去哪儿网前后端分离实践
Posted 前端之巅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了去哪儿网前后端分离实践相关的知识,希望对你有一定的参考价值。
去哪儿网主要有三种前后端的分离方案。
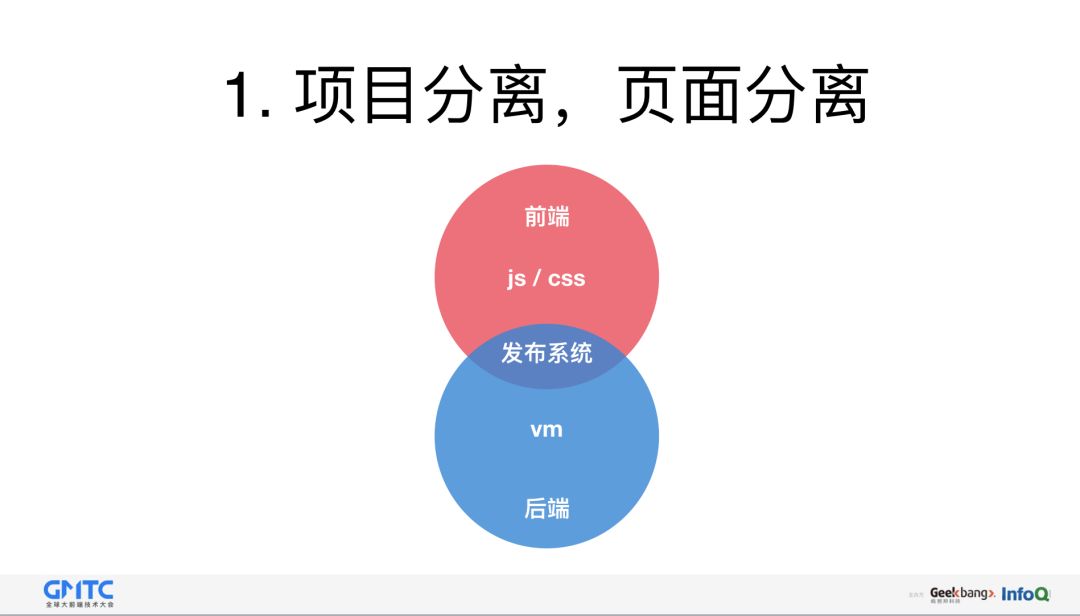
第一种是项目分离,承载页面分离。他的特点是简单,快速,前端只关注浏览器方面,除浏览器端之外都是后端负责。当然缺点是沟通成本高,前期,前端需要使用 ng 或者代理工具调试,后期,还要把页面给到后端,并且新建一个对应的路由。这样来来回回,调试非常的复杂,一旦前后端同学涉及到跨部门,跨楼层合作,这些成本又会相应的增加。
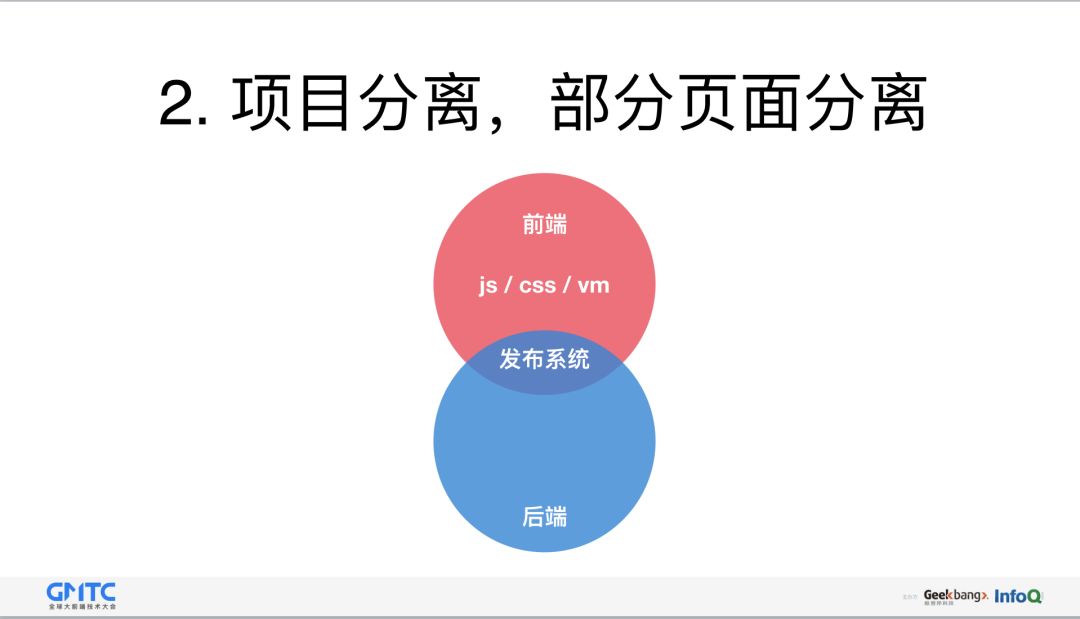
第二种方式还是项目分离,只是后端的页面,放到了前端项目里,后端只需要配置路由,最终上线时,由发布系统负责把前端中的页面,自动同步到后端相应的目录中。其中相应的目录需要前后端提前约定,不然后端在渲染页面的时候,就会找不到相应的文件。相比第一种方案,稍微有点进步。沟通成本会有一定的降低。不过如果需要在页面里做一些业务逻辑处理,还需要前端同学掌握和学习 velocity 语法,对于新同学而言看似掌握的了一门新语法,但实际操作起来并非想象中的流畅。另外考虑使用 React SSR 做页面同构直出,这个方案还有一定的难度。
在三种方案演变的过程中,为了让用户快速的看到页面,我们还设计了一个静态资源包的方案,这是它的整体的流程图:
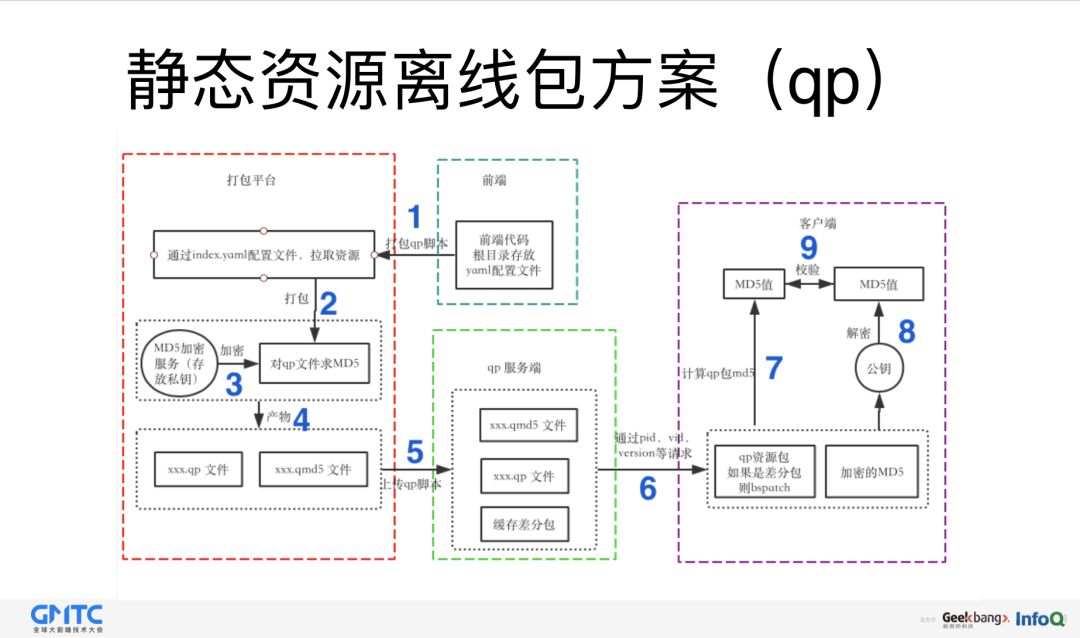
如果某项目想使用离线包,只需要简单的两步。
第一步,在项目的根目录中,新建 index.yaml 配置文件。主要配置唯一的 ID,面向的 ios 和 android 版本,打包的内容,忽略的内容等;
第二步,进入打包平台,选择相应的项目,即可通过自动化工具生成 qp 文件,并且自动上传到 qp 存放服务器中,其中会涉及到压缩,加密,打包等一系列操作,无需人工干预;
当用户进入到客户端,如果网络环境是 wifi,会自动拉取所有的离线包,非 wifi 网络,会选择性的下载相应的离线包。在进入相应的页面之前,会检查本地是否有对应的离线包,如果没有,会自动下载,走线上环境,反之,直接使用离线包中的资源。
用户对离线包是完全无感知和透明的。
大家从整个流程上看相关的一些功能,可能觉得很简单,不复杂,但实际上考虑的事情非常多:
1. 如何保证资源的安全性,不被中间人恶意篡改?
主要体现在 “传输安全”和“存储安全”上。这里我们采用的 RSA 加密方式,在打包平台,使用私钥对 qp 文件求 MD5,在客户端使用公钥对 qp 文件求 MD5 ,并和服务端所返回的 MD5 值进行对比校验,若相等,则校验通过。
2. 如何快速的回滚?
起初,采用的是假回滚的机制,简单来说,一旦离线包有 BUG ,在重新发一版。这种流程看起来或听起来没有什么问题,但实际操作起来,成本很高。因为按照重发的思路,会重新从线上拉取代码,如果这时线上代码变了,打出的包内容也会变。
3. 如何下线和强制更新
下线:当某次发版的 qp 包有 BUG 时,可以进行下线操作。针对的是当前指定版本 qp 包。
强制更新:当某个 qp 包希望用户下载到时,可以是用此操作,针对的是将要下载的 qp 包。
4. 如何提高更新率
不论架构多么简单或多么复杂,更新率问题是最能体现出框架的好与坏。上面提到,有强制更新和普通更新,由于两者的更新机制不同,最终的效果也不同。
最后,关于更新率的效果:
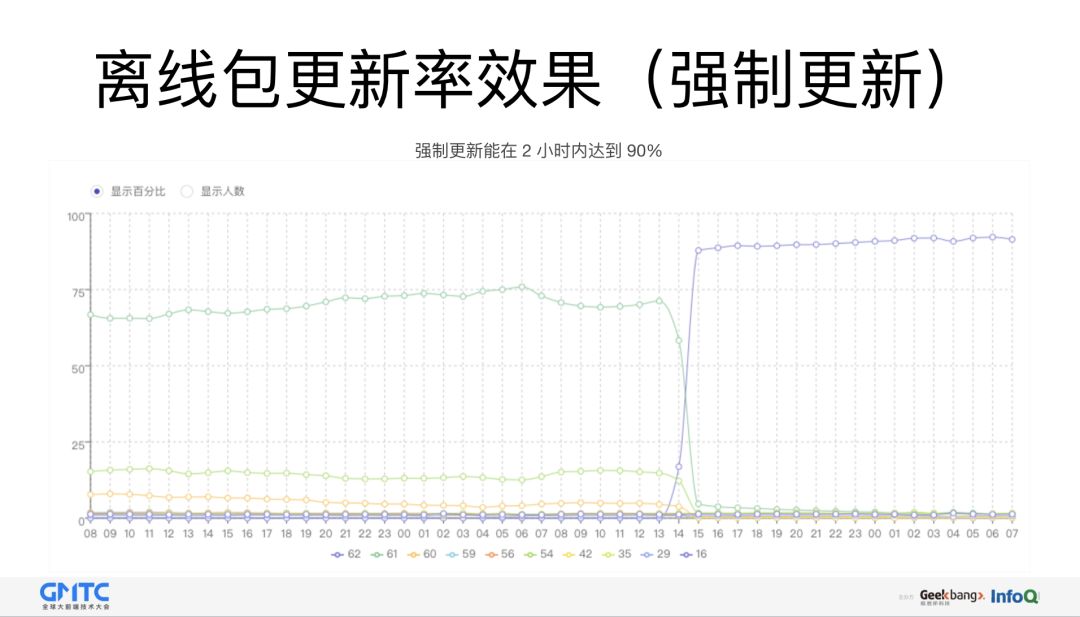
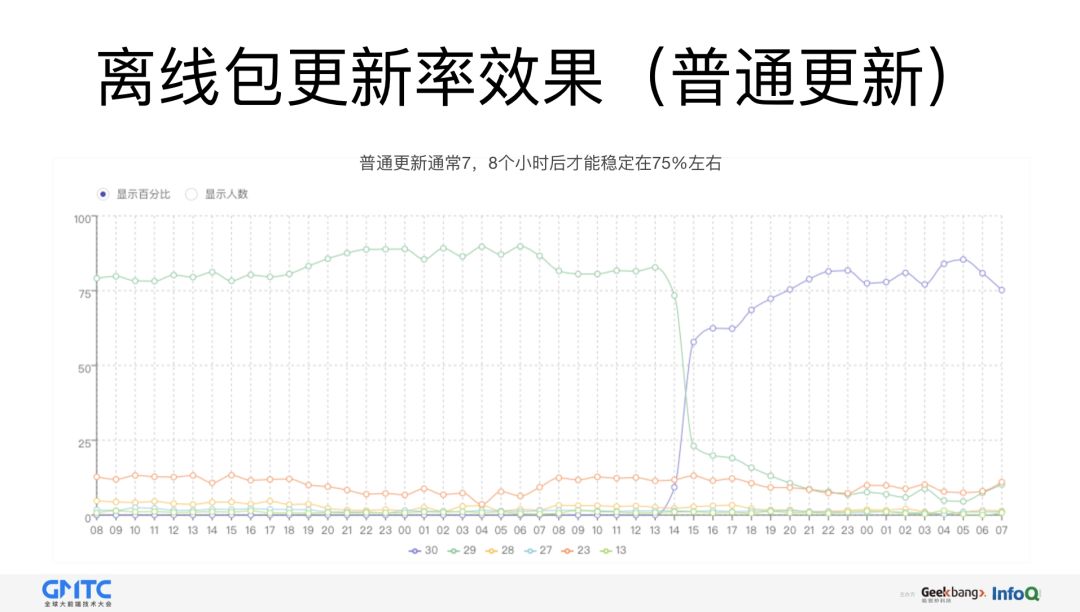
强制更新和普通更新这两个机制实现的方式不一样,所以它的更新效果也不一样,强制更新的效果最明显,它能在两个小时之内达到一个 90% 的水平,普通更新得七八个小时之后才能稳定到 75% 左右。
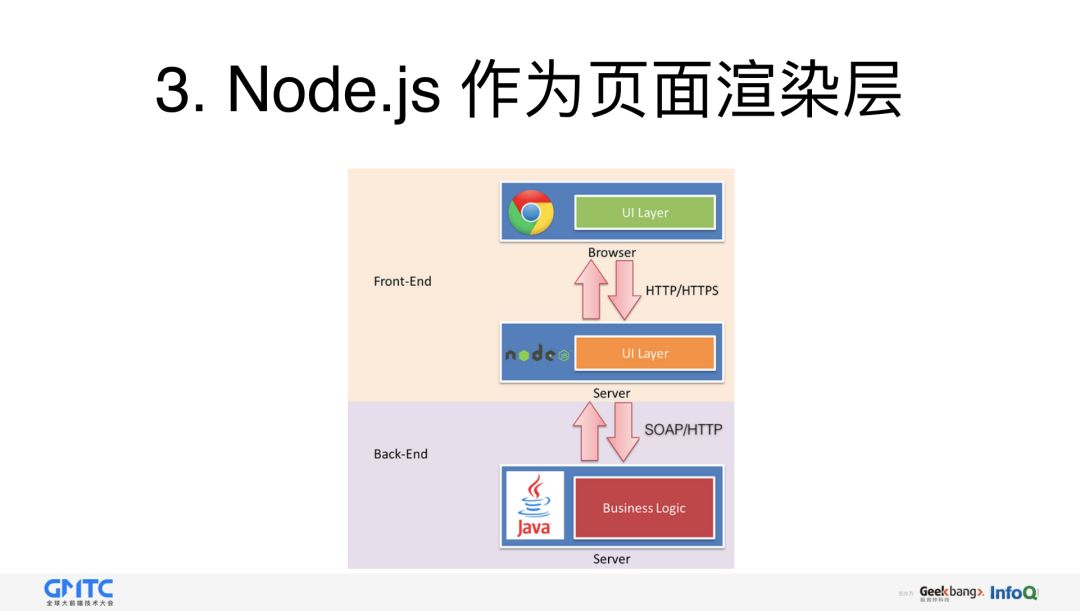
为什么 Node 没有大规模使用呢?我总结了大概的原因:
一些前端开发,只关注浏览器端,服务器端开发关注很少,或者根本就不关注 ;
认为 Node.js 只适合开发一些工具类的功能,对于后端开发是个玩具 ;
Node.js 的生态不如其他后端语言生态健全 ;
涉及到后端开发的知识面比较广,在没有这些基础知识或者经验积累的基础上,考虑问题比较片面,最终做出的系统问题比较多,容易被后端鄙视 ;
对于 Node.js 开发后端,对项目负责人要求比较高(项目的目录规范,开发规范,系统的安全性,稳定性,可靠性,扩展性,维护成本等);
以往前端不需要 7 x 24 保持待命状态,但是接触后端后,需要接收报警短信,有时出现问题还需要马上随时随地解决 ;
看似问题很多,但实质上只有两个原因,一方面,自身知识储备不够。第二方面,对 Node.js 了解不深,不敢应用在生成环境中,即使应用到生产环境,一旦出现问题,不能快速及时的处理,导致高层认为还不如其他后端语言稳定,降低了我们的话语权。
Node.js 到底能解决我们哪些的问题和痛点呢?
首先,提高开发效率,因为有了 Node 之后就不需要配置 nginx 了,也不需要配置一些代理工具了,所有的页面生命周期都是由前端统一去管理的,这时候不需要其他人进行合作。
第二,降低沟通成本,除了接口格式外,不需要和后端进行交互了;
第三,前后端职责也更为清晰,因为这时候,界限更为清晰了,后端只负责生产数据,它只提供数据就可以了,至于数据怎么消费,以及怎么用,都由前端去做;
第四,可以同时使用 React SSR 技术,做到首屏渲染,提高用户体验,除了首屏之外,还可以做异步的加载、SEO 等操作。
最后,Node.js 可提供一些服务,不仅能让我们使用,还可以对外使用,如 RESTful API,这样就不用有求于后端了。
三年前,公司内部就搞了一套基于 Express 的 Node.js 解决方案,包含日志收集,监控,多进程,异常,模板等插件,方案本身也很全面,但在实际项目使用过程中,或多或少的有些不便,主要体现:
如何确定项⽬目⽬目录划分的规范,命名规范 (view or views);
确定规范后,如何保证⼤大家都认可,并且严格遵守;
如何保证系统的安全性、稳定性和扩展性,怎么保证和我们内部系统做很无缝的去对接,这就要求有很好的扩展性;
守护进程程序的选择 (pm2 or supervisor);
怎么保证多环境运⾏行行规则 (local / beta / prod),因为在我们实际项目中,可能对我们的 Local 或者对 Bata 或者对 PID 都有不同的规则,如果这时候没有去做这件事,就有可能对我们的实际应用有可能造成一定的障碍;
如何利利⽤用系统 cpu 多核,以及多进程之间的通信。
针对这些问题,内部也进行了一些改进,但有些功能还是有些不尽人意。
在 17 年 4 月份,团队内部又重新开始 Review 和调研。发现国内有两个框架做的比较好,一个是 360 团队的 Thinkjs ,另一个是阿里的 Eggjs ,两个框架实现目的也是一致,只是使用的方式有些差别。
团队内部针对这两款框架,分别做了不同尝试,最终从框架扩展的易用性,插件数量,以及部署等方面,选择使用的是 Eggjs 作为团队内部的框架,以替代之前的框架。
为了对接我们的内部系统,我们还开发了不同功能的一些插件。
egg-qversion,作用是关联前后端静态资源版本号
egg-qconfig,对接公司内部的 qconfig 系统
egg-qwatcher,对接公司内容的 watercher 系统
egg-accesslog,产生 access.log 日志
egg-swift,对接 swift 系统
egg-healthcheck,系统健康检查
egg-checkurl,应用存活检查
不能利⽤发布系统中相应的端口和⽬录字段,只能在 qunar_xx 服务中写死, 不友好
不能区分多环境策略如 beta 环境和 prod 环境配置规则不一样
启动过程中出现错误,不方便定位问题,需要到机器上排查
写系统服务需要了解 shell 命令和系统服务格式,对于前端开发同学,成本稍高
除了端口、项目路径、运行环境,node.js 启动方式外,处理逻辑相似
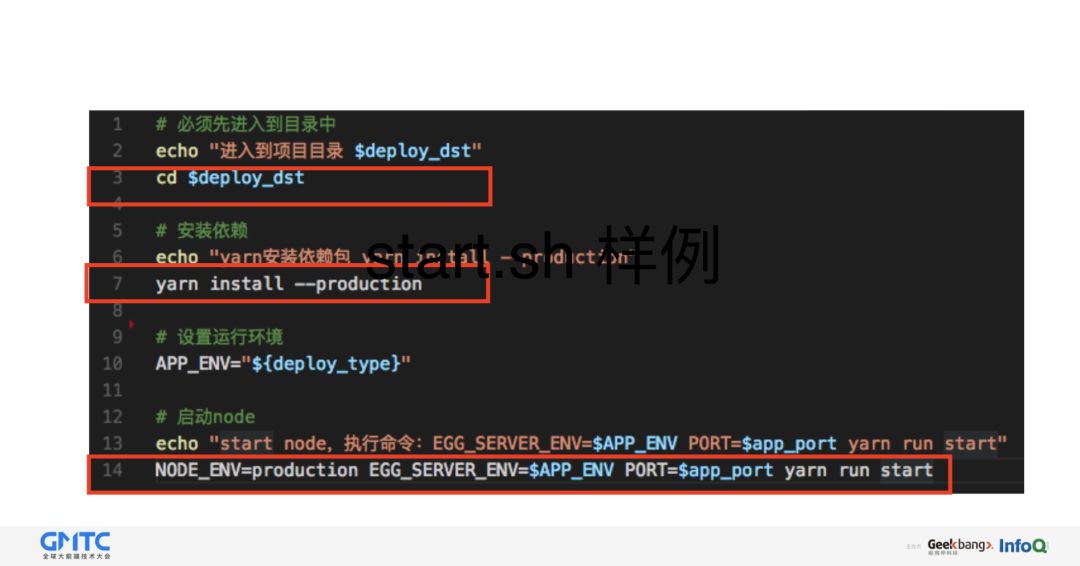
在项目中建立 deploy_scripts 目录,新增 start.sh (名称可以随便命名)
在 start.sh 中填⼊Node.js 启动逻辑,比如 node index.js (之前是 N 行,如今最多两⾏)
在发布系统选择 node 发布方式,填⼊端⼝号,发布路径,以及启动脚本名称(start.sh),停止脚本填入发布系统内置的 stop.sh(按照端口杀掉进程)
这是 start.sh 的一个样例:
这是大致的结构:
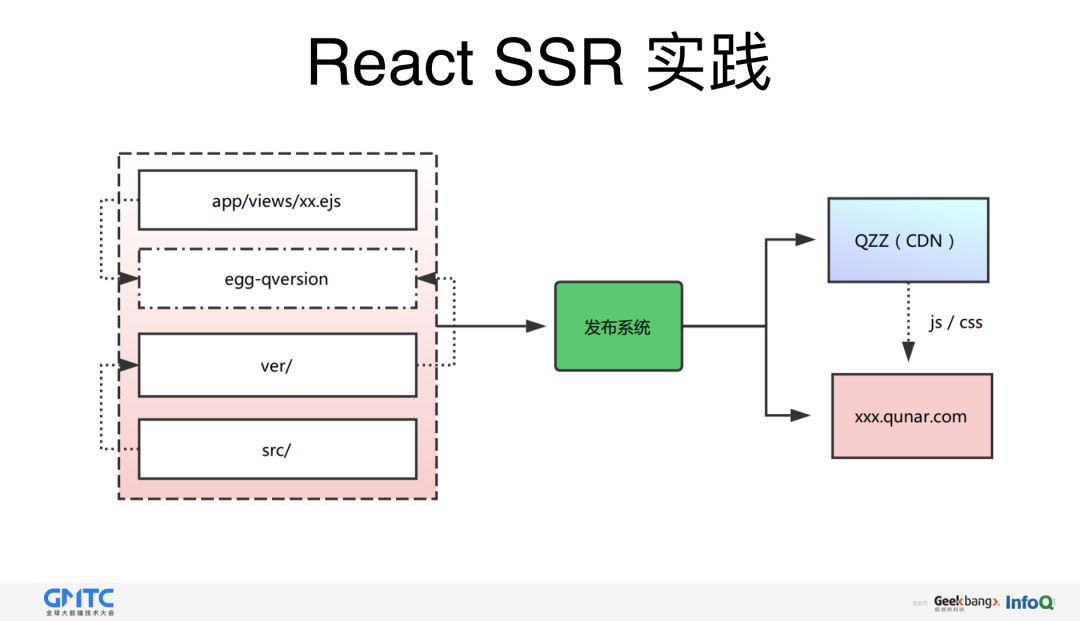
 这里我们没有使用高大上的技术,只是简单使用了 Redux ,原因有两个。一方面,学习成本底,不管对于新同学还是老同学,都能快速上手。第二方面,即使不使用 SSR ,前端代码照常能运行。
这里我们没有使用高大上的技术,只是简单使用了 Redux ,原因有两个。一方面,学习成本底,不管对于新同学还是老同学,都能快速上手。第二方面,即使不使用 SSR ,前端代码照常能运行。
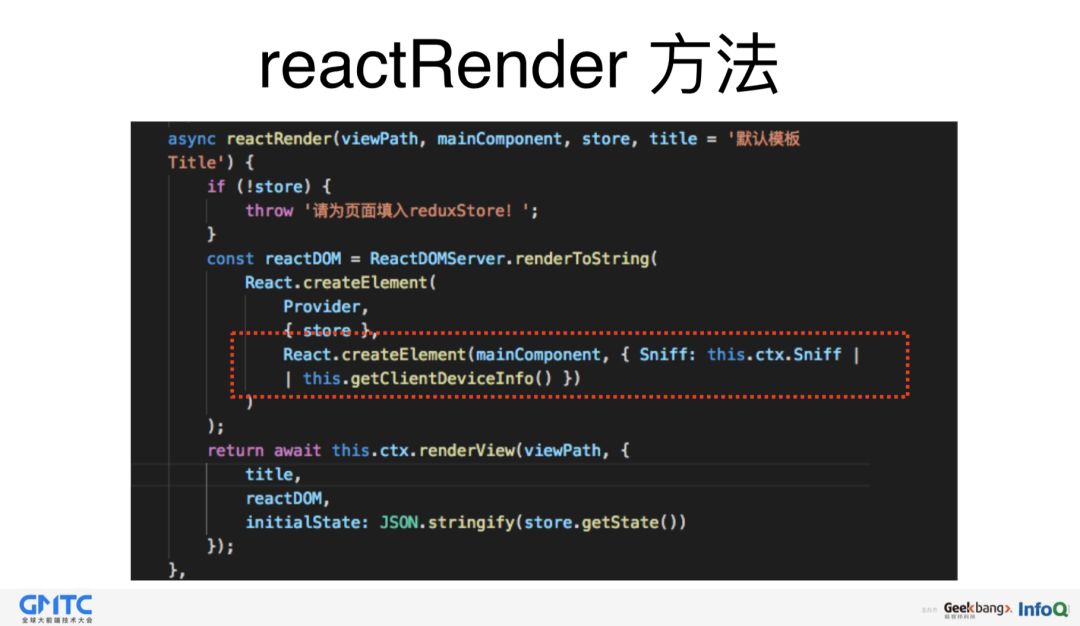
这是 reactRender 的写法。这里额外附加了一个嗅探功能,以便前端能提前获取设备信息。
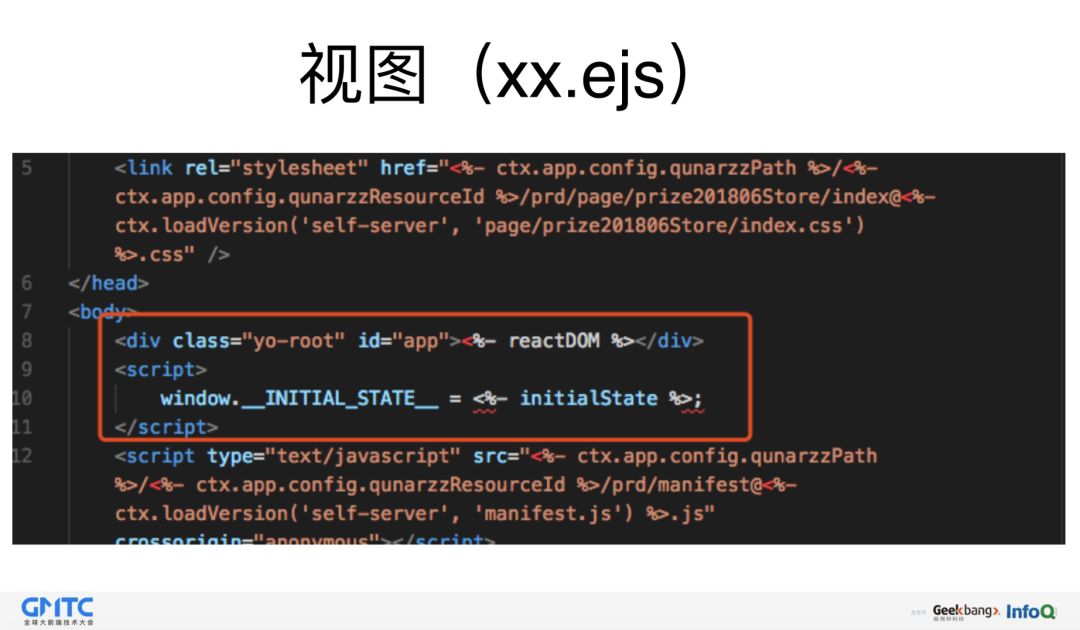 再看视图的写法。
再看视图的写法。
这里把状态数据,挂在到了 window 全局变量上了,当然这也是一个缺点吧。
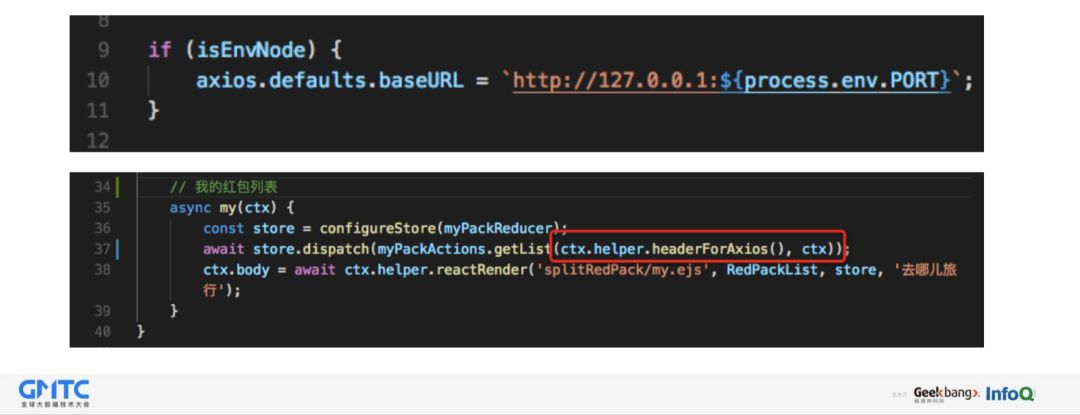
因为前后端共同使用一个 action,后端 dispatch 的时候,需要同步的自身调用自身,所以在请求时,需要配置一个完整的请求 URL 。同样是自身调用自身,本身是没有 cookie 等信息的,所以还需要透传这些信息,方便后端使用。比如判断登陆等
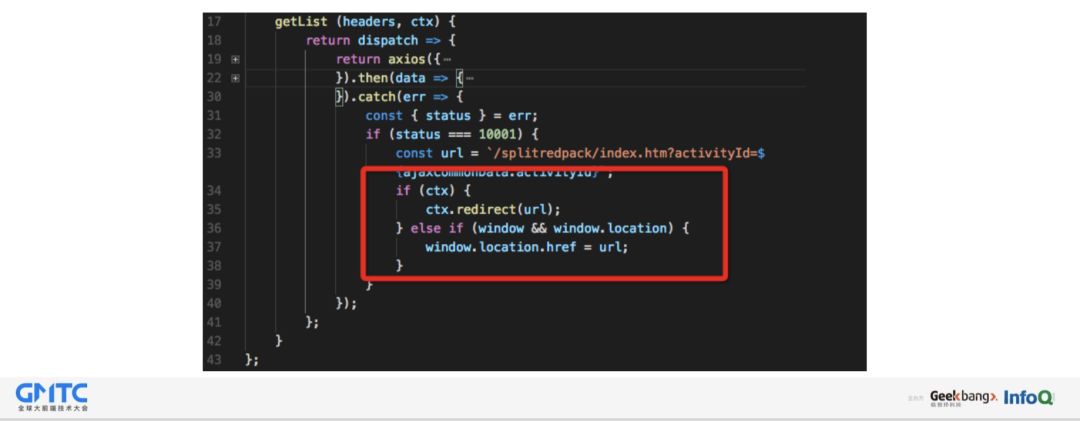
同样,同一个 action 可能被后端调用,也可能被前端调用,如果不处理异常的话,对于定位和处理问题也是非常棘手。我们的做法是,最后一个参数,传递后端的 context ,在处理异常时,区分环境,有针对性的处理。
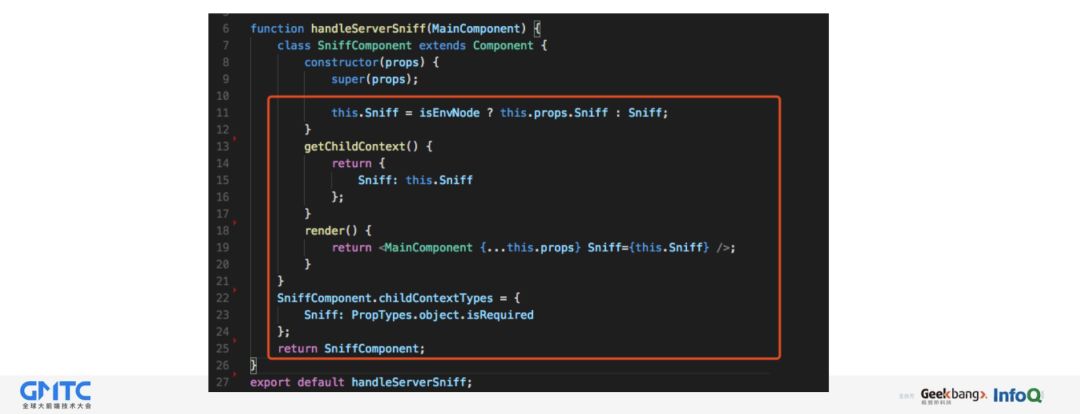
有时,在后端渲染的时候,需要明确知道一些环境信息,比如是否在 APP 内,是否是是 IphoneX 等等,以便在初始渲染的时候,设置额外的信息。所以这里使用的是高阶组件,把这些检测信息统一注入到组件中。这样开发同学就不用在每个页面重复写这些信息了。
对于性能方面,我们做得不是太多,因为 eggjs 本身已经经历过淘宝双十一的洗礼, 相信在阿⾥内部对这块已经做了不少优化,所以简单使用的是公司级别的机器监控。
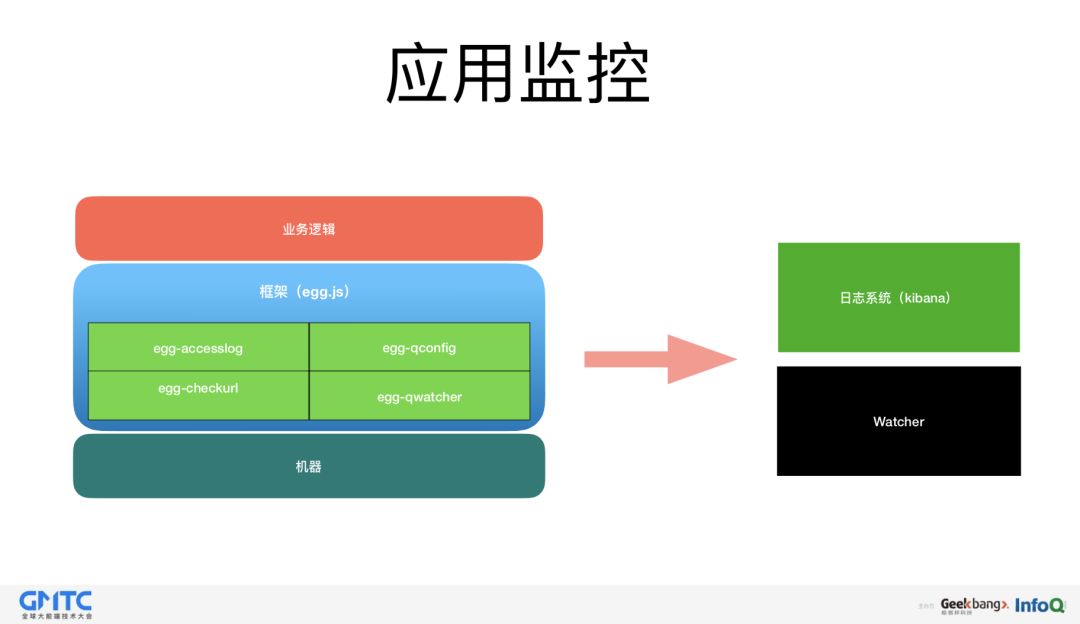
应用监控,分两个方向。
第一个方向,是应用程序级别,比如应用程序错误数,请求后端接口时间消耗和异常信息,accesslog 日志等等。
第二个方面,是前端页面级别,比如脚本全局错误,静态资源文件加载的错误,异步接口错误,页面渲染时长等等
针对这两方面的错误,我们有两套系统,一个是日志系统,一个是 Watcher 系统,这两个系统是搭配合作的。
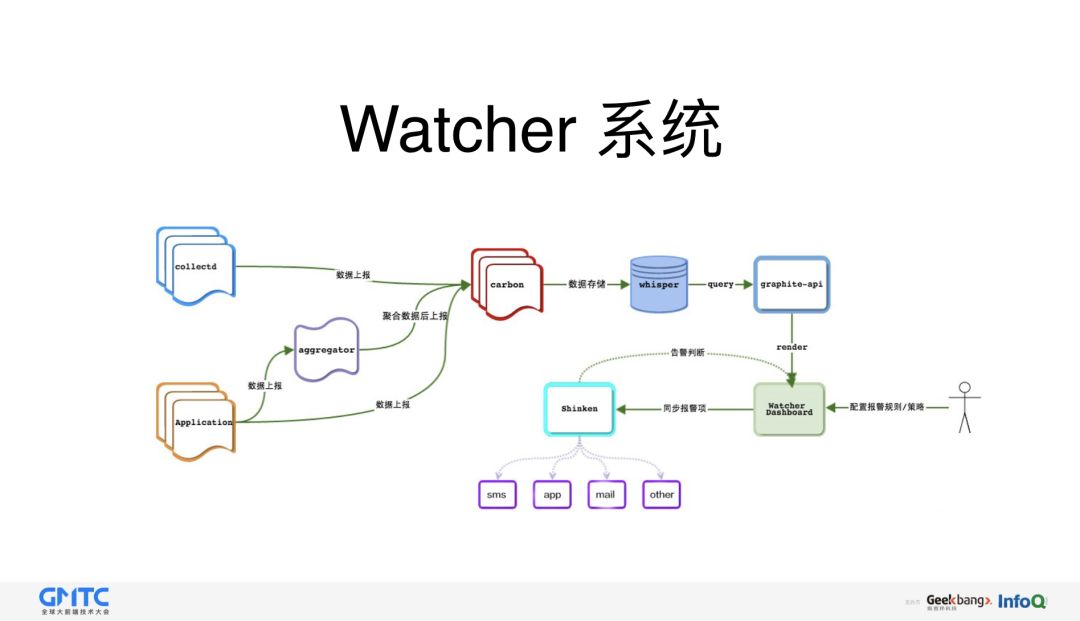
Watcher 系统,它主要的功能是打数,计数,图形化展示,以及设置报警等功能。实时主动的提醒我们系统运行情况,能够在第一时间发现问题,使故障影响范围降到到最小。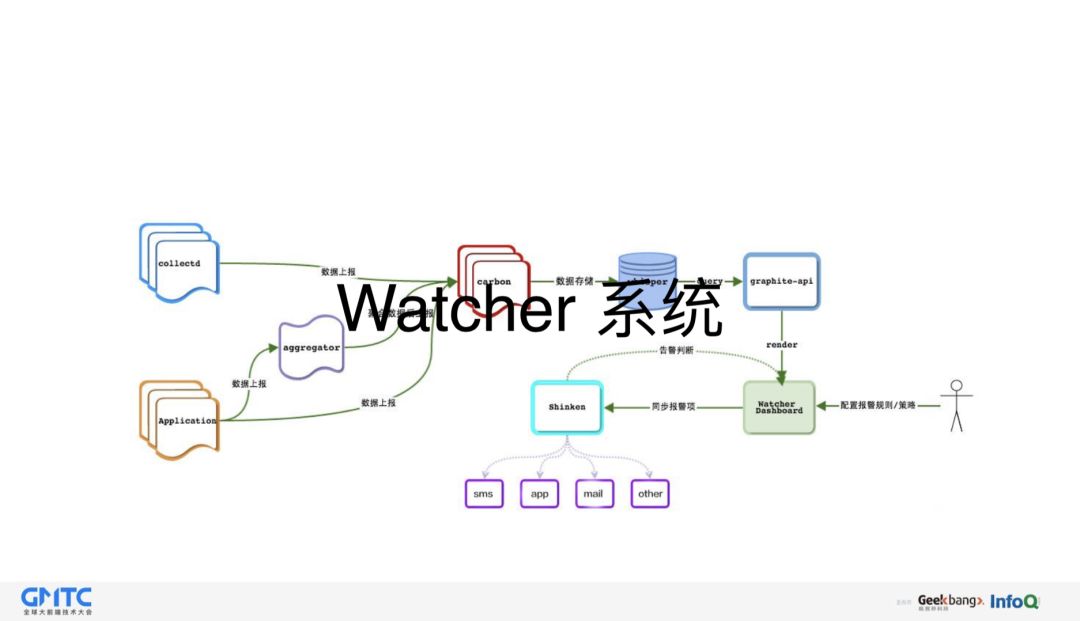
大家可以看出,虽然在特定的时间点报出问题,但只限数量上的程度,具体什么问题,Watcher 系统就不行了,还需要借助第二套「日志系统」。通过 kibana 可以实时查看所有错误信息。
以上是关于去哪儿网前后端分离实践的主要内容,如果未能解决你的问题,请参考以下文章