如何在阿里云数加平台实践Serverless架构?
Posted 阿里云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在阿里云数加平台实践Serverless架构?相关的知识,希望对你有一定的参考价值。
导读
移动互联网、物联网和大数据应用的快速发展极大地促进了人们对云计算的需求。
但是让应用架构拥有良好的可伸缩性和高可用性并非易事,运维和管控庞大的基础架构更是极大的挑战。
近年来,一个新的架构风格Serverless成了热门话题。
What is Serverless

Serverless是一种基于互联网的技术架构理念。
采用FAAS(Function as a Service)架构,通过功能组合来实现应用程序逻辑。
该架构能够让开发者在构建应用的过程中无需关注计算资源的获取和运维,由平台来按需分配计算资源并保证应用执行的SLA,按照调用次数进行计费,有效的节省应用成本。
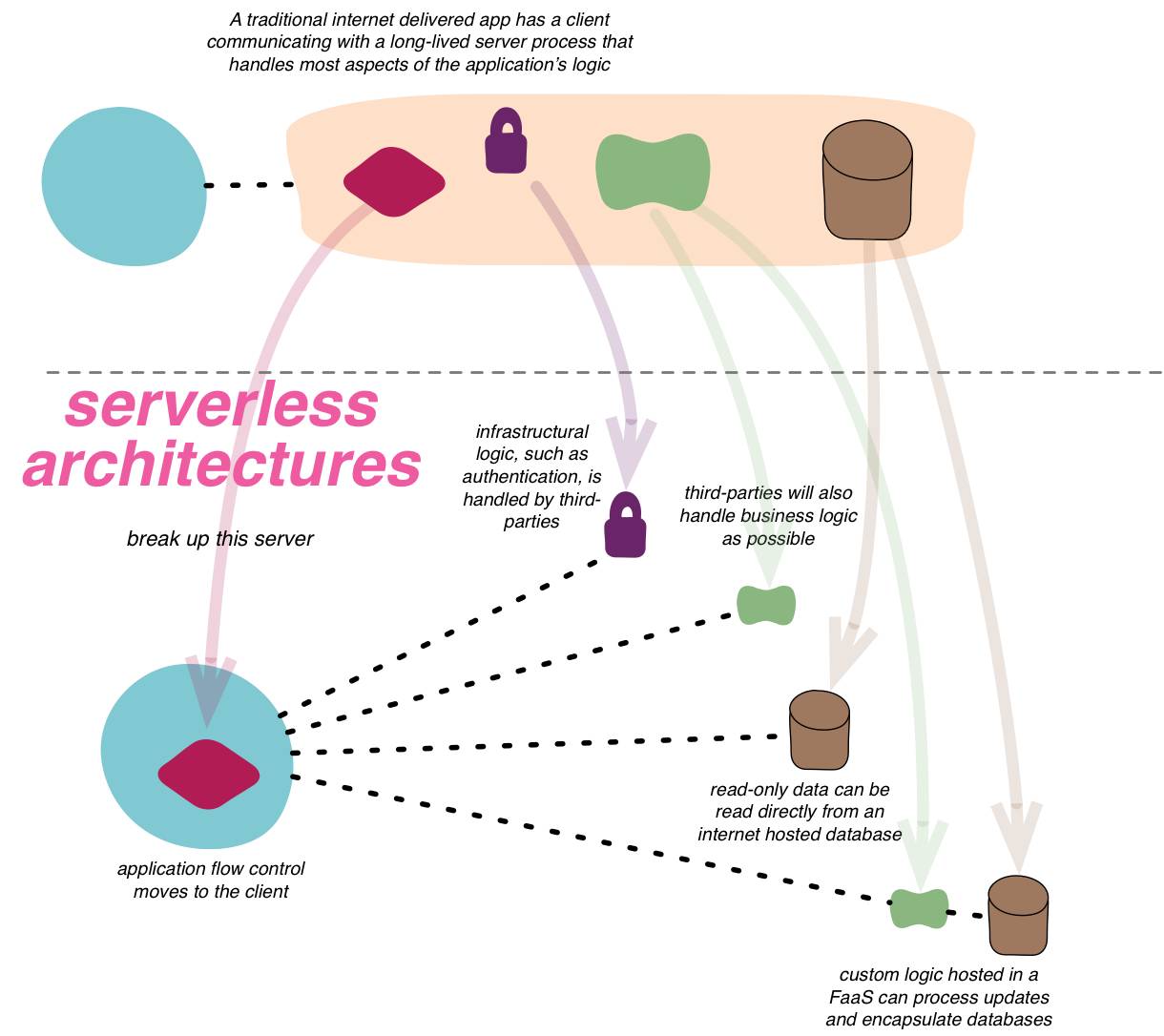
Serverless与传统架构的异同
传统的互联网应用主要采用C/S架构,服务器端需长期维持业务进程来处理客户端请求。
Serverless架构中,应用程序将基于FAAS架构形成多个相互独立的功能组件,并以API服务的形式提供给用户。
同时,服务器端无需长期维持业务进程,业务代码仅在调用时才激活运行,当响应结束占用资源便会释放。
Serverless的优势
节约使用成本
服务根据用户的调用次数进行计费,节省了使用成本。
同时,用户能够通过共享网络、硬盘、CPU等计算资源,在业务高峰期通过弹性扩容方式有效的应对业务峰值,在业务波谷期将资源分享给其他用户。
简化设备运维
开发人员面对的将是第三方开发或自定义的API 和URL,底层硬件对于开发人员透明化了,技术团队无需再关注运维工作,能够更加专注于应用系统开发
提升可维护性
Serverless架构中,应用程序将调用多种第三方功能服务,组成最终的应用逻辑。
例如登陆鉴权服务,云数据库服务等第三方服务在安全性、可用性、性能方面都进行了大量优化,开发团队直接集成第三方的服务,能够有效的降低开发成本,同时使得应用的运维过程变得更加清晰,有效的提升了应用的可维护性。
为什么Serverless适合大数据业务
大数据应用相比流程性的应用有以下特点:
流程长,从采集,存储,清洗,关联,到分析挖掘,直到变成数据服务
逻辑复杂,大数据的价值就是要关联非常多的维度来分析
不确定性强,数据的应用很多都是探索性质的
技术体系复杂,不存在一个通用的引擎可以解决所有大数据的场景,离线处理,流式处理,在线分析需要使用不同的引擎来支持
为了更好的应对大数据场景下的特点,阿里云的大数据平台——数加平台提供了一些列的Serverless服务,使得数据科学家无需陷入到复杂的底层构建和运维的细节,提升了数据分析的效率。
从用户视角来看,数加平台输入的是数据,中间是数加平台提供的serverless服务,最终得到的结果是智慧的服务。 数加平台从底层将整个数据应用的链条全部打通,并提供了一系列的Serverless 服务,从数据采集,存储,各种处理,到最终变成数据服务。
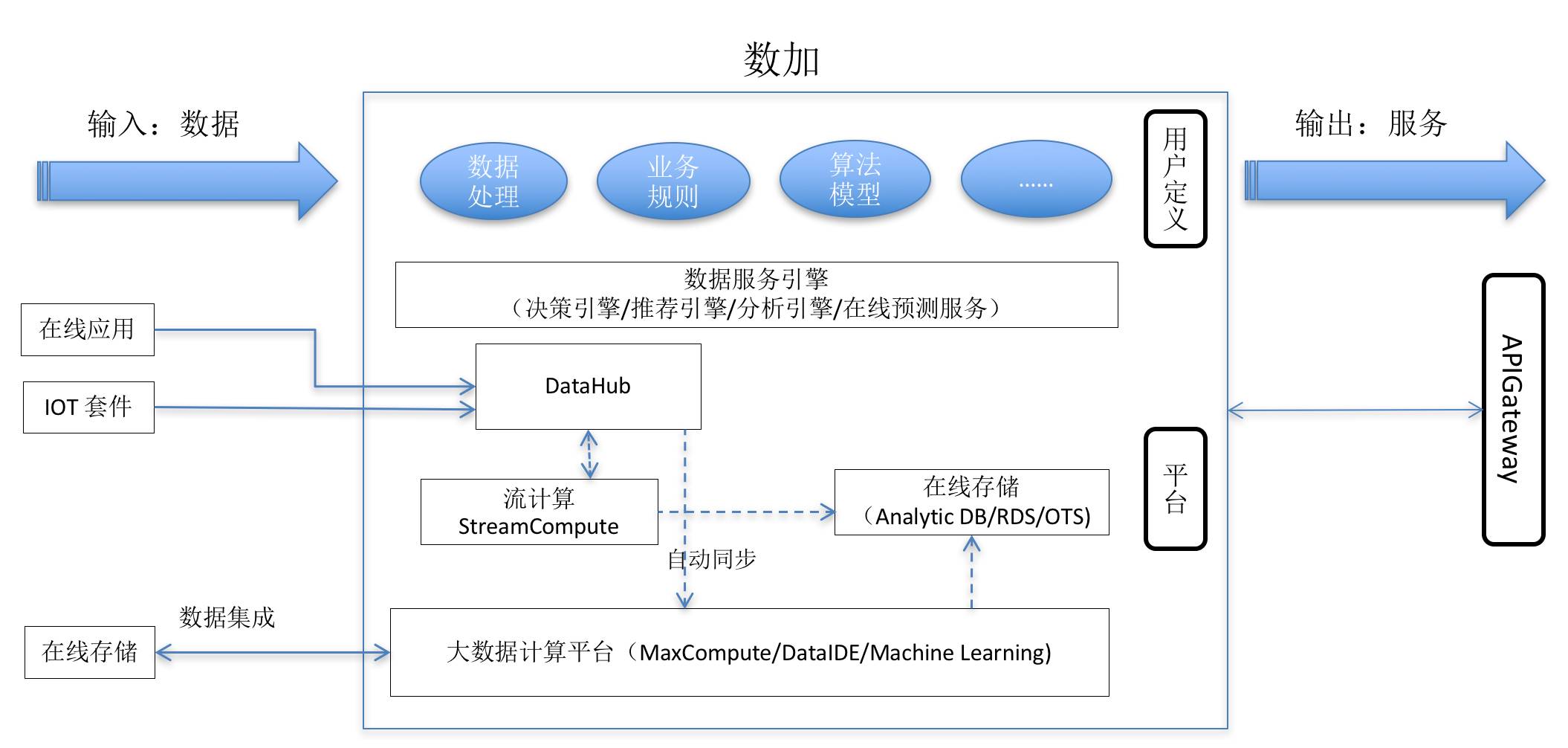
用户需要做的是开发、配置业务相关的处理逻辑、业务规则和算法等,把所有精力关注在数据价值的实现上,而不用关心底层技术和运维层面的架构,也不用关心系统资源管理等。
典型场景
数据分析服务化
按需组合使用各类Serverless 的服务,将多种数据源集成,清洗转换,关联分析,并以可视化的方式展现数据的洞察。过程中不用关心任何的物理架构,也不用关心各种工具的集成。
数据服务化
指将已有的数据通过Serverless的方式(如API化)提供给使用者,常见的有:气象数据获取,根据地理位置获取对应位置的地点信息,图像识别(指能识别出特定的图片信息),特征新闻抓取服务等。
算法服务化
主要是将输入的数据根据特定的算法进行提炼和运算,然后将结果输出,如人脸特征值提取,基因计算,图像渲染等。
开发者无需考虑计算资源,只需将计算代码托管到大数据平台或者通过API接口调用大数据计算服务,由服务商提供计算资源的调度,监控和维护工作,能极大的降低运维工作量,同时具有更好的资源弹性伸缩能力。
经典实践之智慧水务
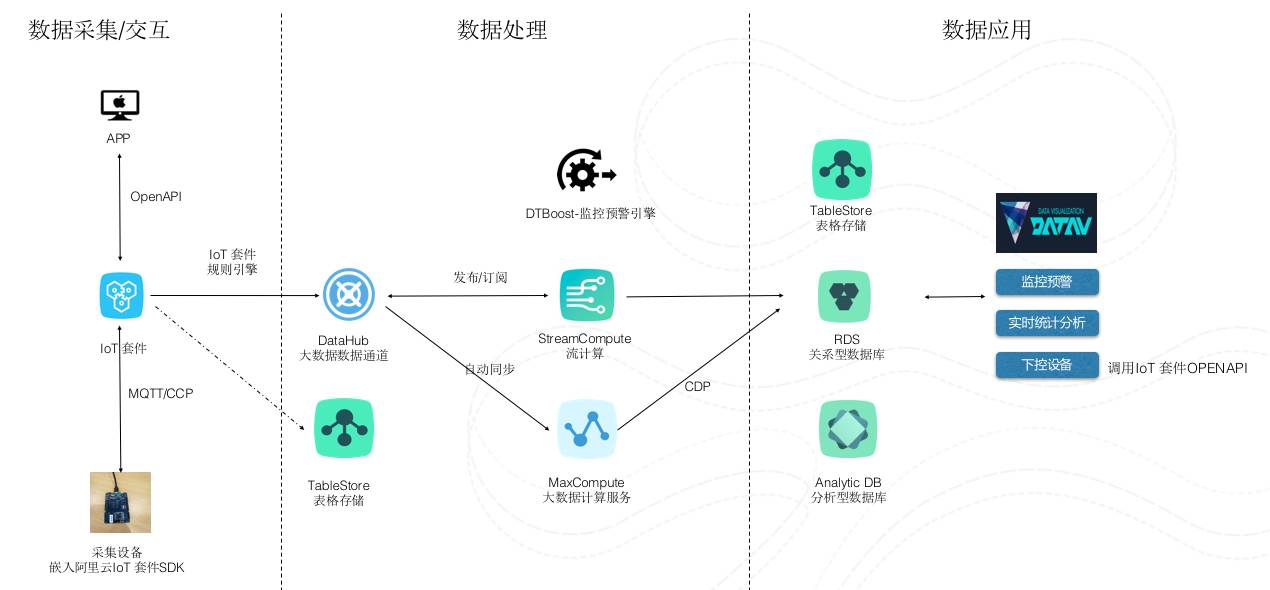
整体架构图
利用IoT 套件采集设备数据,通过简单的配置即可将数据实时对接到大数据平台的DataHub.驱动以下典型的计算场景。
在流计算中自定义SQL 对这些数据做实时的汇总统计,比如流量的统计
在规则引擎中配置业务规则,通过这些规则对数据进行实时分析,判断设备的状态
在规则引擎中配置异常检测的算法对设备状态进行预测,或者利用时间序列算法对管网运行状态进行预测,底层会应用到Maxcompute 对历史数据进行分析,产出的模型对接到StreamCompute,进而对新产生的数据进行实时预测
这个案例里面,利用到了大量的大数据的能力,离线存储和计算,流式计算,机器学习模型训练,数据可视化等等,但对使用者来说,需要做的是流计算SQL 的开发,以及业务规则的配置,以及偏业务算法参数的配置。
而不用去管底层的平台要如何搭建,不同引擎之间的数据如何流转,以及系统的扩展性,稳定性,更不用关心要准备多少的物理资源。
最后最精彩
想要了解更多Serverless方面的资讯,欢迎大家关注2016杭州·云栖大会。
Serverless是当今架构领域最火的话题之一,因为它又一次大幅提升了用户的资源效用效率,降低了管理成本,让DevOps成为真正的事实。
阿里云在Serverless方面提供了哪些能力,未来会怎么发展,10月16日上午Serverless分论坛为您一一揭晓。
目前,大会主场已开放报名。
2016杭州·云栖大会的主题是“飞天·进化 ”。
和去年相比,大会从原本2天的议程增加至4天,从10月13日持续到16日。
点击阅读原文进入报名绿色通道。
以上是关于如何在阿里云数加平台实践Serverless架构?的主要内容,如果未能解决你的问题,请参考以下文章