程序员都应该知道的 Java 虚拟机小常识
Posted 大连中软卓越
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了程序员都应该知道的 Java 虚拟机小常识相关的知识,希望对你有一定的参考价值。
JVM已经是Java开发的必备技能了,JVM相当于Java的操作系统。
背景介绍
JVM已经是Java开发的必备技能了,JVM相当于Java的操作系统。
JVM,java virtual machine, 即Java虚拟机,是运行java class文件的程序。
Java代码经过Java编译器编译,会编译成class文件,一种平台无关的代码格式,class文件按照jvm规范,包括了java代码运行所需的元数据和代码等内容。jvm加载class文件后,就可以执行java代码了。
JVM有不同的实现,有我们熟悉的Hotspot虚拟机,JRockit等。在各个操作系统上,又回有各自的虚拟机实现,从而形成了Java代码 > class文件 > JVM规范 > JVM实现的层次。再加上其他语言如scala、groovy也能够生成class文件,这样不仅实现了平台无关性,也实现了语言无关性。
JVM体系,分为JVM内存结构,Class文件结构,Java ByteCode,垃圾收集算法和实现,调优和监控工具,以及Java内存模型(JMM)。
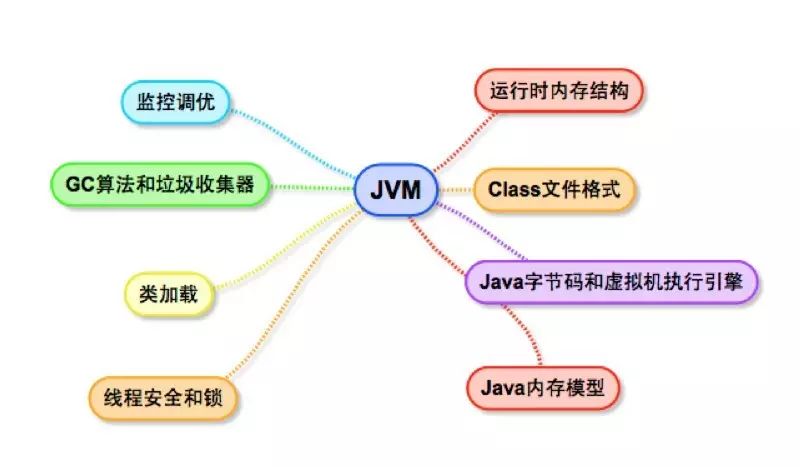
jvm-mindmap
JVM内存结构
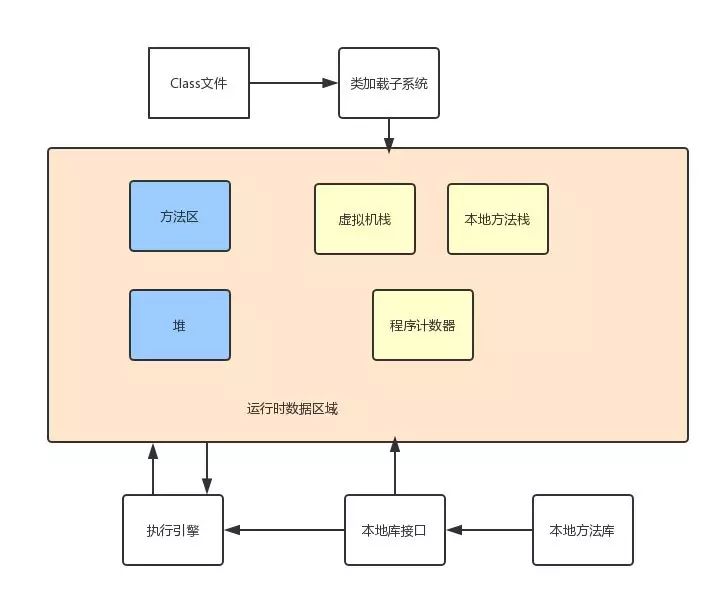
JVM-runtime-area
通常,认为大概分为线程共享的区域和线程私有的区域。共享区域在JVM启动时创建, 私有区域伴随这线程的启动和结束。
私有区域
一个线程拥有的结构有
程序计数器(ProgramCounter, PC)
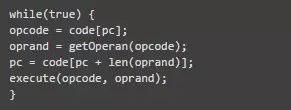
Java天生支持多线程,多线程会有线程切换的问题,当一个线程从可运行状态得到CPU调度进入运行状态,CPU需要知道从哪里开始执行,并且Java是一种基于栈的执行架构(区别于基于寄存器的架构)。
当执行一个Java方法时,PC会指向下一条指令的位置。执行native方法时,PC是未定义。操作指令可能会有0个或多个操作数。JVM的执行流程大概可以描述为:
Java虚拟机栈(Java Virtual Machine Stack)
Java虚拟机栈,或者叫方法栈,会伴随这方法的调用和返回进行相应的入栈和出栈。栈的元素是栈帧(Stack Frame), 栈帧中的内容包括: 操作数栈,本地变量表,动态链接等信息。当线程调用一个方法的时候,会组装对应的栈帧入栈。
本地变量表(LocalVariable Table)
本地变量表存储方法的参数、方法内部创建的局部变量。本地变量表的大小在编译时就确定了。本地变量表会根据变量的作用范围选择重用一个位置。本地变量表会存放 int,char,byte,float,double,long,address(实例引用)。其中除了double和long其他变量占用一个slot,一个slot指一个抽象的位置,在32位虚拟机中是32bit大小, double和long占用两个slot。 值得注意的时,如果一个方法是实例方法,Java编译器会将this作为第一个参数传入本地变量表。另外Java中面向对象,方法调用可以这样理解

操作数栈用于方法内执行保存中间结果,Java方法中的代码逻辑就是通过操作数栈来实现的。和本地方法表一样,操作数栈也是在编译时就确定最大大小了,即最大深度。操作数栈可以和本地变量表交互,进行数据的存放和读取。下面用一个简单的例子展示一下。
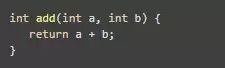
这个实例方法经过Java编译器编译后生成的字节码

线程共享区域
堆(Heap区)
方法区
方法区存放加载的类信息和运行时常量池等。
垃圾收集(GarbageCollect)
在Java应用中不需要也不能通过代码对内存进行手动释放,JVM中的垃圾器帮助我们自动回收没有程序引用的对象。除了进行内存释放,JVM还需对内存进行整理,因为有内存碎片的问题。GC的优点是加快开发效率,不需要关心内存释放,并且避免了很多内存安全问题。缺点是会带来性能损耗。GC必须要做两件事情,找出垃圾对象和回收它们的内存。
何时进行收集
一般来说,当某个区域内存不够的时候就会进行垃圾收集。如当Eden区域分配不下对象时,就会进行年轻代的收集。还有其他的情况,如使用CMS收集器时配置CMSInitiatingOccupancyFraction设置什么时候触发Old区的回收。
如何判断一块内存是垃圾
即判断一个对象不再使用,不再使用可以是没有有效的引用。 一般来说,主要有两种判断方式
引用计数(ReferenceCount)
当有对象引用自身时,就会计数器加1,删除一个引用就减一,当计数为0时即可判断为垃圾。python等语言使用引用计数。引用计数存在循环引用问题,如两个落单的A和B互相引用,但是没有其他对象指向它们这种情况.
可达性分析(ReachabilityAnalysis)
通过一些根节点开始,分析引用链,没有被引用的对象都可以被标记为垃圾对象。根节点是方法栈中的引用、常量等。根节点集合和具体的实现相关,但是会包括: 线程栈帧中的本地变量和操作数栈中的对象引用,静态变量、常量以及已经加载的类的常量池中的队形引用等。所有能够通过引用链引用到的对象都被认为是活对象。 JVM中普遍使用的是可达性分析。
垃圾收集算法
标记清除(Mark Sweep)
对非垃圾对象进行标记都,清除其他的对象。这种方式对对内存空间造成空隙,即内存碎片,最终导致有空余空间,但没有连续的足够大小的空间分配内存。
标记整理(Mark Compact)
标记非垃圾对象后,将这些对象整理好,依次排列内存。这样内存就是整齐的了。但是因为会造成对象移动,所以效率会有降低。
标记清除整理(Mark SweepCompact)
即组合两种方式,在若干次清除后进行一次整理。
复制(Copy)
划分成两个相同大小的区域,收集时,将第一个区域的活对象复制到另一个区域,这样不会有内存碎片问题。但是最多只能存放一半内存,而且所有的活对象都需要拷贝。
Sun HotSpot虚拟机
为了保证实际GC过程中对象的一致性,GC往往需要停顿所有的Java应用线程,也就是常说的StopTheWorld。 目前主流的虚拟机可以知道哪个位置保存着对象引用,在HotSpot中,通过OopMap的数据结构在快速的GC Root枚举。 安全点(Safe Point): 程序并非在所有时刻都能停顿下来开始GC,只有到达安全点才能暂停。安全点知识程序可能长时间执行的可能的指令,例如方法调用、循环跳转、异常跳转等。发生GC时需要让所有线程停下来,有抢先式中断和主动式中断两种方式。为了解决主动式中断线程一直不响应中断请求的问题,又引入了安全区域(Safe Region)的概念,安全区域是在一段代码片段之中引用关系不会发生变化,线程离开安全区域时,要检查系统是否已经完成了根节点枚举,如果没有则一直等待。
垃圾收集器
垃圾收集器就是垃圾收集算法的相应实现。 在大多数的应用中,有基本能统计到以下的现象:
大多数的对象都是短命的对象
大多数的程序会创建一些长时间存活的对象 所以经常会将内存区域划分成两部分,每个部分各自使用合适的收集算法,也就是分代收集。通过记录对象的年龄(经历过的GC次数), 年轻代进行的收集更频繁,对象到达一定年龄后进入老年代。
Serial New
新生代单线程的收集器,是Client模式默认的垃圾收集器
Parallel New
Serial New的多线程版本。ParNew常和CMS拉配使用。这里说明一些Parallel和Concurrent即并行和并发在垃圾收集这里的表示的不同,并行表示有多个线程同时进行垃圾收集,并发是指垃圾收集线程和应用线程可以并发执行。
Parallel Scanvenge
PS收集器是注重吞吐量(ThroughPut)的收集器。
Serial Old。
老年代的单线程收集器
Parallel Old
Serial Old的多线程版本,由于Parallel Scavenge不能和CMS搭配使用,所以会是使用PS时的一种选择。
CMS (Concurrent Mark Sweep)
注重延迟latency的收集器,在交互式应用中,如面向用户的web应用,需要尽可能减少垃圾收集造成的停顿时间。在总的统计上,吞吐量可能没有PS收集器高。 细分上,CMS还分为4个阶段
初始标记,标记GC Root可以直达的对象。STW
并发标记,从第一步标记的对象开始,进行可达性分析遍历,和应用线程并发执行。
重新标记,SWT,修正上一阶段并发执行造成的引用变化。
并发清除,并发的清除垃圾 CMS使用标记清除算法,所以有内存碎片问题,可能设置参数在进行若干次不带整理的收集后进行一次带整理(compact)的收集。另外,因为垃圾收集是和应用线程并发执行的,在收集的同时可能还会有垃圾不断产生,即产生了浮动垃圾。另外还需要预留出一定空间,到达这个值后进行收集,但是还会有收集速度赶不上生产的速度,这时就会出现Concurrent Mode Failure,CMS会退化成Serial Old进行GC。
G1 (Garbage First)
具有大内存收集和目标效率时间等控制能力,目标是代替CMS。G1通过将内存划分成不同的区域(Region),并对不同区域计算分数,分析那个Region最具有收集价值。
一些JVM的GC参数
常用的参数设置有
-Xms=4g -Xmx=4g 设置Java堆的初始大小和最大大小均为4g,即避免了堆大小调整
-Xmn=1g 设置年轻代的总大小为1g
-SurvivorRatio=8, 设置Eden和一个Survivor的比例为8:1
-XX:+PringGCDetails
堆外内存(Non Heap)
Nio中的DirectByteBuffer就是堆外内存的一部分,这部分内存只能通过Full Gc进行清理。一些框架会通过System.gc调用手动触发gc,但是在启动参数中可能设置了禁止调用System.gc()。另外当设置堆过大时可能会造成堆外内存不够导致OOM。
监控工具
监控工具帮助我们在运行时或问题发生后分析现场,分析内存分布状态,哪里导致内存泄漏等(本该被释放的对象仍然被引用)。
命令行工具
HotspotJVM的bin目录下有很多可用的工具。
jps

即java版的ps,可以查看当前用户启动了哪些java进程。
jstat
pid指jps命令查看的java进程号

jstat是一个多种用途的工具,更多需要man jstat或直接输入jstat查看提示。
jmap
jmap可以查看内存状况

jstack
查看Java线程状况

javap (Java Printer)
javap 可以用可读的方法查看class文件内容,在遇到线上class文件问题,如NoSucheMethodError发生时,可以快速进行判断分析。如分析一个A.class文件,查看它的私有方法和字段。

可视化工具
JVisualVM
$JAVA_HOME/bin/jvisualvm
JMC
$JAVA_HOME/bin/jmc
JConsole
$JAVA_HOME/bin/jconsole
Class文件结构
Java编译器将Java代码编译成class文件格式。 其中步骤包括了我们熟悉的词法分析将源文件转换成token流。语法分析将token流转换成抽象语法树(AST)。语义分析分析语义是否正确。源代码优化。目标代码生成和目标代码优化等步骤。最终得到了class文件。之后在虚拟机中,class文件可以通过解释器解释执行和通过即时编译器(JIT-just in time)编译成native代码执行两种方式执行。 class文件是有严格定义的。符合定义的class文件才能够被JVM加载、验证、初始化、执行。 我们通过javap可以查看一个class文件的内容。 Class文件可以分为以下几个部分
Magic Number (0xCAFEBABY)
minor version, major version 如 0x0033 代表 00,51, 是java8版本
constant pool 常量池,常量池中包括了字段、方法、类的名称的符号引用,符号引用会在运行时经过链接转换为直接引用。
access flags 类的private、public等修饰词
this class 表明当前类的名称
super class 父类
interfaces 实现的接口列表
fields class中定义的字段,每个field又是一个结构体
methods 方法,包括MaxLocal, Max Stack,方法名,signature,access flags等。 代码保存在方法的名称为Code的属性中。
attributes
下面以一个简单的类
看一下它的class文件,通过vim打开,在Normal模式下,按: 输入%!xxd,即可转换成16进制表示。然后可以通过%!xxd -r转换回来
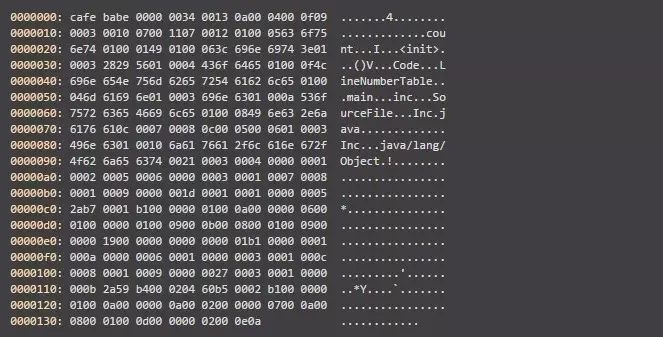
通过javap来看一下它的结构
字节码指令集
bytecode保存在class文件的方法的Code属性中。用一个byte表示操作指令,所以最多有256个指令。一个指令可能会有多个操作数。 操作指令可以分为以下几类:
数学运算,如iadd,i2c,imul,idiv
条件分支, 如ifeq,if_icompeq, if_icmplt
操作数栈和本地变量表的操作,如iload_0,iconst_0, ldc i bipush 100, astore_1, iinc, dup, swap, dup_x1,put_field,get_field, get_static, put_static等。
class操作,如new, checkcast, instanceof
方法调用:1.invokespecial:调用构造器、私有方法和父类方法;2.invokestatic:调用静态方法;3.invokevirtual:调用虚方法,一般的实例方法都是invokevirtual调用;4.invokeinterface:调用接口类的方法;5.invokedynamic,java中对动态语言的支持。 invokevirtual和invokeinterface通过第一个参数查找方法,动态分派,从而实现多态。
JMM (Java内存模型)
现代计算机的一本基本思想是分层模型,例如网络上的分层。在存储上,为解决CPU和内存磁盘的速度有指数级差别的问题加入了很多缓存,利用局部性原理加快速度,从CPU寄存器到L1Cache、L2Cache、内存、磁盘,各个层的速度依次降低、空间增大、单位bit造价降低。最近CPU的处理能力的垂直增加似乎遇到瓶颈,转而向多核方向发展,多个cpu核可能各自缓存自己的内容,又出现了缓存一致性问题。CPU有一些缓存一致性协议,MESI等。CPU还可能会对机器指令进行乱序执行。JVM为了屏蔽底层的这些差异,提出了Java内存模型,即JMM(Java Memory Model),来保证Write One Run Anywhere。开发者面向JMM编程,通过JMM提供的一致性保证和工具,就能保证一致性问题。 JMM模型中,每个线程会有一个私有的内存区域用于缓存读和写,各个线程共享一个主内存。一个重要的概念是happen-before原则。 happen-before用来描述两个操作的偏序关系,如果Ahappen-beforeB,那个A的操作的结果、产生的影响能够被B看到。 如果我们有两个动作x和y,我们记hb(x,y)为x happen before y JMM提供的基础的happen-before规则有
同一个线程内,x在y前面,则hb(x,y)
如果hb(x,y) 并且 hb(y, z) ,则 hb(z,z)
一个监视器锁的unlockhappen before 之后每一个对该监视器的lock
一个volatile字段 写操作 happen before 之后的每一个读
一个线程的start操作happen-before 线程内的任何操作
线程内的任何操作都happen-before任何从该线程的join()方法返回的
happen-before并不要求在之前发生,只需能够看到操作的结果即可,对应的实现可以进行重排序或消除锁,只要保证外观正确。
最后总结
以上的总结梳理权当抛砖引入,帮助大家梳理知识结构,更多细节还需通过查看源码、亲自探索,真像就在那代码中。而且每个知识点又能够引出一篇笔记分析,之后后补充更多细节文章。
参考
JLS
JVMS
深入理解Java虚拟机
Inside The Java Virtual Machine
了解详情请关注官网:www.dletc.com.cn
推荐朋友来学习还可以抽大奖哦!
如果你想通过努力改变职场命运,如果你想了解更多职场咨讯、招聘信息、就业指南、前沿技术,请关注中软卓越的微信一睹为快!定期还有课程优惠及精彩活动,大大小小的惊喜在等着你呦!
以上是关于程序员都应该知道的 Java 虚拟机小常识的主要内容,如果未能解决你的问题,请参考以下文章