ELK日志系统架构杂谈
Posted Coding匠人心2
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK日志系统架构杂谈相关的知识,希望对你有一定的参考价值。
1引言
最近时间还算充裕,整理一下18年下半年的一些资料,也是在工作中遇到,并构建的。博主也是凑合着写写,网上的教程也比较多,希望这篇对你有帮助。
因从事的算是带有金融属性的,对于各种统计和错误即为敏感,每天产生的各类日志都要好几十种,每天需要处理约三千万条日志,需要对其进行统计实时化,热数据存储30天左右。
2日志系统的必要性?
18下半年那会刚入职那会,定位生产问题,就是连上机器看日志,金融属性小项目不怕大家笑话,有没有经历过我这种操作的童鞋?
如果是一两台机器还好,要是十几台甚至上千台机器的集群?怕不是问题没解决,人先GG了。
为了解决上述的问题,临危受命,主张改进了当时的日志集中化管理。提高了查错和相关统计的效率。
我认为,日志数据在以下方面非常重要
1、数据查找
2、服务诊断,了解服务当前的运行状态
3、数据分析,需要在日志做实施统计,计算出各种符合要求的数据并进行实时可视化
啰嗦了这么一大堆,下面开始正式说吧。
3组件介绍:ELK Stack

Logstash : 数据收集处理引擎。支持动态的从各种数据源收集数据,并对数据进行过滤、分析、丰富、统一格式等待操作,然后存储以供后续使用
Kibana:可视化平台。能够进行搜索、展示存储在Elasticsearch中的数据,并能很轻松的进行可视化分析展示。
Elasticsearch:分布式搜索引擎。具有高可伸缩、高可用、易管理等特点。可用于全文检索、结构化检索和分析,性能将这三者结合起来。
Filebeat:轻量级的数据收集引擎,基于原先的Logstash-fowarder的源码改造的。
当然其中的APM探针集成,也是我选择ELK的一个点亮点,对于小架构的项目还是十分友好。
4玩玩版
这一版本各位开发大佬在自己的服务器上搭建练练手就可以,当时我就是使用的Vultr的机器来进行搭建考察是否满足需求。
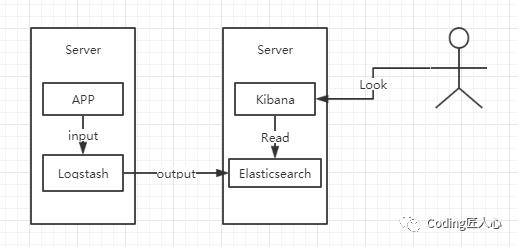
这种架构下面我们把Logstash实例与Elasticsearch实例相连接,主要是为了自己学习快速搭建。
我们将服务产生的日志还是照常的写入LOG文件,然后Logstash将Log读出,进行格式化过滤等操作传递给ES,最后用户访问Kibana。
但是有几个比较明显的缺点
Logstash在生产机器上面部署的话,Logstash采用JVM,这样会占用相当大的内存和CPU消耗,这样在生产机器上面是非常致命。并且如果是做一个日志切分格式化等操作的时候,占用资源会变得相当高。
其次在大并发情况下面,日志传输峰值比较大,如果是直接写入ES,api处理能力有限,在日志写入频繁的情况下可能会造成超时甚至丢失,所以需要一个缓冲中间件。
5初级版本
在这版本中,加入一个缓冲中间件,并且对Logstash进行拆分,使用filebeat。
fileabeat进行日志收集,Lostash进行格式化过滤缓冲日志,输出到Elasticsearch。
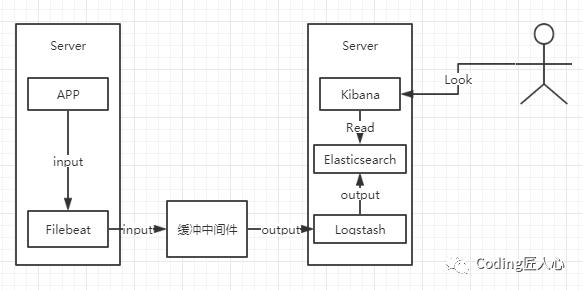
至于这个地方缓冲中间件的选择,推荐Kafka。至于为什么。网上各路大神也有相关的讲解。
缺点在于部署成集群的话,一个业务系统出现问题,将会拖垮整个日志系统。
6集群版本
这版本,采用filebeat来进行收集,上一版本中没有怎么介绍filebeat。filebeat 是采用golang写的,相比Logstash,来说更加轻量,所需要的资源占用也是相当少的。当然也是作者根据logstash重写的轻量级软件。
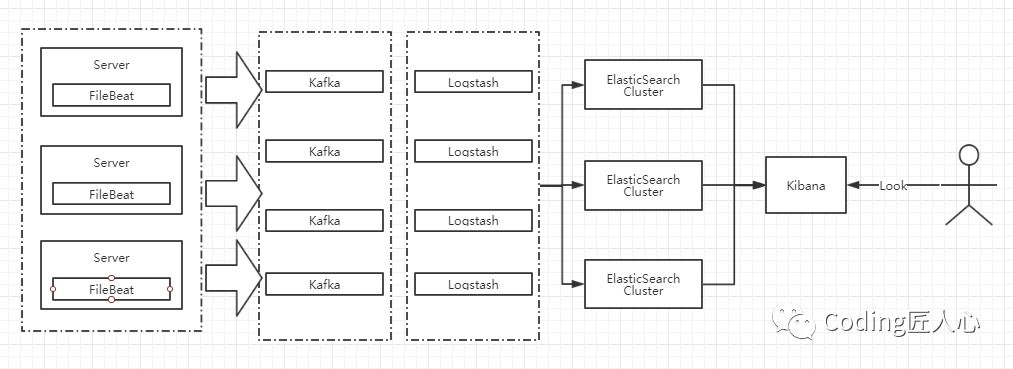
缺点在于没有进行数据的冷热分离,对一些敏感数据没有屏蔽等等等~其他问题。还有其他的一些解决方案这个就不进行讨论了。
7总结
基于ELK Stack 的日志解决问题的优势主要体现于:
可扩展性:采用高可扩展的分布式系统架构设计,可以支持每日TB级别的新增数据
使用简单:通过用户图形界面实现各种统计分析功能,简单
快速响应:从日志产生到查询可见,能做到秒级完成采集处理
界面炫酷:这种优势必须的说一下,傻瓜式操作。仪表盘6666666
最后加一些较早之前学习关于Spark的相关图。
作图软件: https://www.processon.com
后面有时间的话,给大家详解写一下ELK简单版本的搭建流程。
欢迎指正文中错误。跪谢。
以上是关于ELK日志系统架构杂谈的主要内容,如果未能解决你的问题,请参考以下文章
Linux ELK日志分析系统 | logstash日志收集 | elasticsearch 搜索引擎 | kibana 可视化平台 | 架构搭建 | 超详细