基于大数据日志系统的流量回放平台
Posted 酷家乐技术质量
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于大数据日志系统的流量回放平台相关的知识,希望对你有一定的参考价值。
一、说明
这篇文章想阐述的,除了提供当前大数据组流量回放平台的思路和实现,也提醒大家:通过日志系统可以做很多事情,比如获取并分析用户行为,实现基于用户行为的精准测试,又或者是线上巡检等等,而我只是小试牛刀。。。
二、背景
2020H1正在对大数据引擎服务-浑天仪进行重构升级,这个项目主要的场景是:将业务方发送的json(dsl)翻译成sql,查询大数据各类存储引擎的数据,验证重点是:确保查询大数据存储数据接口的请求和返回的处理结果跟原来保持一致。
而主要的难点在于:仅从手工造数据的方式很难覆盖各种业务场景,尤其是如何构造请求参数组合和检查各种返回的内容,难度相当于测试mysql等数据库的sql语法。于是想到了基于流量回放对比的方式提高测试效率。
三、工具调研
虽然团队内部已经有了基于jvm-sandbox-repeater和基于goreplay + diffy实现的两套流量回放平台,但是基于以下几个原因我还是选择了自己造个轮子:
1. 大数据的日志采集和埋点系统已经很成熟,而且性能和稳定性久经考验。通过日志埋点流量回放的方式,可以做到安全、方便(线上日志源源不断,无需手动导流,可实现7*24小时无人值守);
2. 浑天仪服务内外网数据库中的数据基本保持一致,数据来源都是基于ODPS的生产环境数据,在内外网端实现结果对比无需Mock数据。因此轻量级的流量回放对比工具即可满足,容易维护。
四、大数据日志系统
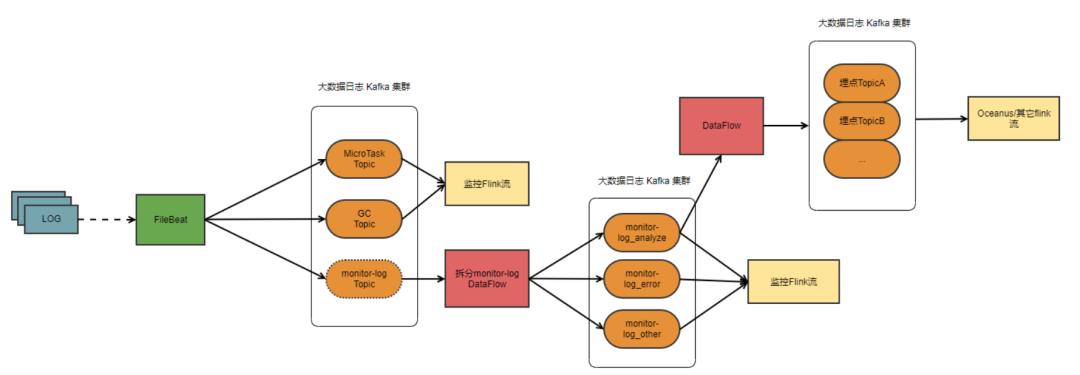
4.1 日志采集流程
酷家乐所有服务器的日志数据都是由大数据服务负责采集的,由Filebeat进行采集,经过dataflow-split flink流对不同级别的日志进行拆分,并临时存储在日志Kafka集群,最后经过dataflow-track流解析生成lms埋点系统中对应的各种埋点数据,再次写回日志Kafka集群中。
虽然我们可以通过监控查询到日志数据(实际上酷家乐监控组的数据源也是由大数据组服务提供的一个拆分流), 但是受限于存储成本,会存在一定的数据丢失。
4.2 埋点系统
需要注意的是只有Analyze级别打印的日志并且在lms埋点系统注册成埋点,才会Kafka集群中生成一个"data_flow_埋点名"的topic,从而被解析成埋点数据存储在kafka中。因此,实现流量回放的思路就是在prod环境的埋点数据中输出接口的请求参数,从而实现流量回放。
以我注册的流量回放埋点为例,在埋点系统中的埋点名是bizdcQuery,其中queryDsl字段是输出请求的body体,即可实现入参的收集。
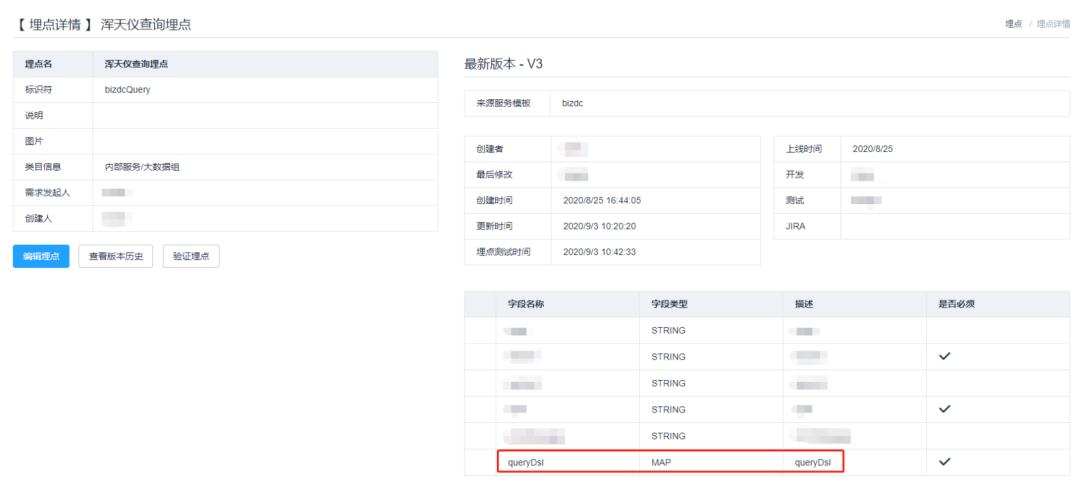
而对应的服务端日志需要按照上述定义格式打印。需要注意的是:日志中需要加入behaviorDescription字段,字段的值是埋点名称。
五、系统设计
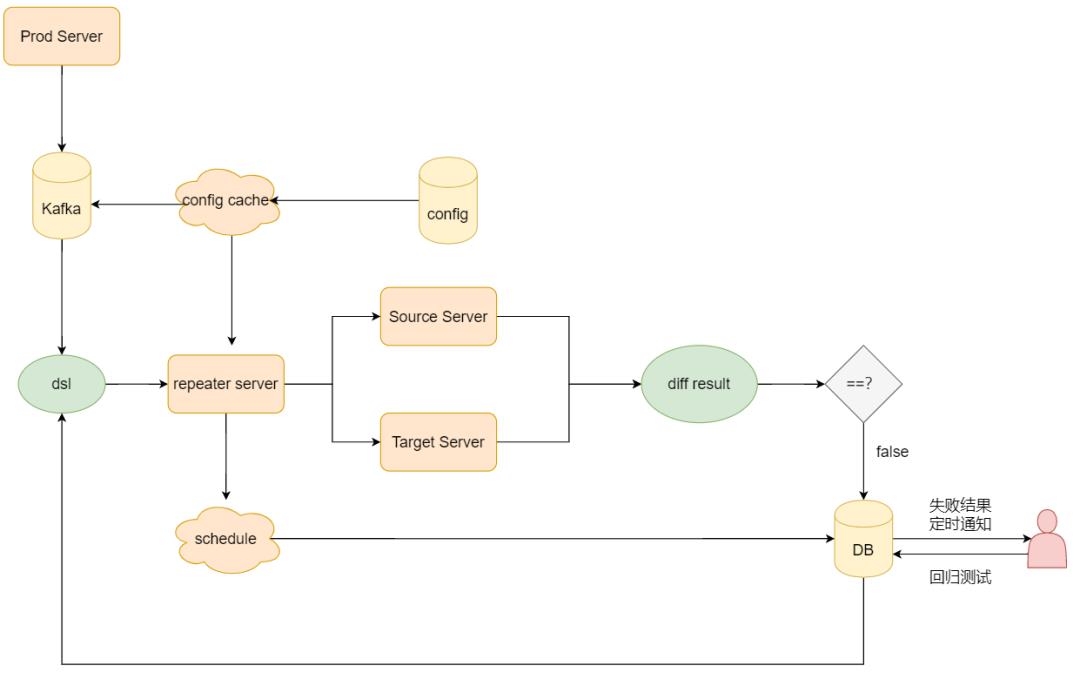
对于不理解大数据日志系统采集流程也没关系,最主要是知道可以通过指定规则获取到日志中的埋点数据。剩下的简单来说,整个系统大概分为以下几步:
2. 创建Kafka消费者,订阅Kafka中日志埋点topic(data_flow_埋点名),获取并解析日志埋点流数据中的请求参数(dsl);
3. 通过流量回放平台同时向不同环境的服务器发起请求,获取响应结果并进行对比;
4. 对比响应值。如果对比结果不一致,则将这条dsl记录到数据库中,并通知消息接收人,否则忽略;
5. 失败的dsl可以作为自动化回归用例展现在流量回放平台上,方便开发和测试同学手动触发回归。
六、核心实现
6.1定时任务
整个流量回放系统可以理解为是由两个定时任务构成:1. 流量回放定时任务; 2. 消息通知定时任务。
定时任务基于quartz实现,并采用JDBC作业存储。但并没有采用quartz推荐的11张表对job状态进行管理,而是使用了1张表并自定义接口实现job状态变更操作,实现轻量级的quartz。
CREATE TABLE tbl_quartz_job (id int unsigned NOT NULL AUTO_INCREMENT COMMENT '自增主键',job_name varchar(50) NOT NULL COMMENT '任务名称',job_group varchar(50) NOT NULL COMMENT '任务分组',job_class_name varchar(100) NOT NULL COMMENT '执行类',cron_expression varchar(100) NOT NULL COMMENT 'cron表达式',trigger_state varchar(15) NOT NULL COMMENT '任务状态',old_job_name varchar(50) NOT NULL DEFAULT '' COMMENT '修改之前的任务名称',old_job_group varchar(50) NOT NULL DEFAULT '' COMMENT '修改之前的任务分组',description varchar(100) NOT NULL COMMENT '描述',PRIMARY KEY (id),UNIQUE KEY un_group_name (job_group,job_name)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='定时任务';
自定义quartz job管理操作,以保存job为例(QuartzJob类映射为上面的数据表):
public boolean saveJob(QuartzJob job) {int res;String jobName = job.getJobName();String jobGroup = job.getJobGroup();try {schedulerJob(job);job.setTriggerState(JobStatus.RUNNING.getStatus());job.setOldJobGroup(jobGroup);job.setOldJobName(jobName);res = jobMapper.saveJob(job);} catch (Exception e) {LOG.error("Failed to save job: ", e);return false;}if (res > 0) {LOG.info("Success to save job. jobName: {}, jobGroup: {}", jobName, jobGroup);return true;}return false;}public void schedulerJob(QuartzJob job) throws Exception {// job里需要指定具体的执行类(全路径)Class cls = Class.forName(job.getJobClassName());// JobDetail表示一个具体的可执行的调度程序,Job是这个可执行程调度程序所要执行的内容,另外JobDetail还包含了这个任务调度的方案和策略。JobDetail jobDetail = JobBuilder.newJob(cls).withIdentity(job.getJobName(), job.getJobGroup()).withDescription(job.getDescription()).build();// Scheduler有simpleScheduleBuilder和cronScheduleBuilder,这里是用cron方式声明定时任务的调度CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder.cronSchedule(job.getCronExpression().trim());// Trigger代表一个调度参数的配置,什么时候去调Trigger trigger = TriggerBuilder.newTrigger().withIdentity(TRIGGER_IDENTITY + job.getJobName(), job.getJobGroup()).startNow().withSchedule(cronScheduleBuilder).build();// Scheduler代表一个调度容器,一个调度容器中可以注册多个JobDetail和Trigger。当Trigger与JobDetail组合,就可以被Scheduler容器调度了。scheduler.scheduleJob(jobDetail, trigger);}
定义一个class实现CommandLineRunner接口并重写run方法,目的是为了在服务启动时自动触发所有非暂停状态的任务。
public class ApplicationInit implements CommandLineRunner {private JobService jobService;private Scheduler scheduler;public void run(String... args) throws Exception {loadJobToQuartz();}private void loadJobToQuartz() throws Exception {List<QuartzJob> jobs = jobService.listQuartzJob();for(QuartzJob job : jobs) {jobService.schedulerJob(job);if (JobStatus.PAUSED.getStatus().equals(job.getTriggerState())) {scheduler.pauseJob(new JobKey(job.getJobName(), job.getJobGroup()));}}}}
6.2回放流程
为了方便拓展不同的流量回放任务,每个任务定义一个类并继承QuartzJobBean类。
// 由于Kafka非线程安全,禁止并发执行public class BizdcRepeatJob extends QuartzJobBean {private BizdcRepeaterComponent component;protected void executeInternal(JobExecutionContext jobExecutionContext) {component.repeat();}}
1. 日志拉取和解析,每次Kafka Consumer拉取日志的存储对象为ConsumerRecord,需要做反序列化处理,获取到queryDsl字段对应的值(即自定义的记录请求参数的参数字段)。每个回放任务持有单例的Kafka消费者组,根据不同的topic创建不同的消费者,执行repeat方法。在repeat方法中主要做以下几件事情:
2. 对包含关键字的请求进行过滤,比如dsl中查询某张大表,会对线上数据库造成压力,可以根据queryDsl中的表名做过滤。为了兼顾配置的灵活变更和减轻对数据库的压力考虑,使用了GuavaCache做本地缓存。
3. 获取流量回放的配置,主要是请求回放的两台目标服务器以及对应的uri。同理,也使用了GuavaCache做了本地缓存。
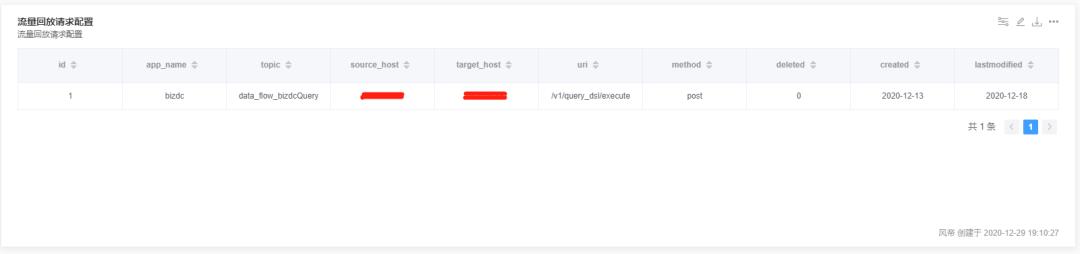
4. 使用基于HttpClient包的工具类做请求转发。
为了避免跨引擎查询场景中因网路抖动造成的请求失败,引入失败重试机制;
由于线上QPS很高,需要提升流量回放对比的速度,以便kafka消费速度跟上消息生产速度,因此采用多线程异步的方式做请求转发和结果对比
private CompareResult sendRequestAndDiff(final String url1, final String url2, final String body) {return CompletableFuture.supplyAsync(() -> sendRequestAsync(url1, body), executorService).thenCombine(CompletableFuture.supplyAsync(() -> sendRequestAsync(url2, body), executorService), (response1, response2) ->DiffUtils.commonDiff(response1, response2)).join();}
5. 结果响应请求对比。由于当前json对比的工具类非常多,这里引用了jvm-sandbox-repeater的json对比工具包,并增加了忽略对比响应结果指定字段的实现方法。
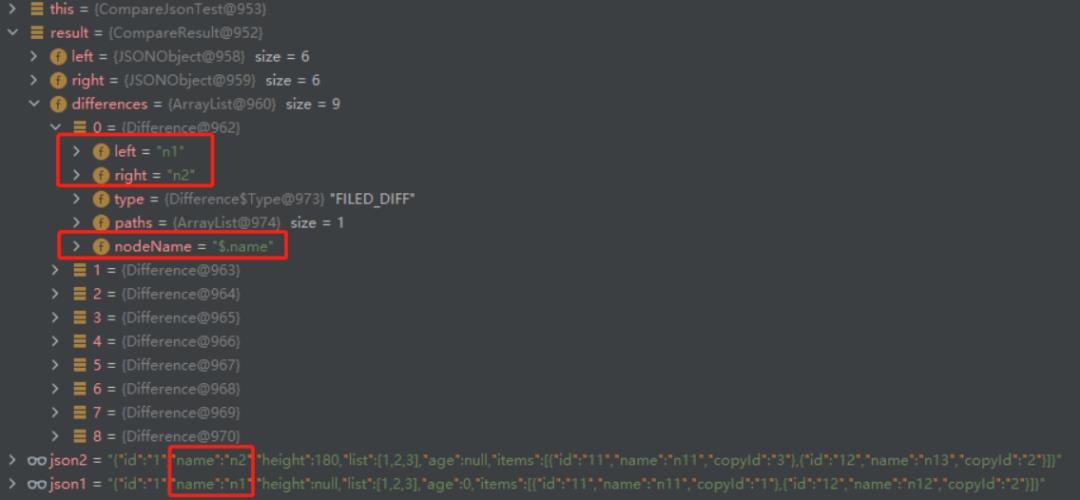
(截图数据为单元测试任意构造数据,不具有任何业务含义)
6. 当结果出现不一致的请求,则记录到数据库中,方便后续做消息通知和展示。
备注:为了避免流量回放对线上数据库造成压力,设置了一定采样率执行回放。目前的采样率是1/200,查询线上数据库的QPS为1.
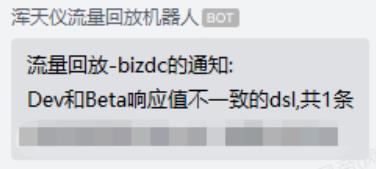
6.3 消息通知
当前采用企信机器人实现消息自动通知
6.4 结果展示
为了节省大家做结果分析和数据报表的前端资源,推荐大家使用大数据组应用层产品-"数据魔方"做可视化展示。只需要在"管理中心"模块中配置好数据源,并在"数据查询"的sql查询模块中自定义sql,即可在看板页面建好sql看板。
如果出现流量回放失败的请求,会实时出现在看板中,还支持邮件等方式做数据预警。
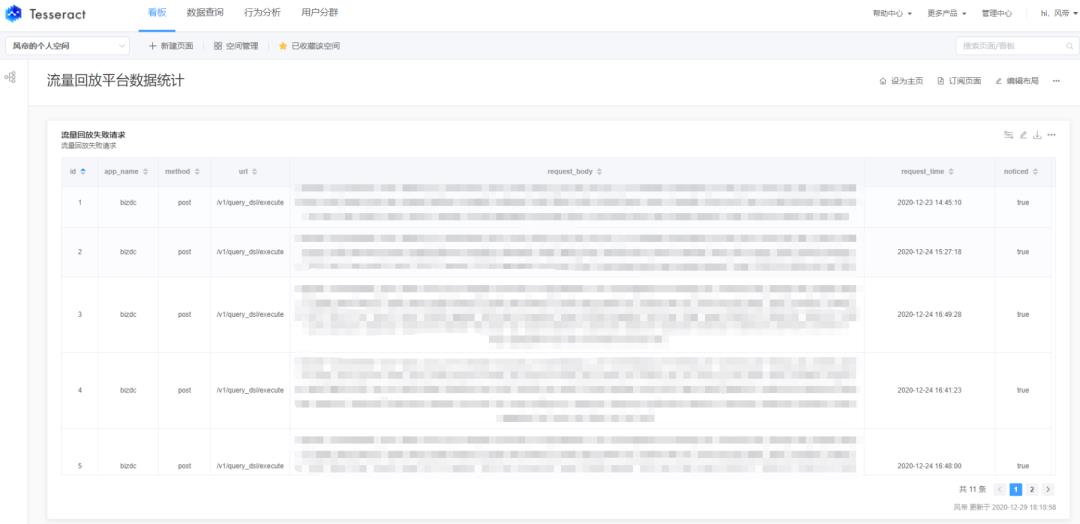
可以结合自身需求做表格、饼图和趋势图等图表,方便从各个维度对回放的流量做数据分析。
6.5 任务调度
1. 流量回放任务的cron表达式设置为* * * * * ? *,即可实现7*24小时无人值守运行,也可以根据实际情况调整。
2. 企信通知任务的cron表达式设置为0 0 18 * * ? ,即每天下午6点通知对比结果。如果没有不一致的结果,则不发通知。
八、总结
1. 基于大数据日志系统实现的流量回放系统上线以来,结合已有的接口自动化测试,可实现开发完全自测,释放了一定的测试资源。迭代的过程中,流量回放平台发挥了自动识别缺陷的作用,为产品平滑上线保驾护航。
2. 当前流量回放平台,是对基于jvm-sandbox-repeater实现的ku-repeater平台的一种补充。如果是面向通用的测试场景,比较适合beta环境和prod环境之间的流量对比。如果大家有这方面的需求,可以接入当前平台。
3. 酷家乐主打大家居设计产品,设计师在画布中的操作可以说是天马行空,公司内部难以感知用户使用产品的习惯。所幸,越来越多的同学意识到日志系统的作用,比如结合业务线自定义埋点获取用户行为,感知用户在设计工具中的操作路径,不仅可以做测试用例设计的参考,甚至有可能100%还原用户行为定位缺陷,同时也可以为设计更加智能化的产品打好铺垫。
TesterHome:kujiale-qa (酷家乐质量效能)
以上是关于基于大数据日志系统的流量回放平台的主要内容,如果未能解决你的问题,请参考以下文章
大数据综合项目--网站流量日志数据分析系统(详细步骤和代码)
开源 | jvm-sandbox-repeater:阿里巴巴开源的基于 JVM-Sandbox 的录制/回放通用解决方案