第1890期看懂 Serverless SSR,这一篇就够了!
Posted 前端早读课
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第1890期看懂 Serverless SSR,这一篇就够了!相关的知识,希望对你有一定的参考价值。
前言
有点长。今日早读文章由@王俊杰,@王天云翻译,@江流授权分享。
正文从这开始~~
了解我们如何为每个Webiny网站获得出色的SEO支持,以及如何在无服务器环境中使用SSR使其超快运行。
内容概要
我确实意识到这是一篇很长的文章,请相信我不是故意写的很长。据我了解,有些人可能没有时间通篇读完,下面我准备了一个简短的内容概要:
单页应用程序(SPAs)很酷,但不幸的是,对SEO的支持不佳。
查阅这篇文章,了解有关在Web上进行渲染的不同方法,然后选择最适合您的用例的方法。
用Webiny构建的应用程序,我们尝试了“按需预渲染”(使用chrome-aws-lambda)和“服务端渲染与激活” 。
只需几个无服务器服务就可以在AWS云中实现这两种方法,他们是S3、Lambda、API网关和CloudFront。
就用户体验方面,如果初始加载屏幕(在应用程序初始化时显示)不是问题,并且搜索引擎优化是您唯一关心的问题,则按需进行预渲染是一种很好的方法,否则可以使用服务器端渲染和激活。
将更多的RAM(1600MB +)分配给实际上将进行预渲染的Lambda函数,并将最小的RAM分配给仅用于服务静态文件的RAM(128MB或256MB)。
尽管我们没有尝试过,但是您可能需要对预渲染的内容进行某种形式的缓存,以便通过更快地返回初始来获得更好的SEO结果。
在使用服务端渲染与激活时,为生成SSR html的Lambda函数分配更多的RAM.
通常,SSR是一项资源密集型任务,它会阻止您足够快地为网站提供服务,因此您很可能需要实现某种缓存
我们使用CloudFront 来缓存SSR HTML,并根据您所构建的应用程序,在短期和长期缓存TTL之间进行选择
如果要使用长期缓存,需要处理缓存失效的情况,这个会有点棘手。
有选择地进行缓存失效,或者说,如果可能的话,仅对必要的页面进行缓存失效–这样可以为您节省大量资金(缓存失效请求由CloudFront收取)
如果内容更改非常频繁,请使用短期缓存TTL,因为这样更有效。
好消息是,使用Webiny,上面提到的都可以处理并定期更新维护一些方法,如果您觉得不错的话,可以经常来Webiny查阅。
这就是内容概要的全部内容了,如果您想更深入地研究该主题,或者只是想看看我们尝试过的无服务器方法和实现成果,我建议您继续往下看。
Serverless Side Rendering
在Webiny,我们的使命是创建一个平台,使开发人员能够构建无服务器应用程序。换句话说,我们希望为开发人员提供适当的工具和流程,以便使用无服务器技术的开发更加轻松,高效和愉悦。最重要的是,我们还希望构建一个包含插件乃至现成应用程序的生态系统,这将进一步减少开发时间和成本。
为了应用程序便于快速开发,Webiny实际上提供了一些基本的应用供开发人员使用,其中之一就是我们的Page Builder应用程序。我不想浪费您的时间,这也不是一篇做广告的文章,我们已经为此工作了相当长的时间(并将继续这样做),尽管面临许多挑战,但无疑,最有趣的挑战之一就是以最佳方式为用户展示页面。换句话说,尽可能快地展示页面,当然,还对搜索引擎优化(SEO)提供了出色的支持。
为了实现上述目标,我们不仅要利用无服务器技术,而且要利用现代的单页应用程序(SPA)方法来构建网站和应用程序。但是事实证明,同时实现和使用所有上述提到的可能有点难度。
SPA很酷,但是它们有一个严重的缺点:SEO支持不好,这是因为它们完全是客户端渲染的,这意味着如果我们不能完全依靠客户端渲染(CSR)来渲染我们的应用程序我们该怎么做呢?在无服务器环境中,我们如何处理服务器“传统上”完成的工作?我们如何实现“无服务器端渲染”?
在本文开始时,我直接放弃讲一些不是那么重要的内容,如果您想要拥有一个现代,快速,可扩展且经过SEO优化的单页应用程序,那么您肯定需要关注这些内容,我会讲我们真正想要为我们的用户提供些什么。
在本文中,我想介绍一下我们尝试几种方法去做,也会讲哪一种方法是最适合我们的解决方案。您会看到没有一个方案能解决所有问题,像灵丹妙药一样,您选择的解决方案将取决于您正在构建的应用程序以及它自身的要求和条件。
由于有很多零散部分要说,为了能给您呈现一个全面的解析,我决定从头开始讲。
首先,让我们谈谈单页应用程序!
Before we begin
单页应用程序, 我们将介绍它们的主要功能,优点/缺点,并且总体上,我们还将讨论Web上的不同渲染方法。如果您是来这里购买严格的无服务器产品的,或者您已经有足够的使用SPA的经验,请跳转至“选择什么?”这个 部分,我们将说明我们决定尝试使用哪种渲染方法,以及如何在无服务器环境中实现它们。
尽管我们确实计划探索其他云提供商,但在Webiny,我们目前主要与AWS合作,因此您将要看到的也是将是针对于AWS的一些实践。但是,如果您不使用AWS,我仍然认为您应该能够阅读本文并使用类似的服务在您的云中构建所有内容。
Single Page Applications
如果您是网络开发人员,那么我很确定您已经熟悉单页应用程序(SPA)的概念。但是,让我们快速了解一下它的一些主要功能和优势。
Client-side Rendering (CSR)
每个SPA的主要功能都是客户端渲染(CSR)。这意味着所有用户界面(HTML)都是在用户浏览器内部生成的,而不是在某种后端(服务器,容器,函数等等… (ツ) /¯)上生成的。最酷的是,不需要整个页面刷新,这意味着当您在应用程序中的其他位置交互操作时,仅这部分页面被重新渲染,而没有刷新整个页面,这样会有更好的体验。
Cleaner code
如果您曾经使用过php,尤其是在过去,那么您可能会记得那些长的Smarty / Twig模板文件,其中包含,CSS,JS,也许是一些if语句,可能是对数据库的一两个调用,以及一些类似的别的什么东西。如果你问我,那真是一团糟。
有了SPA,整个应用程序代码将变得更加整洁。这次我们有两个单独的代码库,一个代表实际的SPA,另一个代表应用程序连接的后端或API。
Easy to serve
SPA易于维护,尤其是在无服务器环境中。创建应用的生产版本后,基本上唯一要做的就是将其上传到您选择的静态文件存储中,例如Amazon S3。而且,如果您希望给您的应用和静态资源提供更快的服务,那么可以将CDN引入到后端体系结构,这种方式也很容易执行。但是,如果您的应用程序依赖于API,值得注意的是,该应用程序将与您的API速度一样快,如果API速度很慢,那么SPA也将变慢,尽管服务速度非常快。
Drawbacks?
如图所示,SPA确实具有很多优点。但是它也有其自身的不足之处,下面我不得不吐槽下它最大的缺点。
每当您创建公开的网站(SPA或非SPA)时,显然都希望拥有链接预览。换句话说,当您分享您的网站链接时,例如 社交媒体网站(如Facebook),您希望获得的是如下图所示的预览:
但是,如果您以前从未使用过SPA,则可能会收到下图的空链接预览,并不是上图完整的链接预览:

没有显示任何内容,仅显示了链接标题和链接描述的纯URL。但是为什么会这样呢??
毫无疑问,您会开始检查代码,很快,您就能看到最初访问您的网站时提供的index.html
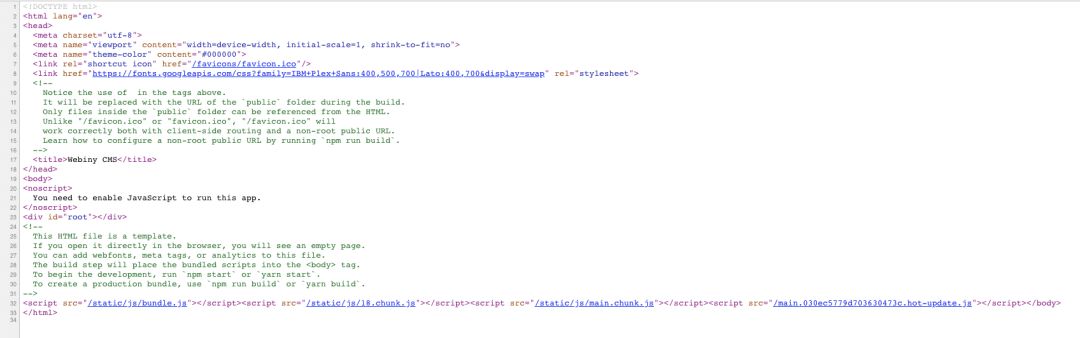
我们可以看到,上面代码中没有太多内容,只有一些基本的HTML标签和一些网站的javascript和CSS文件的链接。这是意料之中的,因为这个初始HTML文档实际上是我们应用程序构建的一部分,也就是说,该文档不是动态生成的,用户每次访问我们的网站时都存在的。
一旦用户在浏览器中输入SPA支持的网站的URL,我粗略地列举下将会出现以下过程:
下载用于SPA初始化的 HTML
下载文件(遇到CSS,JavaScript,图像等)
一旦加载了JavaScript并执行它,这通常意味着SPA初始化开始,获取初始数据,呈现初始UI界面。
但是,当网络抓取工具(例如 Facebook的网络爬虫)访问了该网站,会发生什么呢?
首先是下载初始的SPA HTML,与常规用户不同,网络爬虫不会等到SPA完全初始化,才获取生成的HTML,他们只会分析最初提供给他们的HTML,仅此而已。这就是Facebook的网络爬虫无法生成完整的链接预览的原因,因为初始内容根本没有包含足够的信息。
但是社交媒体网络爬虫并不是唯一的问题,更重要的关于搜索引擎爬虫和SEO
尽管搜索引擎也在寻求可能的解决方案了来应对SPA初始化没有包含足够的信息的问题,但到目前为止,我们仍然不能完全依赖这些解决方案。实际上,我已经看到几个示例,其中介绍了SPA大大降低了SEO质量的结果,例如:
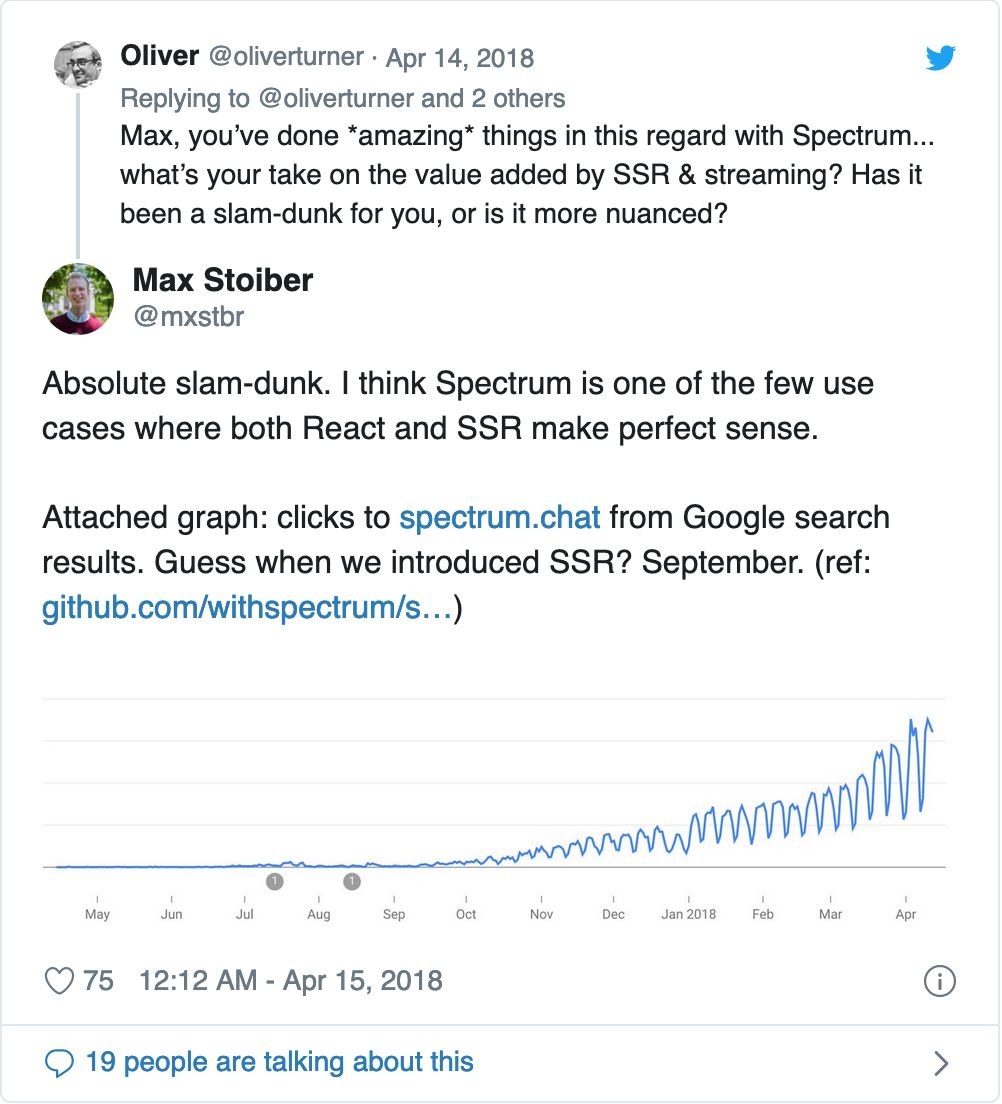
嗨,伙计…想象一下您在一个项目上花费了三个月,在发布之前,您意识到自己根本没有SEO支持。
How to deal with this?
到目前为止,只有一种可靠地解决此问题的方法,那就是为网络爬虫提供有价值的HTML。换句话说,当网络爬虫访问您的网站时,最初提供的HTML必须包含诸如页面标题,适当的meta标记,页面内容(正文)之类的。例如:
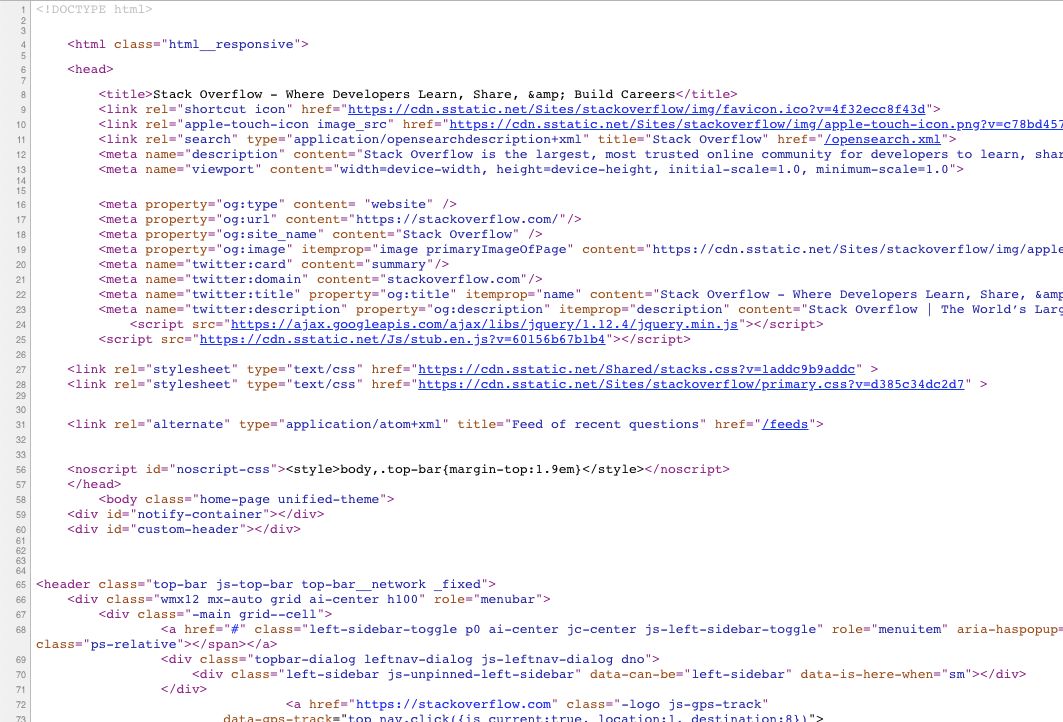
一个HTML文档,其中包含资源链接,必要的meta标签,完整的页面主体等。
但是,实现这一目标的最佳方法是什么?我们是否需要在每个页面请求上动态生成HTML的服务器?还是我们可以使用其他方法?
好吧……这将是我们看的下一个主题:在Web上渲染。
Rendering on the Web
实际上,在web上渲染应用程序有多种方法。,这是Google博客上的一篇文章,我看过好多遍了,写的非常好,它可以帮助您很好地了解不同的渲染方法,并为您提供每种方法的利弊信息。
在本文的结尾,我们可以很好地总结我们今天可以使用的所有渲染方法:

如您所见,摘要中包含了很多有用的信息。让我们快速浏览下每个:
Full CSR
早先我们都知道一种方法,就是后端返回一个简单的HTML,在用户的浏览器中进行应用初始化。这种方法不适合做SEO,但是如果构建网页的时候不需要进行SEO(例如管理员登陆页面),那么它仍然是一种不错的方法。
CSR with Prerendering
如果您曾经与Gatsby一起工作过,则可能对这种方法很熟悉。基本上,一旦我们准备好部署您的网站,便会开始构建过程,该过程会预先生成应用程序的所有页面,然后可以将其上传到静态文件存储中,例如亚马逊S3。
由于构建的页面包含完整的HTML,并且不会动态生成任何内容,因此该应用将以超快的速度提供服务,最重要的是,它将拥有出色的SEO支持。
这种方法的要点是,每当需要进行更改时,即使更改很小,也需要从头开始完全重建所有内容,而在较大的项目上,这可能会花费一些时间。因此,如果您经常进行更改,那么对您来说这可能不是一种超级方便的方法。
Server-side Rendering () with (re)hydration
通过这种方法,我们在服务器端的每个初始页面请求上动态生成HTML。注意这里的“ initial”一词。我们的意思是,服务器端HTML的生成只会在初始页面请求(例如用户在浏览器中输入URL或刷新整个页面时)的时候,有趣的是,在收到初始HTML之后,会初始化完整的CSR SPA,这意味着该时间点的所有HTML都会在用户的浏览器中生成,因此仍然可以创建出色的用户体验。这种方法也称为“同构渲染”。
听起来很不错,但要注意,采用这种方法时,您实际上需要为应用创建两个独立的生产版本,一个仍将在用户浏览器中提供并执行,而另一个将在后端执行以动态生成HTML。创建两个版本的原因是不同的环境,也就是说在NodeJS后端中运行浏览器代码根本行不通(反之亦然)。
尽管有时无法简单地设置SSR,但是一旦学习了一些技巧,您就可以了(设置是,性能完全是另一回事)。使用诸如Next.js之类的框架可以大大节省您的时间。
Last two — Static SSR & Server Rendering
如前所述,静态SSR在构建过程中删除JavaScript,并用于提供纯静态HTML页面。如果您的特定用例可以接受JavaScript删除,则此方法可能对您有用。
最后,一个纯服务器渲染不属于SPA类别,因为它根本不依赖任何客户端渲染。HTML总是从服务器返回,并且在您的应用程序中浏览时,将假定刷新了整个页面,那么,这与我们最先提到的Full CSR完全相反。
What to choose?
上面显示的摘要绝对可以帮助我们选择正确的方法来渲染我们的应用程序。但是我们应该使用哪一个呢?
其实,这取决于您正在构建的应用程序,换句话说,取决于您面前的特定需求。如果您有一个简单的静态网站,那么带有预渲染的CSR绝对是一个不错的选择。另一方面,如果您要创建更具动态性的内容,那么,根据您的SEO需求,您可能要使用SSR渲染与激活或简单的 Full CSR SPA。
因此,对您的应用程序进行快速分析肯定会帮助您选择正确的方法,这正是我们为改进Page Builder应用程序在Webiny所做的。
The Page Builder
下图一目了然地显示了Webiny Page Builder最初的工作方式:
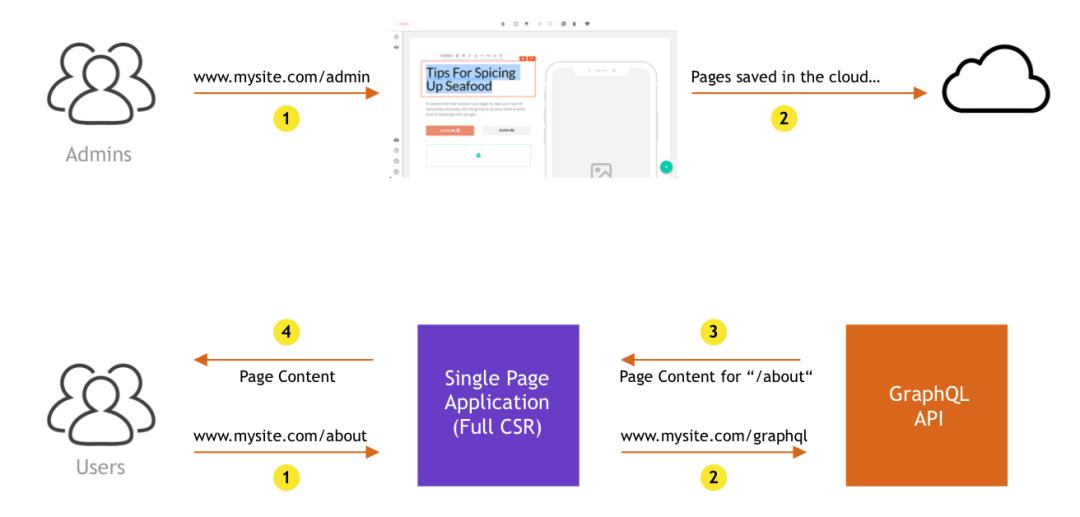
因此,在上方的图中,我们有管理员用户,他们可以通过admin UI创建新页面或编辑现有页面。整个管理界面是一个完整的CSR SPA(使用比较受欢的create-react-app创建),这没有任何问题。
在下图中,我们有一个面向公众的网站和普通用户,我们为他们提供了完整的CSR SPA。这里没有什么超高级的,基本上,一旦应用程序通过GraphQL API初始化,应用程序就会获取需要显示给用户当前URL的内容,并且差不多就可以了。
当然,据我们了解,对于面向公众的应用程序而言,完全CSR方法还不够好,因为公共页面必须具有SEO支持。只是没有更好的办法, 因此,现在可以查阅下Web文档上的“渲染”,并尝试选择最佳的方法。
What we’ve chosen?
因为Page Builder本质上是动态的,这意味着一旦用户单击编辑器中的publish按钮,该页面必须立即上线(并且当然是兼容SEO的),我们选择了第三种方法,即SSR渲染和激活。
但是,因为我们知道当时我们的代码库需要大量更改才能正常工作,所以实际上我们还有一个想法,我们想首先尝试一下这种方法。也就是如果我们可以从后端访问该URL,就像普通用户那样访问该URL,并在Web爬网程序发出请求时将其返回,该怎么办?您知道吗,只需模拟普通用户,等待完整的UI生成,获取最终的HTML,然后就可以使用?对于普通用户而言,什么都不会改变,我们仍然会为他们提供常规的单页面应用,因为实际上,用户并不关心最初从后端收到的HTML(实际上,这确实很重要,在以下各节中将对此进行更多说明)。
我们认为可以这样做,所以我们尝试了一下。我们将这种方法称为“按需呈现”。
因此,总而言之,我们决定尝试以下两种方法:
按需预渲染
SSR(渲染并激活)
让我们看看如何在无服务器环境中实现这些渲染方法,当然,从中可以比较出哪种方法效果更好。
如前所述,请注意,由于我们目前仅与AWS云提供商合作,因此接下来的示例主要是基于AWS来实现。但是,如果您将应用程序托管在任何其他云上,那么我相信您仍然可以使用云提供商提供的类似服务来实现同一目标。
好吧,让我们看看!
Prerendering on demand
为了实现按需预渲染,我们使用了以下AWS服务:

因此,我们使用一个S3 Bucket来托管SPA的生产版本,几个Lambda函数以及最后的API Gateway和CloudFront,以使所有内容在Internet上公开可用并分别启用适当的。
为此,我们还使用了chrome-aws-lambda库,该库基本上是(Headless)浏览器,可以通过编程方式在函数内部进行控制。我们将使用它来访问网络爬虫程序请求的URL,等待单页面应用完全初始化,获取最终生成的HTML,最后将输出返回给网络爬虫程序。
首先,让我们看看普通用户访问网页时会发生什么。
Regular users
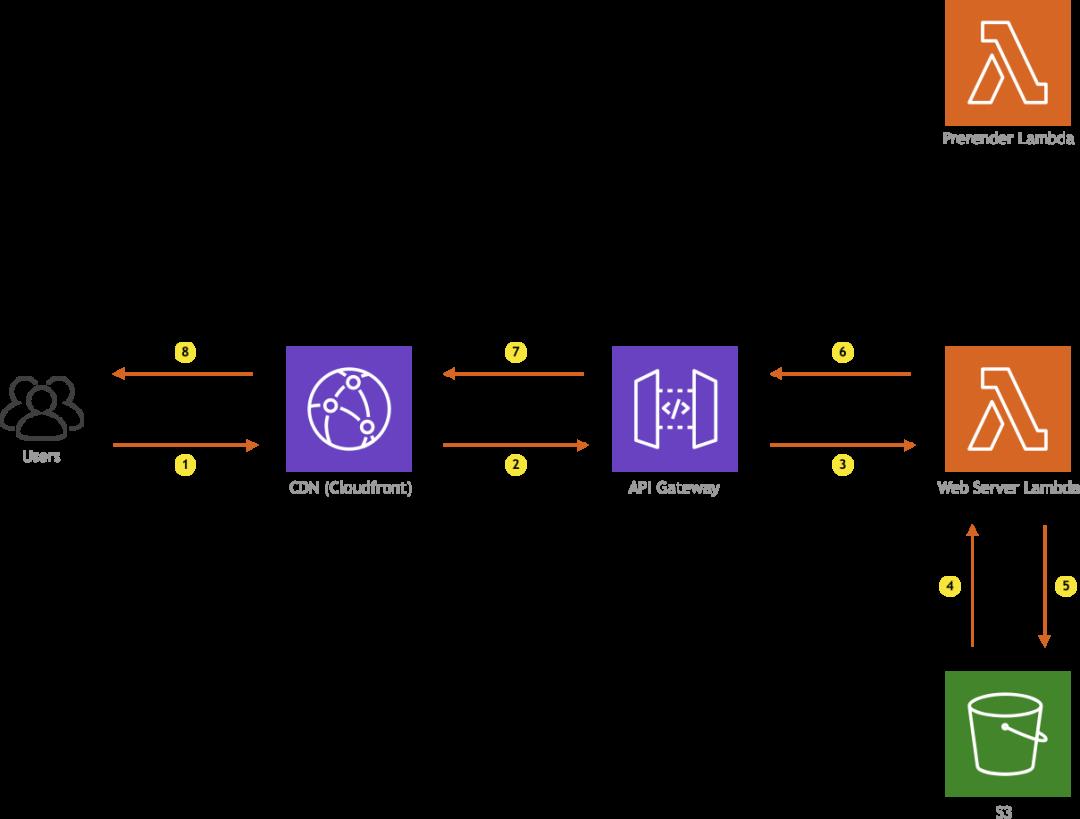
当普通用户访问站点时,HTTP请求将通过CloudFront重定向到API网关,该API网关将调用Web服务器Lambda。我们之所以给它起这个名字是因为,在某种程度上,它实际上起着常规Web服务器的作用,即基于接收到的调用有效负载(HTTP请求),它提供了从S3 bucket中请求的静态资源(JS,CSS,HTML,图像等)。此功能的一些其他作用是,当请求静态资源时发送适当的缓存响应标头,并检测网络爬虫程序,因此我们使用了isisbot软件包。
所以,如果普通用户发出HTTP请求,我们只需从S3 bucket中获取请求的文件,并将其作为调用响应发送回API网关,然后将其返回给CloudFront,就可以返回该文件。
当网络爬虫访问该站点时会发生什么?
Web crawlers
在这种情况下,HTTP请求再次通过CloudFront和API网关到达Web服务器Lambda,但是我们不是从S3提取文件,而是调用Prerender Lambda,它内部使用了上述chrome-aws-lambda库来获取所请求URL的完整的HTML。
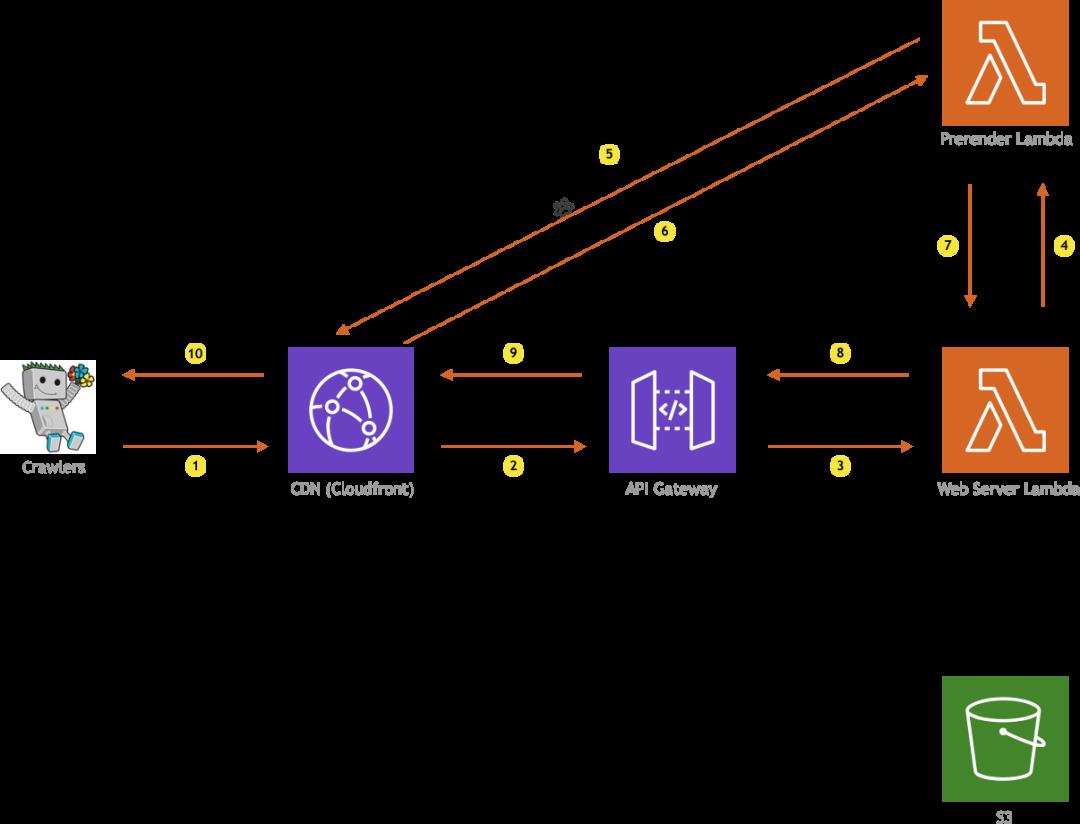
这里有两点需要注意,第一个是chrome-aws-lambda的运行成本可能很高,因为它需要大量资源。图书馆的文档指出,应至少分配512MB的RAM,但建议分配1600MB或更多。这就是为什么我们没有将所有逻辑都放在一个Lambda函数中(放入Web服务器Lambda中)的原因。仅当网络爬虫访问该站点时,Prerender Lambda函数才会被调用,该访问频率比普通用户访问的频率要低。为普通用户提供简单的静态资源,具有基本的128MB或256MB RAM的Lambda函数就足够了,从而为我们节省了一些钱。
我们还有一些有关chrome-aws-lambda库的提示,以某种方式对它进行配置,以免下载不生成DOM的资源(如CSS和图像)。您无需加载这些文件即可获取完整的HTML,这将大大加快HTML的获取过程。
另外,为简化部署,您还可以使用chrome-aws-lambda-layer库,该库基本上使您可以将包含所有必需代码的公共Lambda函数层附加到函数中,这意味着您不必自己上传所有代码(和Chromium二进制文件)。您可以使用Lambda控制台,甚至使用更好的Serverless框架,轻松引用该层。以下serverless.yaml显示了如何执行此操作(请注意preRender函数内部的layers部分):
服务:mySiteService
提供者:
名称:aws
运行时:nodejs 10.x
功能:
preRender:
角色:arn:aws:iam :: 222359618365:role / SOME-ROLE
内存大小:1600
超时:30
层数:
-arn:aws:lambda:us-east-1:764866452798:layer:chrome-aws-lambda:8
处理程序:fns / my-server / index.handler
注意:对于完整的生产环境,您还可以选择自己构建该层,从而为您提供更多的控制权和更好的安全状态。
Results
下图显示了所有优点和缺点:

这里要注意的是,尽管我们设法获得了良好的SEO支持,但不幸的是,我们仍然面临着严重的速度/用户体验问题。
由于用户仍在接收完整的CSR单页面应用,因此在每次请求时,他都必须等待初始化资源(JS和CSS)以及页面数据被加载。当页面加载时,会向用户显示一个加载屏幕,并且用户在每次访问页面时,基本上都会在页面上停留1-3秒,这绝对不是一个很好的用户体验,尤其是我们研究的静态页面。简单的说就是它很慢。
即使我们已经尝试了一些改进的方法,但最终还是无法使它以能够满足我们目标的方式工作,因此放弃了按需渲染的想法。
但是,请注意如果加载屏幕对您的应用程序没有问题,那么这仍然是一种有效的实现方法。我个人喜欢此解决方案,因为与采用服务器端渲染与激活方法不同,此方法更易于维护,因为它不需要构建两个单独的应用程序。
让我们看看我们现在如何使用服务器端渲染与激活方法!
SSR with (re)hydration
对于此实现,我们实际上使用了在按需预渲染实现中相同的服务
但是当然,该图会有所不同:
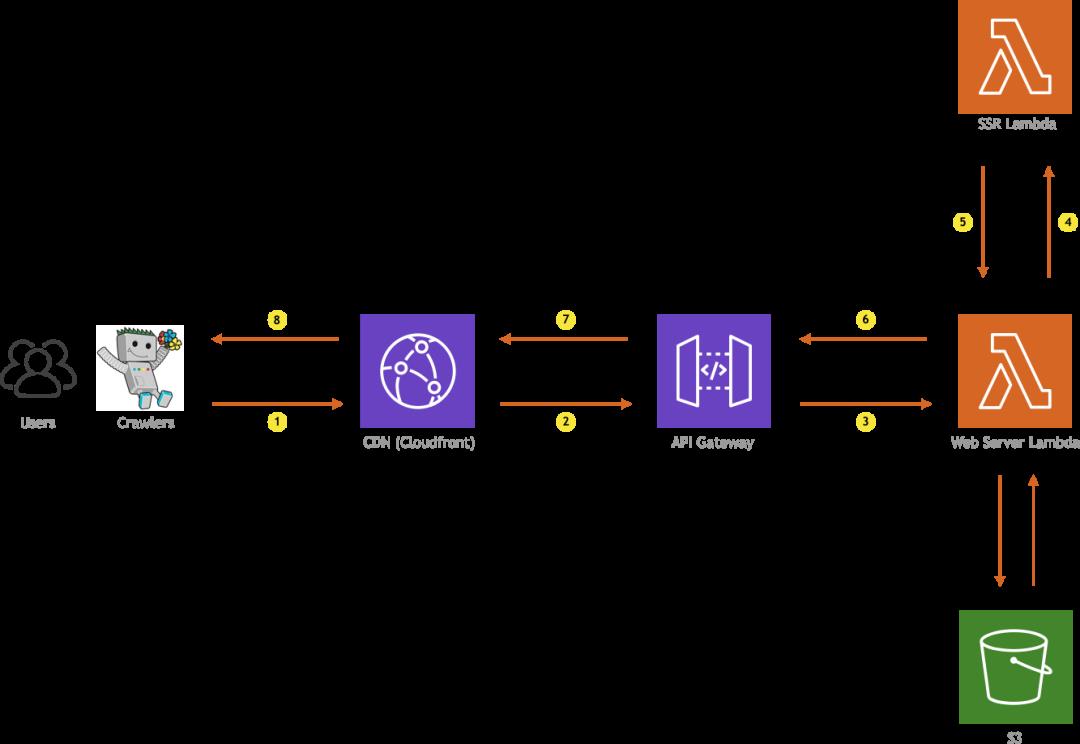
在解释其全部工作原理之前,还记得我们提到服务器渲染与激活方法需要我们构建SPA的两个生产版本吗?一个提供给浏览器并在浏览器中执行,另一个真正在服务器上执行?是的,但是这些应用生产版本将会被存储在哪里呢?
提供给用户浏览器的内部版本与我们先前使用的内部版本没有什么不同,即按需预渲染方法,并且以相同的方式将其存储在一个简单的S3 bucket中。请注意,就像在任何单页面应用版本中一样,此版本不仅包含JavaScript文件,而且还包含CSS文件、图像以及您的网站可能需要的其他静态资源。另一方面,SSR构建不包含所有内容,它仅包含一个JS文件,其中包含最小化的代码,因此,我们决定将其直接捆绑到SSR Lambda中。由于文件大小约为1MB,因此我们认为这可能不是性能问题。好了,回到图上!
这次,用户和网络爬虫的流程是相同的。CloudFront接收HTTP请求并将其转发到API网关,API网关将调用Web服务器Lambda,然后由它决定是必须从S3 bucket中提取文件还是必须调用SSR Lambda。路由很简单,如果请求未指向文件(我们检查文件扩展名是否存在),Web Server Lambda会将请求转发至SSR Lambda,SSR Lambda会生成需要返回给访客的HTML。另一方面,如果请求了静态文件,则将其直接从S3 bucket中提取。如前所述,这与以前看到的按需预渲染方法(普通用户访问该站点)没有什么不同。
那么,这种方法的结果是什么?
Results

有趣的是,即使我们已经通过先前提到的按需预渲染方法解决了SEO兼容性问题,但我们确实也遇到了页面加载速度缓慢问题,这在UX方面可能是非常糟糕的。不幸的是,这和采用服务器渲染与激活方法相比,两者没有什么不同。
使用按需预渲染的方法时,用户必须盯着加载屏幕,直到应用程序完全初始化为止。现在,他们需要再次等待相同的时间,但是这次,他们盯着空白屏幕,等待后端返回服务端渲染的HTML。
您可能会问自己为什么要等呢?好吧,这很合逻辑,这是因为以前在用户浏览器中进行的所有处理(在加载叠加层之后)现在都在后端SSR Lambda函数内部进行。更重要的是,开箱即用的服务器端渲染是一项资源密集型任务,因此生成整个HTML文档需要花费时间。将其与冷启动功能可能会增加的其他延迟配对,可以确保您度过了一段愉快的时光。
当您查看时,由于用户盯着黑屏,而不是我们以前拥有的漂亮的加载叠加,我们实际上已经设法使用户体验变得更糟!
SSR HTML Caching
尽管我们尝试增加SSR Lambda函数的系统资源量,但这仍然没有对整体性能产生足够积极的影响。最后,为了加快处理速度,我们决定引入缓存。我们尝试了许多不同的解决方案,最后,我们解决了如下两个问题:
对于这两者,整个云架构的唯一补充就是数据库,我们将使用该数据库来缓存接收到的SSR HTML。它可以是任何您喜欢的数据库,我们决定使用MongoDB,因为我们已经非常依赖它了。但是,您可以使用DynamoDB或Redis,这些绝对也是不错的选择。
Solution 1— short cache max-age (TTL)
下图几乎与我们在上一节中看到的图一模一样,只不过现在有了一个数据库:
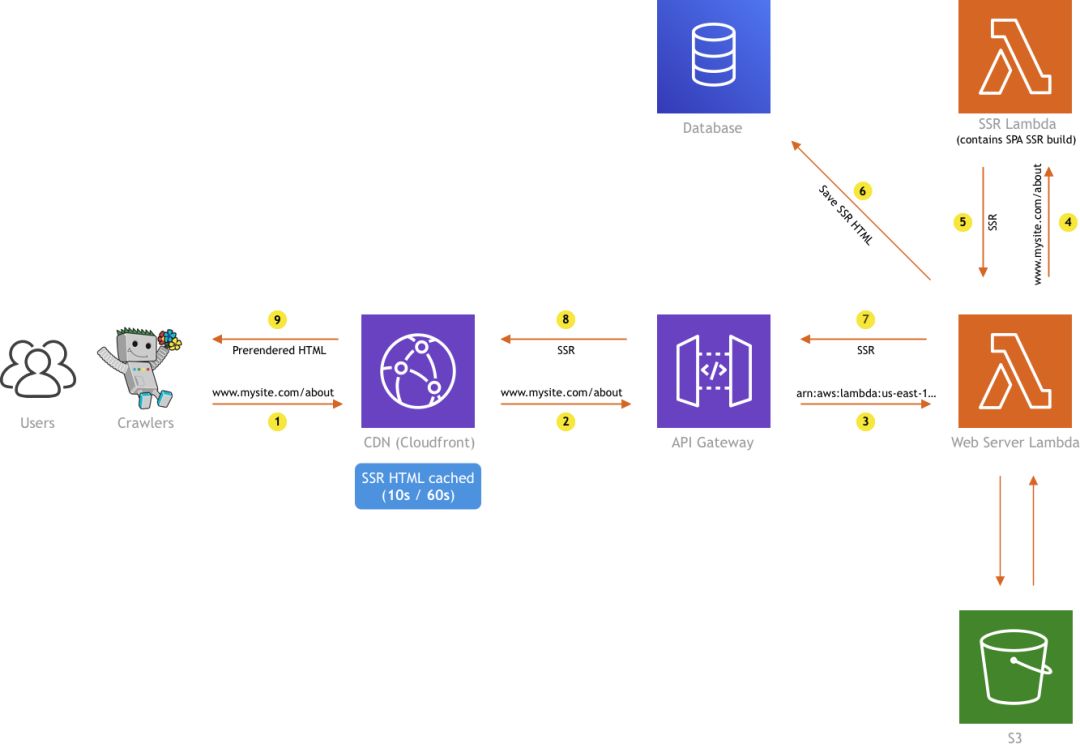
因此,每次Web Server Lambda收到来自SSR Lambda的SSR HTML,在将其返回给API网关之前,我们还将其存储在数据库中。一个简单的数据库条目可能看起来像这样:

因此,一旦将SSR HTML(以及上面片段中显示的其他一些数据)存储在数据库中,我们就将其连同Cache-Control一起发送回API网关:public,max-age = MAXAGE标头,将指示CloudFront CDN将结果缓存MAXAGE秒。
为了获得MAXAGE值,我们使用存储在数据库中的expiresOn(SSR HTML被视为过期的时间点)。由于这是一个日期字符串,并且必须以秒为单位定义MAXAGE,因此我们只计算expiresOn — CURRENTTIME。这里要注意的重要一点是,最初设置expiresOn时,该值将为CURRENTTIME + 60秒。换句话说,calculatedMAX_AGE将为60秒,因此,以下响应标头将返回到CloudFront CDN:控制:public,max-age = 60。
因此,在发出初始请求之后,接下来的60秒内,每次用户在浏览器中点击相同的URL时,由于SSR HTML是从CDN边缘提供的,因此用户基本上会遇到即时响应(〜100ms)。在这种情况下,根本不会调用Lambda函数)。
这太棒了,但是当CDN缓存过期时会发生什么?我们是否还必须等待服务端渲染生成?不需要,在那种情况下,请求将再次到达Web Server Lambda函数,但是现在,我们将立即检查数据库中是否已经存在未过期的缓存SSR HTML,而不是立即调用SSR Lambda。
如果是这样,我们将仅返回接收到的SSR HTML,并再次使用Cache-Control:public,max-age = MAXAGE响应标头。请注意,我们已经使用数据库条目的expiresOn值来再次计算MAXAGE,这次不必是60秒,也可以更短(并且将是)。如果59秒钟前在先前访问者的URL请求之一中将SSR HTML保存到数据库,则甚至可能需要1秒钟。还要注意,如果请求到达的CDN边缘还没有缓存的SSR HTML,则该请求仍会响应Web Server Lambda函数。
另一方面,如果我们确定收到的SSR HTML已过期,我们实际上会执行以下操作:首先开始一个进程,该进程将使用新的SSR HTML和新的expiresOn值更新数据库中的SSR HTML条目,该值等于SSRHTMLREFRESHFINISHEDTIME + 60秒。此过程将以异步方式触发,这意味着我们不会等待它完成,因为如我们所见,获取SSR HTML可能需要一些时间。触发该操作后,我们将立即使用新的expiresOn值将数据库中的同一SSR HTML条目更新为CURRENTTIME + 10秒(请注意短暂的10秒增量)。保存完之后,紧接着,我们将* expired*的SSR HTML返回到API网关,再次使用Cache-Control:public,max-age = MAXAGE标头,仅这次MAX_AGE将为10,这意味着CloudFront CDN只会将此过期的SSR HTML缓存10秒钟。
换句话说,在接下来的10秒钟内,用户将从CloudFront CDN收到SSR HTML的过期版本。之后,缓存将再次过期,并且在那个时间点,我们肯定会准备好要提供的新SSR HTML(在上述异步过程中进行了刷新)。这里唯一需要注意的是,在10秒钟的CDN缓存过期之后,所提供的新鲜SSR HTML的newMAXAGE将取决于从数据库接收到的expiresOn(等于(SSRHTMLREFRESHFINISHEDTIME + 60秒)— CURRENTTIME)。它实际上可以在0s到60s之间,具体取决于10秒钟缓存过期和之后的第一个请求经过了多少时间。如果超过60秒,则该过程将再次重复,这意味着将再次返回10秒的MAX_AGE,并且将触发新的异步SSR HTML刷新过程。
Results
这几乎就是整个流程。从性能角度来看,大多数情况下,用户会在约100毫秒的时间内从浏览器中收到初始HTML。例外情况是CDN缓存已过期,并且需要先从Web服务器Lambda返回SSR HTML,在这种情况下,如果我们要处理冷函数,则延迟可能会跳到200ms(400ms)和800ms(1200ms)。开始。如果你问我,还不错!
另一方面,这种方法的问题之一是,如果数据库中根本没有SSR HTML(甚至没有过期的HTML),那么用户将不得不等待SSR HTML生成过程完成。没有别的办法,因为我们没有任何东西可以返还给用户。这意味着他必须等待1到4秒钟才能返回SSR HTML,如果后台开始冷启动,则还要等待4到7秒钟。
但是请注意,每个网址只会发生一次,因此它并不是很频繁,而且也没什么大不了的。为了减少由冷启动引起的额外延迟,您可以尝试利用最近引入的预配置并发。我必须肯定地说我们没有试过,但是可能值得检查一下是否引起了您的问题。另外,如果可能的话,如果您要避免在用户的实际请求上生成SSR HTML,甚至可以提前请求一些页面。
尽管此方法的一个优点是您不必手动进行任何缓存失效操作(因为缓存会很快过期),但必须注意,API Gateway和Lambda函数将经常被调用,这需要考虑,因为这可能会影响总成本。
这基本上就是为什么我们开始思考如何避免API网关和Lambda函数调用以及如何将尽可能多的流量卸载到CDN的原因。首先想到的是较长的MAX_AGE值。
Solution2— long cache max-age (TTL)
此解决方案的体系结构保持不变。
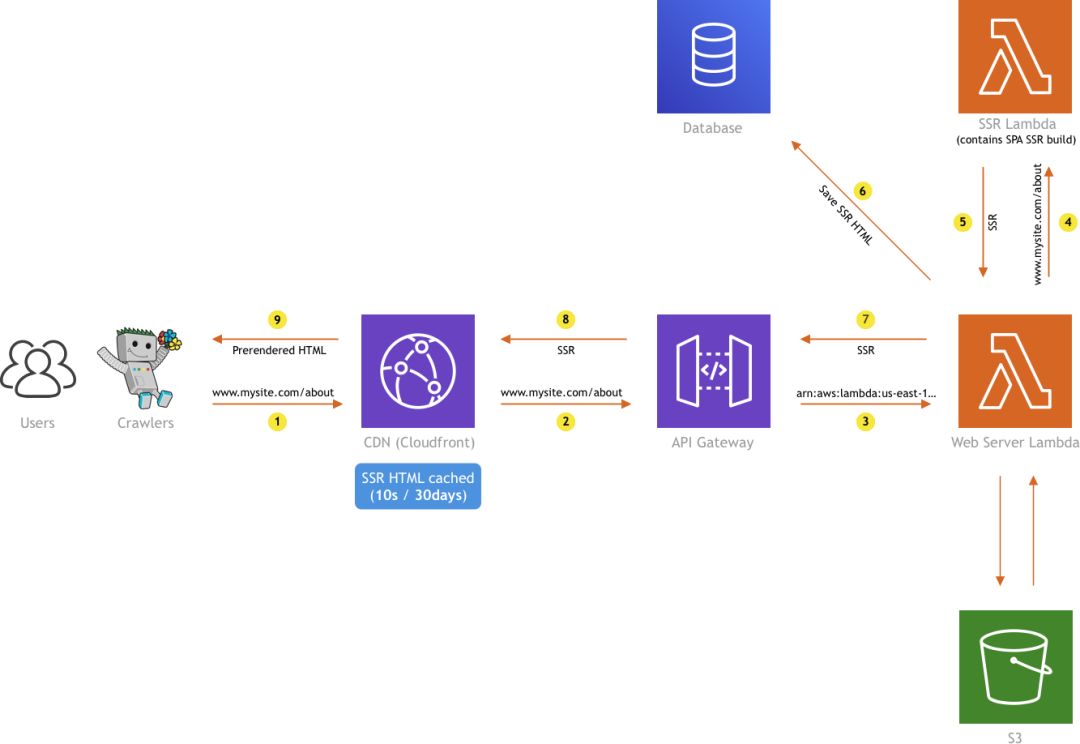
因此,用户将尽可能从CDN接收SSR HTML。否则,Web服务器Lambda将由API网关调用,并且将直接从数据库中或通过现场生成SSR HTML来返回(如图所示,当SSR HTML不存在时,甚至不存在过期的HTML时,都会发生这种情况)。
如上所述,唯一的区别是,我们在响应标头中发送的MAX_AGE值要长得多,例如一个月(缓存控制:public, max-age=2592000)。请注意,如果请求到达Web服务器Lambda,并且我们确定数据库中有过期的SSR HTML缓存,我们仍将使用简短的Cache-Control进行响应:public,max-age = 10response标头。这没有改变。
使用这种方法,我们可以更少地调用Lambda函数,因为在大多数情况下,用户会遇到CDN,这意味着用户不会经历太多的冷启动延迟,而且我们也可以少担心Lambda函数会生成很多费用。完美!
但是现在我们必须考虑缓存失效。我们如何告诉CloudFront CDN清除其拥有的SSR HTML,以便可以从Web服务器Lambda中获取一个新的HTML?例如,当管理员通过“页面构建器”对现有页面进行更改并发布时,这种情况经常发生。
当您考虑它时,它应该很简单,对吧?每次管理员用户对现有页面进行更改并发布时,我们都可以通过编程方式使页面URL的缓存无效,就是这样吗?
好吧,实际上,这只是完整解决方案的一部分。我们还有其他一些关键事件,应使CDN缓存无效。
例如,我们的Page Builder应用程序支持许多不同的页面元素,您可以将它们拖动到页面上,其中之一是可让您从Form Builder应用程序中嵌入表单的元素。因此,您可以在页面上添加表单,发布页面,一切都很好。但是,如果有人在实际表单上进行了更改,例如,添加了其他字段怎么办?如果发生这种情况,站点用户必须能够看到这些更改(SSR HTML必须包含这些更改)。因此,“仅仅在页面上发布无效”的想法在这里还不够。
但是还有更多!假设管理员用户对网站的主菜单进行了更改。由于基本上可以在每个页面上看到菜单,这是否意味着我们应该使包含该菜单的所有页面的缓存无效?好吧,很不幸,但是,没有别的办法了。在我们这样做之前,我们应该了解有关缓存无效定价的任何信息吗?
要的,对于较小的站点,包含菜单的页面总数可以从10到20页不等,但是对于较大的站点,我们可以轻松拥有数百甚至数千页!因此,这可能迫使我们向CDN创建许多缓存无效请求,如果您查看CloudFront的定价页面,我们会发现这些请求并不便宜:每月要求无效的前1,000条路径不会收取额外费用。此后,请求无效的每个路径$ 0.005。
正如我们所看到的,如果我们要实现基本的“只是使包含菜单的所有页面失效”逻辑,我们可能会很快脱离免费层,并且基本上开始为每进行1000次失效支付5美元。这不友好。
因此,我们开始考虑替代性想法,并提出了以下建议。
如果菜单发生更改,请不要使包含该菜单的所有页面的缓存都失效。相反,让我们检查一下是否只有在实际访问时才需要使页面无效。因此,每次用户访问页面时,我们都会发出一个简单的HTTP请求(异步触发,因此不会影响页面性能),该调用将调用Lambda函数,该函数通过以下方法检查CDN缓存是否需要无效:检查存储在数据库中的SSR HTML是否已过期,是因为自生成以来已经经过了足够的时间,还是在一个关键事件中将其简单地标记为已过期(例如,菜单已更新或页面已发布)。如果是的话,它将仅获取新的SSR HTML并将无效请求发送到CDN。
同时,有以下几点需要注意:
首先,对于每次页面访问,我们都会调用Lambda函数。但是,我们尝试使用这种更长的最大寿命(TTL)方法的原因之一是为在实践中避免了这种情况。不幸的是,这是不可避免的。但幸运的是,您可以通过较少地触发此检查来减少调用次数。一分钟,五分钟甚至十分钟触发一次,选择最适合您的触发次数即可。
其次,使CDN缓存无效会花费一些时间,因此,新的SSR HTML会在5秒到5分钟甚至更晚的时间内到达,具体取决于CDN的当前状态。在大多数情况下,这会非常快,这就是我们所经历的平均5-10秒。
Trigger invalidation selectively with custom HTML tags
可以看出,我们看到的“菜单更改”事件是一个重要事件,必须触发不仅一页的缓存失效。但是,假设我们要更新的辅助菜单仅位于少数页面上。更新后,我们绝对不想将网站的所有页面都标记为过期,对吗?因此,自然而然地出现的问题是:有没有一种方法可以使我们更有效,并且只对实际上包含更新菜单的页面的缓存无效?
因为有这个问题,我们决定引入HTML标记。换句话说,我们利用我们自己的customsr-cache HTML标记来有目的地标记不同的HTML部分/ UI部分。
例如,如果您正在使用Menu React组件(由我们的Page Builder应用提供)在页面上呈现菜单,除了实际的菜单外,该组件在渲染时还将包括以下HTML:
<ssr-cache data-class =“ pb-menu” data-id =“ small-menu” />
一个页面可以具有多个这样的不同标记(您也可以介绍自己的标记),并且在进行SSR HTML生成时,所有这些标记都将存储在数据库中。让我们看一下更新的数据库条目:
接收到的SSR HTML中包含的所有ssr-cache HTML标记都被提取并保存在cacheTags数组中,这使我们以后可以更轻松地查询数据。
我们可以看到,cacheTags数组包含三个对象,其中第一个是{“ class”:“ pb-menu”,“ id”:“ small-menu”}。这仅表示SSR HTML包含一个页面构建器菜单(pb-menu),该菜单具有ID二级菜单(此处的ID实际上由菜单的唯一slug表示,该slug是通过admin UI设置的)。
还有更多类似的标签,例如pb-pages-list。此标记仅表示SSR HTML包含页面构建器的“页面列表”页面元素。它之所以存在,是因为如果您的页面上有页面列表,并且发布了新页面(或修改了现有页面),则SSR HTML可以视为已过期,因为曾经在页面上的页面列表可能已受到新发布页面的影响。
因此,既然我们了解了这些标签的用途,那么如何利用它们?其实很简单。为了使开发人员更轻松,我们实际上创建了一个小型SsrCacheClient客户端,您可以使用该客户端分别通过invalidateSsrCacheByPath和invalidateSsrCacheByTags方法通过特定的URL路径或传递的标签触发失效事件。在您定义的关键事件中,当你需要将SSR HTML标记为已过期且缓存无效时,可以使用它们。
例如,当菜单更改时,我们执行以下代码(完整代码):
await ssrApiClient.invalidateSsrCacheByTags({
tags: [{ class: "pb-menu", id: this.slug }]
});
发布新页面(或删除现有页面)时,所有包含pb-pages-list页面元素的页面都必须无效(完整代码):
await ssrApiClient.invalidateSsrCacheByTags({
tags: [{ class: "pb-pages-list" }]
});
基本的Webiny应用程序(例如页面生成器或表单生成器)已经在利用React组件中的ssr-cache标签和后端的SsrCacheClient客户端,因此您不必为此担心。最后,如果要进行自定义开发,则基本上可以归结为识别必须触发SSR HTML失效的事件,将ssr-cache标记放入组件中,并适当地使用SsrCacheClient客户端。
Results
解决方案2很好,但又不是最终解决方案。
对您来说是否是一种好方法的最重要因素是您网站上正在发生的更改量。如果更改(必须触发SSR HTML无效的特定事件)非常频繁地发生,例如每隔几秒钟或几分钟,那么我绝对不建议使用这种方法,因为缓存无效性几乎总是发生,并且以某种方式使目标无效。在这种情况下,我们前面提到的解决方案1可能会更好。分析和测试您的应用程序是关键。
同样,如果长时间不访问某个页面,并且其SSR HTML同时被标记为已过期,则首次访问该页面的用户仍会看到旧页面。因为如果您还记得,在某个键事件触发了多个页面的SSR HTML无效的情况下(例如“菜单更改”事件),实际的缓存无效是由实际访问该页面的用户触发的,而不是我们发送大量的向CloudFront的缓存失效请求数量,并在执行过程中花钱。
但是总的来说,考虑到该解决方案提供的惊人的速度优势和异步缓存失效,我们认为这是一种很好的方法。
实际上,我们已将其设置为每个新Webiny项目的默认缓存行为,但是您可以通过轻松删除几个插件切换到解决方案1。如果您想了解更多信息,请务必查看我们的文档。
Conclusion
你看到最后了吗?哇,我很佩服你!
开个玩笑,哈哈,希望我能向您分享我们的一些经验,并且您从本文中获得了一些价值。
今天,我们学到了很多不同的东西。从单页应用程序的基本概念,缺乏SEO支持以及在Web上呈现的不同方法开始,到在无服务器环境中实现其中两种方法(最适合我们的页面生成器应用程序),即按需预渲染和服务器端渲染和激活。尽管在默认情况下,两种方法都解决了上述提到的SEO支持不足的问题,但是在页面加载时间方面,这些方法都无法提供令人满意的性能。当然,如果您的特定应用程序不太在意屏幕加载问题的话,那么按需预渲染可能对您有用。但是如果没有的话,服务器端渲染与激活可能是您的最佳选择。
我们也可以看到,只需使用一些AWS serverless服务,包括S3,Lambda,API Gateway和CloudFront,就可以在无服务器环境中相对容易地实现这些方法。尽管我们无需管理任何物理层面上的基础架构就可以使所有这些服务正常工作,但我们仍然需要考虑分配给Lambda函数的RAM数量。对于基本的文件服务需求,最少需要128MB RAM,但是对于按需预渲染或服务器端渲染这种资源密集型任务,我们必须分配更多空间。请注意分配并进行适当测试,因为这可能会影响您的每月费用。确保检查每个服务的定价页面,并尝试根据您的每月流量进行估算。
最后,为解决SSR生成缓慢和功能冷启动的问题,我们利用了CDN缓存,这可在性能和成本方面产生重大差异。根据最适合我们的情况,我们可以使用短或长的max-age/ TTL进行缓存。如果我们选择使用后者,则将需要手动缓存无效。并且如果由于内容太动态而导致出现很多此类情况,则您可能需要重新考虑您的策略,看看使用较短的max-age(TTL)值是否是更好的解决方案。
通常任何问题都没有灵丹妙药,我们今天讨论的主题无疑是一个很好的例子。尝试不同的事情是关键,它将帮助您找到最适合您的特定情况的方案。
哦,顺便说一句,好消息是,如果您不想折磨自己并希望避免从头开始实现所有操作,则可以尝试Webiny!您甚至可以通过应用一组特定的插件,在我们展示的两种不同的服务器端渲染 HTML缓存方法之间进行选择。我们喜欢保持灵活性。
再次希望我能解释一下我们在Webiny尝试过的方法,但是如果您有任何疑问,请随时提出!我也想听听您对这个话题的看法,因此,如果您有什么要分享的,请分享吧!
谢谢阅读!我叫Adrian,是Webiny的全职开发人员。在业余时间,我想写一些关于我/我们在一些现代前端和后端(无服务器)Web开发工具的经验,希望它可以对其他开发人员的日常工作有所帮助。如果您有任何疑问,评论或想打个招呼,请随时通过Twitter与我联系。
为你推荐
以上是关于第1890期看懂 Serverless SSR,这一篇就够了!的主要内容,如果未能解决你的问题,请参考以下文章