一文看懂 K8s 日志系统设计和实践
Posted 阿里巴巴云原生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文看懂 K8s 日志系统设计和实践相关的知识,希望对你有一定的参考价值。
导读:上一篇文章中我们介绍了为什么需要一个日志系统、为什么云原生下的日志系统如此重要以及云原生背景下日志系统的建设难点,相信 DevOps、SRE、运维等同学看了之后深有体会。本篇文章单刀直入,会直接跟大家分享一下如何在云原生的场景下搭建一个灵活、功能强大、可靠、可扩容的日志系统。

需求驱动架构设计
需求分解与功能设计
支持各种日志格式、数据源的采集,包括非 K8s;
能够快速的查找/定位问题日志;
能够将各种格式的半结构化/非结构化日志格式化,并支持快速的统计分析、可视化;
支持通过日志进行实时计算并获得一些业务指标,并支持基于业务指标实时的告警(其实本质就是 APM);
支持对于超大规模的日志进行各种维度的关联分析,可接受一定时间的延迟;
能够便捷的对接各种外部系统或支持自定义的获取数据,例如对接第三方审计系统;
能够基于日志以及相关的时序信息,实现智能的告警、预测、根因分析等,并能够支持自定义的离线训练方式以获得更好的效果。
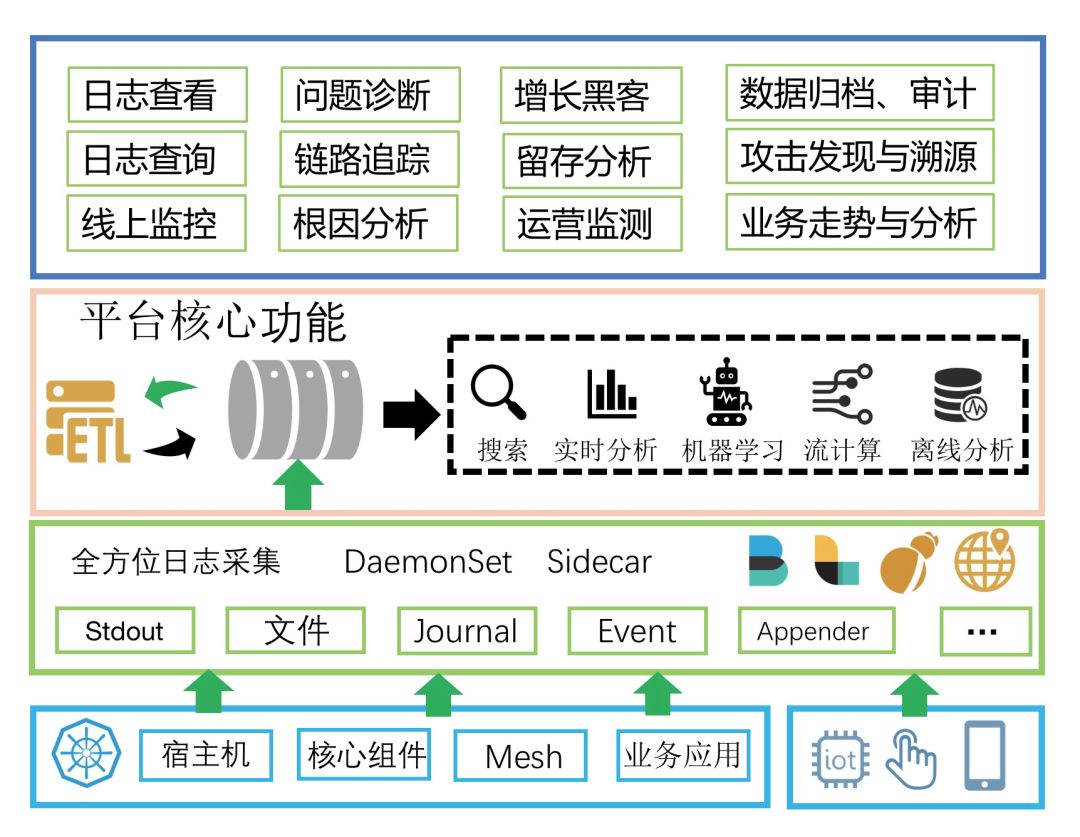
全方位日志采集。支持 DaemonSet、Sidecar 各种采集方式以应对不同的采集需求,同时支持 Web、移动端、IoT 及物理机/虚拟机各种数据源的采集;
日志实时通道。这个是为了对接上下游所必备的功能,保证日志能够被多种系统便捷地使用;
数据清洗(ETL: Extract,Transform,Load)。对各种格式的日志进行清洗,支持过滤、富化、转换、补漏、分裂、聚合等;
日志展现与搜索。这是所有日志平台必须具备的功能,能够根据关键词快速地定位到日志并查看日志上下文,看似简单的功能却最难做好;
实时分析。搜索只能完成一些定位到问题,而分析统计功能可以帮助快速分析问题的根因,同时可以用于快速的计算一些业务指标;
流计算。通常我们都会使用流计算框架(Flink、Storm、Spark Stream 等)来计算一些实时的指标或对数据进行一些自定义的清洗等;
离线分析。运营、安全相关的需求都需要对大量的历史日志进行各种维度的关联计算,目前只有 T+1 的离线分析引擎能够完成;
机器学习框架。能够便捷、快速地将历史的日志对接到机器学习框架进行离线训练,并将训练后的结果加载到线上实时的算法库中。
开源方案设计
-
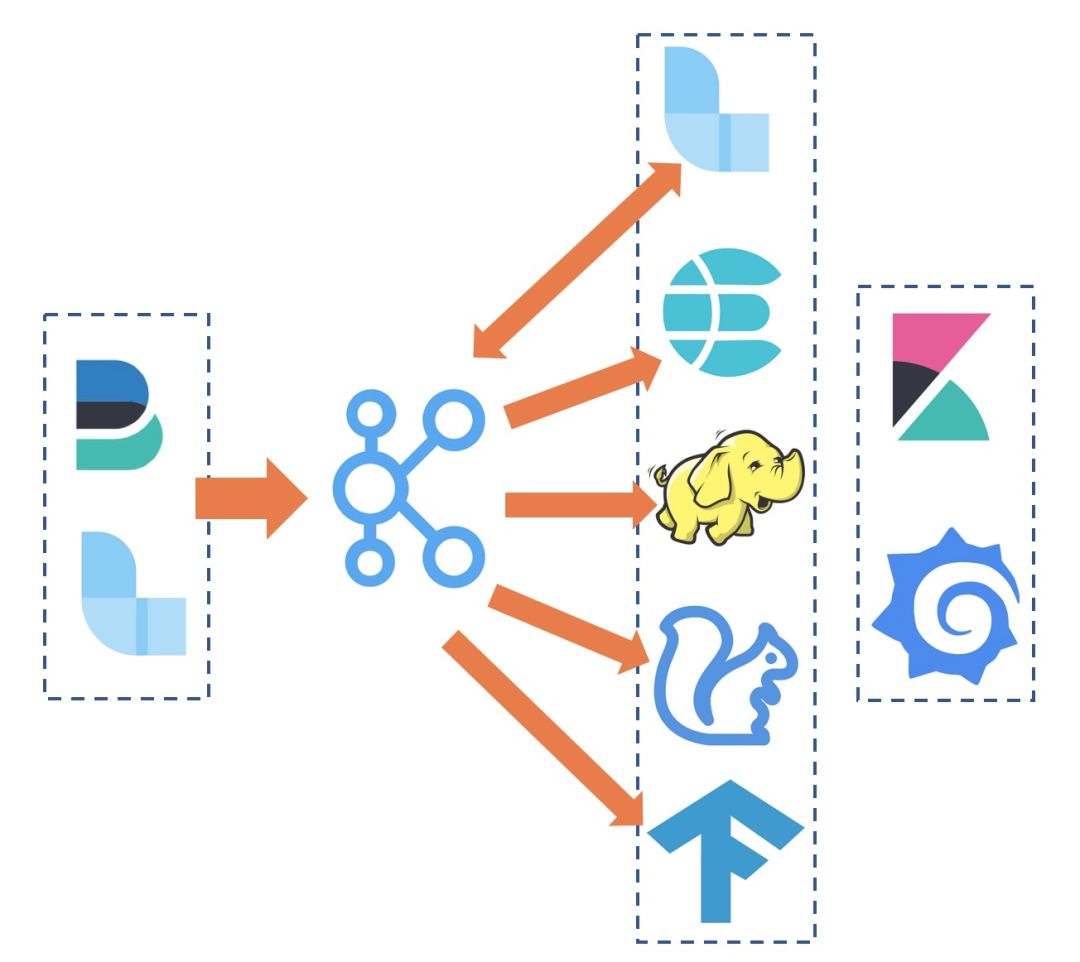
利用 FileBeats、Fluentd 等采集 Agent 实现容器上的数据统一收集;
-
为了提供更加丰富的上下游以及缓冲能力,可以使用 kafka 作为数据采集的接收端;
-
采集到的原始数据还需要进一步的清洗,可以使用 Logstash 或者 Flink 订阅 Kafka 中的数据,清洗完毕后再写入 kafka 中;
-
清洗后的数据可以对接 ElasticSearch 来做实时的查询检索、对接 Flink 来计算实时的指标和告警、对接 Hadoop 来做离线的数据分析、对接 TensorFlow 来做离线模型训练;
-
数据的可视化可以使用 grafana、kibana 等常用的可视化组件。
为什么我们选择自研
-
随着业务量的上涨,日志量也越来越大,Kakfa 和 ES 要不断扩容,同时同步 Kafka 到 ES 的 Connector 也需要扩容,最烦的是采集 Agent,每台机器上部署的 DaemonSet Fluentd 根本没办法扩容,到了单 Agent 瓶颈就没办法了,只能换 Sidecar。换 Sidecar 工作量大不说,还会带来一系列其他的问题,比如怎么和 CICD 系统集成、资源消耗、配置规划、stdout 采集不支持等等;
-
从刚开始上的边缘业务,慢慢更多的核心业务接入,对于日志的可靠性要求越来越高,经常有研发反应从 ES 上查不到数据、运营说统计出来的报表不准、安全说拿到的数据不是实时的......每次问题的排查都要经过采集、队列、清洗、传输等等非常多的路径,排查代价非常高。同时还要为日志系统搭建一套监控方案,能够及时发现问题,而且这套方案还不能基于日志系统、不能自依赖;
-
当越来越多的开发开始用日志平台调查问题时,经常会出现因为某 1-2 个人提交一个大的查询,导致系统整体负载上升,其他人的查询都会被 Block,甚至出现 Full GC 等情况。这时候一些大能力的公司会对 ES 进行改造,来支持多租户隔离;或者为不同的业务部门搭建不同的 ES 集群,最后又要运维多个 ES 集群,工作量还是很大;
-
当投入了很多人力,终于能够把日志平台维持日常使用,这时候公司财务找过来了,说我们用了非常多的机器,成本太大。于是我们又要开始优化成本,但是思来想去就是需要这么多台机器,每天大部分的机器水位都在 20%-30%,但是高峰的水位可能到 70%,所以不能撤,撤了高峰顶不住,这时候只能搞搞削峰填谷,又是一堆工作量。
-
比如面对双 11 的流量,市面上所有的开源软件都无法满足我们那么大流量的需求;
-
面对阿里巴巴内部上万个业务应用,几千名工程师同时使用,并发和多租户隔离我们必须要做到极致;
-
面对非常多核心的订单、交易等场景,整个链路的稳定性必须要求 3 个 9 甚至 4 个 9 的可用性;
-
每天如此大的数据量,对于成本的优化显得极为重要,10% 的成本优化带来的收益可能就有上亿。
阿里巴巴 K8s 日志方案
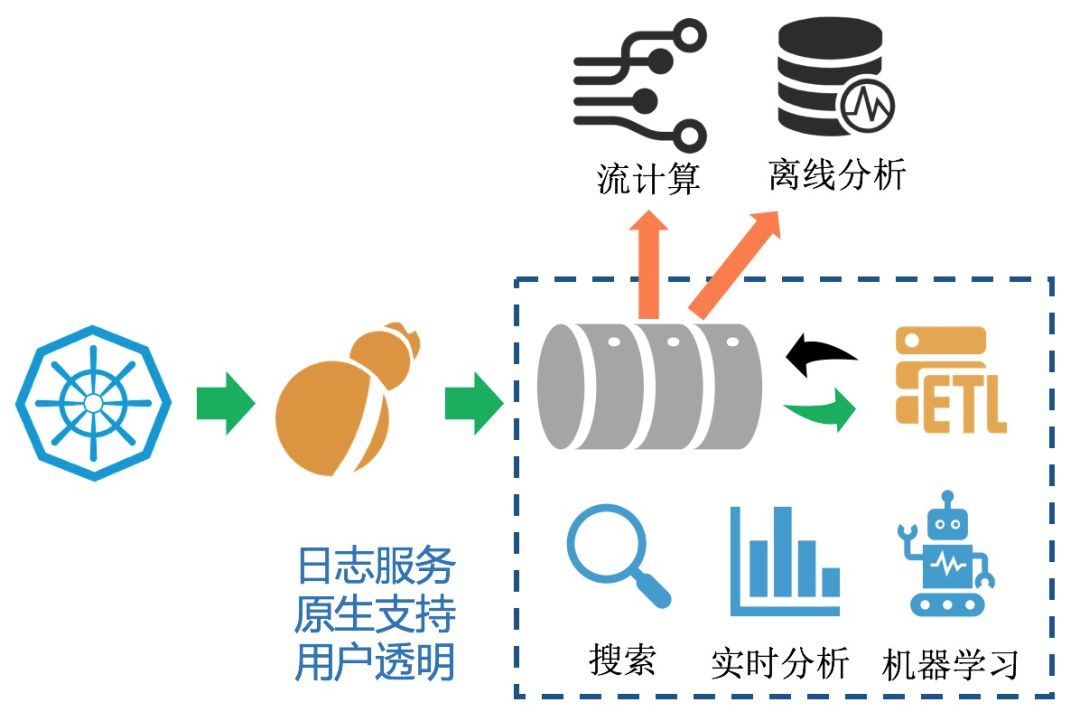
使用我们自研的日志采集 Agent Logtail 实现 K8s 全方位的数据采集,目前 Logtail 在集团内有数百万的全量部署,性能、稳定性经过多次双 11 金融级考验;
化繁为简,数据队列、清洗加工、实时检索、实时分析、AI 算法等原生集成,而不是基于各种开源软件搭积木的形式实,大大降低了数据链路长度,链路长度的降低也意味着出错可能性的减少;
队列、清洗加工、检索、分析、AI 引擎等全部针对日志场景深度定制优化,满足大吞吐、动态扩容、亿级日志秒级可查、低成本、高可用性等需求;
对于流式计算、离线分析场景这种通用需求,无论是开源还是阿里巴巴内部都有非常成熟的产品,我们通过无缝对接的方式来支持,目前日志服务支持了数十种下游的开源、云上产品的对接。
总结
K8s 上以什么样的姿势来打日志?
K8s 上的日志采集方案选择,DaemonSet or Sidecar?
日志方案如何与 CICD 去集成?
微服务下各个应用的日志存储如何划分?
如何基于 K8s 系统的日志去做 K8s 监控?
如何去监控日志平台的可靠性?
如何去对多个微服务/组件去做自动的巡检?
如何自动的监控多个站点并实现流量异常时的快速定位?
 IDEA 插件市场 10 万下载,4.5 高分推荐:(点击“阅读原文”可直接下载插件。)
IDEA 插件市场 10 万下载,4.5 高分推荐:(点击“阅读原文”可直接下载插件。)
|
线下活动 |
||
|
11.24 |
|
北京 |
|
线上直播 |
||
|
11.21 |
|
社群直播 |
以上是关于一文看懂 K8s 日志系统设计和实践的主要内容,如果未能解决你的问题,请参考以下文章