集中日志系统ELK
Posted 青乡
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了集中日志系统ELK相关的知识,希望对你有一定的参考价值。
作用
以前都是登陆到每个机器去看日志,特别是一个服务有多个机器集群部署,还要下载多个机器的日志(运维下载日志,然后给开发排查问题),现在elk是集中式日志系统,所有的项目和项目集群都在一个日志系统里,而且可以搜索。
界面
组成
L是收集日志,还有解析日志
E是搜索引擎,就是ElasticSearch
K就是界面
流程
原始日志(L的客户端)——收集和解析日志(L的服务器端)——搜索引擎(E)——界面展示(K)
解释
1.收集日志和解析日志
收集日志就是客户端到服务器,就是把L客户端安装到部署项目的机器,然后读原始日志文件,再写到L的服务器端。这是收集日志,就是:原始日志文件——L的客户端——L的服务器。
L的服务器还要解析日志,主要是解析为固定的几个字段,比如时间、IP(哪个机器的日志)、日志本身的内容、项目名字(哪个项目的日志)。这几个固定字段是搜索引擎需要的字段。
2.搜索引擎
刚才解析之后的字段,再写给搜索引擎。
3.界面
filebeat
为什么要用filebeat,因为L的客户端性能不好,影响部署项目的机器,所以换了filebeat作为L的客户端,作用和L的客户端一样,都是收集日志,本质就是先读原始日志文件,然后再写到L的服务器。这就是filebeat的作用,对部署项目的机器无影响。
kafka
为什么要用kafka,因为日志产生和日志消费的速度不匹配,还有由于网络原因,可能会导致数据丢失,所以才要加消息中间件,因为消息中间件可以缓存海量数据,并且数据不会丢失(丢失可能性极小,不会大量丢失数据)。
架构图的演变
只有ELK
L的客户端没有使用filebeat。
换了filebeat
L的客户端换成了filebeat。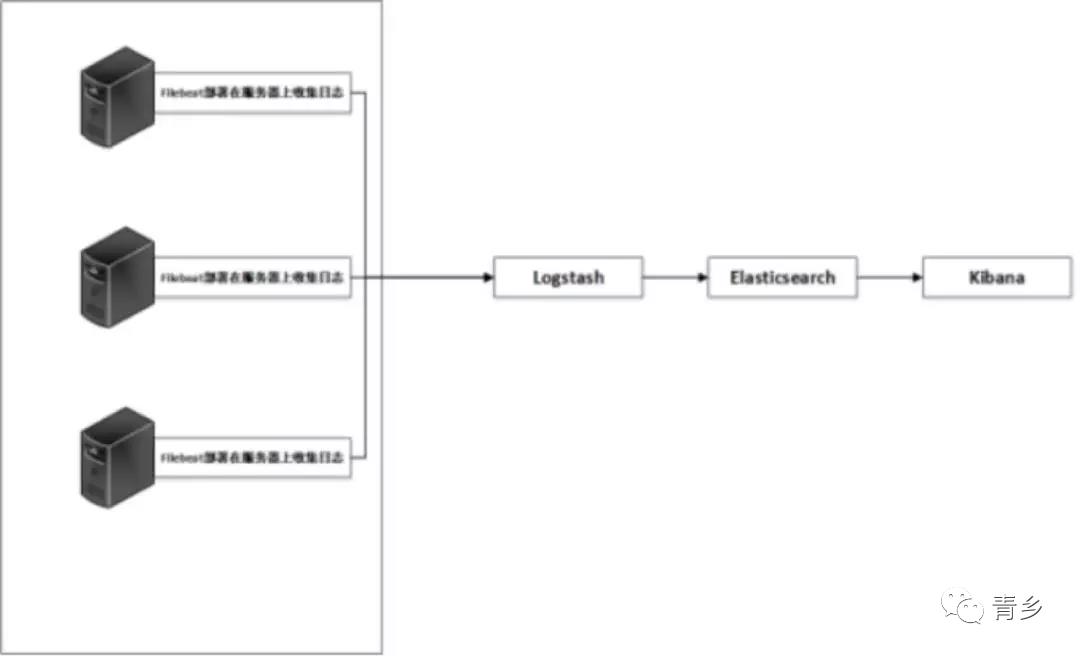
加了消息中间件
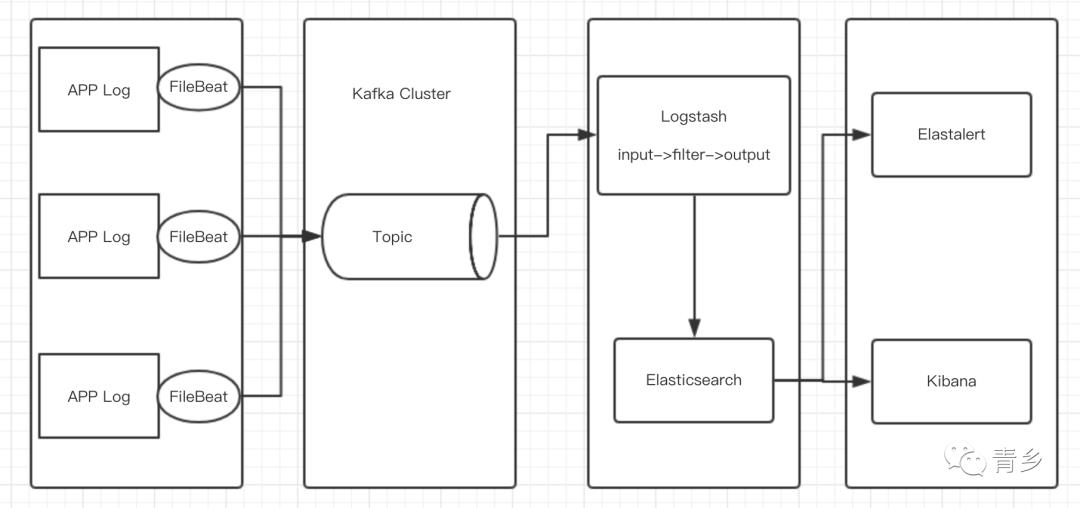
双层L
从左往右看
从右往左看
第一层L作用只是分流,第二层L作用是解析为固定几个字段。
参考
https://mp.weixin.qq.com/s/F8TVva8tDgN0tNsUcLoySg https://www.cnblogs.com/wangxu01/articles/11242408.html
https://blog.qiniu.com/archives/8779
https://jusene.github.io/2018/11/04/elk-1/
以上是关于集中日志系统ELK的主要内容,如果未能解决你的问题,请参考以下文章