debug了很久,发现了Hystrix的两个bug
Posted 占小狼的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了debug了很久,发现了Hystrix的两个bug相关的知识,希望对你有一定的参考价值。
技术干货文章第一时间送达!
最近基于Hystrix源码添加一些花边功能,比如数据埋点、参数动态配置等,交付给业务之后,经过一系列的压测之后,发现了各种问题,比较严重的是下面两个。
1、埋点数据有问题 2、熔断一直不恢复
先来看下埋点数据的问题,经过封装的Hystrix会把正常请求、试探请求、异常请求和熔断状态都记录下来,通过压测后发现发生熔断的时候,出现了好几个数据打点,正常情况下应该只有一个。通过debug,加日志之后,才发现这个隐秘的问题。
每次请求都会获取一个对应的熔断器,假设服务刚启动的时候,对应的熔断器还没有初始化,这时每个线程都会去尝试初始化一个,通过 ConcurrentHashMap的 putIfAbsent方法保证最后拿到的是同一个熔断器,但是作者忽略了一个问题,在熔断器的初始化中,有这么一段逻辑:
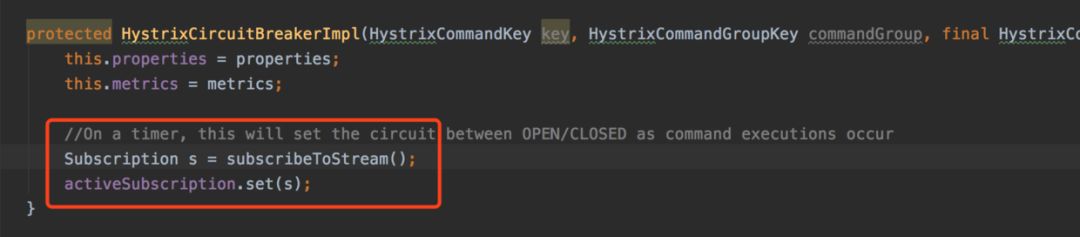
上述逻辑中,熔断器在初始化时,会去注册Metrics的数据流的回调(本质是500ms执行一次,判断是不是达到熔断阈值了)。所以,如果有10个线程同时初始化熔断,虽然最终只会使用一个,但是其它9个熔断器也会注册回调。这就导致了当发生熔断时,熔断标识的埋点数据就有问题。
最好的办法就是初始化熔断器的时候,加个锁。
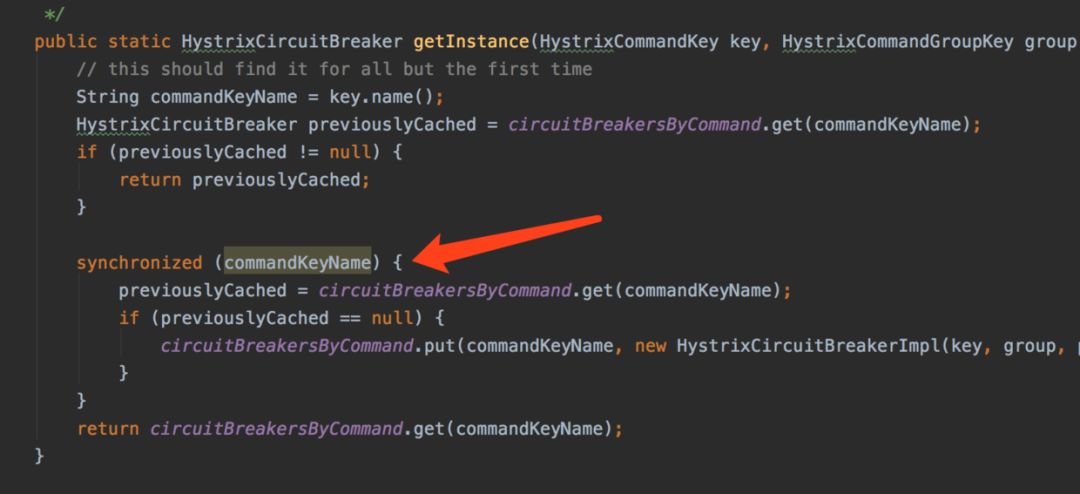
能避免的无效计算,都尽量的避免。
再来看看第二个问题,我觉得这算是一个大bug了,熔断一直不恢复,这意味着什么,意味着钱啊。
先看看什么情况下,熔断之后不会恢复吧。 熔断器内部有三个状态: CLOSED, HALF_OPEN, OPEN。默认情况下,都是处于 CLOSED状态,当请求的失败率过高,达到阈值时,就自动从 CLOSED切成 OPEN,这是所有的请求会执行降级逻辑,这些都没问题。熔断开启之后,如果过了一个试探窗口(5000ms),其中一个请求线程会把熔断状态从 OPEN切成 HALF_OPEN,表明要开始试探下游服务是不是已经恢复了。如果下游已经恢复,那么这个请求正常返回之后,会执行 markSuccess方法,该方法实现如下:
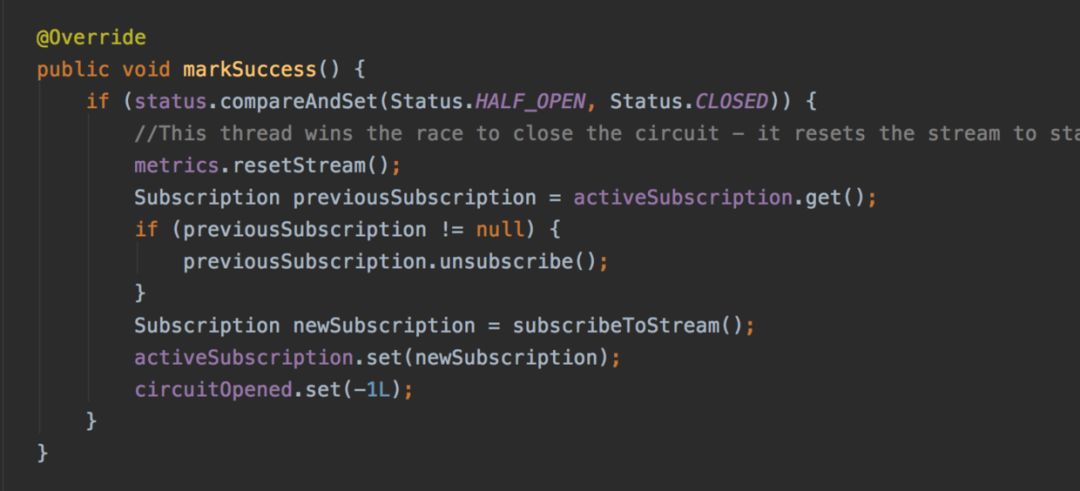
在这个方法中,会把熔断转态从 HALF_OPEN切成 CLOSED,熔断恢复,分析下来,好像这一切是那么的理所当然,顺理成章。
但是,但是!!! 在熔断开启期间,执行降级的请求最后会执行一个叫 unsubscribeCommandCleanup的Action,代码如下:
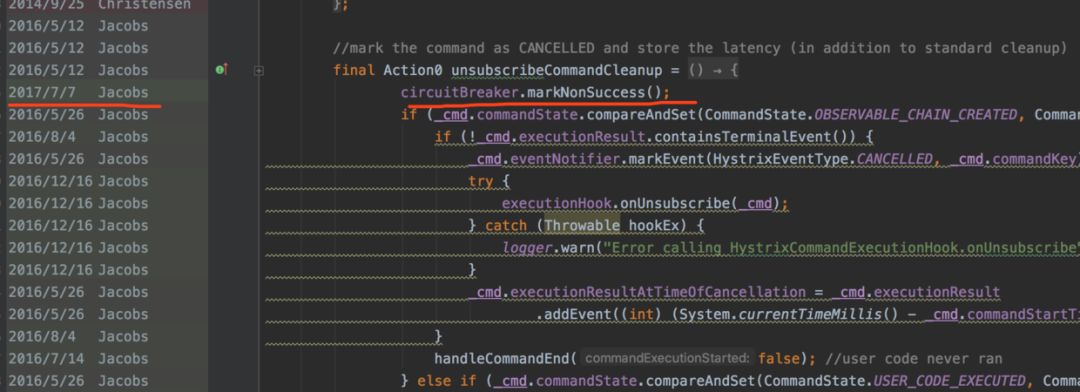
在该Action中,执行 circuitBreaker.markNonSuccess(),这个会导致什么问题?设想一下,如果试探请求刚把熔断从 OPEN切成 HALF_OPEN,正在等待下游返回时,这时一个降级请求,理所当然执行了 markNonSuccess,顺带把熔断又从 HALF_OPEN切成 OPEN,一切都是默默的发生,不留下一丝痕迹,不加个日志,你都不知道发生了什么。
熔断状态被降级请求切回了 OPEN,这时试探请求结果成功返回,执行 markSuccess方法,准备把熔断从从 HALF_OPEN切成 CLOSED,殊不知已经被内部间谍提早偷偷换了转态,就导致了应该恢复的服务,继续降级着,只能祈祷下次没有降级请求提早偷换状态。
去github上翻了一下,在1.5.12版本中,Action unsubscribeCommandCleanup并不会执行 circuitBreaker.markNonSuccess(),而是在1.5.13中,为了修复一个bug而加入的。
加这段代码的本意是:Fixed bug where an unsubscription of a command in half-open state leaves circuit permanently open,就是下面这种写法。
Observable<Boolean> o = cmd5.observe();
Subscription s = o.subscribe();
s.unsubscribe();
结果,种下了另一个隐患,而这个问题17年7月就被种下了,迟迟未得到修复,Hystrix难道没人维护了?
不过,如果不加埋点,这种bug几乎看不出来的,因为在线上运气好点,无非就是晚点恢复,运气再不好,就再晚点恢复,再不恢复,就重启。
最后: 如果想用原生的Hystrix,建议使用1.5.12版本;如果想用最新的版本,建议对源码进行适当的修改,再进行使用。
更多精彩问题,欢迎加入知识星球
500小伙伴正在讨论
以上是关于debug了很久,发现了Hystrix的两个bug的主要内容,如果未能解决你的问题,请参考以下文章