实战 | eBay PB级日志系统的存储方案实践
Posted 过往记忆大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实战 | eBay PB级日志系统的存储方案实践相关的知识,希望对你有一定的参考价值。
eBay存储团队致力于研发与应用业界最好的技术,以支撑最有挑战的业务的存储需求。本文从总体设计方案到具体实现细节,再到遇到的各种软硬件问题,详细描述了如何在生产环境中应用CephFS取代商业存储,支撑起eBay PB级别、每秒GB级别吞吐的集中式日志系统CAL 。希望能对同业人员有所启发。

CAL(Central Application Logging) 系统主要负责收集和处理eBay内部各个应用程序池的日志,日处理超过3PB的数据,供运维团队和开发团队日常监控使用。
CAL从第一天起就运行在Netapp的商业存储上。随着业务的发展,业务产生的数据量急剧增加,单个存储集群已经无法承载 CAL的流量和性能需求,存储团队和业务团队通过增加集群来解决性能问题。一直到2018年,CAL在每个数据中心已经需要25个集群才能支撑起其性能需求。
虽然统计上,CAL只使用了eBay 5%的NFS Filer总容量,但实际上却消耗了50%的总性能。性能和容量的巨大偏离,使得实际成本已经比该存储方案的裸$/GB成本高了一个数量级。
高成本,叠加上由eBay业务驱动的每年30%自然增长,这套架构亟需重构优化。
2014年,eBay 存储团队开始在公司内将Ceph应用于生产环境。第一阶段主要是RBD块设备服务。
2017年,Jewel版本发布后,我们开始尝试提供CephFS分布式文件系统服务,多个天使应用从商业存储迁移到CephFS上,从中我们发现修复了MDS的多个bug并贡献回社区,也在社区首次完成了MDS的性能分析。
2018年,随着MDS多活功能的初步成熟,我们也和业务团队一起,开始了把CAL迁移到CephFS上的征程。
2019年初上线至今,Ceph在大流量下稳定运行。平均读写带宽同时超过了3GB/S,读写请求数合计超过100K IOPS(每秒进行读写操作的次数), 文件系统元数据操作数超过30K OP/S(每秒操作次数)。
1)文件系统元数据路径,支持100K OP/S ,包括:create / getattr / lookup / readdir / unlink等文件系统操作;并预留足够的升级空间满足业务发展。
2)文件系统的数据路径,支持150K IOPS(50%读,50%写),以及至少6GB/S(50%读,50%写)的吞吐。
3)单集群容量需求300TB 可用空间,满足性能需求的前提下尽可能降低存储成本。
这个略显激进的设计目标,其实在很大程度上已经决定了我们的方案。
-
基于我们之前针对Ceph MDS的性能研究,单MDS只能支持2K ~ 4K OP/S, 要支持100K OP/S,MDS多活负载均衡集群是唯一的路径。至少需要25个MDS Active-Active 组成集群。同时,业务负载还要能相对均衡地分布到每个MDS上。
-
150K IOPS的读写性能,如果单用机械硬盘HDD,需要至少1500块盘,可用容量接近3PB,又回到了用尽性能而浪费容量的老路。如果全部用SSD,1PB 裸容量的SSD 虽然能比商业存储省钱,但仍是一笔不小的数字。针对日志数据有明显冷热度的特点,使用分层存储,把频繁访问的数据放在SSD上,相对冷的数据放在HDD上,才能达到最佳费效比。
MDS多活负载均衡集群
要实现向外扩展(scale-out)的架构,核心是任务分配,把负载相对均等地分配到每个MDS上。对于文件系统来说,整个目录结构是一棵树。任务分配的本质,是通过设计目录树的结构,使得叶子(文件)平均地长在这颗树的每个枝干(目录)上。同时,每个层次的文件/文件夹个数必须是可控且相对均衡的,这样才能尽量降低树的深度,避免对一个巨大文件夹进行ListDir操作带来的延迟和开销。
CAL原先的目录层次如下图1所示,一共有15层,100多万个文件夹,几乎违反了上面讨论的所有原则,目录过深且不均衡。eBay每个pool承担一个服务,每个服务的流量,服务器数量差异显著。更糟糕的是整个目录树,在每个小时开始的时候,几乎完全重建(虚线部分),导致每小时开始时元数据操作风暴。
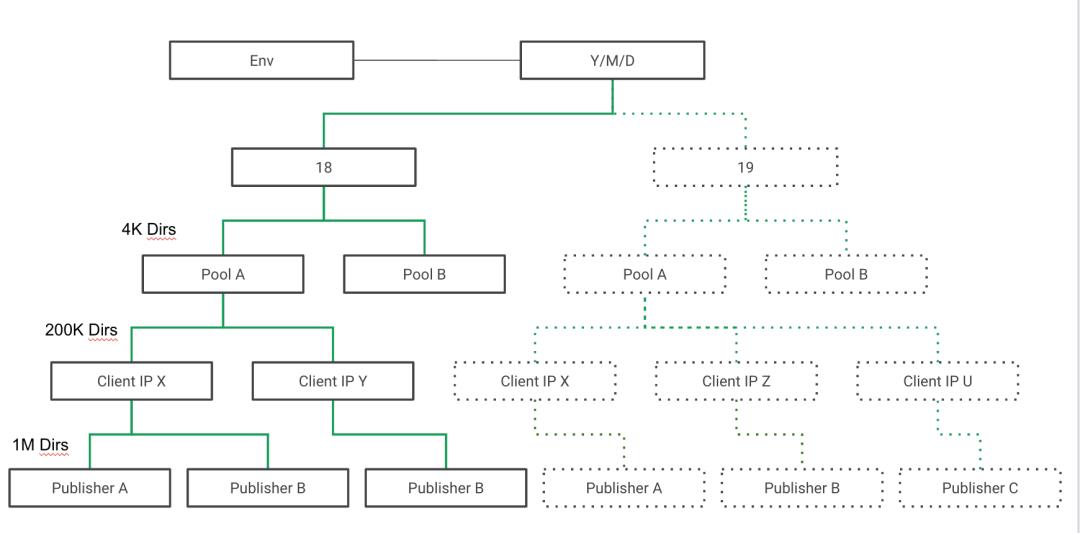
图1(点击可查看大图)
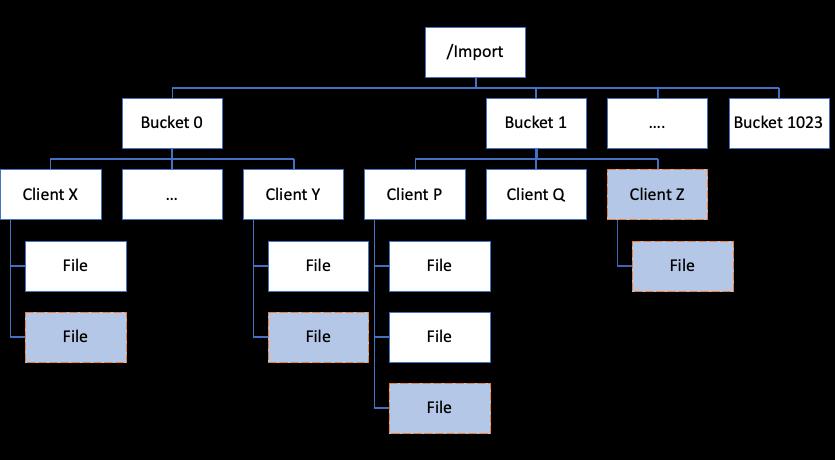
图2(点击可查看大图)
1)在根目录下建立1024个Bucket, Client(CAL的Client,其实是业务APP服务器)通过哈希映射到其中一个bucket下。由于哈希的(统计意义)均衡性,每个Bucket里的Client文件夹数量是均衡的。而Client文件夹的总数,和业务APP服务器的总数对应。
auth_pin = bucket_id % NUM_MDSs
Cache Tier
Ceph Cache Tier是一个在诞生之初被抱以巨大期望,而在现实中让不少部署踩坑的技术,尤其是在RBD 和CephFS上。在社区邮件组和IRC里最经常出现的问题就是应用了Cache Tier,性能反而下降了。
其实,那些场景多数是误读了Cache Tier的应用领域。Cache Tier的管理粒度是Object(默认4MB), 而在RBD/CephFS上的用户IO通常明显小于4MB。当用户访问未命中,Cache Tier决定将这个Object从Base Tier 缓存到 Cache Tier时, 付出了OBJ_SIZE 大小的慢速读(Base Tier)加上 OBJ_SIZE大小的快速写(Cache Tier)。
只有后续用户对同一个Object的重复访问达到足够多的次数,才能体现Cache Tier的性能和成本优势。例如,业务负载是随机IO,平均请求大小4KB,则命中率必须达到99.9%以上。
现实是许多业务负载并没有这样的特性。
在CAL的业务模型里,典型的IO负载是应用日志每隔一分钟或者128KB触发一次写入。同时,读取端不断地追踪日志,以同样的间隔把数据读走。针对这个特点,我们决定将Cache Tier配置成为一个Writeback Cache(回写式缓存), 这样就能实现多个目的:
1)写入缓冲与合并。Cache Tier的设计容量足够缓存一小时的写入量,不论业务的写入请求大小是多少,都会被Cache Tier吸收,以OBJ_SIZE(4M)为单位刷回Base Tier。4M的大块写,是对HDD最友好的访问行为,可以最大化Base Tier的吞吐量。
值得一提的一个优化点是:我们通过禁用Hitset关闭了Proxy Write这个功能。Ceph Cache Tier的默认行为是Proxy Write——即若待写入数据在Cache Tier不命中,Cache Tier会直接把请求写入Base Tier,并在写入完成后才将结果返回给应用。
这是一个正确的设计,主要是为了避免写请求不命中时promote带来的额外延迟,并解耦数据写入逻辑和 Cache Promote逻辑。
但在eBay日志的应用场景中,因为写入行为的顺序性和日志不可变更的特性,可以明确知道写入不命中一定是因为写入了一个新的Ceph Object,而非对老Object的改写,因此proxy write的逻辑就带来了额外的开销。
例如,对obj x 的第一次写入, write(obj_x, 128kb),在默认的Proxy Write行为下,这个写被proxy到了Base Tier。写入成功后,在Base Tier留下128KB的object,然后Cache Tier再把obj_x 从Base_tier promote上来。
而关闭proxy write后,则先对obj_x做一次promote,在Cache Tier中产生一个空对象,再直接写入128KB数据即可。
相比之下,后者节约了Base Tier一次128KB写和一次128KB读,对于由全机械硬盘构成的Base Tier来说,这样的节约意义重大,并且应用的写入延迟大大降低了。这部分Ceph具体代码,可以阅读PrimaryLogPG::maybe_ handle_cache_detail的实现。
其他的配置优化包括设置min_flush_age和min_evict_age来保证最近一小时的数据不会被刷出Cache,以及对target_max_byte, target_dirty_ratio, target_dirty_ratio_high的调整,在此不一一赘述。
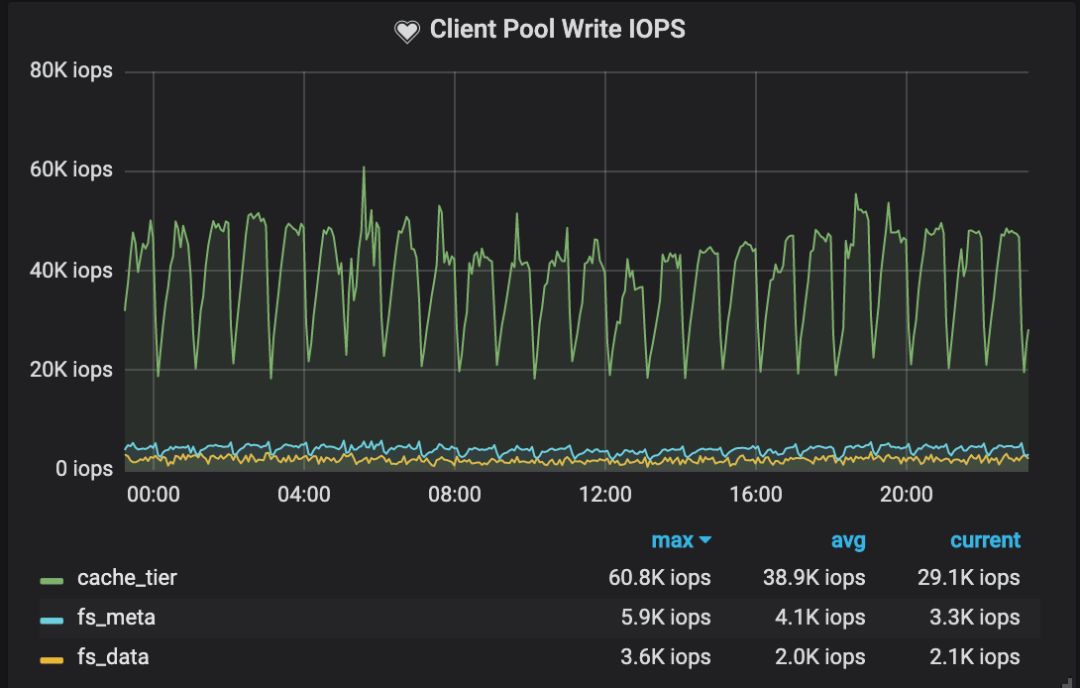
图3 集群客户端写入性能
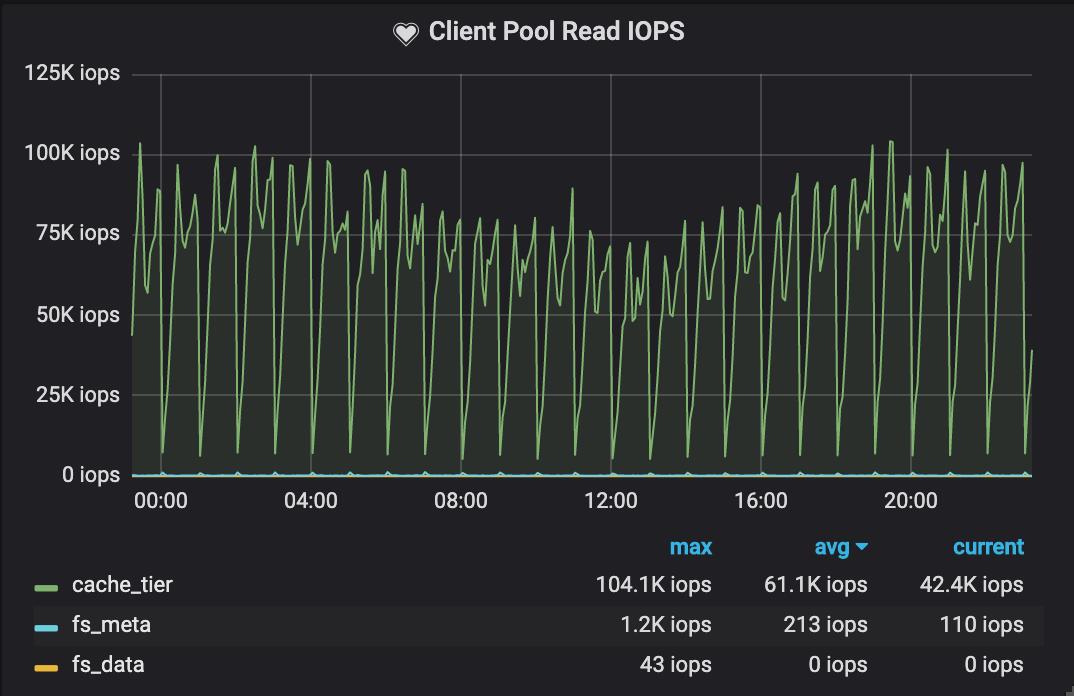
图4 集群客户端读取性能(点击可查看大图)
综合来看, 在Cache Tier上的总IOPS达到了70K,而Base Tier 只有1.5K IOPS。通过深入理解业务的IO模型,合理配置Cache Tier,我们实现了分层存储。
应用享受到了全闪存集群的性能,成本上却接近全机械盘的价格,实现了了性价比最大化。
下面分享几个在实施日志存储方案中遇到的软硬件问题,附上我们的解决方案,以供大家参考。
Bluestore Allocator(空间分配器)
在上线过程中,我们很顺利地度过了25%, 50%的流量。但在75%流量时,遇到了诡异的性能问题。
如下图5所示,Cache Tier 的写入延迟暴增,甚至能达到分钟级别,通过OSD Performance Counter很快把问题缩小到Bluestore内部, 结合日志发现延迟主由STATE_KV_COMMITING_ LATSTATE_KV_COMMITING_LAT约等于 commit_lat。
我们第一个怀疑的对象是RocksDB的性能,尤其是compaction带来的影响,并在此做了大量的调优,然而一无所获。
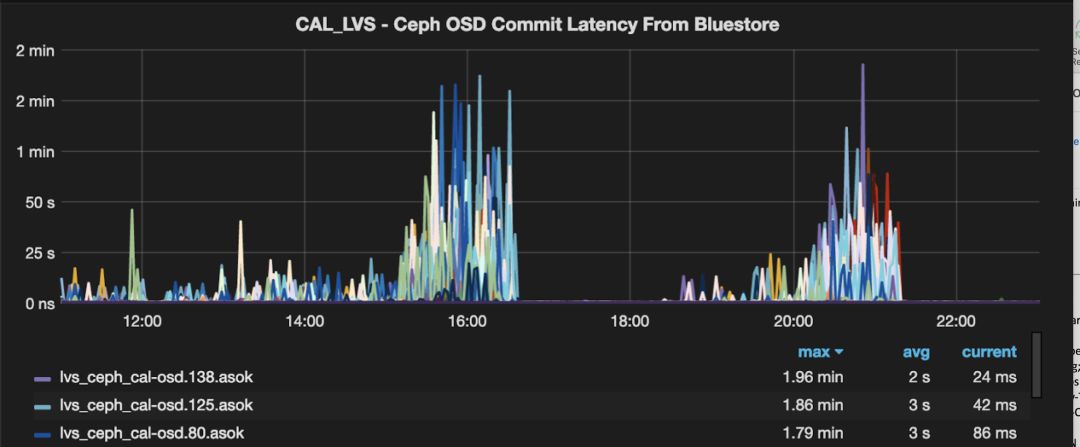
图5 Bluestore commit latency性能监控

图6

图7
其中[8K, 12K) 区域已经是个碎片,但因为和周边区块不是同样大小,落到不同的bin中,已经很难再被合并了,而类似的操作序列,在Bluestore日常面临的空间分配回收请求中并不鲜见。

图8
我们首先在社区发现定位了这个问题,并与核心开发者一起验证了Naultilus中的位图分配器(Bitmap Allocator)没有类似问题,且性能表现更为稳定。因此也使得位图分配器被完整地反向移植到Luminous和Mimic 版本中,并成为默认分配器。
应对SSD稳态性能下降
关于SSD性能有一个并不冷门的常识——SSD的稳态性能与标称性能不一定是一致的。对于普通数据中心级别的SSD来说,稳态性能通常比非稳态性能低(相应的,非稳态可以认为SSD尚有足够空间供分配,或者后台维护行为对业务IO无干扰),非写入密集型的型号差距会尤其明显。
SSD进入稳态是需要一定写入量和时间的,因此在做硬件性能和软件性能调优时需要将这个因素充分考虑进去,否则实际产品运行起来以后就会出现意料不到的问题。
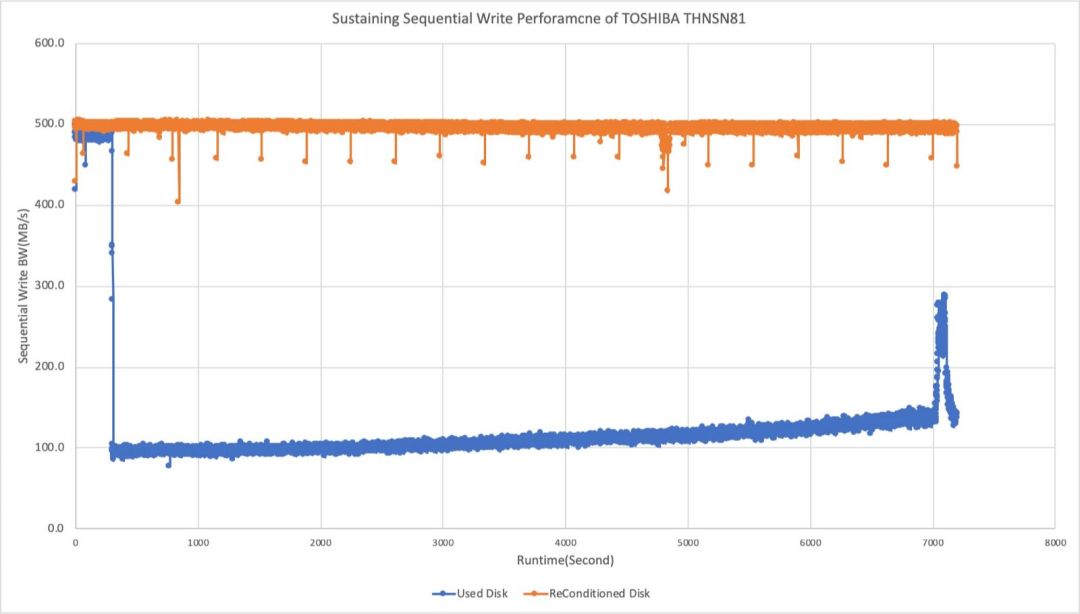
图9 SSD稳态与非稳态性能对比
受限于成本以及当前可用服务器选择,我们所采用的SSD即属于非写入密集型(DWPD较低),同机型同容量,来自3个不同厂商的SSD的DWPD分布在0.7~1之间。而eBay日志存储Cache Tier恰好是写入读取都很密集的类型。这下,我们似乎面临了巧妇难为无米之炊的困境。
基于我们对SSD实现原理的理解,非写入密集型SSD(DWPD指标低)稳态与非稳态性能差距大的主要原因之一是厂商针对这类SSD的产品设计上,出厂预留的Over Provision空间较小。
当合理的产品设计面临“不合理”的业务需求时,大写入压力持续一段时间以后,SSD固件做空间整理和垃圾回收(GC)的效率会变低。应用端的表现是在持续的大负载写入下,GC发生时延迟和吞吐都会受到很大的负面影响。
分析完这个可能原因后,在无法变更硬件的前提下,我们的解决办法是通过主动预留空间,来弥补厂商原有OP先天不足的“缺点”:
在SSD被加入集群前,我们对全盘TRIM之后,分区时只使用80%的空间;留下20%被TRIM过的区域因为在固件FTL中标记为空闲,自然会在GC等操作的时候当作缓冲来使用。加上这额外的20% OP后,我们SSD的写入延迟和带宽都能稳定在最佳状态(图9中橘色线的性能)。
这套实践应用在同机型、多批次来自3个不同厂商的SSD上都获得同样好的效果,上线至今并未观察到衰减。
那么20%的空间预留是目前的经验值,当应用行为有所改变时SSD性能再次衰减又该怎么应对呢?需要停下服务重新修改预留空间大小吗?
其实不然,对于已经衰减的SSD, 只需要TRIM 20%的区域提供OP,再经过一个完整的写入周期后,性能就可以回升到最佳状态。
图10 对预留区域TRIM恢复全盘性能测试
CephFS由于成熟得相对晚,在国内外的大规模商用案例有限,更多的被作为归档和冷存储使用,较少有大流量的线上业务应用。尽管我们比较激进的使用了MultiMDS多活,Cache Tier等当前在业界还较少部署的技术,但CephFS在大流量的生产环境中证明了自己的价值和稳定性,为其他eBay内部应用迁移到CephFS打下了坚实的基础。
1、
2、
3、
4、
过往记忆大数据技术交流群,请添加个人微信:fangzhen0219,备注进群。
以上是关于实战 | eBay PB级日志系统的存储方案实践的主要内容,如果未能解决你的问题,请参考以下文章
腾讯 PB 级大规模 Elasticsearch 集群运维与调优实践