什么叫拇指规则
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么叫拇指规则相关的知识,希望对你有一定的参考价值。
什么叫做大拇指规则?我在经济学、管理学等等学科中都遇到过这个词,到底是什么意思呢?请求指点。谢了!
大拇指规则 (RULE OF THUMB) 可以理解诚是一种试探法 (heuristics)试探法 (heuristics):The high-level, often imprecise rules of thumb and intuitive reasoning that experts use to solve problems.
专家用于求解问题的高级的但常常是不确切的经验法则和直觉推理法。
大拇指规则字面的理解应该是从经验、实践中总结得出的方法和规则什么的,不是经过科学实验得出的, 因为以前没有温度计,别人烧水什么的时候不知道到底有多热,所以呢就用大拇指浸一下,然后就可以知道,水已经很热了。还有一种说法,比较正常一点人性化一点,因为古代的时候大家都是用便于计量的单位来计量,比方说脚、手指,忘记掉以前哪个英国国王说,从我鼻子到我伸出的手指头就是一yard.
大拇指法则=经验法则一种可用于许多情况的有用的原则,但并不是放诸四海皆准
在英国普通法中, 有一条“大拇指规则”(rule of thumb), 意即只要用一根比大拇指小的棍子鞭打妻子,便不属虐待妻子行为。后经引申在管理学等其他知识领域上理解为经验和试探法.
----------------------------------------------
附上大拇指规则的英文解释:
"rule of thumb"
by Mark Israel
[This is a fast-access FAQ excerpt.]
This term for "a simple principle having wide application but not
intended to be strictly accurate" dates from 1692. A frequently
repeated story is that "rule of thumb" comes from an old law
regulating wife-beating: "if a stick were used, it should not be
thicker than a man's thumb." Jesse Sheidlower writes at
[...]
[The URL that was given above is no longer valid. Jesse's
article on "rule of thumb" is now at
<http://www.randomhouse.com/wotd/index.pperl?date=19961108>.]
"It seems that in 1782 a well-respected English judge named Francis
Buller made a public statement that a man had the right to beat his
wife as long as the stick was no thicker than his thumb. There was
a public outcry, with satirical cartoons in newspapers, and the
story still appeared in biographies of Buller written almost a
century later. Several legal rulings and books in the late
eighteenth and nineteenth centuries mention the practice as
something some people believe is true. There are also earlier
precedents for the supposed right of a man to beat his wife.
"This 'rule' is probably not related to the phrase 'rule of
thumb', however. For one thing, the phrase is [...] attested
[earlier ...]. (Of course, it's possible that it was a well-known,
but unrecorded, practice before Buller.) Another problem is that
the phrase 'rule of thumb' is never found in connection with the
beating practice until the 1970s. Finally, there is no semantic
link [... from what was presumably a very specific distinction to
the current sense 'rough guideline']. The precise origin of 'rule
of thumb' is not certain, but it seems likely to refer to the thumb
as a rough measuring device ('rule' meaning 'ruler' rather than
'regulation'), which is a common practice. The linkage of the
phrase to the wife-beating rule appears to be based on a
misinterpretation of a 1976 National Organization of Women report,
which mentioned the phrase and the practice but did not imply a
connection. There is more information about this, with citations
from relevant sources, at the Urban Legends Archive."
Thumbs were used to measure *lots* of things (the first joint
was roughly one inch long before we started growing bigger, and
French pouce means both "inch" and "thumb"). The phrase may also
come from ancient brewmasters' dipping their thumb in the brew to
test the temperature of a batch; or from a guideline for tailors:
"Twice around the thumb is once around the wrist..."
For a definitive rule of thumb, see the paper "Thumb's rule
tested: Visual angle of thumb's width is about 2 deg." 参考技术A “拇指规则”是指经济决策者对信息的处理方式不是按照理性预期的方式,把所有获得的信息都引入到决策模型中,他们往往遵循的是:只考虑重要信息,而忽略掉其他信息。否则信息成本无限高。
(转)什么是爬虫
我们先看看维基百科的定义
通俗的说爬虫就是通过一定的规则策略,自动抓取、下载互联网上网页,在按照某些规则算法对这些网页进行数据抽取、 索引。 像百度、谷歌、今日头条、包括各类新闻站都是通过爬虫来抓取数据。

题外话
博客园里偶尔看到爬虫的文章,其实很多都称不上为爬虫。 只能叫玩具或者叫http请求下载程序吧。。 严格来说爬虫是一个系统,它包含了爬取策略、更新策略、队列、排重、存储模块等部分。
爬虫的分类
按照抓取网站对象来分类,可以分为2类爬虫。
1. 通用爬虫
类似百度、谷歌这样的爬虫,抓取对象是整个互联网,对于网页没有固定的抽取规则。 对于所有网页都是一套通用的处理方法。
2. 垂直爬虫
这类爬虫主要针对一些特定对象、网站,有一台指定的爬取路径、数据抽取规则。比如今日头条,它的目标网站就是所有的新闻类网站。 比如Etao比价、网易的慧慧购物助手,他们的目标网站就是 淘宝、京东、天猫等等电商网站。
通用爬虫和垂直爬虫显著的区别:
- 抓取范围,通用爬虫的抓取范围要比垂直爬虫大得多,一个是整个互联网,一个是指定的网站。
- 爬取路线,一个通用爬虫要不按照深度爬取、要不是按广度爬取。 而垂直爬虫则可能是按照指定路线爬取。
- 数据处理,通用爬虫一般就是分词、索引到数据库。 而垂直爬虫则通过特定的规则来抽取更加精细的数据 。
一般爬虫的构成
那么一个完整的爬虫程序由哪些东西组成呢?
1. HTTP下载器
顾名思义就是负责HTTP下载,别小瞧它,要做好还挺不容易,因为你面对的复杂而无序、甚至包含错误的互联网。
2. 抓取队列
就是存储新产生的URL队列(queue),队列可以是多种形式的,他可以是redis的队列、数据库中的表、内存中的队列。根据场景,你可以自行选择。
3. 调度器
调度嘛,就是负责管理工作的,它通过制定策略,规定哪些URL优先执行、哪些URL靠后。
4. 多线程模块
对我来说,一个爬虫必须要支持多线程,并且可控。
5. 排重集合
排重,这是一个爬虫必不可少的部分,你必须记录下哪些URL已经采集过、哪些是未采集过的,复杂点的爬虫,你可能还需要记录上次抓取时间。
6. 页面解析器
就是定义如何解析抓取到的页面,对于通用爬虫,它可能对于所有页面都是一套逻辑,就是分词、索引。 但对于垂直爬虫,则需要指定规则。手段可能有正则、XPath、正文识别等等。
7.存储数据
定义以什么方式存储抓取到的数据, 一般情况下都是存储到数据库啦。当然,是一般的关系数据库,还是NoSQL 就看需求了。
一般爬虫的流程
通用爬虫、垂直爬虫他们的流程都是相似的,下面我们简单说说一个爬虫到底是怎么运行的。
首先,我们用一张一般爬虫的流程结构图来看看。
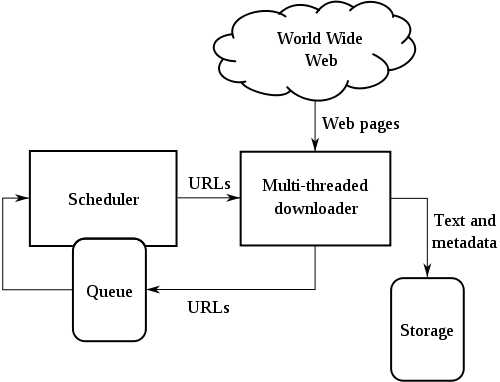
英文我就不翻译了。 大概说说流程吧。
- 指定起始URLs。 也就是指定一个入口。不管是通用爬虫还是垂直爬虫,都需要一个入口。
- 下载、解析URL。 这里分为2个操作,1. 抽取数据,存储到数据库;2. 解析出页面中包含的URL。
- 将解析的新URL放到队列中。
- 调度器从URL队列中,按照一定策略,取出要下载的URL,添加到HTTP下载中。
- 重复执行第二步,直到URL队列为空。
开源爬虫的框架、程序
这里列举一些比较有名的爬虫项目,有些我用过,有些没用过。我平时工作环境是 .net ,对python爬虫也略有研究。
- Scrapy , 非常有名的Python爬虫项目,用户数非常多,文档做的也很棒。
- Nutch ,Java的,它其实是一个搜索引擎项目,包含了搜索和Web爬虫两个部分。 没用过。
- NCrawler, .net 写的。 架构和代码都很棒,建议想学习 .net 爬虫的同学,多研究。可惜没用文档
Scrapy 额外点评, 在我大概读了下它的源码后,我觉得 Scrapy 在一些地方还是很不错的,比如回调模型。 但是它太臃肿了。对于一个垂直爬虫框架来说的,有很多不必要的设计,比如下载器、中间件。
暂且就列这几个, 欢迎各位同学补充!
除了学习爬虫框架,还需要学习哪些技术?
1. HTTP协议
主要的包括GET、POST方法。 各种类型Header的了解 ,包括Referer、User-Agent、Cookie、Accept、Encoding、Content-Type等等。
了解各种HTTP状态码的含义,常见的状态码比如 200表示正常; 301表示重定向,同时会返回新的URL;404表示页面不存在;5xx表示服务器端错误
了解Cookie的构成,原理。
2. HTML
HTML基础知识,了解HTML常用元素, 比如A、IMG等等。
了解URL的构成,路径、参数,绝对路径、相对路径。
编码相关,HTML charset, HTML EncodeDecode,URL EncodeDecode,JS EncodeDecode,
3. 浏览器相关
HTTP协议、HTML其实都是浏览器相关的
了解浏览器,从你输入一个URL,到看到完整的网页,中间发生了什么。相关知识点: URL、DNS、HTTP、Web Server、HTML、JS、CSS、DOM树、JS引擎等等。
其中DOM树、JavaScript相关知识对于爬虫来说还是相当重要的。有些时候需要反解JS。
4. 抓包技术
常用抓包工具,比如Fiddler、浏览器的F12、Wireshark、Microsoft Network Monitor。后面2个属于TCP级别,用的较少。
通过学习抓包工具使用,可以帮你更好的学习HTTP协议、浏览器相关知识。
这里强烈、重点推荐 Fiddler。
大概说下几个常用功能吧, 抓包、保存包数据、Composer(构造HTTP请求)、AutoResponser(自动响应HTTP)、FidderScript 通过编写脚本定制程序、修改HTTP包。
如果你是 .net 技术相关的,建议反编译下,读下源代码,HTTP协议你就搞定啦。它还提供了 FiddlerCore 库让你可以编写自己抓包程序。
反爬虫技术
有爬虫,当然就有反爬虫技术啦。 他们俩一直处于一个对抗、共存的状态。 这是一个非常有意思的过程,对于一些爬虫从业、爱好者来说。
通常来说,只要你想爬,没有爬取不到的数据,就看你的资源和技术了。 不论是网站还是APP。
下面列举下常见几种反爬虫技术:
- useragent、referer 等常见反爬虫技术(低级)
- 需要登录 cookie,
- 封 IP ,限制 IP 访问频率
- 验证码,包括图像验证码、拖动验证码等等
- 浏览器端 Javascript 混淆 ajax 参数
- 其他如 token、随机数
没关系,虽然反爬技术多,但是只是增加你的成本而已。 不过网站也是有代价的,有些反爬会损害用户体验的。
有意思的事情:
许多大的互联网公司,会同时有爬虫部门和反爬虫部门。哈哈哈,是这样的,爬虫部门用来爬别人家的数据, 反爬部门用来屏蔽别人家的爬虫咯! 举个例子,就像之前的58和赶集(不过现在他们合并了)
有意思的项目:
一步采集 通过算法,计算出一个网页中列表、分页地址。类似于 正文识别 算法。
这个技术对于需要做大量垂直爬虫的人来说,就很有用图。不用再编写XPath、正则表达式。
转自:https://www.cnblogs.com/pspider/p/7040681.html
以上是关于什么叫拇指规则的主要内容,如果未能解决你的问题,请参考以下文章