一次 Serverless 架构改造实践:基因样本对比
Posted UCloud技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一次 Serverless 架构改造实践:基因样本对比相关的知识,希望对你有一定的参考价值。
Serverless 是一种新兴的无服务器架构,使用它的时候开发者只需专注于代码,无需关心运维、资源交付或者部署。本文从代码的角度,通过改造一个 Python 程序来帮助读者从侧面理解 Serverless,让应用继承 Serverless 架构的优点。
现有资源:
1. 一个成熟的基因对比算法(Python实现,运行一次的时间花费为 2 秒)
2. 2020 个基因样本文件(每个文件的大小为 2M,可以直接作为算法的输入)
3. 一台 8 核心云主机
基因检测服务
我们使用上面的资源来对比两个人的基因样本并 print 对比结果(如:有直系血缘关系的概率)。
我们构造目录结构如下:
├── relation.py
└── samples
├── one.sample
└── two.sample
relations.py 代码如下:
import sys
def relationship_algorithm(human_sample_one, human_sample_two):
# it's a secret
return result
if __name__ == "__main__":
length = len(sys.argv)
# sys.argv is a list, the first element always be the script's name
if length != 3:
sys.stderr.write("Need two samples")
else:
# read the first sample
with open(sys.argv[1], "r") as sample_one:
sample_one_list = sample_one.readlines() # read the second sample
with open(sys.argv[2], "r") as sample_two:
sample_two_list = sample_two.readlines() # run the algorithm
print relationship_algirithm(sample_one_list, sample_two_list)
使用方法如下:
➜ python relation.py ./samples/one.sample ./samples/two.sample
➜ 0.054
流程比较简单,从本地磁盘读取两个代表基因序列的文件,经过算法计算,最后返回结果。
我们接到了如下业务需求:
假设我们有 2000 人寻找自己的孩子,20 人寻找自己的父亲。
首先收集唾液样本经过专业仪器分析后,然后生成样本文件并上传到我们的主机上,一共 2020 个样本文件,最后我们需要运行上面的算法。
2000 * 20 = 40000(次)
才可完成需求,我们计算一下总花费的时间:
40000(次) * 2(秒)= 80000 (秒)80000(秒)/ 60.0 / 24 ≈ 56(天)
串行需要花费55天才能算完,太慢了,不过我们的机器是 8 核心的,开 8 个进程一起算:
56 / 8 ≈ 7(天)
也要 7 天,还是太慢,假设 8 核算力已经到极限了,接下来如何优化呢?
介绍一种Serverless产品:UGC
UGC: UCloud General Compute(通用计算)
与 AWS 的 lambda 不同,UGC 允许你将计算密集型算法封装为 Docker Image (后文统称为「算法镜像」),只需将算法镜像 push 到特定的镜像仓库中,UGC 会将算法镜像预先 pull 到一部分计算节点上,当你使用以下两种形式:
1.算法镜像的名字和一些验证信息通过 querystring 的形式 (例如:http://api.ugc.service.ucloud.cn?ImageName=relation&AccessToken=!Q@W#E)
2.算法镜像所需的数据通过 HTTP body 的形式
特别构造的 HTTP 请求发送到 UGC 的 API 服务时,「任务调度器」会帮你挑选已经 pull 成功算法镜像的节点,并将请求调度过去。然后启动此算法镜像「容器」将此请求的 HTTP body 以标准输入 stdin 的形式传到容器中。
经过算法计算,再把算法的标准输出 stdout 和标准错误 stderr 打成一个 tar 包,以 HTTP body 的形式经过「调度器」返回给你,你只需要把返回的 body 当做 tar 包来解压即可得到本次算法运行的结果。
讲了这么多,这个产品使你可以把密集的计算放到了数万的计算节点上,而不是我们小小的 8 核心机器,有数万核心可供使用。那么如何使用如此牛逼的架构呢,这里就需要对程序进行小小的改造了。
针对此 Serverless 架构的改造
两部分:
1.改造算法中元数据从「文件输入」改为「标准输入」,输出改为「标准输出」。
2.开发客户端构造 HTTP 请求,并提高并发。
01
改造算法输入输出
① 改造输入为 stdin
cat ./samples/one.sample ./samples/two.sample
| python relation.py
这样把内容通过管道交给 relation.py 的 stdin ,然后在 relation.py 中通过以下方式拿到:
import sys
mystdin = sys.stdin.read()
# 这里的 mystdin 包含 ./samples/one.sample ./samples/two.sample 的全部内容,无分隔,实际使用可以自己设定分隔符来拆分。
② 将算法的输出数据写入 stdout
# 把标准输入拆分回两个 sample
sample_one, sample_two = separate(mystdin)
# 改造算法的输出为 stdout
def relationship_algorithm(sample_one,
sample_two)
# 改造前
return result
# 改造后
sys.stdout.write(result)
到此就改造完了,很快吧!
02
客户端与开发
构造 HTTP 请求并读取返回结果:
imageName =
"cn-bj2.ugchub.service.ucloud.cn/testbucket
/relationship:0.1"
token = tokenManager.getToken()
# SDK 有现成的
# summitTask 构造 HTTP 请求并将镜像的 STDOUT 打成 tar 包返回
response = submitTask(imageName, token, data)
它也支持异步请求。之前提到,此 Serverless 产品会将算法的标准输出打成 tar 包放到 HTTP body 中返回给客户端,所以我们准备此解包函数:
import tarfile
import io
def untar(data):
tar = tarfile.open(fileobj=io.BytesIO(data))
for member in tar.getmembers():
f = tar.extractfile(member)
with open('result.txt','a') as resultf:
strs = f.read()
resultf.write(strs)
解开 tar 包,并将结果写入 result.txt 文件。
假设我们 2200 个样本文件的绝对路径列表可以通过 get_sample_list 方法拿到:
sample_2000_list,
sample_20_list = get_sample_list()
计算 2000 个样本与 20 个样本的笛卡尔积,我们可以直接使用 itertools.product:
import itertools
all = list(itertools.product(sample_2000_list, sample_20_list))
assert len(all) == 40000
结合上面的代码段,我们封装一个方法:
def worker(two_file_tuple):
sample_one_dir, sample_two_dir = two_file_tuple with open(sample_one_dir) as onef:
one_data = onef.read()
with open(samle_two_dir) as twof:
two_data = twof.read()
data = one_data + two_data
response = summitTask(imageName, token, data)
untar(response)
因为构造 HTTP 请求提交是 I/O 密集型而非计算密集型,所以我们使用协程池处理是非常高效的:
import gevent.pool
import gevent.monkey
gevent.monkey.patch_all() # 猴子补丁
pool = gevent.pool.Pool(200)
pool.map(worker, all)
只是提交任务 200 并发很轻松,全部改造完成,我们来简单分析一下:之前是 8 个进程跑计算密集型算法,现在我们把计算密集型算法放到了 Serverless 产品中,因为客户端是 I/O 密集型的,单机使用协程可以开很高的并发,我们不贪心,按 200 并发来算:
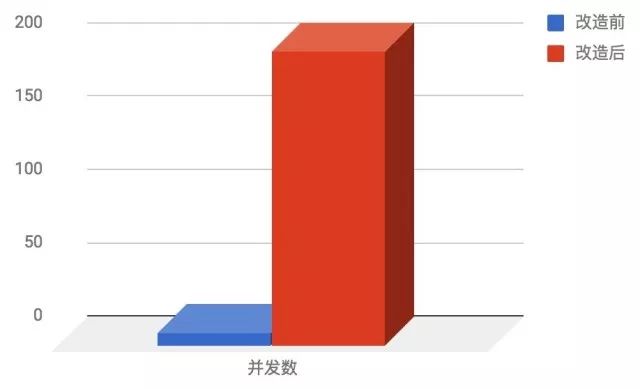
进阶阅读:上面这种情况下带宽反而有可能成为瓶颈,我们可以使用 gzip 来压缩 HTTP body,这是一个计算比较密集的操作,为了 8 核心算力的高效利用,可以将样本数据分为 8 份,启动 8 个进程,进程中再使用协程去提交任务就好了。
40000 * 2 = 80000(秒)
80000 / 200 = 400(秒)
也就是说进行一组检测只需要 400 秒,从之前的 7 天提高到 400 秒,成果斐然。图表更直观:
而且算力瓶颈还远未达到,任务提交的并发数还可以提升,再给我们一台机器提交任务,便可以缩短到 200 秒,4 台 100 秒,8 台 50 秒...
最重要的是改造后的架构还继承了 Serverless 架构的优点:免运维、高可用、按需付费、发布容易。
1.免运维 -- 因为你没有服务器了...
2.高可用 -- Serverless 服务一般依托云计算的强大基础设施,任何模块都不会只有单点,都尽可能做到跨可用区,或者跨交换机容灾,而且本次使用的服务有一个有趣的机制:同一个任务,你提交一次,会被多个节点执行,如果一个计算节点挂了,其他节点还可以正常返回,哪个先执行完,先返回哪个。
3.按需付费 -- 文中说每个算法执行一次花费单核心 CPU 时间 2 秒,我们直接算一下花费:
2000 * 20 * 2 = 80000(秒)
80000 / 60 / 24.0 = 55.5556(小时)
55.5556(小时) * 0.09(元) * 1(核心) ~
= 5(元)
每核时 0.09 元(即单核心 CPU 时间 1 小时,计费 9 分钱)。
4.发布简单 -- 因为使用 Docker 作为载体,所以它是语言无关的,而且发布也很快,代码写好直接上传镜像就好了,至于灰度,客户端 imageName 指定不同版本即可区分不同代码了。
— END —
更
多
精
彩
请猛戳右边二维码
ucloud_tech
点击下方“阅读原文”,查看UGC产品详情!
以上是关于一次 Serverless 架构改造实践:基因样本对比的主要内容,如果未能解决你的问题,请参考以下文章