JAVA面试又被问一致性hash算法,到底啥是一致性hash?
Posted 社评社
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA面试又被问一致性hash算法,到底啥是一致性hash?相关的知识,希望对你有一定的参考价值。
我来给大家讲讲一致性hash算法,如果有理解错误的地方,也请大家留言指正。
单台服务器
就拿Redis来举例吧,我们经常会用Redis做缓存,把一些数据放在上面,以减少数据的压力。
当数据量少,访问压力不大的时候,通常一台Redis就能搞定,为了高可用,弄个主从也就足够了;
多台服务器数据分布的问题
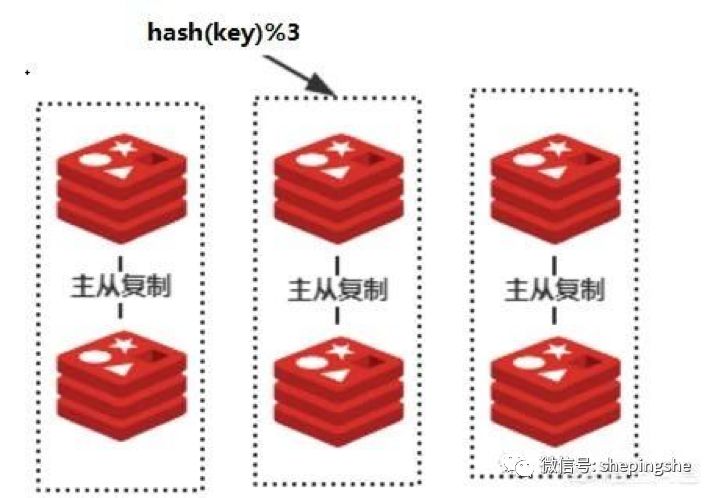
当数据量变大,并发量也增加的时候,把全部的缓存数据放在一台机器上就有些吃力了,毕竟一台机器的资源是有限的,通常我们会搭建集群环境,让数据尽量平均的放到每一台Redis中,比如我们的集群中有三台Redis。
那么如何把数据尽量平均地放到这三台Redis中呢?最简单的就是求余算法:hash(key)%N,在这里N=3。
看起来非常地美好,因为依靠这样的方法,我们可以让数据平均存储到三台Redis中,当有新的请求过来的时候,我们也可以定位数据会在哪台Redis中,这样可以精确地查询到缓存数据。
但是注意了,如果要增加一台Redis,或者三台中的一台Redis发生了故障变成了两台,那么这个求余算法就会变成:hash(key)%4或者hash(key)%2;那么可以想象一下,当前大部分缓存的位置都会是错误的,极端情况下,所有的缓存的位置都要发生改变,这样会造成【缓存雪崩】。
一致性hash算法
一致性hash算法可以很好地解决这个问题,它的大概过程是:
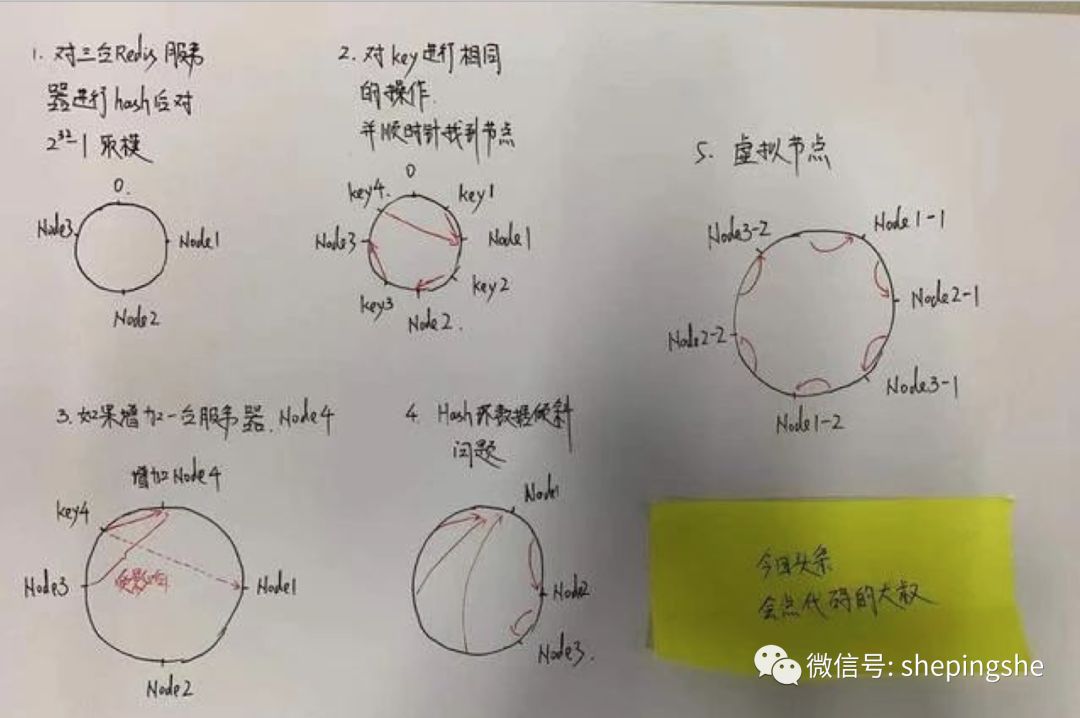
o 把0作为起点,2^32-1作为终点,画一条直线,再把起点和终点重合,直线变成一个圆,方向是顺时针从小到大。0的右侧第一个点是1,然后是2,以此类推。
o 对三台服务器的IP或其他关键字进行hash后对2^32取模,这样势必能落在这个圈上的某个位置,记为Node1、Node2、Node3(图1)。
o 然后对数据key进行相同的操作,势必也会落在圈上的某个位置;然后顺时针行走,可以找到某一个Node,这就是这个key要储存的服务器(图2)。
o 如果增加一台服务器或者删除一台服务器,只会影响部分小部分数据(图3)。
o 如果节点太少或分布不均匀的时候,容易造成数据倾斜,也就是被数据会集中在某一台服务器上(图4)。
o 为了解决数据倾斜问题,一致性Hash算法提出了【虚拟节点】,会对每一个服务节点计算多个哈希,然后放到圈上的不同位置(图5)。
o 原谅我的小学生字体,下一次我一定好好地画一画图,电脑上画的那种。
用最通俗易懂的方式来解释下一致性hash算法;
首先我们要明确的是一般的hash算法在取模的时候往往跟实际应用有关!
比如说nginx hash的时候,会根据后台的应用服务器数量进行取模,比如说后台有四台应用,那么hash(key)%4 =(0,1,2,3),就能获取到具体哪一台的标号,这个时候如果后台应用需要扩容,那么hash算法就要换成hash(key)%6 =(0,1,2,3,4,5),分布到六台不同的机器上去请求,看着没什么太大问题,但是如果我们把场景切换为数据库根据业务主键business_no进行hash的的分库分表结构,在切换之后,因为hash算法的改变,原本的数据落在4,但是hash结果为5,肯定查不到原来的数据,这就出现了数据查询错误问题!
而如果上述问题是出现在redis上,因为数据大量不命中,大量的查询降落在底层的数据库上,严重的话发生缓存雪崩问题,导致数据库系统乃至整个系统全部雪崩;
下面详细说下一致性hash算法(以redis存储为例),来解决上面遇到的问题:
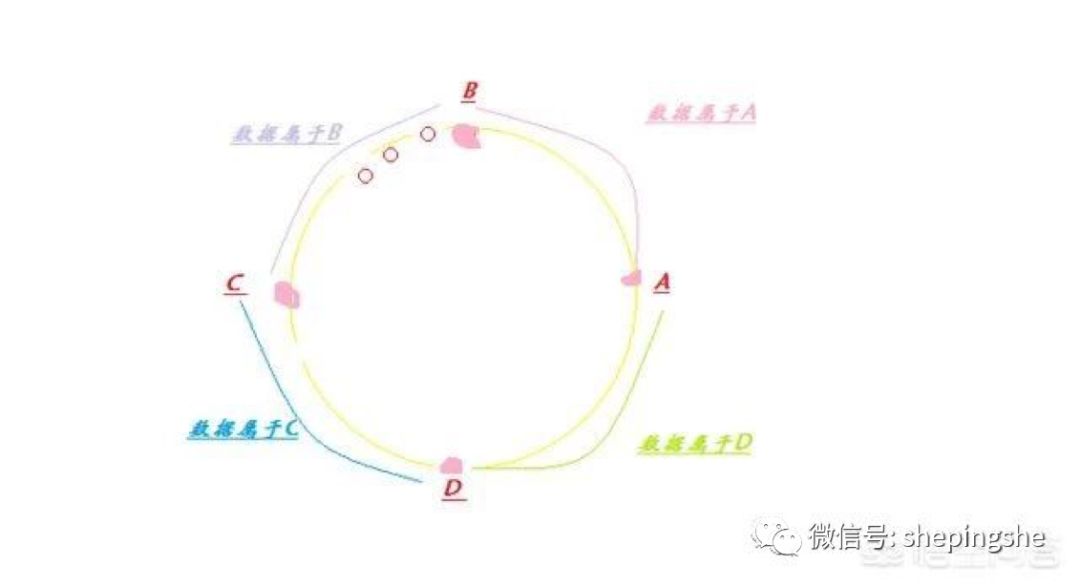
一致性hash算法,不管你的应用有多少,都使用2^32(2的32次方)作为取模,并且将0和2^32-1首尾相连,结成一个环,这样所有使用一致性hash算法的数据都大概率均匀的落在这个环上;
落在环上面的数据又是怎么落到不同的redis服务器上的呢?我们不管是使用redis服务器的IP也好,域名也好,总之是一个唯一标识,通过计算hash值也落在这个环上(ABCD服务器节点),然后规定把落在环上的数据以顺时针的方向旋转,保存在遇到的第一个节点(服务器)上,这很好理解;如下图所示:
使用了一致性hash之后,我们服务器的扩展也会变得很容易,如果监控到某个节点(D)压力比较大,则通过计算hash值,在这个节点的逆时针上游加一个服务器E(A和D之间),如下图:
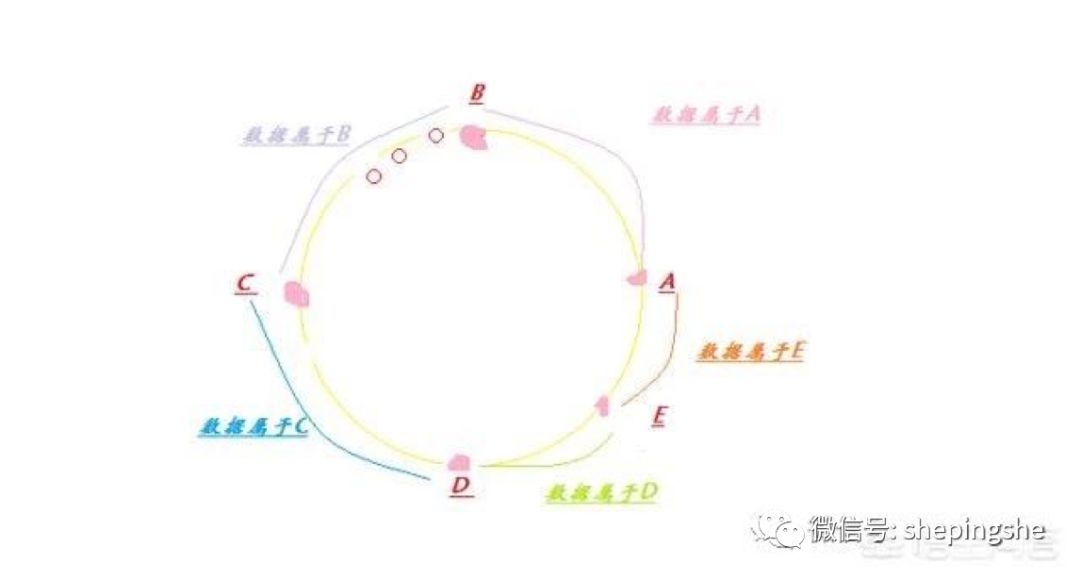
这时候如果有请求进来,在整个环上的数据,只有A到E之间的数据获取不到从而对下层数据库有影响,而其他的所有数据不会有任何影响,由此可见使用一致性hash扩展是十分方便的!
一致性hash存在的问题:
1,雪崩效应:假设我们并没有上面说的类似的监控,或者某个节点(B)的数据激增,在我们的反应之前,这个时候这个节点出现了宕机,那么所有的数据请求将迅速落在A上,A不仅承受自己的数据,还要承受B的,肯定也马上奔溃,最终整个缓存系统发生缓存雪崩效应!
2,分布不均匀:上面的例子对于hash算法过于理想化了,比如ABCD四台服务器的hash值刚好为1,2,3,4也就代表着hash值在(4,2^32-1]这个范围的所有数据将落在一台服务上,这也将是灾难性的。。。
那么我们怎么解决这种数据分布十分不均匀的情况呢?
解决办法:最好的办法就是增加虚拟节点,截图如下:
ABCD对每个服务器A,B,C,D都新增了一个(也可以是多个)虚拟节点,也就是说现在A节点可以接受B2-A1加上C1到A2的数据,假设A服务宕机了,那么A1的数据将落在C2(也就是C),A2的数据将落在D1(也就是D)上,也就是说随着崩溃的服务器增多,相对应的数据将分散在更多的服务器,从而防止整个缓存系统的持续雪崩效应;
经过上述的案例,我们能看到一致性hash遵循的原则有下列几个:①,平衡性:数据将尽可能的均匀分布在整个hash环上,
②,单调性:在扩展的时候,将保证原来的数据尽量少的落在新的节点上。
③,分散性:相同的内容尽量避免落在不同的节点上去!
一致性hash原理很简单,但是一致性hash算法广泛的用在了诸如redis集群,数据库分库分表等情景当中,良好解决了数据分布不均,扩展困难的难题,是大规模集群中的优良算法!
个人感觉本文中的解释还算通俗易懂,如果有不明白的朋友,可以私信我,我再解释下,后期会有更多的技术分享,也请持续关注,谢谢。。。
举个应用场景:分布式存储
现在互联网面对的都是海量的数据和海量的用户,我们为了提高数据的读取,写入能力,一般都采用分布式的方式来存储数据,比如分布式缓存。我们有海量的数据需要缓存,所以一台机器是肯定不够的,于是我们需要将数据分布在多台机器上。
该如何决定哪些数据放在那台机器上,可以借助数据分片的思想,采用hash算法对数据取hash值,然后对机器取模,这个最终值就是存储缓存的机器编号。
但是如果数据增多,原来的10台机器不够,需要扩容到13台机器,那么原来数据是通过与10来取模的,比如15这个数据,与10取模就是5,现在与13取模就是2。机器的编号完全变了,扩容并不是简单的增加机器,而是需要重新计算机器上的缓存存储位置。这无疑是一件很头疼的问题。
所以,我们需要一种方法,是的新加入机器后,并不需要做大量的数据搬迁,这时候就需要用到一致性hash算法了。
假设我们有k个机器,数据的hash范围是[0-Max],现在我们将范围划分为m个小区间(m要远大于k),每个机器负责m/k个区间,当有新机器加入时,我们只需要将某几个小区间的数据搬运到新的机器上即可,这样既不用全部搬移数据,也保持了各个机器的数据均衡。
以上是关于JAVA面试又被问一致性hash算法,到底啥是一致性hash?的主要内容,如果未能解决你的问题,请参考以下文章