query getBook($id: ID!) {
book(id: $id) {
title
id
author
}
}
给返回的值设置别名
query getBook($id: ID!) {
testname: book(id: $id) {
nickname: title
id
author
}
}
好了,接口正常返回。
更多查询变更可看官方文档[4]
进阶
在实际项目中,我们会将数据库 ,dataloaders 注入到 context 中,方便所有 resolver 调用。
Dataloader
Dataloader 是 facebook 搞的一个 js 库,可以大幅降低数据库的访问频次,从而降低系统负载,经常在 Graphql 场景中使用。通过使用 dataloader,数据库的访问频次可以指数级别下降。
dataloader 是如何工作的呢,可以看下图:
对于 User 表的多次访问,通过 dataloader 去取,会自动合并为一个请求。dataloader 之所以可以实现这样的能力,是因为他把每一次数据请求,都推迟到 node 的 Next Tick 后集中批处理运行,这样就可以对请求进行加工合并。
关注「前端加加」,回复 graphql demo 即可获取完整代码
参考资料
官方文档: https://www.apollographql.com/docs/apollo-server/getting-started/
[2]官方文档: https://graphql.org/learn/schema/
[3]resolver 文档: https://www.graphql-tools.com/docs/resolvers
[4]官方文档: https://graphql.cn/learn/queries/?spm=ata.13261165.0.0.5e996a21sHCP3T
以上是关于一文快速入门 Graphql的主要内容,如果未能解决你的问题,请参考以下文章