TiDB与gRPC的那点事
Posted 聊聊架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TiDB与gRPC的那点事相关的知识,希望对你有一定的参考价值。
如果有关注 TiDB 的朋友可能注意到,我们在上个月的 RC3 版本中已经完成了将 TiDB 中的 RPC 框架替换成了 gRPC,这个工作其实已经铺垫了快一年了,如果装逼一点说的话,其实 gRPC 开源的第一天看了一眼设计和哲学,就决定在 TiDB 中使用它。
今天抽空写一下背后的一些思考和在这个过程中的一些经验,本次分享不太会介绍大家怎么去用 gRPC,可能更加偏向一些为什么的问题。
其实做分布式系统那么久,几乎也是天天和 RPC 打交道,要说 各个模块是系统的筋肉,那 RPC 就是整个系统的血管,数据的流通,信令的传递,都离不开 RPC。
RPC 并不是一个固定的东西,可重可轻,重的如同 MS 的 DCOM,JAVA 的 EJB,轻的 HTTP 也可以说是 RPC,甚至自己写个 TCP 的文本通信协议也算。
大家也都知道 Google 内部其实没怎么用 gRPC,大量使用的是 Stubby,它作为 gRPC 的前身,也是一个 Protobuf RPC 的实现,因为大量依赖了 Google 的其他基础服务所以不太方便开放出来给社区使用。
随着 SPDY / QUIC,乃至 HTTP/2 的成熟,Google 决定用这些更加标准的组件来构建一个新的 RPC 框架,也就是 gRPC。不过这个项目过于庞大,而且 Google 内部 Stubby 已经用了超过 10 年,很难直接替换,毕竟程序员最烦的事情之一就是去改跑着好好的老代码。。。
不过 anyway,尽管 gRPC 没有在 Google 内部广泛使用,也是给社区带来了一个非常好的基础组件,现在为止包括ETCD / Kubernetes / TiDB在内的大量社区顶级开源分布式项目都在使用它。
有人说,RPC 多简单啊,不就是一个长连接,Sender 和 Reciver 来回发包嘛,顶多再搞个服务发现做 Failover,搞得那么复杂为啥。另外要强大不是已经有 EJB 什么的嘛,gRPC 的意义何在?我想从官方的 gRPC 的设计动机和原则说起:
1、Google 应该是践行服务化的先驱之一,在业界没那么推崇微服务的时代,Google 就已经大规模的微服务化。
微服务的精髓之一就是服务之间传递的是可序列化消息,而不是对象和引用,这个思想是和 DCOM 及 EJB 完全相反的。只有数据,不包含逻辑;这个设计的好处不用我多说也很好理解,参考 CSP 。
2、Protobuf 作为一个良好的序列化方案,注意,只是 序列化(尽管 pb 也有定义 rpc service 的能力,Protobuf 默认生成的代码并不包含 RPC 的实现),它并不像 Thrift 天生就带一个 RPC Framework,相对的来说比较轻。
在 gRPC 的设计中,一个很重要的原则就是 Payload agnostic,RPC 框架不应该规定用的是什么 payload 格式,可以是 Protobuf,JSON,XML,这也让 gRPC 的设计和层次更加清晰。
3、比传统的 Request / Response 更丰富的 API Interface,这个是我们使用 gRPC 的重要理由,gRPC 不仅支持传统的一应一答的模式,更是支持三种 Streaming 的调用方式,现代的业务经常会需要传输大的数据流,Streaming API 的设计让这些业务写起来轻松很多。
4、有了 Streaming 就不可避免地需要引入 Flow-control ,这点 gRPC 的处理很聪明,直接依赖了 HTTP/2,在流控这边不怎么用操心,顺带还可以用 HTTP 反向代理做负载均衡。
但是另一方面也会带来更多的调优复杂度,毕竟和 Web 的使用场景不太一样,比如默认的 INITIAL_WINDOW_SIZE 在 gRPC 里是 64k,太小,吞吐上不去,需要人工改大。
5、另一方面由于直接使用了 HTTP/2,TLS 的支持就几乎是天然的,对于 TiDB 这样的商业数据库而言,传输层加密是一个很重要的功能,在 gRPC 中直接就可以支持。本着不重新造轮子的原则,直接用 gRPC 就好了。
下面是 TiDB 整个项目的架构图:
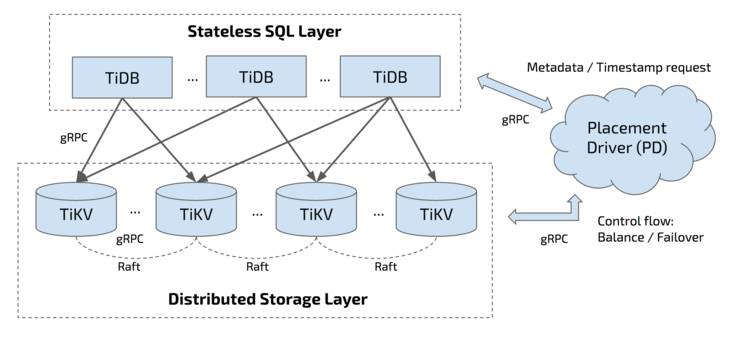
大家也都知道,TiDB 的底层存储 (TiKV) 是使用 Rust 开发的,至于为啥用 Rust 我在其他文章里说的比较多了,也不是今天的重点就不展开了。
当时我们决定采用 gRPC 的时候摆在我们面前的一个很现实的问题是 gRPC 并没有 Rust 语言的实现,而且另一个更大的问题是,Rust 甚至还没有 HTTP/2 的实现。
但是呢,不能因为这个原因不用呀,我们公司的做事风格还是拥抱社区,如果没有社区就自己创造社区。
刚好那个时候我在旧金山,在 Mozilla 总部和 Rust core team 的团队提到这个事情,后来对方介绍了 Yandex 的一个工程师,也是 Rust proto3 库的作者,他开了个坑开始实现 Rust HTTP/2 library 和 gRPC 的 pure Rust 实现,应该是 2016 年 9 月前后,一开始我们非常期待啊,也一直在帮助这个库完善。
后来大概在 2017 年 3 月,整个 rust gRPC 觉得大概可用了,然后 Yandex 这个哥们进度有点慢了,我们于是只好把这个坑接过来自己填,同时往 TiKV 上整合。
大概花了一个多月的时间,完成以后在我们的测试平台上一测,发现稳定性有很大的问题,经过大概两个月艰苦的修 Bug 的过程,仍然看不到希望。
而且毕竟不是官方的作品,和主干 Features 的合并也牵扯了很大精力,虽然也想过把这个项目捐给 gRPC 官方,但是估计 gRPC 官方也没有人能维护这个项目,所以也还是我们自己维护,最后没办法,我们发版本的压力也很大,只好另想办法。
大家也都知道 gRPC 的官方主要维护的就三种语言:C / Java / Go,至于 C++ / Python / Ruby 什么的都是在 C 的 gRPC core 之上进行封装的,但是没有 Rust。
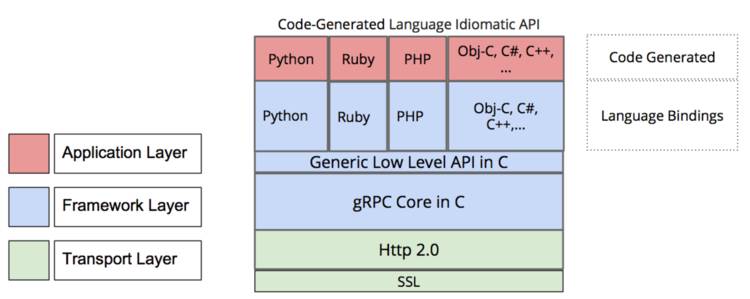
幸运的是,Rust 对于 C ABI 支持很好,毕竟后端直接就是 llvm ,性能上更没有什么损失,直接可以封装一下得到一个 Rust 的 gRPC 库。其实现在看看,一开始就应该这样,在追求纯 Rust 实现 gRPC 库上我们浪费了一些时间,是一个失误。
在我们官方 Blog 的一篇文章里,我们描述了我们的 gRPC-rs 的设计:
https://zhuanlan.zhihu.com/p/27995238,
这里我也不想赘述,总的来说,从最后的完成时间来看,估计也就花了大概 1 人月的时间,而且整个 core 的稳定性也有保证。
值得一提的是在我们的 gRPC-rs 中,并不是简单地做了一层 gRPC core 的 wrapper 就完事了,我们使用了 futures-rs,将 Futures 引入 RPC 的调用 API 中的一个好处就是很多异步逻辑可以用近似同步的书写方式(组合子)来写,程序看起来会更加清晰。
详细内容就不展开了,有兴趣的可以看看
github.com/pingcap/grpc-rs ,
也欢迎参与一起开发。
在完成 gRPC 库的 Rust 语言移植后,摆在我们眼前的一个重大的问题就是性能问题,在 gRPC 之前,我们使用的是一个自己写的很裸的 Protobuf RPC 实现,简单得不能再简单,长连接,Protobuf Payload,只有 Req / Resp 模式,但是简单也有简单的好处,几乎没有太多性能的损失,但是也有简单的坏处:
之前的实现 scale 起来比较麻烦,用 gRPC 的话 scale 只需要改改 gRPC 线程数就好。最开始直接换成 gRPC 后,延迟性能和吞吐都有 30% 以上的下降,同时观察到 CPU 的消耗是原来的 200%,然后就开始了调优之路。
其实 gRPC 本身的设计并不差,核心 task 的异步化调用的设计采用了组合子还是蛮巧妙的 :
https://github.com/grpc/grpc/blob/master/doc/combiner-explainer.md,
另外基于 epoll 封装了一套类似 IOCP 机制,在官方的设计文档中有很好的解释
https://github.com/grpc/grpc/blob/master/doc/epoll-polling-engine.md。
但是由于整体依赖了 HTTP/2,所以比裸的 RPC 还是多出了很多工作,主要集中在 HTTP/2 的包处理上,所以我们的性能调优也是集中在 HTTP/2 这边。
比如,上面提到的用于 HTTP/2 流控的 INITIAL_WINDOW_SIZE ,默认 64k,调大有助于提高吞吐,比如参见社区的这个 issue:
https://github.com/grpc/grpc-go/issues/760
另外 HTTP/2 是单连接的,实际测试发现也制约了吞吐,我们实践中不管是 TiDB 连接 TiKV 还是 TiKV 之间的连接都是采用多个 gRPC client 的方式来同时建立多个 HTTP/2 连接。
如果你知道自己的 workload 的大小,通过适当的调整 GRPC_WRITE_BUFFER_HINT 改变 write buffer 的大小也能显著减少 syscall 的调用:
https://github.com/grpc/grpc/issues/9121;
GRPC_ARG_MAX_CONCURRENT_STREAMS规定在一个 HTTP/2 连接中最多存在多少 stream,在 gRPC 中一次 RPC 就是一个 stream。在 TiKV 的应用场景中,适当调高该参数同样有助于提高吞吐。
还有就是 gRPC 本身不适用于传送大文件的场景,见 issue:
https://github.com/grpc/grpc-go/issues/414 。
TiKV 之间发送 snapshot 就是采用 issue 中推荐的方案,把大文件拆成多个 chunk 后使用 client streaming 发送。
总体感觉,现在 gRPC 这个项目还不是太成熟,从不断在重构 iomgr 这部分就能看出来,现在的 poll engine 的设计还是有很大的进步空间。
目前的效果 TiKV 吞吐已经和原来我们的手写的 RPC 框架持平,但是 CPU 的消耗略高一些,但是功能上已经让我们新功能的开发简化很多,总体来说一定是利大于弊的,我们也在紧跟 gRPC 社区,相信这些性能问题都能被解决。
黄东旭,知名开源软件作者,代表作品分布式 Redis 缓存方案 Codis,以及分布式关系型数据库 TiDB。曾就职与微软亚洲研究院,网易有道及豌豆荚,现任 PingCAP 联合创始人兼 CTO,资深基础软件工程师,架构师。擅长分布式系统以及数据库开发,在分布式存储领域有丰富的经验和独到的见解。
今日荐文
简单模式,带你速成微服务架构
最近 k8s 势头很火啊,无疑成为了时下最值得关注的技术之一,看来这场容器之战就要见分晓了!CNUTCon2017 上海站 特设“容器编排与管理”专场,邀请了来自 eBay、腾讯、京东的大咖现场分享他们在这方面的最新技术实践,届时可以面对面深入交流!目前大会 9 折限时优惠报名中,点击阅读原文先睹为快!
以上是关于TiDB与gRPC的那点事的主要内容,如果未能解决你的问题,请参考以下文章