5个机器学习开源项目,挑战你的数据科学技能!(附链接)
Posted 大数据文摘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5个机器学习开源项目,挑战你的数据科学技能!(附链接)相关的知识,希望对你有一定的参考价值。
大数据文摘授权转载自数据派THU
编译:张达敏
简介
越来越多的人开始踏入数据科学领域。不管你是应届毕业生、初入职场者,还是有一定相关经验的专业人士,亦或是机器学习的爱好者 – 任何人都想搭上数据科学的快车。
机器学习
如果你来自印度,相信你一定读过有关政府在数据领域投资的消息(2020年联邦预算)。当下是个投资自己的绝佳时机。
在许多开启自己数据科学生涯的绝佳方式中,投资自己是其中之一。以下是一个简化的流程:
-
找到你所感兴趣的机器学习开源项目。 -
对于该项目,了解当前领先的解决方案。 -
如果有相关的解决方案,从中汲取知识。但如果这种方案并不存在,就利用你所掌握的机器学习知识来创造一个。


Transformer架构的出现改变了自然语言处理。越来越多的自然语言处理框架开始进入大众视野,例如BERT, XLNet, GPT-2.
自然语言处理框架
https://www.analyticsvidhya.com/blog/2019/08/complete-list-important-frameworks-nlp/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
https://www.analyticsvidhya.com/blog/2019/09/demystifying-bert-groundbreaking-nlp-framework/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
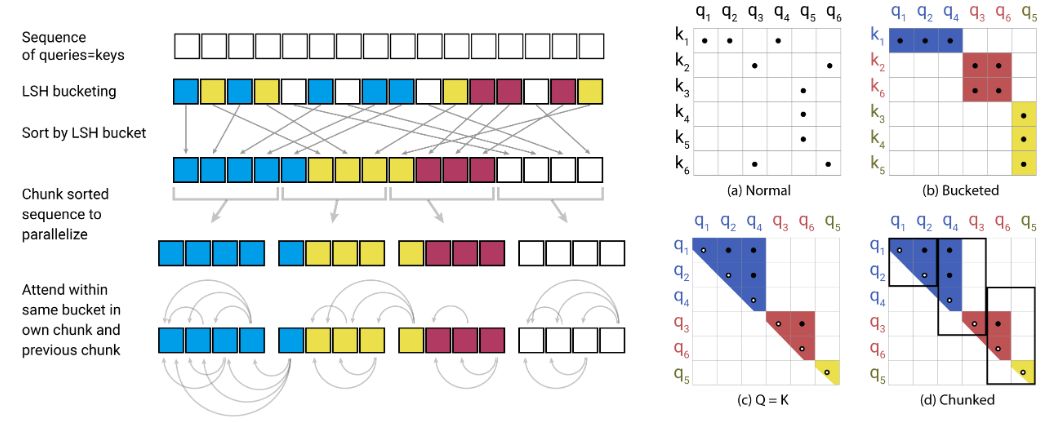
pip install reformer_pytorch-
How do Transformers Work in NLP? A Guide to the Latest State-of-the-Art Models
-
A Beginner-Friendly Guide to PyTorch and How it Works from Scratch
PandaPy – 你最爱的Python库

-
在小数据集上进行简单计算时(例如加法、乘法、取对数),PandaPy比Pandas快25至80倍。 -
在小数据集上进行表操作时(例如聚合、透视、删除、合并、填充缺失数据),PandaPy比Pandas快5-100倍。 -
在大多数小数据使用情况下,PandaPy比Dask,Modin Ray和Pandas都要快。
!pip3 install pandapy谷歌地球引擎 – 用300多个Jupyter Notebook来分析地理空间数据
-
Earth Engine Python API -
Folium -
Geehydro
这个Github库有大量的Python例子能够帮你上手。好好研究一下,玩得开心!
这还有一篇很优秀的文章能帮你上手地理空间数据:
https://medium.com/analytics-vidhya/geospatial-data-and-its-role-in-data-science-c60b2e0d3f7f
AVA – 自动化视图分析
还有一个很优秀的数据可视化概念。数据发掘自动化的想法已经流传一段时间了,但一直没有实质性的框架出现。直到现在:
“AVA,自动化视图分析的简写,是阿里巴巴为了让视图分析更智能化和自动化所创造的框架。”
我强烈推荐你了解下面的资源,它们能帮你创建和加强数据可视化简介:
Mastering Tableau from Scratch: Become a Data Visualization Rockstar
Collection of Data Visualization Articles and Tutorials
https://www.analyticsvidhya.com/blog/tag/data-visualization/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
Fast Neptune – 你机器学习项目的加速器
现如今,不论是学术界还是工业界,生产力是任何一个机器学习项目的重要指标。我们需要追踪每一个测试、每一次迭代,以及每对参数和结果。
“Fast Neptune库能够快速记录开展机器学习测试所需的所有信息。也就是说,Fast Neptune是上文所提及的生产力问题的答案。”
Fast Neptune有几个特性能够帮我们进行快速测试(从上文链接里引用):
有关运行代码的机器的元数据,包括系统及系统版本。
对测试所在的Notebook的相关要求。
在测试过程中用到的参数,也就是你想追踪的变量的值的命名。
测试过程中你想记录使用的代码。
是不是很直观?你只用一行代码就可以安装Fast Neptune:
pip install fast-neptune几个值得关注的框架:
我还想介绍其他几个2020年1月发行的框架,你应该关注一下:
1. Thinc:这是一个spaCy作者制作的轻量化深度学习库。Thinc“为composing model提供一个优雅、能够类型检查、功能化编程的接口,同时为其他框架定义的层提供支持,例如PyTorch,TensorFlow或者MXNet”
Thinc
spaCy
PyTorch
https://www.analyticsvidhya.com/blog/2019/09/introduction-to-pytorch-from-scratch/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
TensorFlow
https://www.analyticsvidhya.com/blog/2016/10/an-introduction-to-implementing-neural-networks-using-tensorflow/?utm_source=blog&utm_medium=5-open-source-machine-learning-projects-data-scientist
2. 谷歌仿人类生成聊天机器人:谷歌创造的Meena是一个拥有26亿参数点对点训练的神经交谈式模型。相比于行业领先的聊天机器人,Meena能够引导更合理更具体的对话。谷歌会开源Meena的代码吗?我们还不得而知,但这是个值得关注的事。
谷歌仿人类生成聊天机器人
结束语
2020是机器学习快速发展的一年。先进技术会继续快速进化,以至于让新手难以快速上手。
这也是我发表这些月刊的初衷,把最有相关性和实用性的开源机器学习项目带给我们的社区。
你有没有其他想了解的机器学习项目或框架?我非常想在下面的评论区听听你的想法和主意。让我们一起头脑风暴。
你也可以通过Analytics Vidhya的安卓软件阅读这篇文章。

“宅”家发呆,不如学嗨
手把手教你关联数据的深度分析
配套TigerGragh部署与实战解析
快扫码到碗里来~
实习/全职编辑记者招聘ing
以上是关于5个机器学习开源项目,挑战你的数据科学技能!(附链接)的主要内容,如果未能解决你的问题,请参考以下文章