ELK日志系统扫盲
Posted 云吞信息
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK日志系统扫盲相关的知识,希望对你有一定的参考价值。
ELK简介
ELK是当下流行的一整套解决方案,其架构由三个组件构成:
Elasticsearch,负责数据的索引和存储
Logstash,负责日志的采集和格式化
Kibana,负责前端统计的展示
值得关注是Logstash,Elasticsearch的使用,Kibana主要是数据的展示,如果打算自己做数据分析或展示,这个组件可能不需要太深入。
架构介绍
这套日志处理方案的最大优势在于简单明了,部署和配置都极为方便。 大致的架构如下:
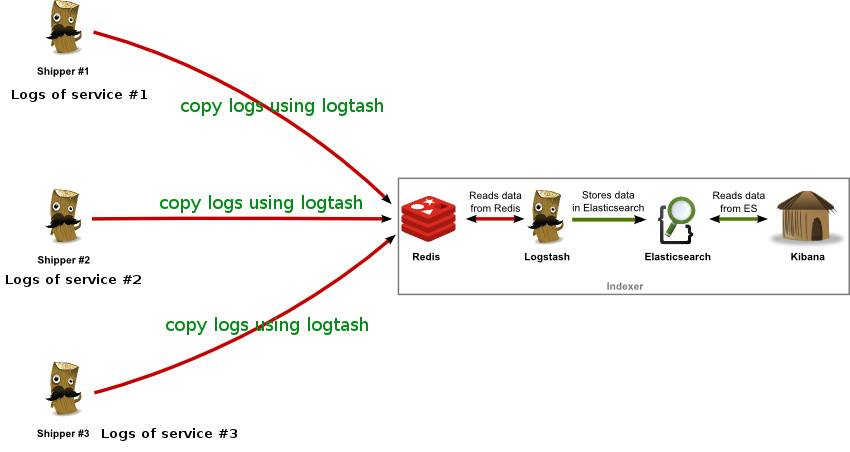
logstash的角色分别为两种,一种是shipper,负责日志的采集和格式化并将日志传送到redis中,部署在日志采集端。另外一种是indexer,负责从redis队列中将日志提取存入ElasticSearch中。主要特点:
1. 几乎可以访问任何数据
2. 可以和多种外部应用结合
3. 支持弹性扩展
redis提供队列来作为broker负责log传输过程中的缓冲,也可以由kafka等来代替,或者省略。
Elasticsearch是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析。它是一个建立在全文搜索引擎Apache Lucene基础上的搜索引擎,使用Java语言编写。主要特点如下:
1. 实时分析
2. 分布式实时文件存储,并将每一个字段都编入索引
3. 文档导向,所有的对象全部是文档
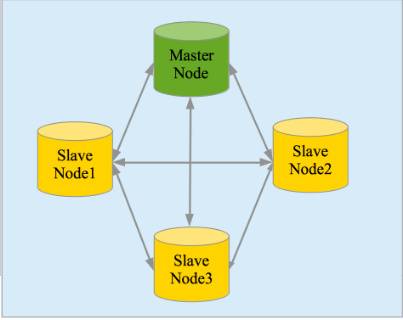
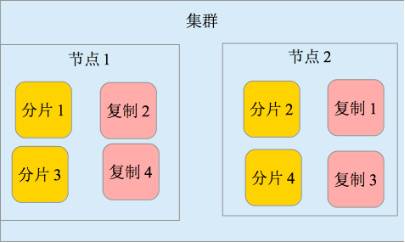
4. 高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)
5. 接口友好,支持JSON
Kibana是一款基于Apache开源协议,使用javascript语言编写,为Elasticsearch提供分析和可视化的Web 平台。它可以在Elasticsearch的索引中查找,交互数据,并生成各种维度的表图。
安装部署
操作系统:RHEL6.5
硬件配置:2C4G
软件环境:jdk_1.8.0
ELK版本:logstash-2.3.2+elasticsearch-2.3.2+kibana-4.5.0
安装文件可以从elastic官方网站下载,3个组件各自都有zip、tar、deb和rpm格式的安装包。因为我们的系统是RHEL,所以我们下载rpm格式的安装包来进行安装。
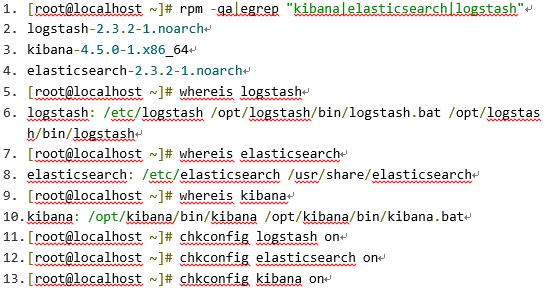
配置elasticsearch
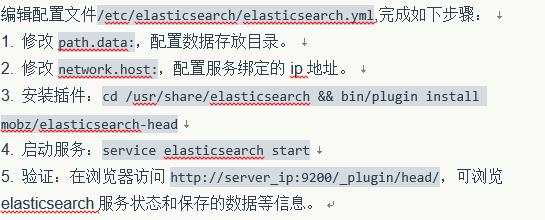
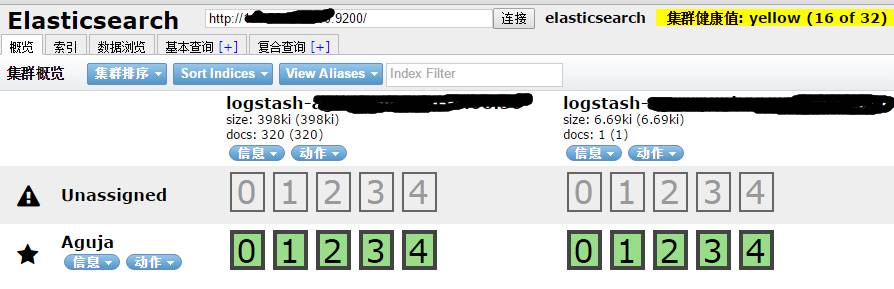
本例是单台elasticsearch,数据的副本分片确实,所以集群健康值是黄色。如果做成集群后,健康值为绿色,表示所有主分片和副本分片都正确运行。
2. 配置kibana
如果kibana和elasticsearch部署在同一台机器,那么直接启动kibana即可:service kibana start
3. 配置logstash
logstash配置文件是以json格式设置参数的,配置文件位于/etc/logstash/conf.d目录下,配置包括三个部分:输入端,过滤器和输出。
本例使用系统日志/var/log/message作为示例,来验证elk架构是否正常工作。
定义了结构化日志存储到elasticsearch和logstash的标准输入文 件/var/log/logstash/logstash.stdout,对于不匹配grok的日志写入到文件。
输出到标准输出,可以方便排错,正式运行时可将stdout段注释。
注意,后面添加的过滤器文件名要位于01-99之间。因为logstash运行时,会将零散的配置文件有顺序的组织起来作为运行时的配置。
在启动logstash服务之前,最好先进行配置文件检测,如下:
1. [root@localhost ~]# /opt/logstash/bin/logstash --configtest -f /etc/logstash/conf.d/*
2. Configuration OK
也可指定文件名检测,直到OK才行。不然,logstash服务器起不起来。
最后,就是启动logstash服务了。
ELK实践小目标
rsyslog
filebeat
Tile Map
Kibana使用高德地图
You'll never walk alone
欢迎小伙伴们右下角积极留言☺
以上是关于ELK日志系统扫盲的主要内容,如果未能解决你的问题,请参考以下文章