服务容错与保护方案 — Hystrix
Posted 互联网后端架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了服务容错与保护方案 — Hystrix相关的知识,希望对你有一定的参考价值。
1、Hystrix能做什么
在通过第三方客户端访问(通常是通过网络)依赖服务出现高延迟或者失败时,为系统提供保护和控制
在分布式系统中防止级联失败
快速失败(Fail fast)同时能快速恢复
提供失败回退(Fallback)和优雅的服务降级机制
提供近实时的监控、报警和运维控制手段
2、Hystrix设计原则
防止单个依赖耗尽容器(例如 Tomcat)内所有用户线程
降低系统负载,对无法及时处理的请求快速失败(fail fast)而不是排队
提供失败回退,以在必要时让失效对用户透明化
使用隔离机制(例如『舱壁』/『泳道』模式,熔断器模式等)降低依赖服务对整个系统的影响
针对系统服务的度量、监控和报警,提供优化以满足近实时性的要求
在 Hystrix 绝大部分需要动态调整配置并快速部署到所有应用方面,提供优化以满足快速恢复的要求
能保护应用不受依赖服务的整个执行过程中失败的影响,而不仅仅是网络请求
3、Hystrix如何实现这些目标
Hystrix 通过如下几个方式实现了设计目标:
3.1、命令模式
将所有请求外部系统(或者叫依赖服务)的逻辑封装到 HystrixCommand 或者 HystrixObservableCommand 对象中
Run()方法为实现业务逻辑,这些逻辑将会在独立的线程中被执行当请求依赖服务时出现拒绝服务、超时或者短路(多个依赖服务顺序请求,前面的依赖服务请求失败,则后面的请求不会发出)时,执行该依赖服务的失败回退逻辑(Fallback)
3.2、隔离策略
Hystrix 为每个依赖项维护一个小线程池(或信号量);如果它们达到设定值(触发隔离),则发往该依赖项的请求将立即被拒绝,执行失败回退逻辑(Fallback),而不是排队。
隔离策略分线程隔离和信号隔离。
线程隔离
第三方客户端(执行Hystrix的run()方法)会在单独的线程执行,会与调用的该任务的线程进行隔离,以此来防止调用者调用依赖所消耗的时间过长而阻塞调用者的线程。
使用线程隔离的好处:
应用程序可以不受失控的第三方客户端的威胁,如果第三方客户端出现问题,可以通过降级来隔离依赖。
当失败的客户端服务恢复时,线程池将会被清除,应用程序也会恢复,而不至于使整个Tomcat容器出现故障。
如果一个客户端库的配置错误,线程池可以很快的感知这一错误(通过增加错误比例,延迟,超时,拒绝等),并可以在不影响应用程序的功能情况下来处理这些问题(可以通过动态配置来进行实时的改变)。
如果一个客户端服务的性能变差,可以通过改变线程池的指标(错误、延迟、超时、拒绝)来进行属性的调整,并且这些调整可以不影响其他的客户端请求。
简而言之,由线程供的隔离功能可以使客户端和应用程序优雅的处理各种变化,而不会造成中断。
线程池的缺点
线程最主要的缺点就是增加了CPU的计算开销,每个command都会在单独的线程上执行,这样的执行方式会涉及到命令的排队、调度和上下文切换。
Netflix在设计这个系统时,决定接受这个开销的代价,来换取它所提供的好处,并且认为这个开销是足够小的,不会有重大的成本或者是性能影响。
信号隔离
信号隔离是通过限制依赖服务的并发请求数,来控制隔离开关。信号隔离方式下,业务请求线程和执行依赖服务的线程是同一个线程(例如Tomcat容器线程)。
线程池隔离与信号量隔离对比
| 对比项 | 线程池隔离 | 信号量隔离 |
|---|---|---|
| 线程池 | 与调用线程非相同线程 | 与调用线程相同(jetty线程) |
| 开销 | 排队、调度、上下文开销等 | 无线程切换,开销低 |
| 异步 | 支持 | 不支持 |
| 并发 | 支持(最大线程池大小) | 支持(最大信号量上限) |
| 应用场景 | 第三方应用或者接口、并发量大 | 内部应用或者中间件、并发需求不大 |
注意:
如果不涉及远程RPC调用(没有网络开销)则使用信号量来隔离,更为轻量,开销更小。
如果是缓存调用,响应快,不会占用容器线程太长时间,也可以使用信号量来隔离
3.3、观察者模式
Hystrix通过观察者模式对服务进行状态监听
每个任务都包含有一个对应的Metrics,所有Metrics都由一个ConcurrentHashMap来进行维护,Key是CommandKey.name()
在任务的不同阶段会往Metrics中写入不同的信息,Metrics会对统计到的历史信息进行统计汇总,供熔断器以及Dashboard监控时使用
Metrics
Metrics内部又包含了许多内部用来管理各种状态的类,所有的状态都是由这些类管理的
各种状态的内部也是用ConcurrentHashMap来进行维护的
Metrics在统计各种状态时,时运用滑动窗口思想进行统计的,在一个滑动窗口时间中又划分了若干个Bucket(滑动窗口时间与Bucket成整数倍关系),滑动窗口的移动是以Bucket为单位进行滑动的。
HealthCounts 记录的是一个Buckets的监控状态,Buckets为一个滑动窗口的一小部分,如果一个滑动窗口时间为 t ,Bucket数量为 n,那么每t/n秒将新建一个HealthCounts对象。
4、熔断机制
熔断机制是一种保护性机制,当系统中某个服务失败率过高时,将开启熔断器,对该服务的后续调用,直接拒绝,进行Fallback操作。
熔断所依靠的数据即是Metrics中的HealthCount所统计的错误率。
熔断器的判断流程图:
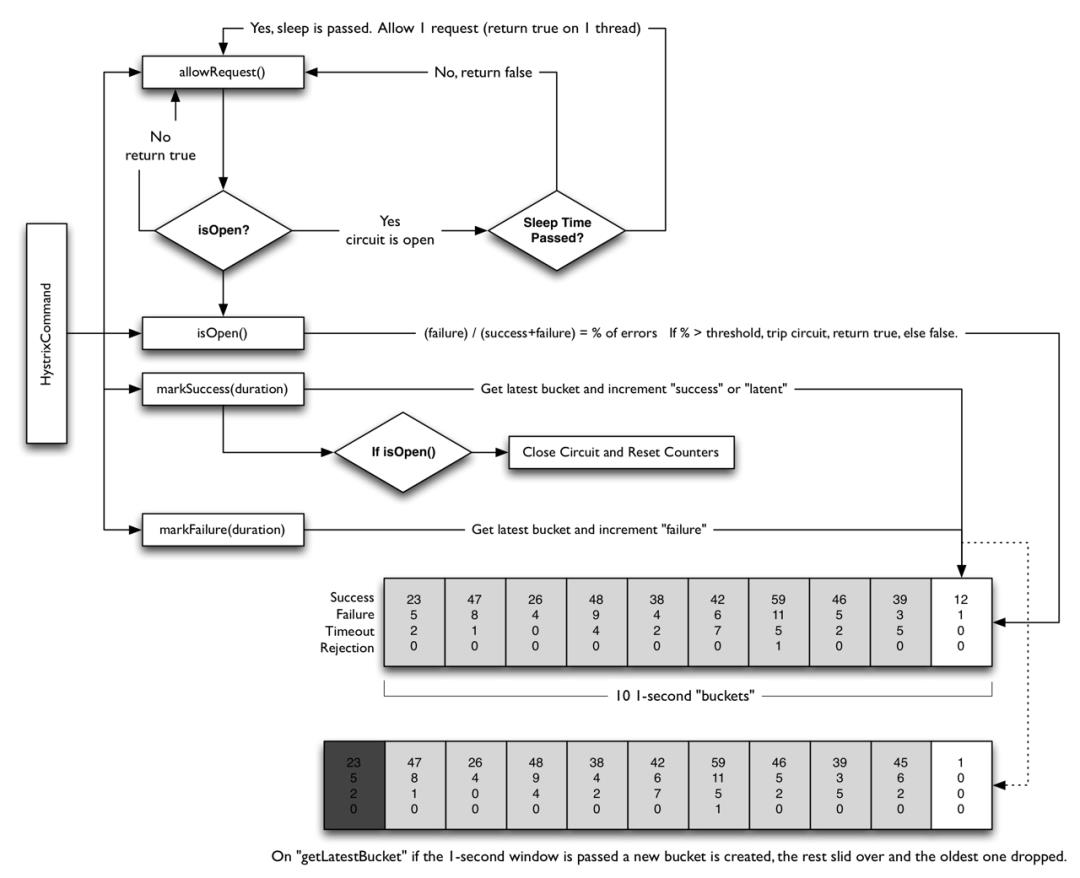
1、执行allowRequest()方法,具体步骤如下:
a、 先查看熔断器是否强制开启(ForceOpen()),如果开启,再看休眠期是否已过,如果还在休眠期,则拒绝请求,如果已过休眠期,执行第3步
b、再查看熔断器是否强制关闭(ForceClosed()),如果关闭,则允许请求
2、执行isOpen(),判断是否应该开启熔断器,如果开启,则拒绝所有请求
3、熔断器休眠期过后,允许且只允许一个请求,如果这个请求正确执行,则关闭熔断器,并重置计算
4、如果执行失败,则再次开启熔断器,进入新的熔断周期
如何判断是否应该开启熔断器?
必须同时满足两个条件:
1、请求数达到设定的阀值
2、请求的失败数 / 总请求数 > 错误占比阀值%
5、降级策略
当construct()或run()执行失败时,Hystrix调用fallback执行回退逻辑,回退逻辑包含了通用的响应信息,这些响应从内存缓存中或者其他固定逻辑中得到,而不应有任何的网络依赖。
如果一定要在失败回退逻辑中包含网络请求,必须将这些网络请求包装在另一个 HystrixCommand 或 HystrixObservableCommand 中,即多次降级。
失败降级也有频率限时,如果同一fallback短时间请求过大,则会抛出拒绝异常。
6、缓存机制
同一对象的不同HystrixCommand实例,只执行一次底层的run()方法,并将第一个响应结果缓存起来,其后的请求都会从缓存返回相同的数据。
由于请求缓存位于construct()或run()方法调用之前,所以,它减少了线程的执行,消除了线程、上下文等开销。
7、工作流程
主要的原理已经了解,现在回头再看Hystrix整体的工作流程。
1、构建HystrixCommand或HystrixObservableCommand对象的实例
2、执行Command(四种方式:execute()、queue()、observe()、toObservable())
3、判断响应是否有缓存,如果有,则返回缓存结果,如果没有,继续下一步
4、判断熔断器是否打开,如果打开,执行第8步;如果没有,继续下一步
5、判断线程池/信号量是否拒绝请求,如果是,执行第8步,同时,执行第7步;如果不是,继续下一步
6、调用
HystrixObservableCommand.construct()或HystrixCommand.run(),如果执行失败或超时,接着执行第8步,如果执行成功,则进行第9步7、计算熔断器健康,根据计算结果决定是否打开熔断器
8、执行回退逻辑,如果执行失败(抛出异常或方法没有被实现),整个流程失败
9、返回Observable对象
以上是关于服务容错与保护方案 — Hystrix的主要内容,如果未能解决你的问题,请参考以下文章
第五章 服务容错保护:Spring Cloud Hystrix
Spring Cloud构建微服务架构 服务容错保护(Hystrix断路器)Dalston版