传统框架部署到 Serverless 架构的利与弊
Posted TencentServerless
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了传统框架部署到 Serverless 架构的利与弊相关的知识,希望对你有一定的参考价值。
Serverless 是一个比较新的概念、架构,让开发者放弃之前的开发习惯、放弃现有的 Express、Koa、Flask、Django 等框架,无缝转向 Serverless 架构,显然是不可能的,必须得有一段过渡和适应的时间。在这段时间内,开发者需要思考是否可以将现有的框架部署到 Serverless 架构上?如果要部署,如何才能顺利上云呢?
Web 框架在 Serverless 上的表现
首先,我们以 Flask 框架进行一个简单的测试:
测试四种接口:
-
Get 请求(可能涉及到通过路径传递参数) -
Post 请求(通过 Formdata 传递参数) -
Get 请求(通过 url 参数进行参数传递) -
Get 请求(带有 jieba 等计算功能)
测试两种情况:
-
本地表现 -
通过 Flask-Component 部署表现
测试两种性能:
-
传统云服务器上的性能表现 -
云函数性能表现
测试代码如下:
from flask import Flask, redirect, url_for, request
import jieba
import jieba.analyse
app = Flask(__name__)
@app.route('/hello/<name>')
def success(name):
return 'hello %s' % name
@app.route('/welcome/post', methods=['POST'])
def welcome_post():
user = request.form['name']
return 'POST %s' % user
@app.route('/welcome/get', methods=['GET'])
def welcome_get():
user = request.args.get('name')
return 'GET %s' % user
@app.route('/jieba/', methods=['GET'])
def jieba_test():
str = "Serverless Framework 是业界非常受欢迎的无服务器应用框架,开发者无需关心底层资源即可部署完整可用的 Serverless 应用架构。Serverless Framework 具有资源编排、自动伸缩、事件驱动等能力,覆盖编码、调试、测试、部署等全生命周期,帮助开发者通过联动云资源,迅速构建 Serverless 应用。"
print(", ".join(jieba.cut(str)))
print(jieba.analyse.extract_tags(str, topK=20, withWeight=False, allowPOS=()))
print(jieba.analyse.textrank(str, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')))
return 'success'
if __name__ == '__main__':
app.run(debug=True)
这段测试代码是比较有趣的,它包括了最常用的请求方法、传参方法,同时还囊括了简单的接口和稍微复杂的接口。
本地表现
本地运行之后,通过 Postman 进行三个接口简单测试:
-
Get 请求:
-
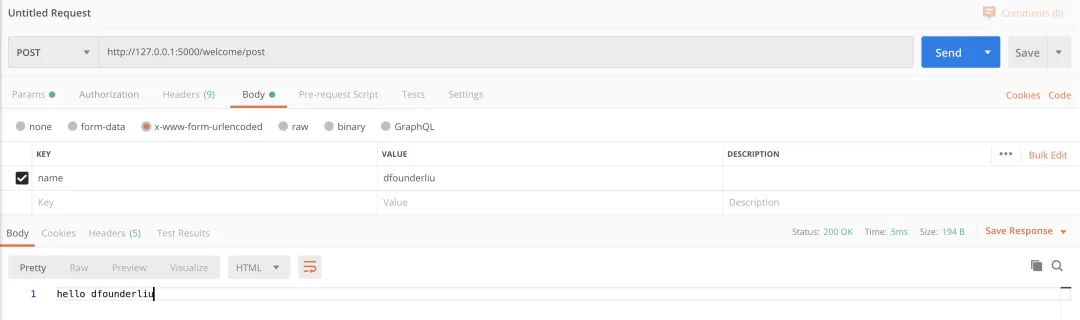
Post 参数传递:
-
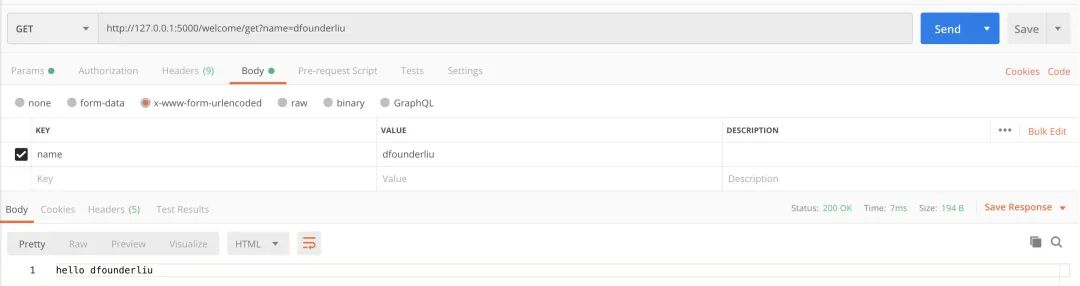
Get 参数传递:
通过 Flask-Component 部署表现
接下来,我们将这个代码部署到云函数中:
Yaml 文档内容:
FlaskComponent:
component: '@gosls/tencent-flask'
inputs:
region: ap-beijing
functionName: Flask_Component
code: ./flask_component
functionConf:
timeout: 10
memorySize: 128
environment:
variables:
TEST: vale
vpcConfig:
subnetId: ''
vpcId: ''
apigatewayConf:
protocols:
- http
environment: release
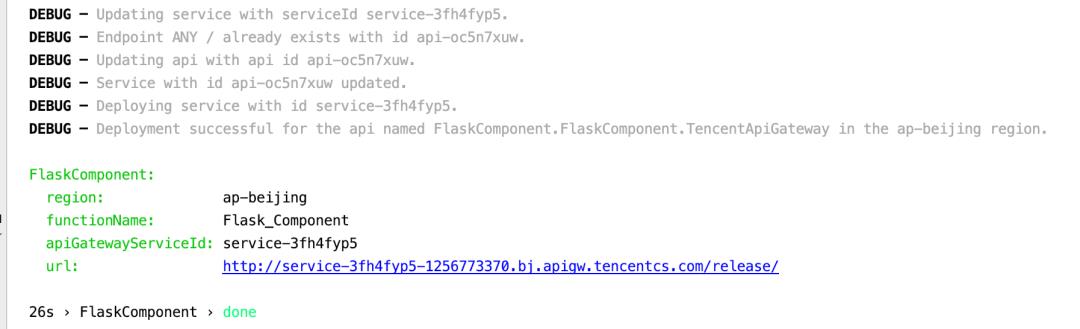
部署完成
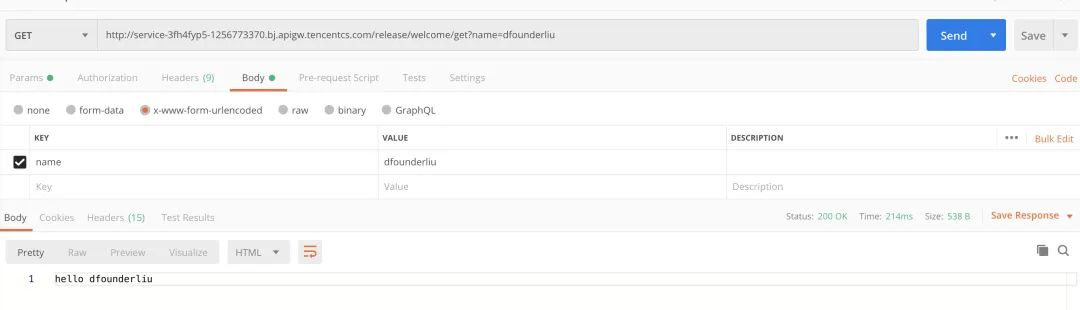
接下来测试三个目标接口
-
Get 通过路径传参:
-
Post 参数传递:
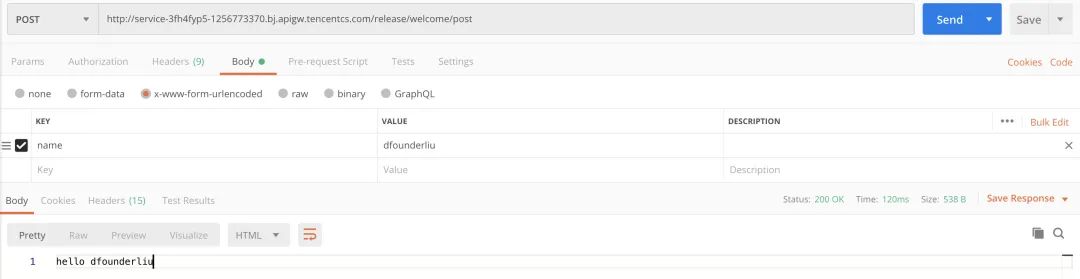
-
Get 参数传递:
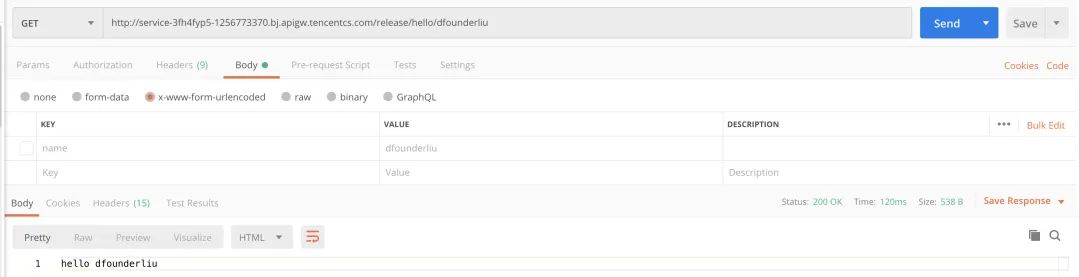
从上面的测试,我们可以看出,通过 Flask-Component 部署的云函数同样可以具备常用的几种请求形式和传参形式。一般情况下,用户的 Flask 项目可以直接通过腾讯云提供的 Flask-component 快速部署到 Serverless 架构上,并获得比较良好的运行。
简单的性能测试
接下来我们对性能进行一些简单的测试,首先购买一个云服务器,将这个部分代码部署到云服务器上。
首先,我们购买了 1 核 2G 的云服务器
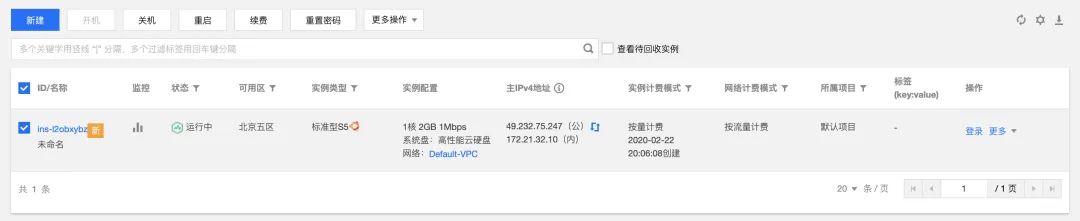
配置环境,使得服务可以正常运行:
通过 Post 设置简单的 Tests:
对接口进行测试:
完成接口测试:

通过接口测试结果进行部分可视化:
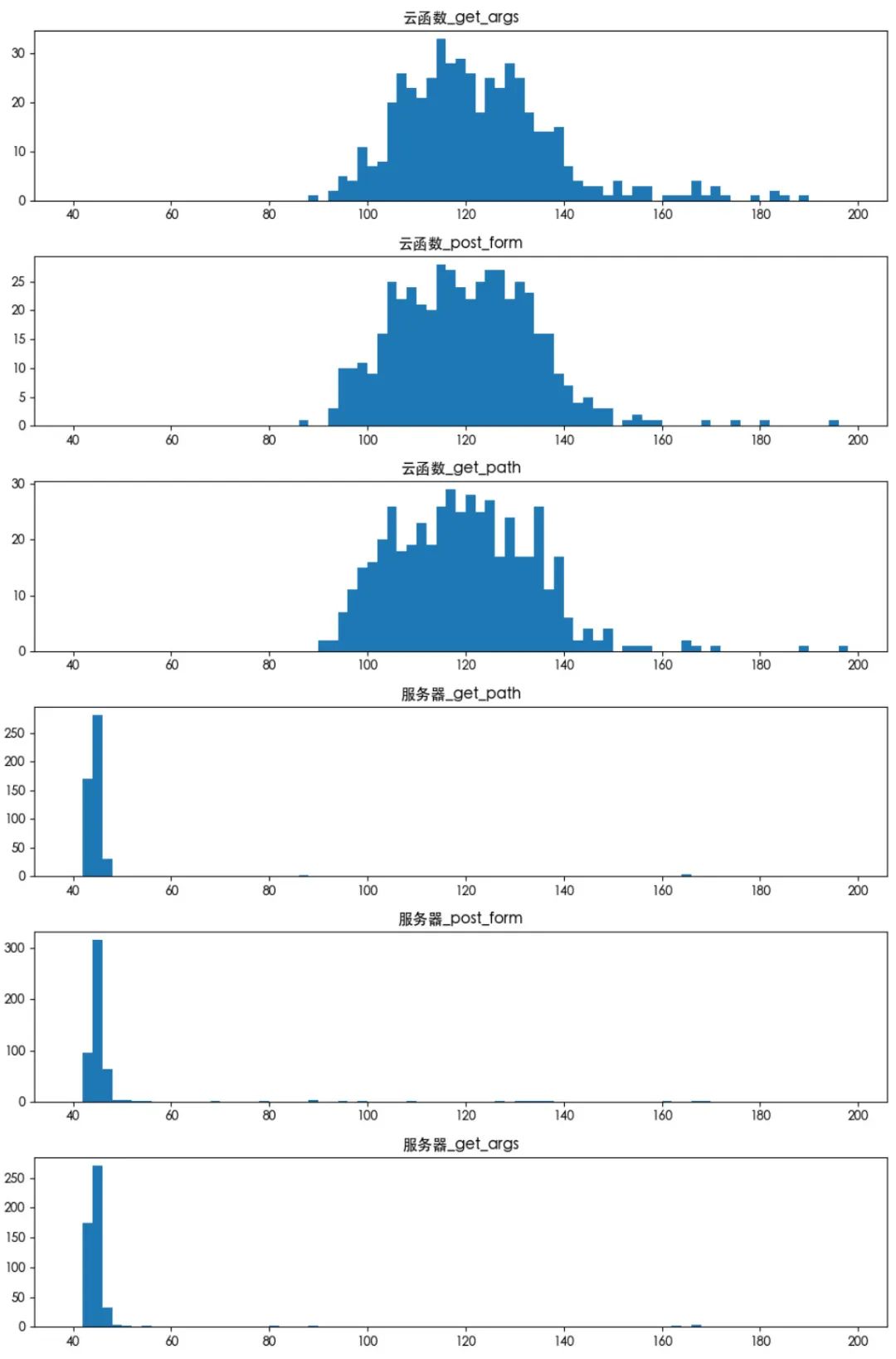
统计数据:
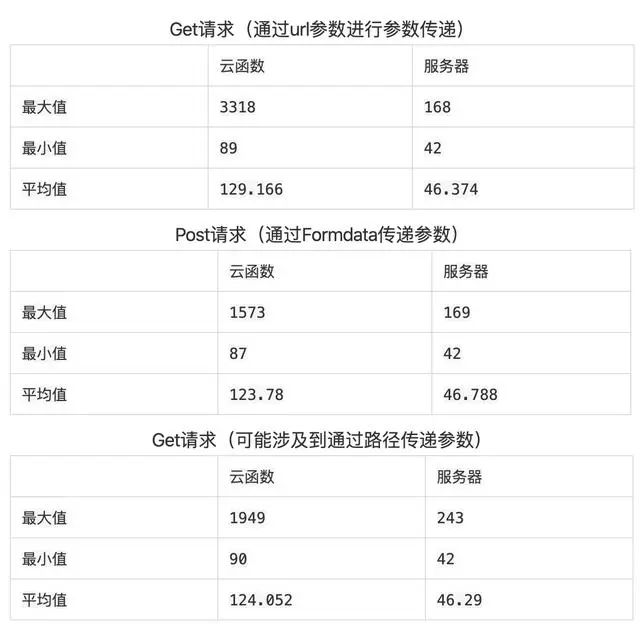
通过上面的图表,我们可以看到服务器的整体响应时间都快于云函数的响应时间,同时函数是存在冷启动的,一旦出现冷启动,其响应时间会增长 20 余倍。
接下来,我们再测试一下稍微复杂的接口 在由于上述测试,仅仅是非常简单的接口,接下来我们来测试一下稍微复杂的接口,使用了 jieba 分词的接口。
测试结果:

可视化结果:
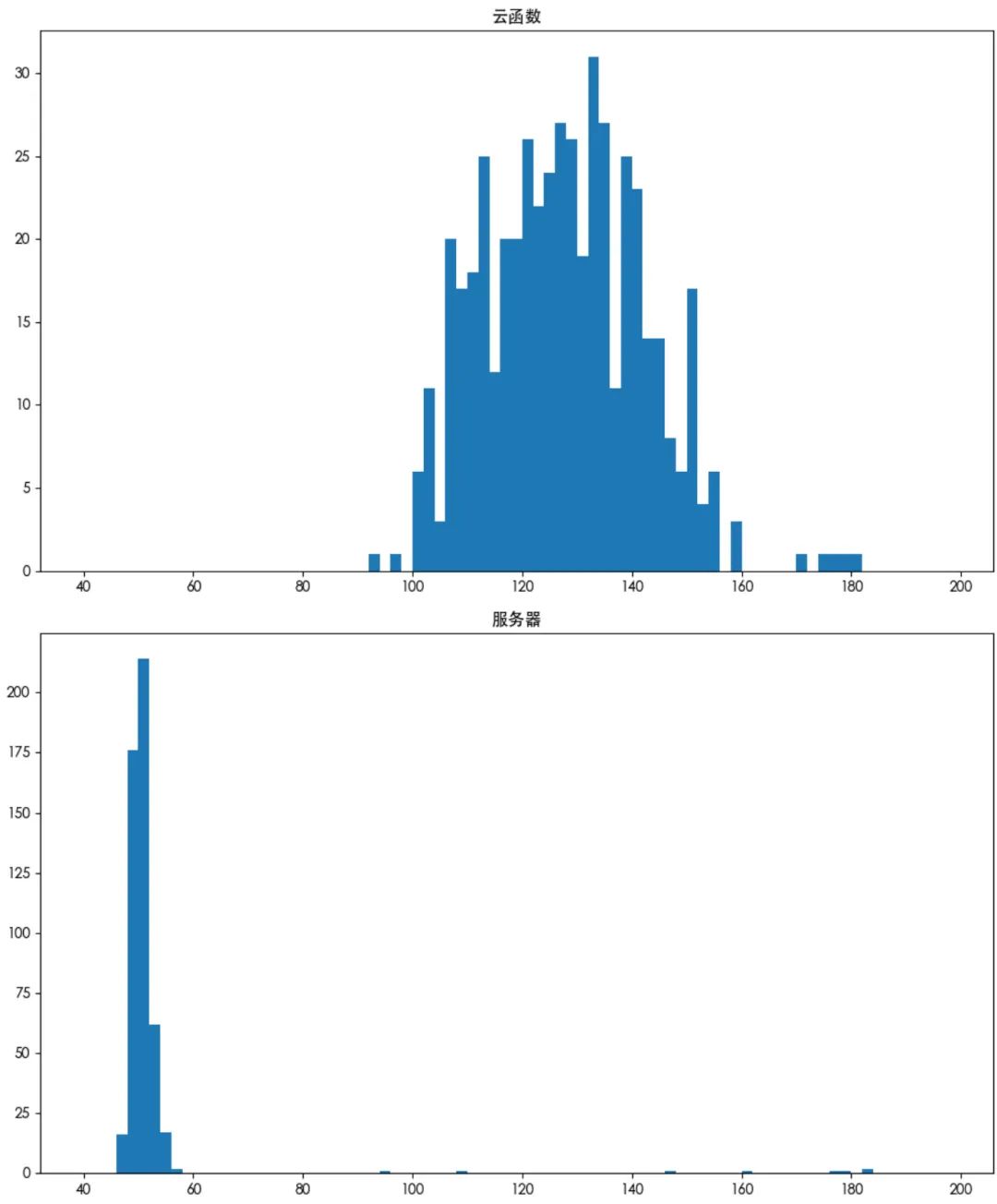
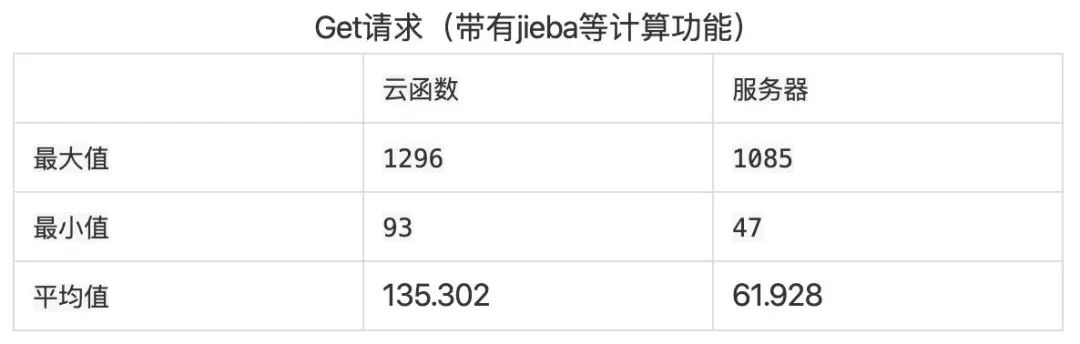
根据对 Jieba 接口的测试,我们发现虽然服务器也会有因分词组件进行初始化而产生比较慢的响应时间,但是整体而言,速度依旧是远远低于云函数。
那么问题来了,这是函数本身的性能有问题,还是增加了 Flask 框架 +APIGW 响应集成之后才有问题?
接下来,我们做一组新的接口测试,在函数中,直接返回内容,不进行额外处理,看看函数 +API 网关性能和正常情况下的服务器性能对比
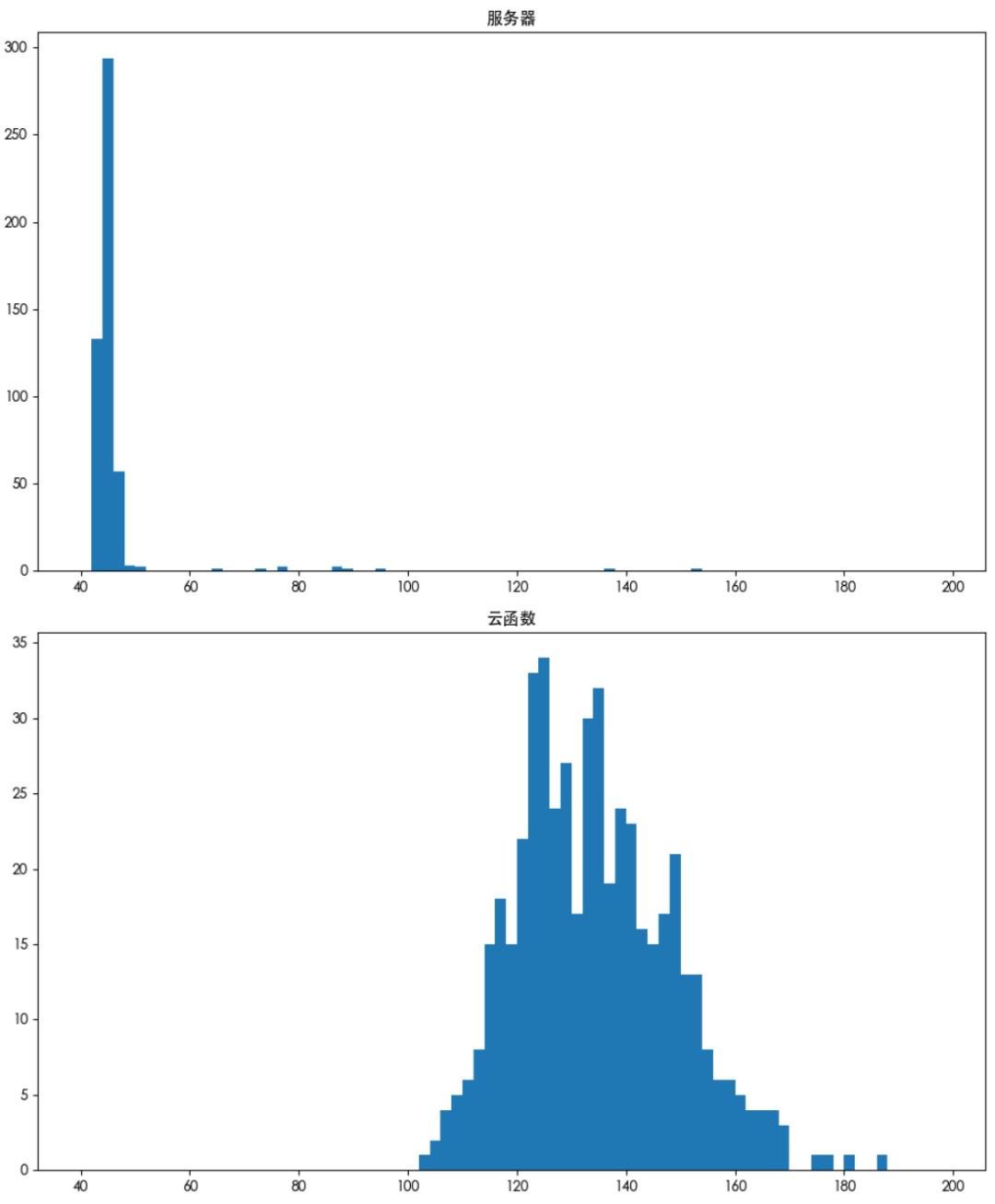
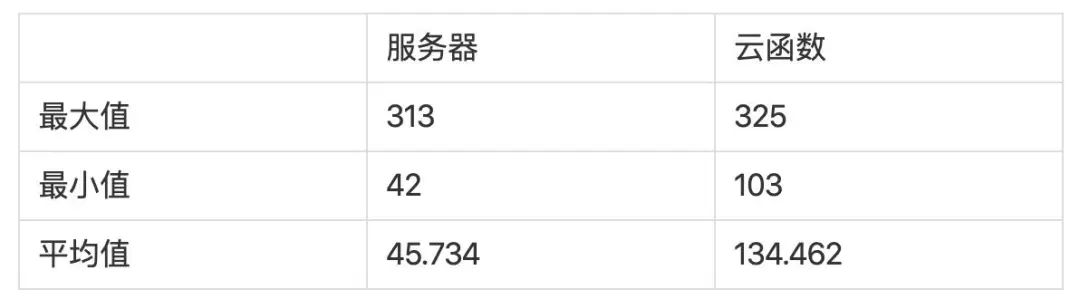
从上图我们可以看出最小和平均耗时的区别不是很大,最大耗时基本上是持平,框架的加载会导致函数冷启动时间长度变得异常可怕。
通过 Python 代码,我们对 Flask 框架进行并发测试:
对函数进行 3 次压测,每次并发 300:
===========task end===========
total:301,succ:301,fail:0,except:0
response maxtime: 1.2727971077
response mintime 0.573610067368
===========task end===========
total:301,succ:301,fail:0,except:0
response maxtime: 1.1745698452
response mintime 0.172255039215
===========task end===========
total:301,succ:301,fail:0,except:0
response maxtime: 1.2857568264
response mintime 0.157210826874
对服务器进行 3 次压测,同样是每次并发 300:
===========task end===========
total:301,succ:301,fail:0,except:0
response maxtime: 3.41151213646
response mintime 0.255661010742
===========task end===========
total:301,succ:301,fail:0,except:0
response maxtime: 3.37784004211
response mintime 0.212490081787
===========task end===========
total:301,succ:301,fail:0,except:0
response maxtime: 3.39548277855
response mintime 0.439364910126
这一波压测,我们可以看到了一个奇怪现象:在函数和服务器预热完成之后,连续三次并发 301 个请求,函数的整体表现反而比服务器的要好。这说明在 Serverless 架构下,弹性伸缩发挥了重要作用。传统服务器,如果出现了高并发现象,很容易会导致整体服务受到严重影响,例如响应时间变长,无响应,甚至是服务器直接挂掉,但是在 Serverless 架构下,具备弹性伸缩能力,因此当并发量达到一定的时候,优势就会凸显出来。
传统 Web 框架上云方法(以 Python Web 框架为例)
分析已有 Component(Flask 为例)
首先,我们要知道其他的框架是怎么运行的,例如 Flask 等。我们先按照腾讯云的 Flask-Component 的说明部署一下:
部署上线之后,在函数的控制台把部署好的下载下来:

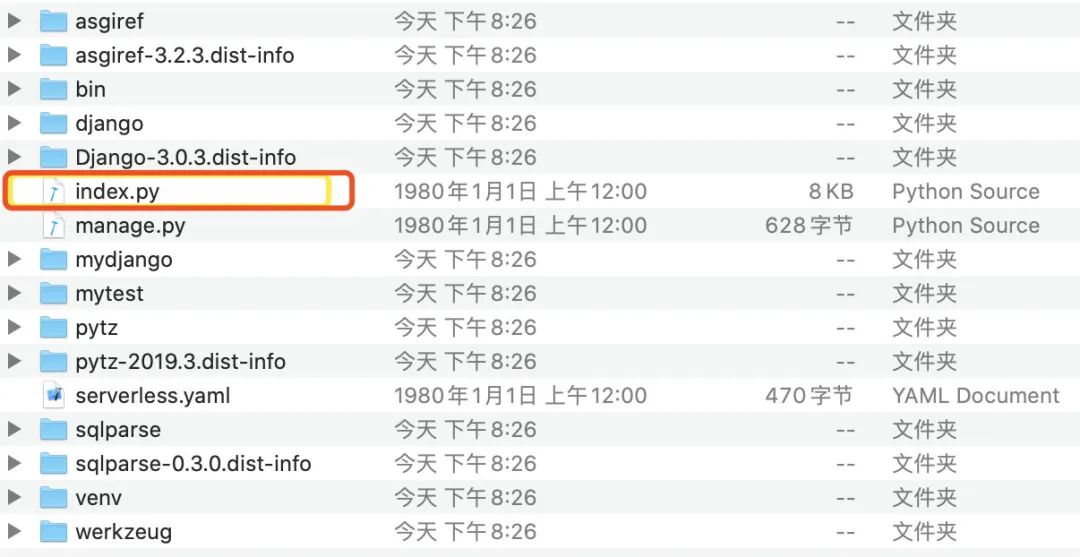
下载解压之后,我们可以看到这样一个目录结构:
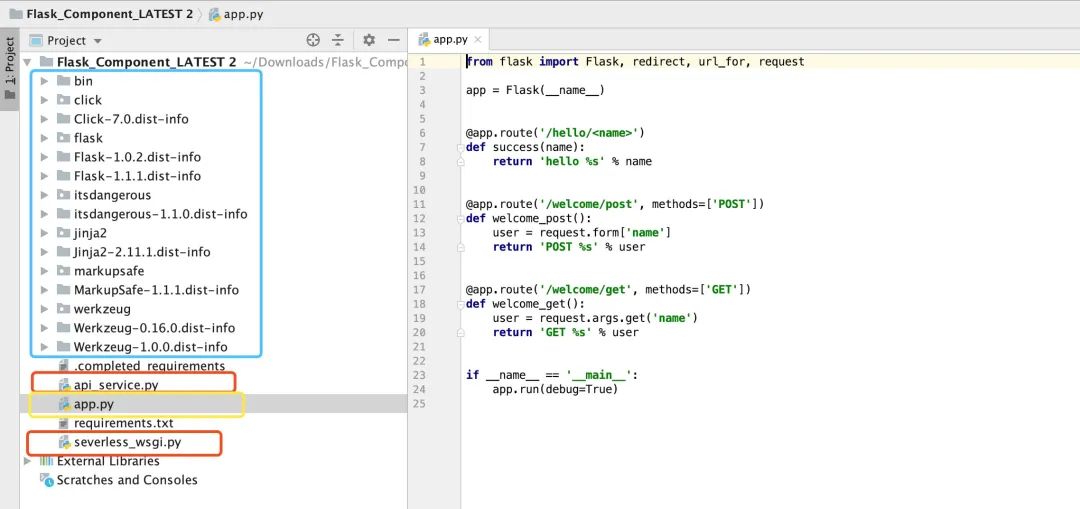
蓝色框中的是依赖包,黄色的 app.py 是我们自己写的代码,而红色框中的是什么?
api_server.py 文件内容:
import app # Replace with your actual application
import severless_wsgi
# If you need to send additional content types as text, add then directly
# to the whitelist:
#
# serverless_wsgi.TEXT_MIME_TYPES.append("application/custom+json")
def handler(event, context):
return severless_wsgi.handle_request(app.app, event, context)
可以看到,这是将我们创建的 app.py 文件引入,并且拿到了 app 对象,将 event 和 context 同时传递给 severless_wsgi.py 中的 handle_reques 方法中,那么问题来了,这个方法是什么?
再观察一下这段代码:

实际上,这一段代码就是将我们拿到的参数(event 和 context)进行转换,转换之后统一到 environ 中,通过 werkzeug 依赖将其变成 request 对象,并与 app 对象一起调用 from_app 方法。
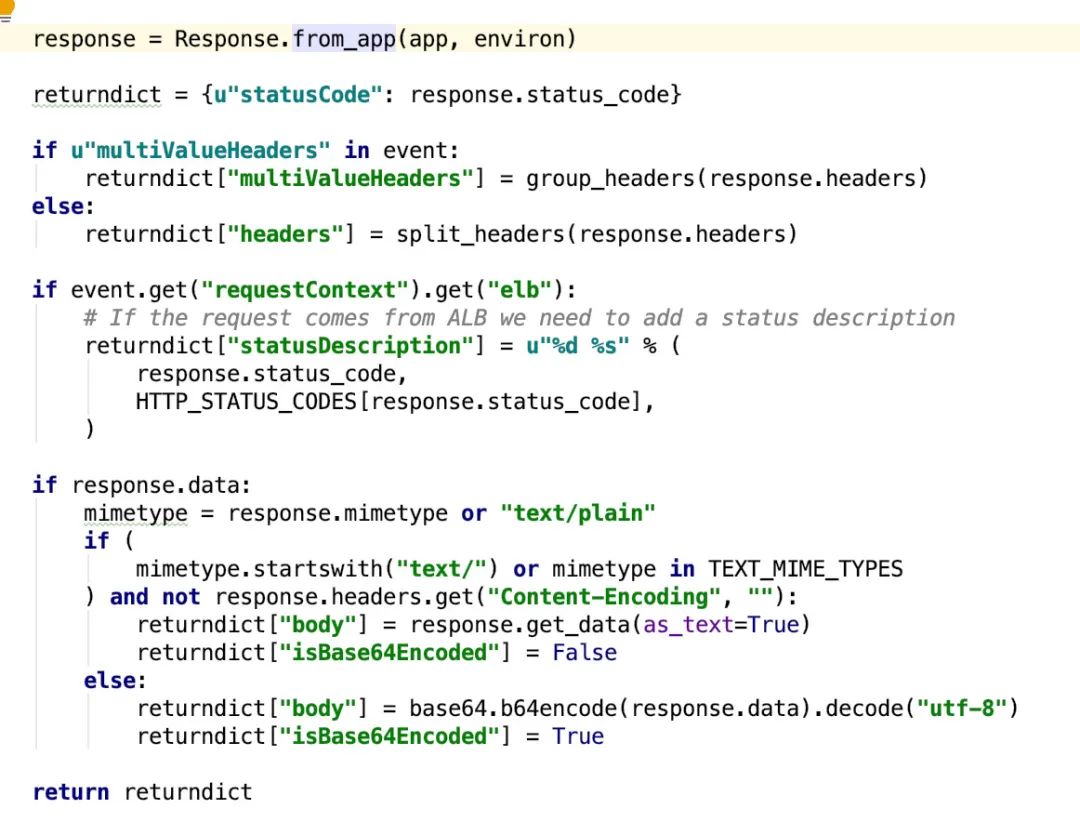
按照 API 网关的响应集成的格式,将结果返回。
相信执行到这里,大家可能就有所感悟了,我们再看一下 Flask/Django 这些框架的实现原理:
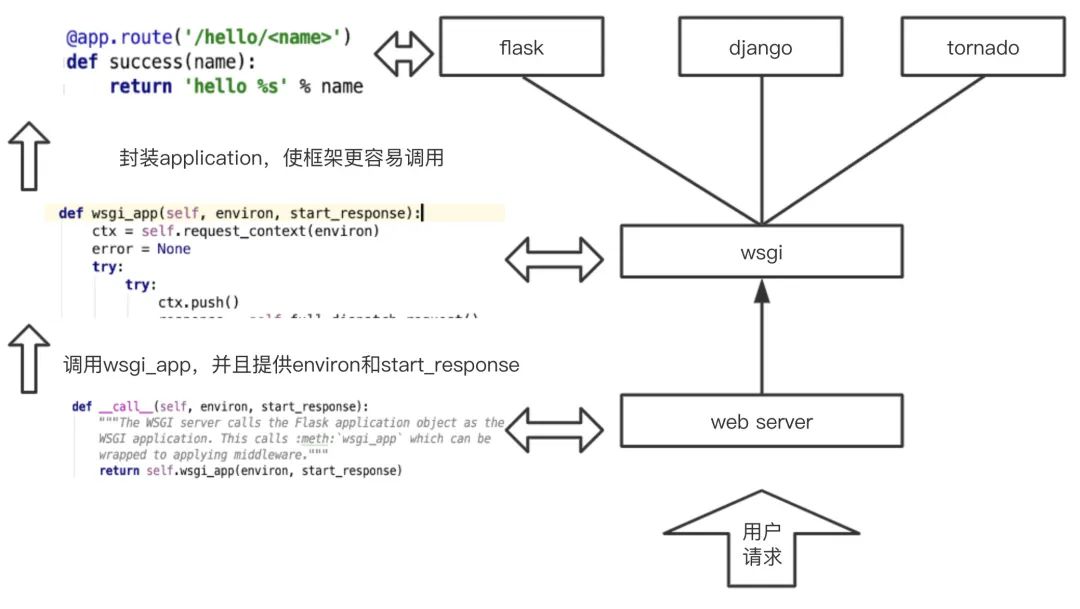
根据简版原理图,相信大家都明白正常用的时候要通过 web_server,进入到下一个环节,而云函数更多是一个函数,不需要启动 web server,所以可以直接调用 wsgi_app 方法,其中 environ 就是对 event/context 等进行处理后的对象,start_response 可以认为是一种特殊的数据结构,例如 response 结构形态等。
因此,如果我们想要自己动手实现这个过程,可以这样做:
import sys
try:
from urllib import urlencode
except ImportError:
from urllib.parse import urlencode
from flask import Flask
try:
from cStringIO import StringIO
except ImportError:
try:
from StringIO import StringIO
except ImportError:
from io import StringIO
from werkzeug.wrappers import BaseRequest
__version__ = '0.0.4'
def make_environ(event):
environ = {}
for hdr_name, hdr_value in event['headers'].items():
hdr_name = hdr_name.replace('-', '_').upper()
if hdr_name in ['CONTENT_TYPE', 'CONTENT_LENGTH']:
environ[hdr_name] = hdr_value
continue
http_hdr_name = 'HTTP_%s' % hdr_name
environ[http_hdr_name] = hdr_value
apigateway_qs = event['queryStringParameters']
request_qs = event['queryString']
qs = apigateway_qs.copy()
qs.update(request_qs)
body = ''
if 'body' in event:
body = event['body']
environ['REQUEST_METHOD'] = event['httpMethod']
environ['PATH_INFO'] = event['path']
environ['QUERY_STRING'] = urlencode(qs) if qs else ''
environ['REMOTE_ADDR'] = 80
environ['HOST'] = event['headers']['host']
environ['SCRIPT_NAME'] = ''
environ['SERVER_PORT'] = 80
environ['SERVER_PROTOCOL'] = 'HTTP/1.1'
environ['CONTENT_LENGTH'] = str(len(body))
environ['wsgi.url_scheme'] = ''
environ['wsgi.input'] = StringIO(body)
environ['wsgi.version'] = (1, 0)
environ['wsgi.errors'] = sys.stderr
environ['wsgi.multithread'] = False
environ['wsgi.run_once'] = True
environ['wsgi.multiprocess'] = False
BaseRequest(environ)
return environ
class LambdaResponse(object):
def __init__(self):
self.status = None
self.response_headers = None
def start_response(self, status, response_headers, exc_info=None):
self.status = int(status[:3])
self.response_headers = dict(response_headers)
class FlaskLambda(Flask):
def __call__(self, event, context):
if 'httpMethod' not in event:
print('httpMethod not in event')
return super(FlaskLambda, self).__call__(event, context)
response = LambdaResponse()
body = next(self.wsgi_app(
make_environ(event),
response.start_response
))
return {
'statusCode': response.status,
'headers': response.response_headers,
'body': body
}
整个实现过程可以认为是对 web server 部分进行了一种“截断”或者是“替换”:
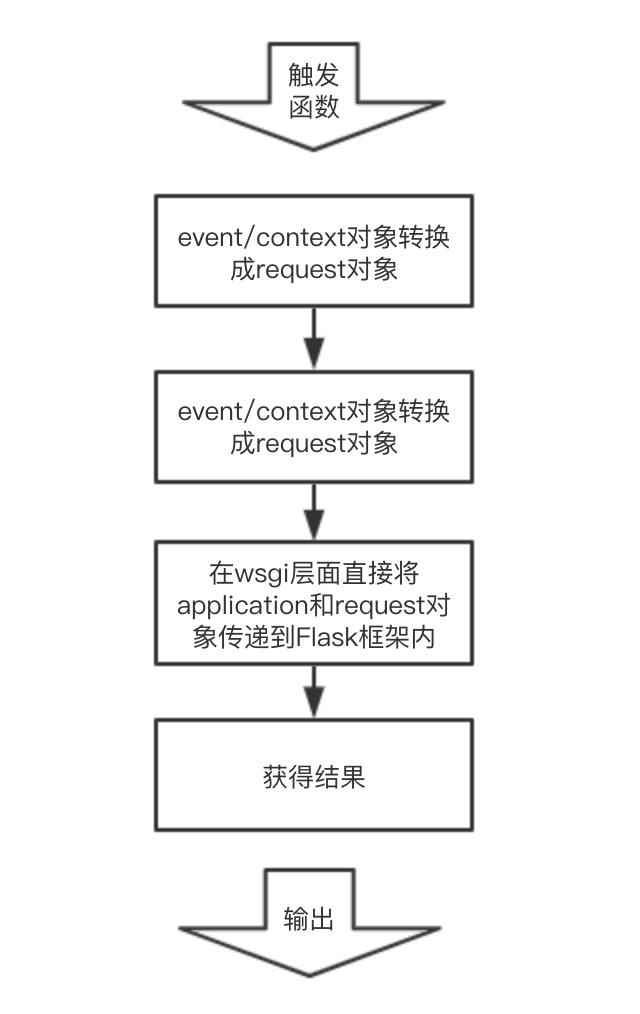
以上就是对 Flask-Component 的基本分析思路,按照这个思路我们是否可以将 Django 框架也部署在 Serverless 架构上呢?Flask 和 Django 有什么区别呢?(特指运行启动过程)
拓展思路:实现 Django-component
我们是否可以直接使用 Flask 的转换逻辑,将 flask 的 app 替换成 django 的 app? 把:
from flask import Flask
app = Flask(__name__)
替换成:
import os
from django.core.wsgi import get_wsgi_application
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'mydjango.settings')
application = get_wsgi_application()
替换完成,我们来测试一下:
建立好 Django 项目,直接增加 index.py:
# -*- coding: utf-8 -*-
import os
import sys
import base64
from werkzeug.datastructures import Headers, MultiDict
from werkzeug.wrappers import Response
from werkzeug.urls import url_encode, url_unquote
from werkzeug.http import HTTP_STATUS_CODES
from werkzeug._compat import BytesIO, string_types, to_bytes, wsgi_encoding_dance
import mydjango.wsgi
TEXT_MIME_TYPES = [
"application/json",
"application/javascript",
"application/xml",
"application/vnd.api+json",
"image/svg+xml",
]
def all_casings(input_string):
if not input_string:
yield ""
else:
first = input_string[:1]
if first.lower() == first.upper():
for sub_casing in all_casings(input_string[1:]):
yield first + sub_casing
else:
for sub_casing in all_casings(input_string[1:]):
yield first.lower() + sub_casing
yield first.upper() + sub_casing
def split_headers(headers):
"""
If there are multiple occurrences of headers, create case-mutated variations
in order to pass them through APIGW. This is a hack that's currently
needed. See: https://github.com/logandk/serverless-wsgi/issues/11
Source: https://github.com/Miserlou/Zappa/blob/master/zappa/middleware.py
"""
new_headers = {}
for key in headers.keys():
values = headers.get_all(key)
if len(values) > 1:
for value, casing in zip(values, all_casings(key)):
new_headers[casing] = value
elif len(values) == 1:
new_headers[key] = values[0]
return new_headers
def group_headers(headers):
new_headers = {}
for key in headers.keys():
new_headers[key] = headers.get_all(key)
return new_headers
def encode_query_string(event):
multi = event.get(u"multiValueQueryStringParameters")
if multi:
return url_encode(MultiDict((i, j) for i in multi for j in multi[i]))
else:
return url_encode(event.get(u"queryString") or {})
def handle_request(application, event, context):
if u"multiValueHeaders" in event:
headers = Headers(event["multiValueHeaders"])
else:
headers = Headers(event["headers"])
strip_stage_path = os.environ.get("STRIP_STAGE_PATH", "").lower().strip() in [
"yes",
"y",
"true",
"t",
"1",
]
if u"apigw.tencentcs.com" in headers.get(u"Host", u"") and not strip_stage_path:
script_name = "/{}".format(event["requestContext"].get(u"stage", ""))
else:
script_name = ""
path_info = event["path"]
base_path = os.environ.get("API_GATEWAY_BASE_PATH")
if base_path:
script_name = "/" + base_path
if path_info.startswith(script_name):
path_info = path_info[len(script_name) :] or "/"
if u"body" in event:
body = event[u"body"] or ""
else:
body = ""
if event.get("isBase64Encoded", False):
body = base64.b64decode(body)
if isinstance(body, string_types):
body = to_bytes(body, charset="utf-8")
environ = {
"CONTENT_LENGTH": str(len(body)),
"CONTENT_TYPE": headers.get(u"Content-Type", ""),
"PATH_INFO": url_unquote(path_info),
"QUERY_STRING": encode_query_string(event),
"REMOTE_ADDR": event["requestContext"]
.get(u"identity", {})
.get(u"sourceIp", ""),
"REMOTE_USER": event["requestContext"]
.get(u"authorizer", {})
.get(u"principalId", ""),
"REQUEST_METHOD": event["httpMethod"],
"SCRIPT_NAME": script_name,
"SERVER_NAME": headers.get(u"Host", "lambda"),
"SERVER_PORT": headers.get(u"X-Forwarded-Port", "80"),
"SERVER_PROTOCOL": "HTTP/1.1",
"wsgi.errors": sys.stderr,
"wsgi.input": BytesIO(body),
"wsgi.multiprocess": False,
"wsgi.multithread": False,
"wsgi.run_once": False,
"wsgi.url_scheme": headers.get(u"X-Forwarded-Proto", "http"),
"wsgi.version": (1, 0),
"serverless.authorizer": event["requestContext"].get(u"authorizer"),
"serverless.event": event,
"serverless.context": context,
# TODO: Deprecate the following entries, as they do not comply with the WSGI
# spec. For custom variables, the spec says:
#
# Finally, the environ dictionary may also contain server-defined variables.
# These variables should be named using only lower-case letters, numbers, dots,
# and underscores, and should be prefixed with a name that is unique to the
# defining server or gateway.
"API_GATEWAY_AUTHORIZER": event["requestContext"].get(u"authorizer"),
"event": event,
"context": context,
}
for key, value in environ.items():
if isinstance(value, string_types):
environ[key] = wsgi_encoding_dance(value)
for key, value in headers.items():
key = "HTTP_" + key.upper().replace("-", "_")
if key not in ("HTTP_CONTENT_TYPE", "HTTP_CONTENT_LENGTH"):
environ[key] = value
response = Response.from_app(application, environ)
returndict = {u"statusCode": response.status_code}
if u"multiValueHeaders" in event:
returndict["multiValueHeaders"] = group_headers(response.headers)
else:
returndict["headers"] = split_headers(response.headers)
if event.get("requestContext").get("elb"):
# If the request comes from ALB we need to add a status description
returndict["statusDescription"] = u"%d %s" % (
response.status_code,
HTTP_STATUS_CODES[response.status_code],
)
if response.data:
mimetype = response.mimetype or "text/plain"
if (
mimetype.startswith("text/") or mimetype in TEXT_MIME_TYPES
) and not response.headers.get("Content-Encoding", ""):
returndict["body"] = response.get_data(as_text=True)
returndict["isBase64Encoded"] = False
else:
returndict["body"] = base64.b64encode(response.data).decode("utf-8")
returndict["isBase64Encoded"] = True
return returndict
def main_handler(event, context):
return handle_request(mydjango.wsgi.application, event, context)
将其部署到函数上,看一下效果: 函数信息:
from django.shortcuts import render
from django.http import HttpResponse
from django.views.decorators.csrf import csrf_exempt
# Create your views here.
@csrf_exempt
def hello(request):
if request.method == "POST":
return HttpResponse("Hello world ! " + request.POST.get("name"))
if request.method == "GET":
return HttpResponse("Hello world ! " + request.GET.get("name"))
部署完成,绑定 apigw 触发器,并在 postman 中进行测试: get:
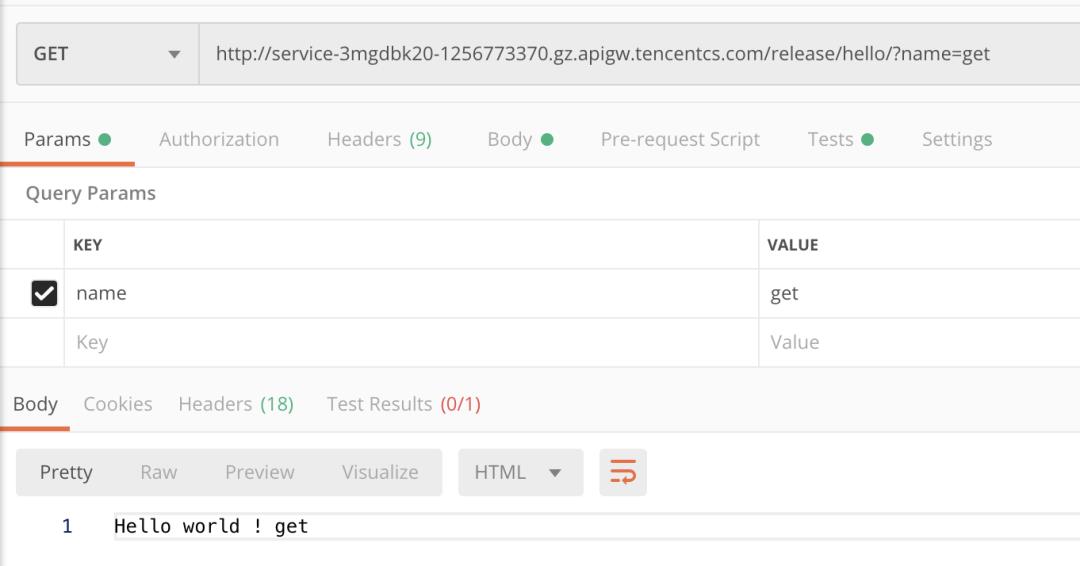
post:
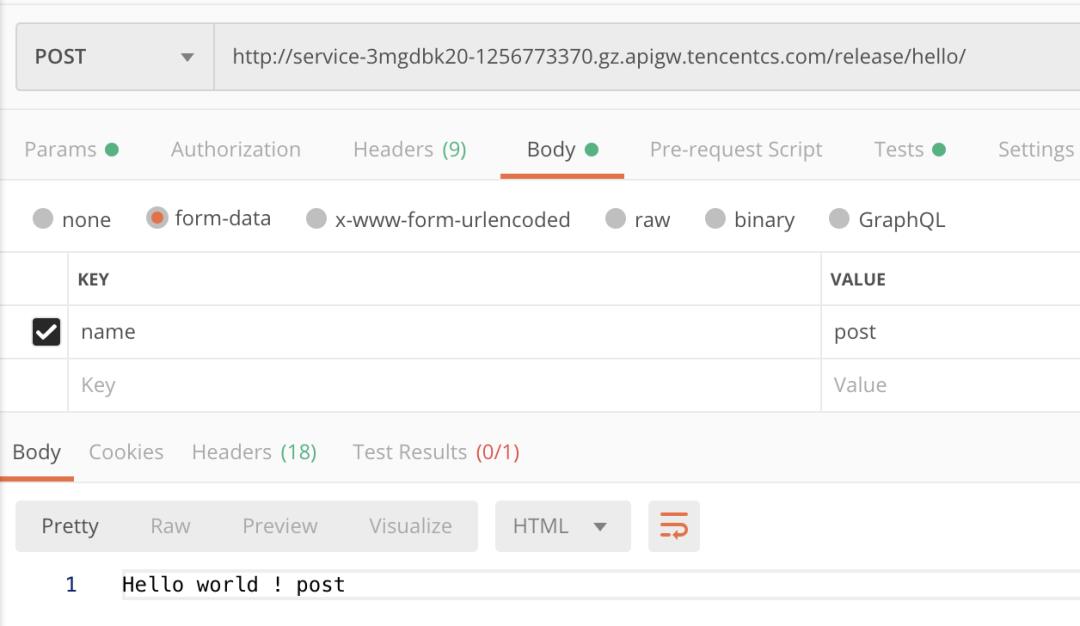
通过对运行原理的基本剖析和对 django 的改造,我们已经通过增加一个文件和相关依赖的方法,成功将 Django 搬上了 Serverless。
接下来,我们看一下,如何将代码写成一个 Component: 首先 Clone 下来 Flask-Component 的代码:
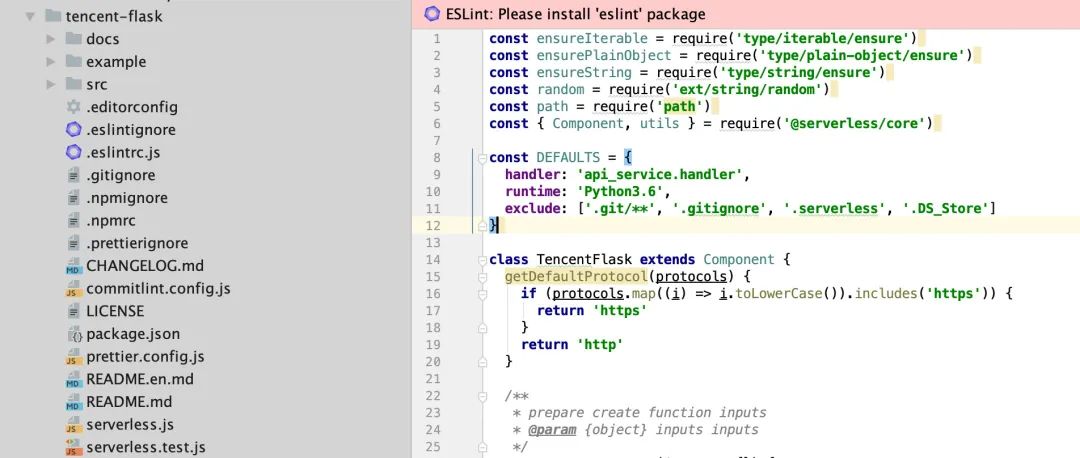
按照 Django 的部分模式进行修改:
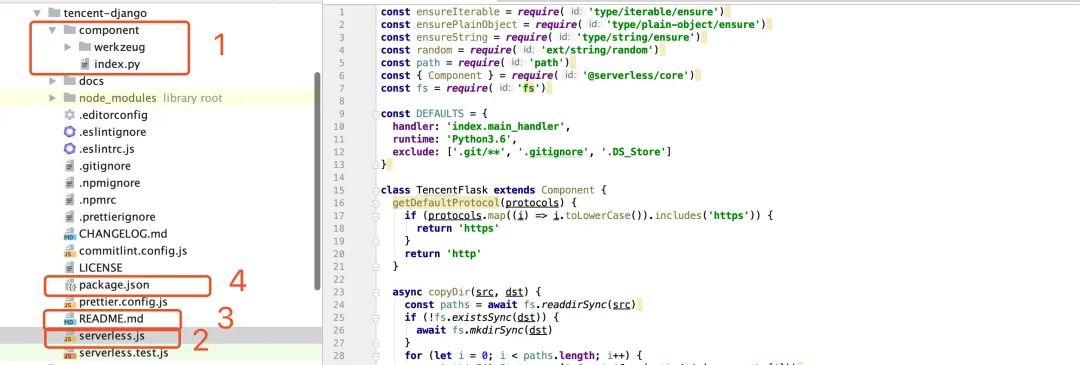
第一部分,是我们可能会依赖的一个依赖包,以及刚才放入的 index.py 文件。在用户调用这个 Component 的时候,我们会把这两个文件放入用户的代码中,一并上传。
第二部分是 Serverless.js,下面是一个基本格式:
const { Component } = require('@serverless/core')
class TencentDjango extends Component {
async default(inputs = {}) {
}
async remove(inputs = {}) {
}
}
module.exports = TencentDjango
用户在执行 sls 时会默认调用 default 方法,在执行 sls remove 时会调用 remove 方法,所以可以认为 default 的内容是部署,而 remove 的内容是移除。
主要流程的部署也很简单,首先将文件进行复制和处理,然后直接调用云函数的组件,通过函数中的 include 参数将这些文件额外加入,再通过调用 apigw 的组件来进网关的管理。用户写的 yaml 中 inpust 的内容会在 inputs 中获取,我们要做的就是对应的传给不同的组件:
除了将这两部分对应部署,region 等一些信息也要进行对应处理。调用底层组件方法也很简单:
const tencentCloudFunction = await this.load('@serverless/tencent-scf'
const tencentCloudFunctionOutputs = await tencentCloudFunction(inputs)
处理好之后,只需要修改一下 package.json 和 readme 就可以了。
至此,我们完成了一个 Django Component 的开发,发布到 NPM 后,在使用时只需要引入这个 Component 即可:
DjangoTest:
component: '@serverless/tencent-django'
inputs:
region: ap-guangzhou
functionName: DjangoFunctionTest
djangoProjectName: mydjango
code: ./
functionConf:
timeout: 10
memorySize: 256
environment:
variables:
TEST: vale
vpcConfig:
subnetId: ''
vpcId: ''
apigatewayConf:
protocols:
- http
environment: release
总结:
Flask 可以通过很简单的方法部署在 Serverless 架构上,用户基本可以按照原生 Flask 开发习惯来开发 Flask 项目,尤其是使用 Flask 开发接口服务的项目。
整体框架迁移上 Serverless 架构有几个需要额外注意的点:
-
如果接口比较多,需要按照资源消耗比较大的那个接口来设置内存大小。如果是按照文章中的例子,非 jieba 接口使用时的最小内存(64M),而 jieba 接口却需要 256M 的内存。因为项目是一体的,只能设置一个内存,所以为了保证项目可用性,应该整体设置为 256M 的内存,这样一来在另外三个接口访问比较多的前提下,资源消耗可能会相对增加比较大,有条件的话,可考虑将资源消耗比较大的接口额外提取出来; -
云函数 +API 网关的组合对静态资源以及文件上传等的支持并不是十分友好,尤其是云函数 +API 网关的双重收费,所以建议将 Flask 中的静态资源统一放在对象存储中,同时将文件上传逻辑修改成优先上传到对象存储中。
框架越大、框架内的资源越多,函数冷启动的时间就会越大。在上文的测试过程中,非框架下,最高耗时是平均耗时的 3 倍,而在加载 Flask 框架和 Jieba 的前提下,最高耗时是平均的 10+ 倍!如果能保证函数都是热启动还好,一旦出现冷启动,就会有一定的影响。
由于用户发起请求是客户端到 API 网关再到函数,然后从函数回到 API 网关,再回到客户端。相对于直接访问服务器获得结果,这个过程明显链路更长,所以在实际测试过程中,用户量较少的时候,表现不是很好,几次测试基本上都是 1 核 2G 的服务器优于函数。但当并发量上来的之后,函数的表现实现了大超车。因此,我们可以得出一个有趣的结论:对于极小规模请求,函数是按量付费,在性能上有一定的劣势,但在价格上有一定的优势;当流量逐渐变大之后,函数在性能上的优势也逐渐凸显。
除了对传统 Web 框架部署到 Serverless 架构的利弊分析之外,通过对 Flask 框架进行分析,我们可以总结出 Web 框架搬上 Serverless 架构的原理思路,虽然说 Serverless 团队很活跃,各个云厂商也很活跃,但在实际生产中,必然会用到很多定制化组件,Serverless Component 本身就是组件化的产品,如果深度使用就可以定制化开发 Component 满足自身需求,这时候就要知道一些原理和技巧。
我相信,Serverless 架构虽然目前还存在一些问题,但一定会随着时间发展得越发成熟!
Serverless Framework 30 天试用计划
我们诚邀您来体验最便捷的 Serverless 开发和部署方式。在试用期内,相关联的产品及服务均提供免费资源和专业的技术支持,帮助您的业务快速、便捷地实现 Serverless!
详情可查阅:https://cloud.tencent.com/document/product/1154/38792
One More Thing
3 秒你能做什么?喝一口水,看一封邮件,还是 —— 部署一个完整的 Serverless 应用?复制以下链接至 PC 浏览器访问:
china.serverless.com/express
3 秒极速部署,立即体验史上最快的 Serverless HTTP 实战开发!
传送门:
GitHub: github.com/serverless 官网:serverless.com
点击阅读原文,访问:Serverless 中文网,您可以在 最佳实践 里体验更多关于 Serverless 应用的开发!
以上是关于传统框架部署到 Serverless 架构的利与弊的主要内容,如果未能解决你的问题,请参考以下文章