刷新你对 SQLite 的认知 - 数据类型机制
Posted SwiftCafe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了刷新你对 SQLite 的认知 - 数据类型机制相关的知识,希望对你有一定的参考价值。
SQLite 数据类型
这次选 SQLite 的这个话题。 主要有几个原因,一个是 SQLite 作为移动客户端最常用的本地数据库之一,它的使用范围其实很大,所以有深入了解他的价值。 另外一个是 SQLite 的数据类型机制其实常常会被大家忽略,因为我们或多或少之前对数据库的基本操作有过一定了解。所以在使用 SQLite 的时候就比较容易想当然的根据通用的 SQL 知识来使用它。比如要创建一个数据表,我想大家会很容易的写出类似这样的 SQL 语句来:
create table person {
id int pirmary key,
name varchar(255)
}
一眼看上去这个 SQL 没什么问题, 并且执行到 SQLite 中也能正常运行,成功的创建出数据表。在很长的时间中,我自己也都是这样来写的。直到有一天我在开始搞一个 APP 的 SQLite 环境搭建的时候,突然涌出一个想法 — 这样在 SQLite 中创建数据表的语法虽然符合标准 SQL 中的定义,但这样写是最优的解决方案吗?
因为我知道,每个数据库的实现虽然尽可能的符合 SQL 标准,但肯定做不到完全吻合,SQLite 应该也不例外,一定有它自己的特性部分。带着这个想法,我查了一下相关文档,和我想的一样,SQLite 关于数据类型确实有它自己的一套机制,而且和我们通常熟悉的还不太一样。
SQLite 的官网上有一篇文档专门解释了这个事情:https://sqlite.org/datatype3.html
接下来我就和大家聊聊我的收获。
Storage Class
SQLite 数据类型中,第一个重要的概念就是 Storage Class。 简单来说就是,SQLite 数据表中的每个字段的类型是动态的。和我们熟悉的其他关系数据库不同,假如我定义了一个字段 name 的类型是 varchar(255),如果按照 SQL 标准来说,这张表中每一条记录的 name 字段都必须是这个类型,然而 SQLite 实际上不是这样的。
如果是在 SQLite 中,每条记录的 name 字段的类型是动态的,也就是说同一张表的不同数据条目中,name 字段的类型是可以不同的。并且 SQLite 中用于表示不同值得类型时,用的也不是静态类型,而是 Storage Class。
在 SQLite 中, Storage Class 只有 5 个类型:
NULL : 对应 NULL 值。
INTEGER: 表示有符号整数,根据整数的取值分为 1,2,3,4,6,8 个字节尺寸。
REAL: 用于存储浮点数。
TEXT: 用于存储字符串类型数据。
BLOB: 二进制大数据。
如上所示,SQLite 的核心数据类型只有这 5 个。 比想象的要简单很多,并且 SQLite 数据是动态类型。 那么为什么我们可以在 create table 语句中使用 varchar, double 这样的数据类型写法呢?这就涉及到另外一个概念了。
Type Affinity
上面提到的 Storage Class 是 SQLite 中数据的存储类型,它们代表的是数据实际在磁盘上面的存放类型。如果我们要在 SQL 语句中表示数据类型,就需要用到另外一个概念,也就是 Type Affinity。
Type Affinity 可以理解为对这个数据字段的推荐类型。为什么说是推荐类型呢,因为我们前面提到过,SQLite 的数据类型是动态的,我们只能给这个字段推荐一个类型,而不能规定这个字段只能是这个类型。
Type Affinity 也分为 5 个类型:
TEXT
NUMERIC
INTEGER
REAL
BLOB
虽然和前面的 Storage Class 的 5 个取值有部分重合,但它们的含义是不同的。Type Affinity 是可以直接写到 SQL 语句中的,比如我们开始的例子中可以改用更符合 SQLite 自身标准的写法:
create table person {
id INTEGER primary key,
name TEXT
}
那么大家之这时候可能会有些疑问了,比如 name 字段,既可以用 TEXT 也可以用 varchar(255) ,那我到底该用哪个呢,它们之间的区别是什么?
这就要从 Type Affinity 的匹配规则说起,我们除了这样明确的写出 INTEGER 和 TEXT 这样的 Type Affinity 外,SQLite 还会对 Type Affinity 进行匹配。
比如 INTEGER 类型,只要我们在 SQL 中指定的类型名称包含 INT, 都会被匹配成 INTEGER,不区分大小写。 也就是说你在 SQL 中写的类型名称是下面中的任何一个,都会被匹配成 INTEGER:
INT INTEGER TINYINT SMALLINT MEDIUMINT BIGINT UNSIGNED BIG INT INT2 INT8
只要类型名中包含 INT 的,就会被匹配成 INTEGER。 这就解释了为什么我们最开始的那个 SQL 语句也可以成功运行了。下面是每个 Type Affinity 的匹配规则:
INTEGER: 类型名中包含
INT。TEXT: 类型名中包含
CHAR,CLOB,TEXT。REAL: 类型名中包含
REAL,FLOA,DOUB。BLOB: 类型名中包含
BLOB。NUMERIC: 其他情况都会匹配到这个。
这些匹配规则都是不区分大小写的,知道了这个规则的存在,再回头看看我们最开始写的 SQL:
create table person {
id int pirmary key,
name varchar(255)
}
int 符合 INTEGER 的匹配规则,所以能执行通过, varchar(255) 符合 TEXT 的匹配规则,所以也能执行通过。然后他们之间有区别吗? 其实是没有区别的,只是一个概念的不同写法。int,varchar 这些匹配规则的存在是为了更好的兼容我们熟悉的 SQL 标准的写法。
无论怎么写,本质上都是对应的 5 个 Type Affinity 之一。 当然,如果你是在为 SQLite 环境进行 SQL 设计,TEXT,INTEGER 这种写法会更加合适一些。
最后,关于 Type Affinity 的匹配规则有两个值得一提的事情,首先匹配是严格按照我们上面写的顺序进行的,也就是说如果你遇到一个 CHARINT 的类型名称,它同时匹配了 TEXT 和 INTEGER。 但因为 INTEGER 是最先匹配的,所以他会被匹配成 INTEGER。
另外一个就是, 虽然 varchar(255) 这种写法,可以匹配到 TEXT 类型,但括号里面表示长度的 255,是会被忽略的,SQLite 中字符串字段没有长度限制。
Type Affinity 如何工作
我们了解了 Type Affinity 的存在,以及它如何匹配,生效。那么还有最后一个问题,假如我们给一个字段指定了 Type Affinity, 它在实际运行中都起什么作用呢?
还是以 name 字段为例,它的 Type Affinity 类型是 TEXT。 我们可以这样写 insert 语句:
insert into person (name) values ('mark');
这里插入的数据类型和 Type Affinity 推荐的类型是一样的,都是字符串,语句被成功的执行。另外一种情况,如果我们这样写 insert 语句呢:
insert into person (name) values (500);
这次我们插入的是一个整数,这时候 Type Affinity 的作用就体现了,因为 Type Affinity 建议的类型是 TEXT, SQLite 就会把这个数字 500,转换成字符串 `500` 然后在插入数据库中。
这个机制对于 INTEGER 也一样,比如 id 字段:
insert into person (id) values ('20');
这条数据在插入的时候,也会把字符串 `20` 转换成数字 20。
在 DB Browser 中验证
到这里,我们算是把 SQLite 数据类型机制了解了一遍。 那么在实际使用时会是什么样呢,我们来用 DB Browser 试着操作一下真实的 SQLite 数据库。
DB Browser 是一个很好用的 SQLite 数据库管理工具,首先,我们试着创建一个数据表:
可以看到,DB Browser 在创建表的时候,使用的是 SQLite 的 Type Affinity 类型。可见,它采用的就是更加符合 SQLite 习惯的类型名称。看完这篇文章后,下次再使用类似 DB Browser 的工具创建表的时候,就不要质疑为什么没有 varchar, float 这样的字段类型了。 Type Affinity 的类型命名方式,才是 SQLite 中更加标准的。
我们还可以用 DB Browser 验证一下 Type Affinity 和 SQLite 的动态类型机制是如何运行的。还是在 DB Browser 中,执行一条这样的插入语句:
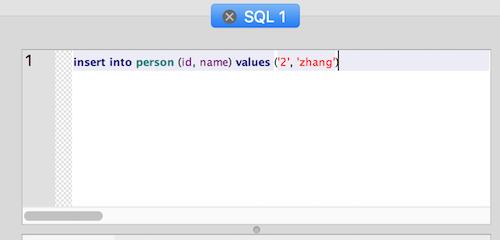
id 字段应该是 INTEGER 类型的,但我们这里给它插入了一条字符串类型的值。执行一下,这条插入语句是能够成功运行的。我们需要验证一下插入到表中的这条数据实际存储的类型是什么,我们可以运行这条语句:
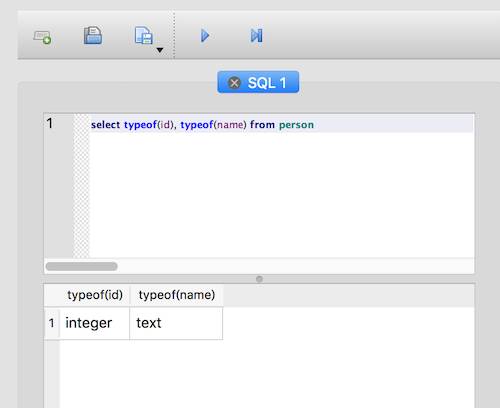
typeof 函数可以获取到每条数据在库中实际的存储类型,虽然我们 insert 语句中插入的 id 是字符串类型,但因为 id 字段的 Type Affinity 是 INTEGER。 数据在实际存储之前,会被 SQLite 根据每个字段的 Type Affinity 转换成相应的类型。
这也就是为什么我们给 INTEGER 字段插入一个字符串值能够成功,并且实际存储的类型也正确的原因了。
让我们再进一步思考一下,看看另外一个 insert 语句:
这次更加奔放,前面那条 insert 语句我们虽然给 id 插入的是字符串,但好歹还是 `2` 这个能有意义的转换成整数的字符串。 这次我们插入的是 `text`。 那么这条语句能不能被执行成功呢?
执行一下,居然也成功了。我们再用 typeof 来验证一下看看:
可以看到,这条记录中 id 字段的实际类型是 TEXT。 尽管 id 的 Type Affinity 是 INTEGER。 但正如我们前面说的, Type Affinity 只是推荐,不是必须。每条数据最终的 Storage Class 是动态的。
比如我们这条插入语句,我们给 id 插入了一个字符串 text, SQLite 会根据 id 的 Type Affinity 尝试将这个字符串转换成 INTEGER 类型。但很明显,转换不能成功,所以这个数据就原样的存储进来了。所以它的类型也没有被转换,依然是 TEXT。
这个例子是对 SQLite 动态类型机制一个很好的解释,你可以给字段指定 Type Affinity。 但即使你指定了 Type Affinity,也不能强制这个字段的存储类型。
结束
这篇文章对 SQLite 数据类型机制给大家做了比较明确的解释,并通过 DB Browser 的几个实践操作验证了 SQLite 类型机制的运作过程。内容不算特别高深,只求一篇内容能帮你解决某一个具体类型的问题,日积月累作用就会明显。看完这个后,应该会对你下次使用 SQLite 的时候有所帮助。你在写 SQL 或者用工具的时候,带着这个思维模式一定会做出更加标准的方案。
以上是关于刷新你对 SQLite 的认知 - 数据类型机制的主要内容,如果未能解决你的问题,请参考以下文章