一些JAVA面试的常见问题汇总
Posted 柠檬学园
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一些JAVA面试的常见问题汇总相关的知识,希望对你有一定的参考价值。
本篇用于总结在面试中常见的java问题:
java中equals和等号(==)的区别?
java中的数据类型,可分为两类:
1、基本数据类型,也称原始数据类型。byte,short,char,int,long,float,double,boolean 他们之间的比较,应用双等号(==),比较的是他们的值。
3、如果在覆写equals方法的情况下,是用于比较两个独立对象的内容是否相同。就好比去比较两个人的长相是否相同,它比较的两个对象是独立的。例如,对于下面的代码:
String a=new String("foo");
String b=new String("foo");
int和Integer的区别?
1、Integer是int的包装类,int则是java的一种基本数据类型
2、Integer变量必须实例化后才能使用,而int变量不需要
3、Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
4、Integer的默认值是null,int的默认值是0
Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.print(i == j); //false
2、Integer变量和int变量比较时,只要两个变量的值是相等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
Integer i = new Integer(100);
int j = 100;
System.out.print(i == j); //true
Integer i = new Integer(100);
Integer j = 100;
System.out.print(i == j); //false
4、对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
Integer i = 100;
Integer j = 100;
System.out.print(i == j); //true
Integer i = 128;
Integer j = 128;
System.out.print(i == j); //false
对于第4条的原因:
java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
public static Integer valueOf(int i){
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high){
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}
java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了
JAVA的包装类、拆箱和装箱?
虽然 Java 语言是典型的面向对象编程语言,但其中的八种基本数据类型并不支持面向对象编程,基本类型的数据不具备“对象”的特性——不携带属性、没有方法可调用。 沿用它们只是为了迎合人类根深蒂固的习惯,并的确能简单、有效地进行常规数据处理。
这种借助于非面向对象技术的做法有时也会带来不便,比如引用类型数据均继承了 Object 类的特性,要转换为 String 类型(经常有这种需要)时只要简单调用 Object 类中定义的toString()即可,而基本数据类型转换为 String 类型则要麻烦得多。为解决此类问题 ,Java为每种基本数据类型分别设计了对应的类,称之为包装类(Wrapper Classes),也有教材称为外覆类或数据类型类。
基本数据类型及对应的包装类
每个包装类的对象可以封装一个相应的基本类型的数据,并提供了其它一些有用的方法。包装类对象一经创建,其内容(所封装的基本类型数据值)不可改变。
基本类型和对应的包装类可以相互装换:
由基本类型向对应的包装类转换称为装箱,例如把 int 包装成 Integer 类的对象;
包装类向对应的基本类型转换称为拆箱,例如把 Integer 类的对象重新简化为 int。
包装类的应用
八个包装类的使用比较相似,下面是常见的应用场景。
1) 实现 int 和 Integer 的相互转换
可以通过 Integer 类的构造方法将 int 装箱,通过 Integer 类的 intValue 方法将 Integer 拆箱。例如:
public class Demo {
public static void main(String[] args) {
int m = 500;
Integer obj = new Integer(m); // 手动装箱
int n = obj.intValue(); // 手动拆箱
System.out.println("n = " + n);
Integer obj1 = new Integer(500);
System.out.println("obj 等价于 obj1?" + obj.equals(obj1));
}
}
运行结果:
n = 500
obj 等价于 obj1?true
2) 将字符串转换为整数
Integer 类有一个静态的 paseInt() 方法,可以将字符串转换为整数,语法为:
parseInt(String s, int radix);
s 为要转换的字符串,radix 为进制,可选,默认为十进制。
下面的代码将会告诉你什么样的字符串可以转换为整数:
public class Demo {
public static void main(String[] args) {
String str[] = {"123", "123abc", "abc123", "abcxyz"};
for(String str1 : str){
try{
int m = Integer.parseInt(str1, 10);
System.out.println(str1 + " 可以转换为整数 " + m);
}catch(Exception e){
System.out.println(str1 + " 无法转换为整数");
}
}
}
}
运行结果:
123 可以转换为整数 123
123abc 无法转换为整数
abc123 无法转换为整数
abcxyz 无法转换为整数
3) 将整数转换为字符串
Integer 类有一个静态的 toString() 方法,可以将整数转换为字符串。例如:
public class Demo {
public static void main(String[] args) {
int m = 500;
String s = Integer.toString(m);
System.out.println("s = " + s);
}
}
运行结果:
s = 500
自动拆箱和装箱
上面的例子都需要手动实例化一个包装类,称为手动拆箱装箱。Java 1.5(5.0) 之前必须手动拆箱装箱。
Java 1.5 之后可以自动拆箱装箱,也就是在进行基本数据类型和对应的包装类转换时,系统将自动进行,这将大大方便程序员的代码书写。例如:
public class Demo {
public static void main www.120xh.cn (String[] args) {
int m = 500;
Integer obj = m; // 自动装箱
int n = obj; // 自动拆箱
System.out.println("n = " + n);
Integer obj1 = 500;
System.out.println("obj 等价于 obj1?" + obj.equals(obj1));
}
}
运行结果:
n = 500
obj 等价于 obj1?true
自动拆箱装箱是常用的一个功能,需要重点掌握。
什么是HashCode?
1、hash和hash表是什么
想要知道这个hashcode,首先得知道hash,通过百度百科看一下:


hash是一个函数,该函数中的实现就是一种算法,就是通过一系列的算法来得到一个hash值,这个时候,我们就需要知道另一个东西,hash表,通过hash算法得到的hash值就在这张hash表中,也就是说,hash表就是所有的hash值组成的,有很多种hash函数,也就代表着有很多种算法得到hash值,如上面截图的三种,等会我们就拿第一种来说。
2、hashcode
有了前面的基础,这里讲解就简单了,hashcode就是通过hash函数得来的,通俗的说,就是通过某一种算法得到的,hashcode就是在hash表中有对应的位置。
每个对象都有hashcode,对象的hashcode怎么得来的呢?
3、hashcode的作用
为什么hashcode就查找的更快,比如:我们有一个能存放1000个数这样大的内存中,在其中要存放1000个不一样的数字,用最笨的方法,就是存一个数字,就遍历一遍,看有没有相同得数,当存了900个数字,开始存901个数字的时候,就需要跟900个数字进行对比,这样就很麻烦,很是消耗时间,用hashcode来记录对象的位置,来看一下。hash表中有1、2、3、4、5、6、7、8个位置,存第一个数,hashcode为1,该数就放在hash表中1的位置,存到100个数字,hash表中8个位置会有很多数字了,1中可能有20个数字,存101个数字时,他先查hashcode值对应的位置,假设为1,那么就有20个数字和他的hashcode相同,他只需要跟这20个数字相比较(equals),如果没一个相同,那么就放在1这个位置,这样比较的次数就少了很多,实际上hash表中有很多位置,这里只是举例只有8个,所以比较的次数会让你觉得也挺多的,实际上,如果hash表很大,那么比较的次数就很少很少了。 通过对原始方法和使用hashcode方法进行对比,我们就知道了hashcode的作用,并且为什么要使用hashcode了。
4、equals方法和hashcode的关系
通过前面这个例子,大概可以知道,先通过hashcode来比较,如果hashcode相等,那么就用equals方法来比较两个对象是否相等,用个例子说明:上面说的hash表中的8个位置,就好比8个桶,每个桶里能装很多的对象,对象A通过hash函数算法得到将它放到1号桶中,当然肯定有别的对象也会放到1号桶中,如果对象B也通过算法分到了1号桶,那么它如何识别桶中其他对象是否和它一样呢,这时候就需要equals方法来进行筛选了。
1、如果两个对象equals相等,那么这两个对象的HashCode一定也相同
2、如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置
这两条你们就能够理解了。
5、为什么equals方法重写的话,建议也一起重写hashcode方法?
举个例子,其实就明白这个道理了。
比如:有个A类重写了equals方法,但是没有重写hashCode方法,看输出结果,对象a1和对象a2使用equals方法相等,按照上面的hashcode的用法,那么他们两个的hashcode肯定相等,但是这里由于没重写hashcode方法,他们两个hashcode并不一样,所以,我们在重写了equals方法后,尽量也重写了hashcode方法,通过一定的算法,使他们在equals相等时,也会有相同的hashcode值。
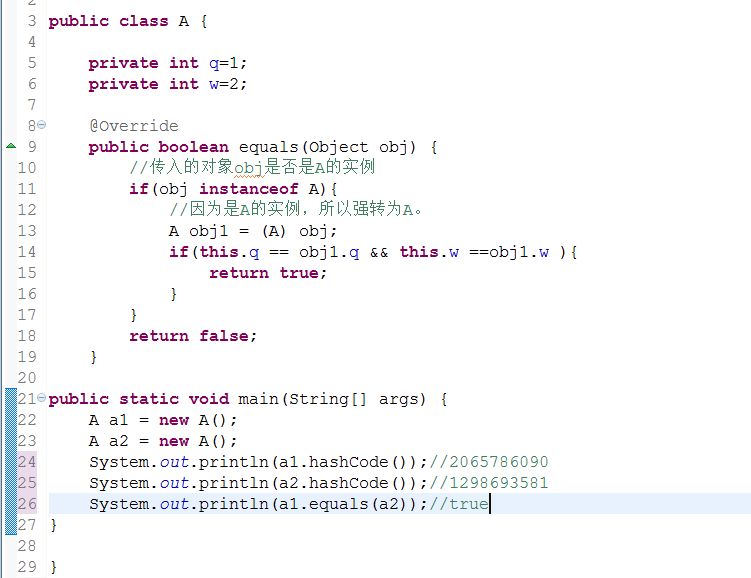
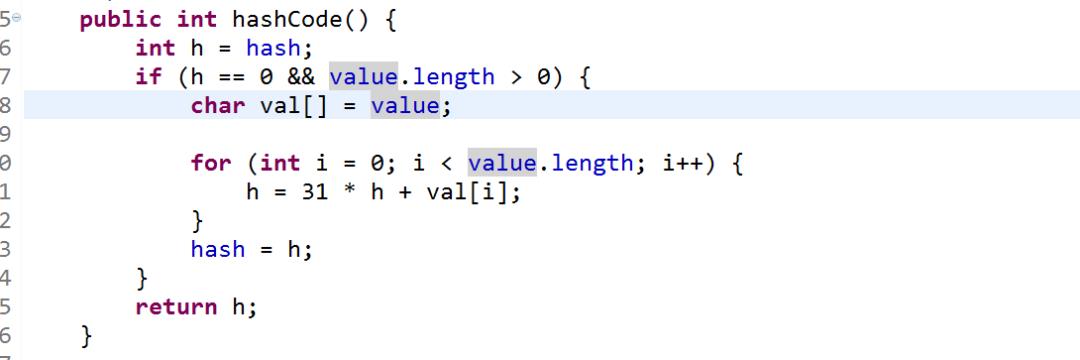
实例:现在来看一下String的源码中的equals方法和hashcode方法。这个类就重写了这两个方法,现在为什么需要重写这两个方法了吧?
equals方法:其实跟我上面写的那个例子是一样的原理,所以通过源码又知道了String的equals方法验证的是两个字符串的值是否一样。还有Double类也重写了这些方法。很多类有比较这类的,都重写了这两个方法,因为在所有类的父类Object中。equals的功能就是 “==”号的功能。你们还可以比较String对象的equals和==的区别啦。这里不再说明。

hashcode方法
6、JAVA多线程
一.线程的生命周期及五种基本状态
关于Java中线程的生命周期,首先看一下下面这张较为经典的图:
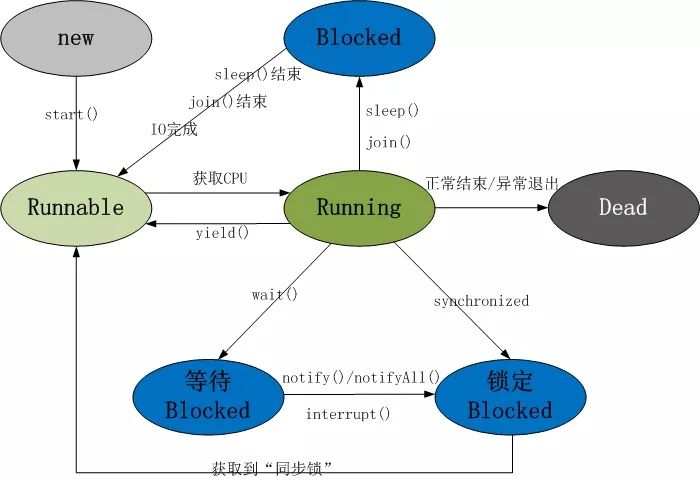
上图中基本上囊括了Java中多线程各重要知识点。掌握了上图中的各知识点,Java中的多线程也就基本上掌握了。主要包括:
Java线程具有五种基本状态
新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
就绪状态(Runnable):当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
1.等待阻塞:运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
2.同步阻塞:线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
3.其他阻塞:通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
二. Java多线程的创建及启动
Java中线程的创建常见有如三种基本形式
1.继承Thread类,重写该类的run()方法。
class MyThread extends Thread {
private int i = 0;
@Override
public void run() {
for (i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
}
public class ThreadTest {
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
if (i == 30) {
Thread myThread1 = new MyThread(); // 创建一个新的线程 myThread1 此线程进入新建状态
Thread myThread2 = new MyThread(); // 创建一个新的线程 myThread2 此线程进入新建状态
myThread1.start(); // 调用start()方法使得线程进入就绪状态
myThread2.start(); // 调用start()方法使得线程进入就绪状态
}
}
}
}
如上所示,继承Thread类,通过重写run()方法定义了一个新的线程类MyThread,其中run()方法的方法体代表了线程需要完成的任务,称之为线程执行体。当创建此线程类对象时一个新的线程得以创建,并进入到线程新建状态。通过调用线程对象引用的start()方法,使得该线程进入到就绪状态,此时此线程并不一定会马上得以执行,这取决于CPU调度时机。
2.实现Runnable接口,并重写该接口的run()方法,该run()方法同样是线程执行体,创建Runnable实现类的实例,并以此实例作为Thread类的target来创建Thread对象,该Thread对象才是真正的线程对象。
class MyRunnable implements Runnable {
private int i = 0;
@Override
public void run() {
for (i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
}
public class ThreadTest {
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
if (i == 30) {
Runnable myRunnable = new MyRunnable(); // 创建一个Runnable实现类的对象
Thread thread1 = new Thread(myRunnable); // 将myRunnable作为Thread target创建新的线程
Thread thread2 = new Thread(myRunnable);
thread1.start(); // 调用start()方法使得线程进入就绪状态
thread2.start();
}
}
}
}
相信以上两种创建新线程的方式大家都很熟悉了,那么Thread和Runnable之间到底是什么关系呢?我们首先来看一下下面这个例子。
public class ThreadTest {
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
if (i == 30) {
Runnable myRunnable = new MyRunnable();
Thread thread = new MyThread(myRunnable);
thread.start();
}
}
}
}
class MyRunnable implements Runnable {
private int i = 0;
@Override
public void run() {
System.out.println("in MyRunnable run");
for (i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
}
class MyThread extends Thread {
private int i = 0;
public MyThread(Runnable runnable){
super(runnable);
}
@Override
public void run() {
System.out.println("in MyThread run");
for (i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
}
}
}
同样的,与实现Runnable接口创建线程方式相似,不同的地方在于
Thread thread = new MyThread(myRunnable);
那么这种方式可以顺利创建出一个新的线程么?答案是肯定的。至于此时的线程执行体到底是MyRunnable接口中的run()方法还是MyThread类中的run()方法呢?通过输出我们知道线程执行体是MyThread类中的run()方法。其实原因很简单,因为Thread类本身也是实现了Runnable接口,而run()方法最先是在Runnable接口中定义的方法。
public interface Runnable {
public abstract void run();
}
我们看一下Thread类中对Runnable接口中run()方法的实现:
@Override
public void run() {
if (target != null) {
target.run();
}
}
也就是说,当执行到Thread类中的run()方法时,会首先判断target是否存在,存在则执行target中的run()方法,也就是实现了Runnable接口并重写了run()方法的类中的run()方法。但是上述给到的例子中,由于多态的存在,根本就没有执行到Thread类中的run()方法,而是直接先执行了运行时类型即MyThread类中的run()方法。
3.使用Callable和Future接口创建线程。具体是创建Callable接口的实现类,并实现clall()方法。并使用FutureTask类来包装Callable实现类的对象,且以此FutureTask对象作为Thread对象的target来创建线程。
看着好像有点复杂,直接来看一个例子就清晰了。
public class ThreadTest {
public static void main(String[] args) {
Callable<Integer> myCallable = new MyCallable(); // 创建MyCallable对象
FutureTask<Integer> ft = new FutureTask<Integer>(myCallable); //使用FutureTask来包装MyCallable对象
for (int i = 0; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
if (i == 30) {
Thread thread = new Thread(ft); //FutureTask对象作为Thread对象的target创建新的线程
thread.start(); //线程进入到就绪状态
}
}
System.out.println("主线程for循环执行完毕..");
try {
int sum = ft.get(); //取得新创建的新线程中的call()方法返回的结果
System.out.println("sum = " + sum);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
class MyCallable implements Callable<Integer> {
private int i = 0;
// 与run()方法不同的是,call()方法具有返回值
@Override
public Integer call() {
int sum = 0;
for (; i < 100; i++) {
System.out.println(Thread.currentThread().getName() + " " + i);
sum += i;
}
return sum;
}
}
首先,我们发现,在实现Callable接口中,此时不再是run()方法了,而是call()方法,此call()方法作为线程执行体,同时还具有返回值!在创建新的线程时,是通过FutureTask来包装MyCallable对象,同时作为了Thread对象的target。那么看下FutureTask类的定义:
public class FutureTask<V> implements RunnableFuture<V> {
//....
}
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
于是,我们发现FutureTask类实际上是同时实现了Runnable和Future接口,由此才使得其具有Future和Runnable双重特性。通过Runnable特性,可以作为Thread对象的target,而Future特性,使得其可以取得新创建线程中的call()方法的返回值。
执行下此程序,我们发现sum = 4950永远都是最后输出的。而“主线程for循环执行完毕..”则很可能是在子线程循环中间输出。由CPU的线程调度机制,我们知道,“主线程for循环执行完毕..”的输出时机是没有任何问题的,那么为什么sum =4950会永远最后输出呢?
原因在于通过ft.get()方法获取子线程call()方法的返回值时,当子线程此方法还未执行完毕,ft.get()方法会一直阻塞,直到call()方法执行完毕才能取到返回值。
上述主要讲解了三种常见的线程创建方式,对于线程的启动而言,都是调用线程对象的start()方法,需要特别注意的是:不能对同一线程对象两次调用start()方法。
三. Java多线程的就绪、运行和死亡状态
就绪状态转换为运行状态:当此线程得到处理器资源;
运行状态转换为就绪状态:当此线程主动调用yield()方法或在运行过程中失去处理器资源。
运行状态转换为死亡状态:当此线程线程执行体执行完毕或发生了异常。
此处需要特别注意的是:当调用线程的yield()方法时,线程从运行状态转换为就绪状态,但接下来CPU调度就绪状态中的哪个线程具有一定的随机性,因此,可能会出现A线程调用了yield()方法后,接下来CPU仍然调度了A线程的情况。
由于实际的业务需要,常常会遇到需要在特定时机终止某一线程的运行,使其进入到死亡状态。目前最通用的做法是设置一boolean型的变量,当条件满足时,使线程执行体快速执行完毕。如:
1 public class ThreadTest {
2
3 public static void main(String[] args) {
4
5 MyRunnable myRunnable = new MyRunnable();
6 Thread thread = new Thread(myRunnable);
7
8 for (int i = 0; i < 100; i++) {
9 System.out.println(Thread.currentThread().getName() + " " + i);
10 if (i == 30) {
11 thread.start();
12 }
13 if(i == 40){
14 myRunnable.stopThread();
15 }
16 }
17 }
18 }
19
20 class MyRunnable implements Runnable {
21
22 private boolean stop;
23
24 @Override
25 public void run() {
26 for (int i = 0; i < 100 && !stop; i++) {
27 System.out.println(Thread.currentThread().getName() + " " + i);
28 }
29 }
30
31 public void stopThread() {
32 this.stop = true;
33 }
34
35 }
7、Java Synchronize 和 Lock 的区别与用法
在分布式开发中,锁是线程控制的重要途径。Java为此也提供了2种锁机制,synchronized和lock。做为Java爱好者,自然少不了对比一下这2种机制,也能从中学到些分布式开发需要注意的地方。
我们先从最简单的入手,逐步分析这2种的区别。
一、synchronized和lock的用法区别
synchronized:在需要同步的对象中加入此控制,synchronized可以加在方法上,也可以加在特定代码块中,括号中表示需要锁的对象。
lock:需要显示指定起始位置和终止位置。一般使用ReentrantLock类做为锁,多个线程中必须要使用一个ReentrantLock类做为对象才能保证锁的生效。且在加锁和解锁处需要通过lock()和unlock()显示指出。所以一般会在finally块中写unlock()以防死锁。
用法区别比较简单,这里不赘述了,如果不懂的可以看看Java基本语法。
二、synchronized和lock性能区别
synchronized是托管给JVM执行的,而lock是java写的控制锁的代码。在Java1.5中,synchronize是性能低效的。因为这是一个重量级操作,需要调用操作接口,导致有可能加锁消耗的系统时间比加锁以外的操作还多。相比之下使用Java提供的Lock对象,性能更高一些。但是到了Java1.6,发生了变化。synchronize在语义上很清晰,可以进行很多优化,有适应自旋,锁消除,锁粗化,轻量级锁,偏向锁等等。导致在Java1.6上synchronize的性能并不比Lock差。官方也表示,他们也更支持synchronize,在未来的版本中还有优化余地。
说到这里,还是想提一下这2种机制的具体区别。据我所知,synchronized原始采用的是CPU悲观锁机制,即线程获得的是独占锁。独占锁意味着其他线程只能依靠阻塞来等待线程释放锁。而在CPU转换线程阻塞时会引起线程上下文切换,当有很多线程竞争锁的时候,会引起CPU频繁的上下文切换导致效率很低。
而Lock用的是乐观锁方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。乐观锁实现的机制就是CAS操作(Compare and Swap)。我们可以进一步研究ReentrantLock的源代码,会发现其中比较重要的获得锁的一个方法是compareAndSetState。这里其实就是调用的CPU提供的特殊指令。
现代的CPU提供了指令,可以自动更新共享数据,而且能够检测到其他线程的干扰,而 compareAndSet() 就用这些代替了锁定。这个算法称作非阻塞算法,意思是一个线程的失败或者挂起不应该影响其他线程的失败或挂起的算法。
三、synchronized和lock用途区别
synchronized原语和ReentrantLock在一般情况下没有什么区别,但是在非常复杂的同步应用中,请考虑使用ReentrantLock,特别是遇到下面2种需求的时候。
1.某个线程在等待一个锁的控制权的这段时间需要中断
2.需要分开处理一些wait-notify,ReentrantLock里面的Condition应用,能够控制notify哪个线程
3.具有公平锁功能,每个到来的线程都将排队等候
先说第一种情况,ReentrantLock的lock机制有2种,忽略中断锁和响应中断锁,这给我们带来了很大的灵活性。比如:如果A、B两个线程去竞争锁,A线程得到了锁,B线程等待,但是A线程这个时候实在有太多事情要处理,就是一直不返回,B线程可能就会等不及了,想中断自己,不再等待这个锁了,转而处理其他事情。这个时候ReentrantLock就提供了2种机制,第一,B线程中断自己(或者别的线程中断它),但是ReentrantLock不去响应,继续让B线程等待,你再怎么中断,我全当耳边风(synchronized原语就是如此);第二,B线程中断自己(或者别的线程中断它),ReentrantLock处理了这个中断,并且不再等待这个锁的到来,完全放弃。(如果你没有了解java的中断机制,请参考下相关资料,再回头看这篇文章,80%的人根本没有真正理解什么是java的中断)
这里来做个试验,首先搞一个Buffer类,它有读操作和写操作,为了不读到脏数据,写和读都需要加锁,我们先用synchronized原语来加锁,如下:
public class Buffer {
private Object lock;
public Buffer() {
lock = this;
}
public void write() {
synchronized (lock) {
long startTime = System.currentTimeMillis();
System.out.println("开始往这个buff写入数据…");
for (;;)// 模拟要处理很长时间
{
if (System.currentTimeMillis()
- startTime > Integer.MAX_VALUE)
break;
}
System.out.println("终于写完了");
}
}
public void read() {
synchronized (lock) {
System.out.println("从这个buff读数据");
}
}
}
接着,我们来定义2个线程,一个线程去写,一个线程去读。
public class Writer extends Thread {
private Buffer buff;
public Writer(Buffer buff) {
this.buff = buff;
}
@Override
public void run() {
buff.write();
}
}
public class Reader extends Thread {
private Buffer buff;
public Reader(Buffer buff) {
this.buff = buff;
}
@Override
public void run() {
buff.read();//这里估计会一直阻塞
System.out.println("读结束");
}
}
好了,写一个Main来试验下,我们有意先去“写”,然后让“读”等待,“写”的时间是无穷的,就看“读”能不能放弃了。
public class Test {
public static void main(String[] args) {
Buffer buff = new Buffer();
final Writer writer = new Writer(buff);
final Reader reader = new Reader(buff);
writer.start();
reader.start();
new Thread(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
for (;;) {
//等5秒钟去中断读
if (System.currentTimeMillis()
- start > 5000) {
System.out.println("不等了,尝试中断");
reader.interrupt();
break;
}
}
}
}).start();
}
}
我们期待“读”这个线程能退出等待锁,可是事与愿违,一旦读这个线程发现自己得不到锁,就一直开始等待了,就算它等死,也得不到锁,因为写线程要21亿秒才能完成 T_T ,即使我们中断它,它都不来响应下,看来真的要等死了。这个时候,ReentrantLock给了一种机制让我们来响应中断,让“读”能伸能屈,勇敢放弃对这个锁的等待。我们来改写Buffer这个类,就叫BufferInterruptibly吧,可中断缓存。
import java.util.concurrent.locks.ReentrantLock;
public class BufferInterruptibly {
private ReentrantLock lock = new ReentrantLock();
public void write() {
lock.lock();
try {
long startTime = System.currentTimeMillis();
System.out.println("开始往这个buff写入数据…");
for (;;)// 模拟要处理很长时间
{
if (System.currentTimeMillis()
- startTime > Integer.MAX_VALUE)
break;
}
System.out.println("终于写完了");
} finally {
lock.unlock();
}
}
public void read() throws InterruptedException {
lock.lockInterruptibly();// 注意这里,可以响应中断
try {
System.out.println("从这个buff读数据");
} finally {
lock.unlock();
}
}
}
当然,要对reader和writer做响应的修改
public class Reader extends Thread {
private BufferInterruptibly buff;
public Reader(BufferInterruptibly buff) {
this.buff = buff;
}
@Override
public void run() {
try {
buff.read();//可以收到中断的异常,从而有效退出
} catch (InterruptedException e) {
System.out.println("我不读了");
}
System.out.println("读结束");
}
}
/**
* Writer倒不用怎么改动
*/
public class Writer extends Thread {
private BufferInterruptibly buff;
public Writer(BufferInterruptibly buff) {
this.buff = buff;
}
@Override
public void run() {
buff.write();
}
}
public class Test {
public static void main(String[] args) {
BufferInterruptibly buff = new BufferInterruptibly();
final Writer writer = new Writer(buff);
final Reader reader = new Reader(buff);
writer.start();
reader.start();
new Thread(new Runnable() {
@Override
public void run() {
long start = System.currentTimeMillis();
for (;;) {
if (System.currentTimeMillis()
- start > 5000) {
System.out.println("不等了,尝试中断");
reader.interrupt();
break;
}
}
}
}).start();
}
}
这次“读”线程接收到了lock.lockInterruptibly()中断,并且有效处理了这个“异常”。
至于第二种情况,ReentrantLock可以与Condition的配合使用,Condition为ReentrantLock锁的等待和释放提供控制逻辑。
例如,使用ReentrantLock加锁之后,可以通过它自身的Condition.await()方法释放该锁,线程在此等待Condition.signal()方法,然后继续执行下去。await方法需要放在while循环中,因此,在不同线程之间实现并发控制,还需要一个volatile的变量,boolean是原子性的变量。因此,一般的并发控制的操作逻辑如下所示:
volatile boolean isProcess = false;
ReentrantLock lock = new ReentrantLock();
Condtion processReady = lock.newCondtion();
thread: run() {
lock.lock();
isProcess = true;
try {
while(!isProcessReady) { //isProcessReady 是另外一个线程的控制变量
processReady.await();//释放了lock,在此等待signal
}catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
lock.unlock();
isProcess = false;
}
}
}
}
这里只是代码使用的一段简化,下面我们看Hadoop的一段摘取的源码:
private class MapOutputBuffer<K extends Object, V extends Object>
implements MapOutputCollector<K, V>, IndexedSortable {
...
boolean spillInProgress;
final ReentrantLock spillLock = new ReentrantLock();
final Condition spillDone = spillLock.newCondition();
final Condition spillReady = spillLock.newCondition();
volatile boolean spillThreadRunning = false;
final SpillThread spillThread = new SpillThread();
...
public MapOutputBuffer(TaskUmbilicalProtocol umbilical, JobConf job,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
...
spillInProgress = false;
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
spillLock.lock();
try {
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw new IOException("Spill thread failed to initialize", e);
} finally {
spillLock.unlock();
}
}
protected class SpillThread extends Thread {
@Override
public void run() {
spillLock.lock();
spillThreadRunning = true;
try {
while (true) {
spillDone.signal();
while (!spillInProgress) {
spillReady.await();
}
try {
spillLock.unlock();
sortAndSpill();
} catch (Throwable t) {
sortSpillException = t;
} finally {
spillLock.lock();
if (bufend < bufstart) {
bufvoid = kvbuffer.length;
}
kvstart = kvend;
bufstart = bufend;
spillInProgress = false;
}
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
spillLock.unlock();
spillThreadRunning = false;
}
}
}
代码中spillDone 就是 spillLock的一个newCondition()。调用spillDone.await()时可以释放spillLock锁,线程进入阻塞状态,而等待其他线程的 spillDone.signal()操作时,就会唤醒线程,重新持有spillLock锁。
这里可以看出,利用lock可以使我们多线程交互变得方便,而使用synchronized则无法做到这点。
最后呢,ReentrantLock这个类还提供了2种竞争锁的机制:公平锁和非公平锁。这2种机制的意思从字面上也能了解个大概:即对于多线程来说,公平锁会依赖线程进来的顺序,后进来的线程后获得锁。而非公平锁的意思就是后进来的锁也可以和前边等待锁的线程同时竞争锁资源。对于效率来讲,当然是非公平锁效率更高,因为公平锁还要判断是不是线程队列的第一个才会让线程获得锁。
以上是关于一些JAVA面试的常见问题汇总的主要内容,如果未能解决你的问题,请参考以下文章