Netty使用
Posted MatrixLog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Netty使用相关的知识,希望对你有一定的参考价值。
1. 简介
Netty是一个NIO框架,能帮助开发者方便快捷的开发网络应用。先上一个官方的整体框架图感受下(虽然并没啥用):
与Java NIO相比(也比较官方):
Java NIO
<1> NIO的类库和API繁杂,使用麻烦;
<2> 需要具备其他的技能做铺垫,如Java多线程编程,NIO编程涉及到Reactor模式,必须对多线程和网路编程非常熟悉,才能编写出高质量的NIO程序;
<3> 可靠性,如断连重连,网络闪断、半包读取、失败缓存、网络拥塞、异常码流等等,完成功能编写可能很容易,但可靠性补齐则难度较大;
<4> JDK NIO bug重重。
Netty:
<1> API使用简单,开发门槛低;
<2> 功能强大,预置了多种编码功能,支持多种主流协议;
<3> 定制能力强,可以通过ChannelHandler对通信框架进行灵活地扩展;
<4> 性能高,通过与其他业界主流的NIO框架对比;
<5> 成熟、稳定、社区活跃;
2. 实现原理(Netty4)
让我们从一个简单的Netty Proxy Server开始。(示例代码在同性交友网站,jjmatrix/CommonProxy)
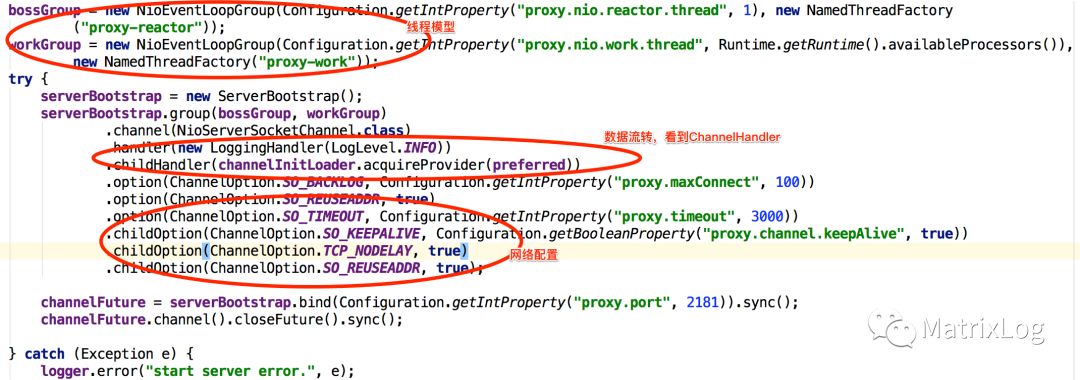
上面这段简单的代码基本包含了Netty几个核心部分:
高效的线程模型
IO数据流转(Pipeline)
编解码(ByteBuf,状态信息保存)
网络配置(backlog,timeout等)
2.1 高效线程模型
先来看看传统的四种IO模型,或者应该说是三种。
<1> 同步堵塞:最简单的一种IO模型,用户线程发起IO操作之后堵塞等待数据,待内核数据包准备好之后用户线程便可继续执行。
<2>同步非堵塞:在同步堵塞IO中将socket设置为NONBLOCK,这样用户线程在发起IO操作之后可以立即返回,不过得通过轮询来确定请求数据是否准备好。
<3> IO多路复用:由操作系统提供一种机制,通过它监视IO句柄的就绪状态,之后通知程序进行处理。又可细分为Reactor和Proactor两种模式。
Reactor模式基于同步I/O,典型的实现有select,poll,epoll(Linux环境中jdk的SelectorProvider会选择epoll,其它操作系统有其它对应的实现,如Mac用KQueue等等)。Reactor模式中,epoll等系统调用不负责IO操作,只负责告诉你当前IO句柄的就绪状态(可读、可写),并且将数据填充到读写缓冲区,读写控制由用户负责。
Proactor模式则基于异步I/O,典型实现有微软的IOCP。在Proactor中,由操作系统直接负责I/O读写操作,完成以后通过回调通知用户,这样带来的缺点是我们无法控制I/O通道,假如发生堵塞等都无能为力。
最传统的BIO线程模型
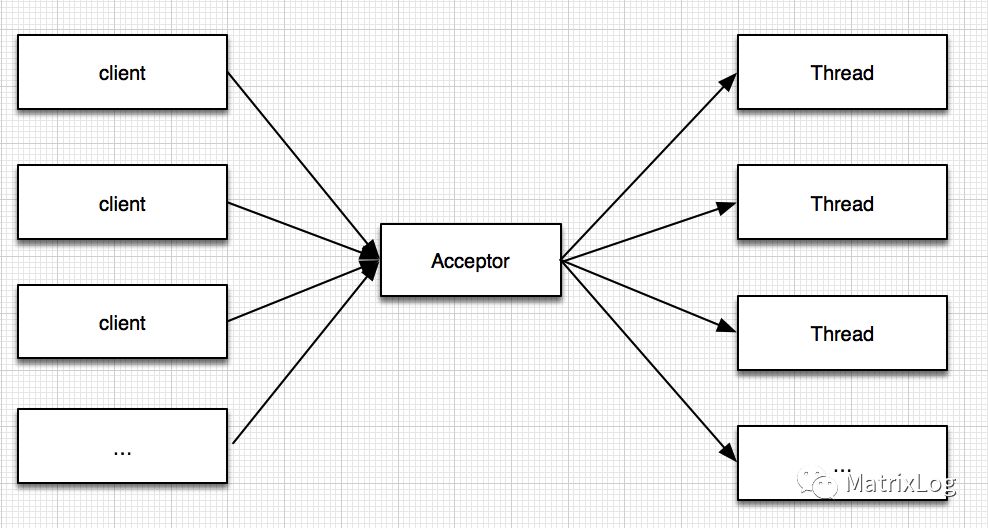
这种线程模型对于每个连接请求需要一个单独的线程来处理,因此完全无法应对高并发的场景。如果无限制的启动线程来处理并发请求,则系统资源将很快被耗尽,并且大量线程导致CPU都消耗在无用的线程switch中。
为了限制线程的增长,演变出了改进的BIO线程模型,如采用BIO的tomcat线程模型:
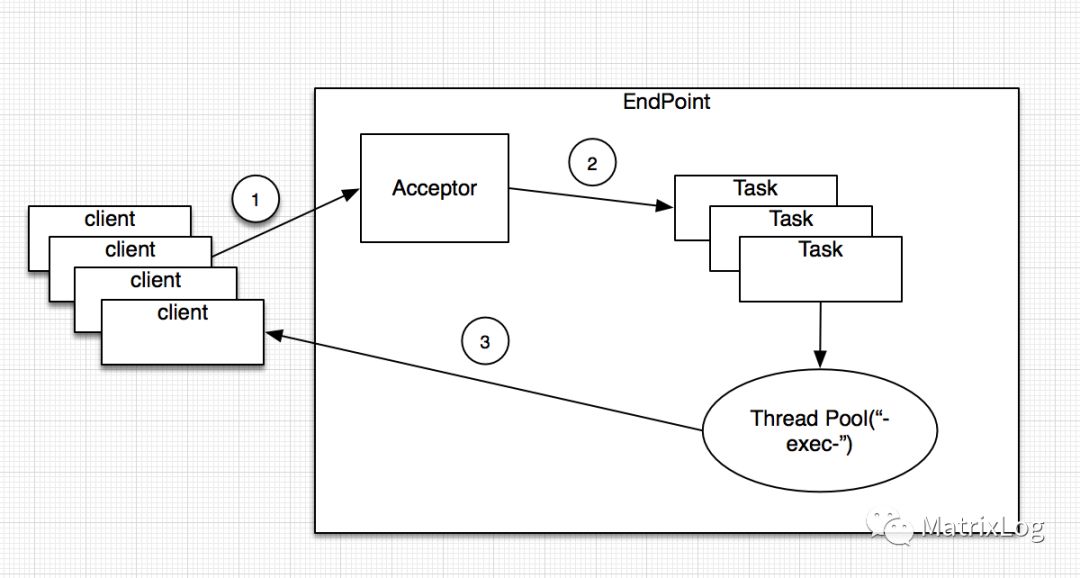
采用线程池的方式很好的限制了资源的消耗问题,但解决不了根本问题,每个client需要分配一个thread,限制了线程池的大小也就限制了Server的处理能力,Server无法承载更多的请求。
NIO的提出则很好的解决了这个问题。NIO采用的是Reactor模式,根据处理I/O操作的NIO线程的数量来区分。
Reactor单线程模型、
多线程模型
主从Reactor线程模型。
单线程模型
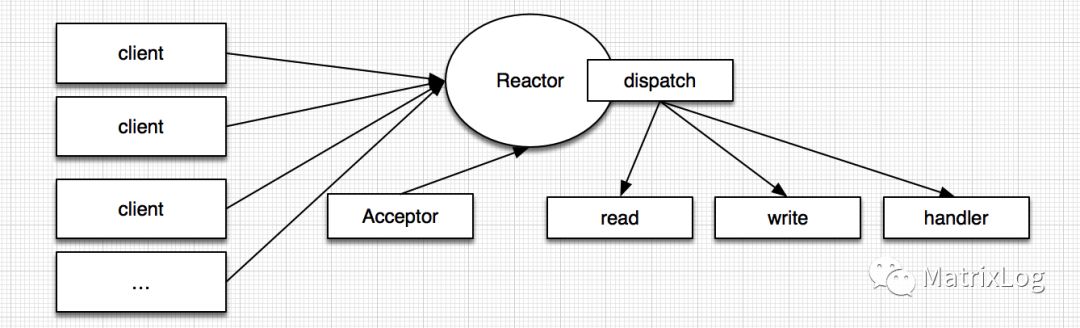
因为Reactor模式采用的是异步非阻塞I/O,所有的I/O操作都不会堵塞,因此可以使用单线程处理所有相关的I/O操作,如accept请求、数据读取,请求dispatch等。这种模型只适合小应用,在高并发应用中则不合适。一个NIO线程无法同时处理上千的链路,如果NIO线程过载,导致大量的消息积压和处理超时,则会成为系统的瓶颈。
多线程模型
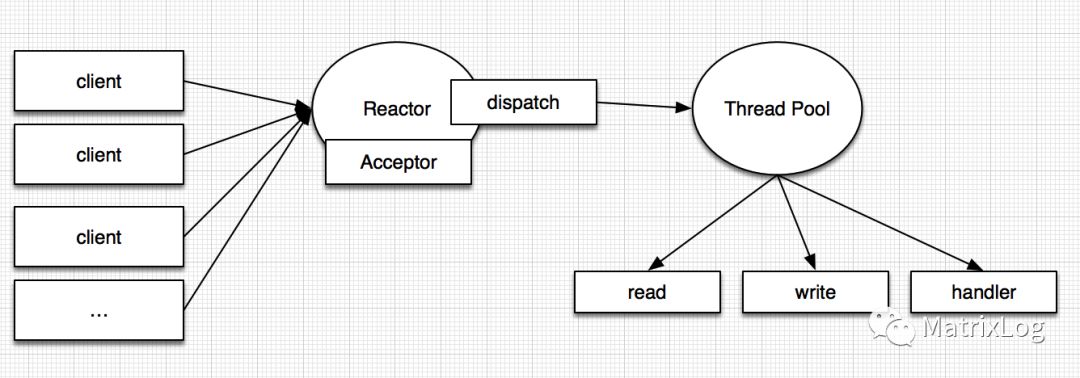
多线程模型区别于单线程模型的地方,在于增加一个Thread Pool用于处理网络IO操作,负责读取、编解码、发送。而Acceptor线程只负责监听服务端,处理Client链路。多数场景下,Reactor多线程模型可以满足性能需求。个别场景,如需承载百万并发、增加SSL验证等(认证本身非常损耗系能),在这类场景中,采用单个线程处理client链路无法满足要求。
主从Reactor多线程模型,也即Netty典型采用的模型
Netty的线程模型比较比较灵活,根据不同的配置,也即组合boss与work的NioEventLoopGroup即可采用上述三种模型,如:
bossGroup = new NioEventLoopGroup(Configuration.getIntProperty("proxy.nio.reactor.thread", 1), new NamedThreadFactory ("proxy-reactor")); workGroup = new NioEventLoopGroup(Configuration.getIntProperty("proxy.nio.work.thread", Runtime.getRuntime().availableProcessors()), new NamedThreadFactory("proxy-work")); |
<1> 将bossGroup==workGroup,不开启单独的线程池处理IO操作,则是单线程模型;
<2> 将bossGroup==workGroup,开启单独的线程池处理IO操作,在ChannelHandler中将请求dispatch到线程池;
<3> 如示例代码,bossGroup!=workGroup,则是主从Reactor模型,这也是Netty推荐采用的线程模型,如:
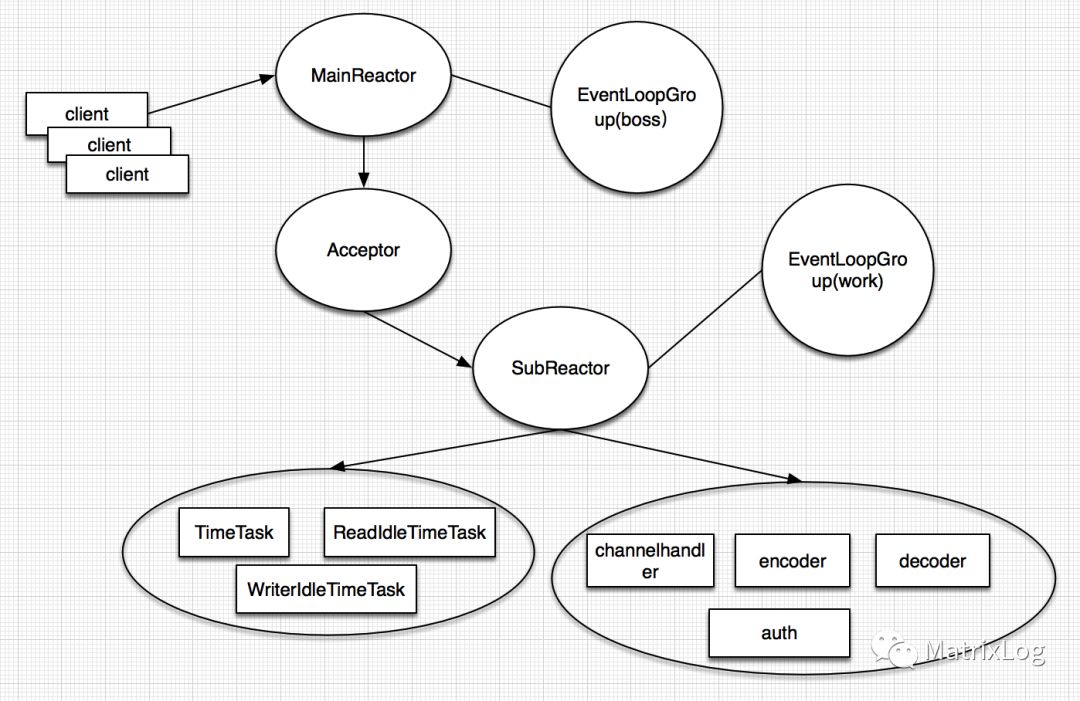
boss与work线程的职责为:
boss:请求accept
work:链路读写,验证验证,定时任务(如处理连接超时,由于nio采用非堵塞,不同通过直接设置socket timeout的方式)
这便是Netty采用的主从Reactor模型,Server端不再使用一个单独的NIO线程处理所有链路,而是采用独立的NIO线程池。MainReactor,也即boss线程负责accept连接,之后注册到SubReactor,也即work nio线程池。
另外,Netty将channel的读写均放在一个NIO线程中完成,这样可以避免线程切换带来的开销,同时也可避免多线程的同步问题。当然这要建立在你的业务处理逻辑比较简单,不涉及其它需要等待的网络IO,比如数据库读写等操作的前提下,否则你应该启独立的应用线程池去处理耗时的业务逻辑,以避免堵塞IO线程。(可以通过测试对比使用业务线程池与不使用业务线程池的性能情况)
如果深入到类层次,则Channel的处理过程如:
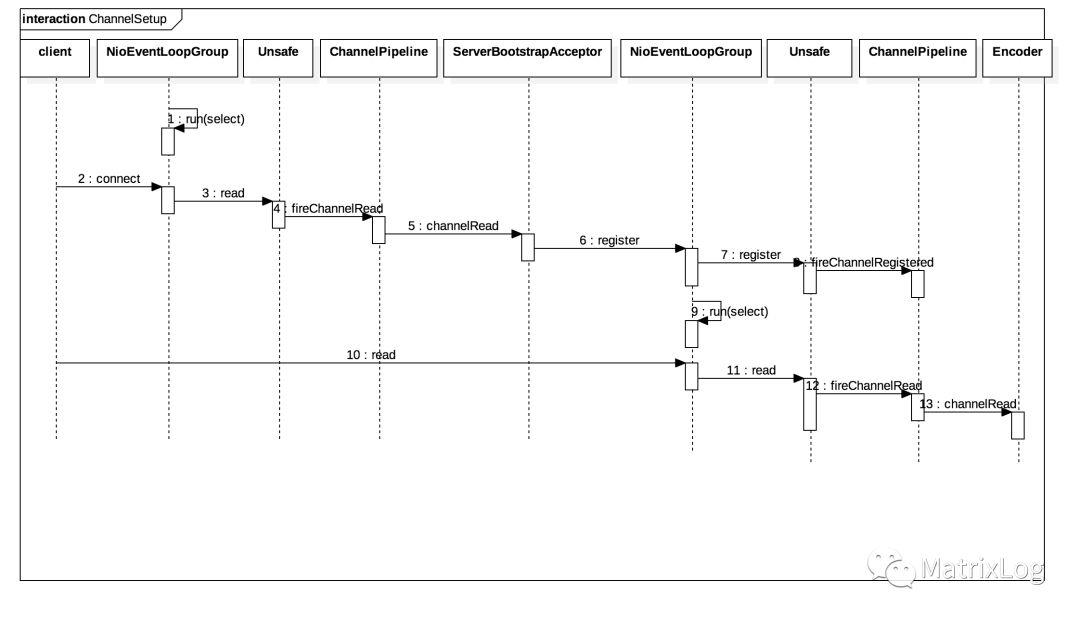
<1> 在Server启动以后,boss线程会循环检测就绪SelectorKey来accept client请求;
<2> client发起连接请求,boss线程accept请求后,通过Unsafe触发read操作;
<3> 之后read请求在pipeline中流转,由处于末端的ServerBootstrapAcceptor将建立链路的NiosocketChannel注册到work线程;
<4> 之后便由work线程来处理channel上的链路操作;
2.2 IO数据流转
前面分析Netty的线程模型时提过,Netty的IO读写操作均在一个work线程中完成。work线程会循环检测channel就绪状态,当发生IO事件,触发相应的事件,经ChannelPipeline完成整个ChannelHandler链条的处理。ChannelPipeline是ChannelHandler的容器,负责每个Channel关联的ChannelHandler的管理、事件处理与调度。
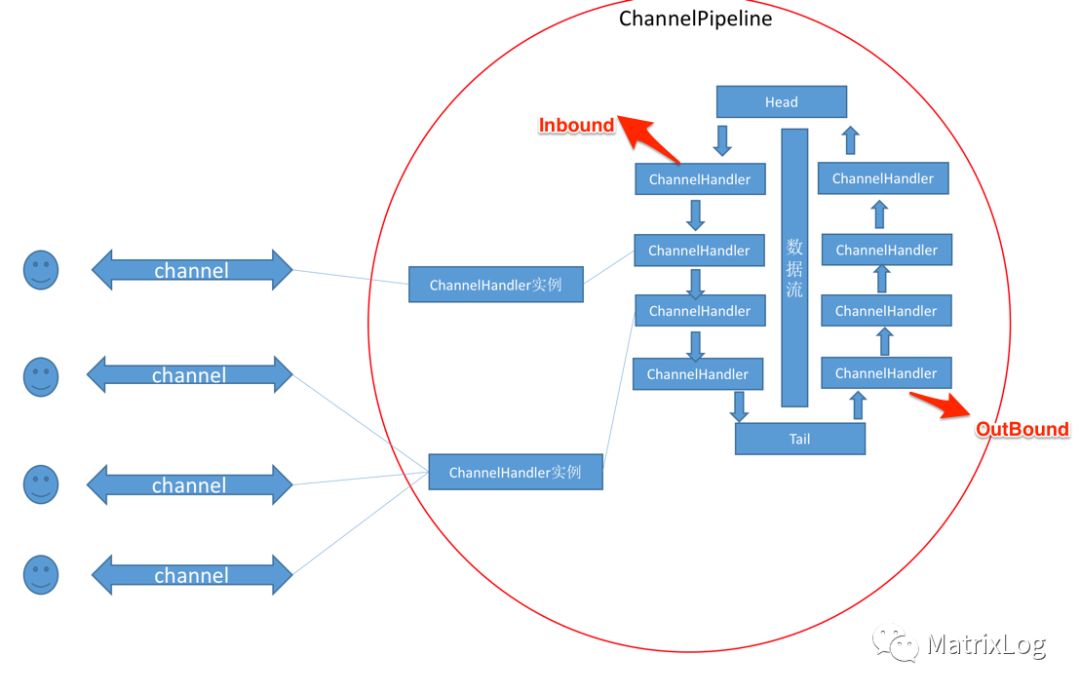
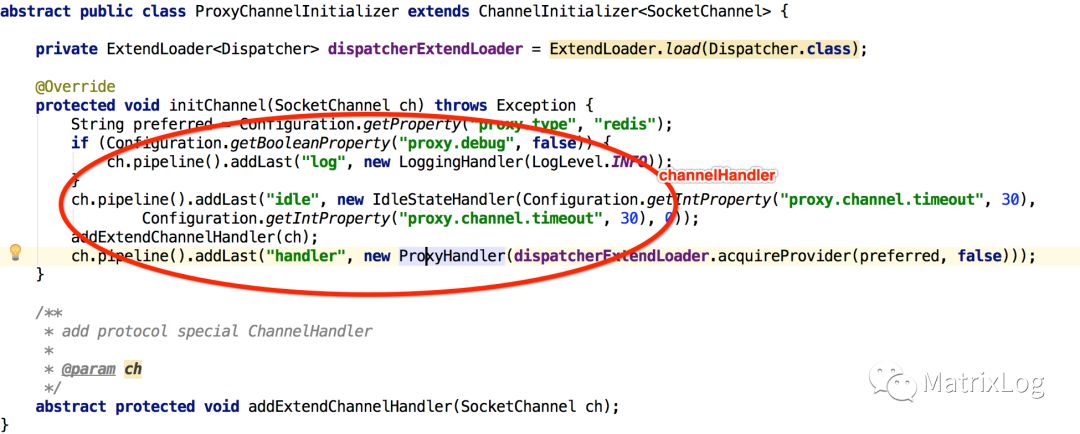
ChannelHandler由ChannelPipeline维护,由我们的创建Netty应用的时候指定,并可以动态改变。如前面Netty Proxy Server的例子:
if (Configuration.getBooleanProperty("proxy.debug", false)) { ch.pipeline().addLast("log", new LoggingHandler(LogLevel.INFO)); } ch.pipeline().addLast("idle", new IdleStateHandler(Configuration.getIntProperty("proxy.channel.timeout", 30), Configuration.getIntProperty("proxy.channel.timeout", 30), 0)); addExtendChannelHandler(ch); ch.pipeline().addLast("handler", new ProxyHandler(dispatcherExtendLoader.acquireProvider(preferred, false))); |
ChannelPipeline会根据添加的顺序将这些做不同事情(如编码、解码、超时处理等等)的ChannelHandler串成链条,并加入Head与Tail两个HandlerContext。当然,由于IO数据流是有Inbound与OutBound两个方向的,ChannelPipeline需要在read/write时区分对待。
举个栗子,用Netty做Redis Proxy服务,整个处理流程如:
<1> client发起get请求;
<2> ChannelPipeline通过Head的fireChannelRead触发Inbound流程;
<3> 负责解码的ChannelHandler解析redis协议;
<4> 根据redis请求,通过writeAndFlush返回结果;
<3> ChannelPipeline通过Tail触发OutBound流程;
2.3 状态信息保存
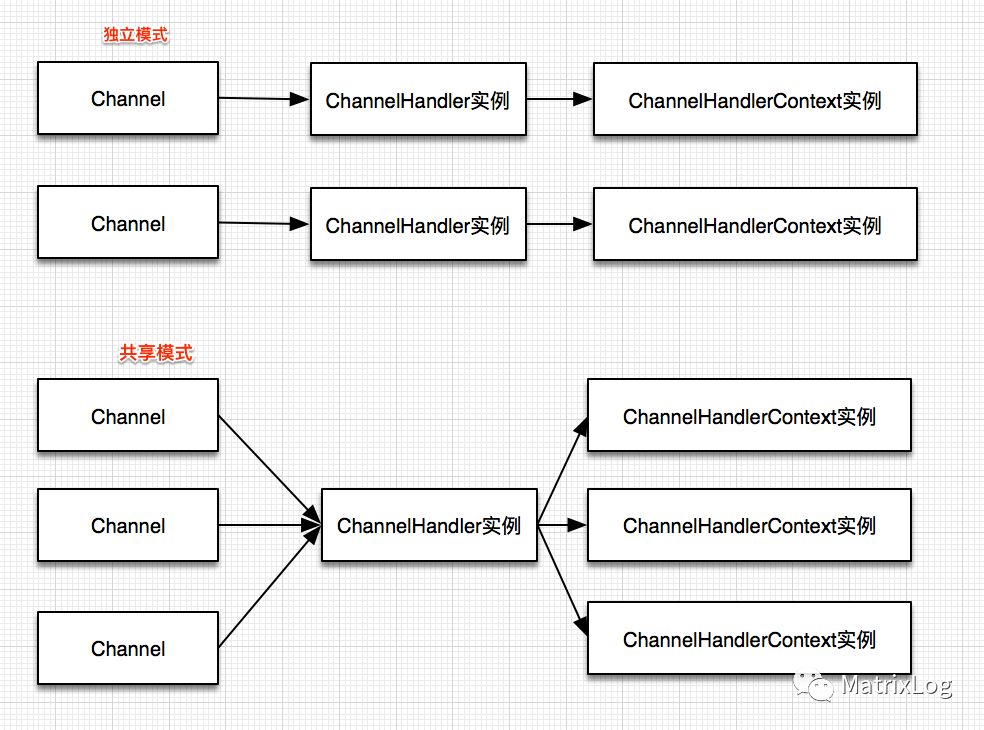
ChannelHandler有两种配置方式,一种是每次new新的实例,一种是采用共享的方式。我们知道ChannelHandler链条是关联到Channel的,因此除非必要,均采用new新实例的方式,如:
ch.pipeline().addLast("handler", new ProxyHandler(dispatcherExtendLoader.acquireProvider(preferred, false))); |
采用这样的方式,每个Channel(也即每个链接)均有一个独立的ChannelHandler,这样便可以在ChannelHandler中采用成员变量来保存状态信息,而不会有线程同步问题。
当然,如果你理由充足(多new一个ChannelHandler要命),也可以采用共享ChannelHandler的方式。这个时候,如果要保存状态信息需要采用ChannelHandlerContext,通过AttributeKey。ChannelHandlerContext是Netty提供的上下文对象,通过它可以动态修改pipeline,在inbound,outbound,甚至其它线程中传递,用于触发事件等。在共享模式中,ChannelHandlerContext之所以可以保存状态信息,是因为尽管ChannelHandler可以在Channel中共享,但是ChannelHandlerContext却不是,也即一个ChannelHandler可以有多个ChannelHandlerContext。
综上所述,结合2.2的数据流转图,可梳理这几个核心实例的对应关系如:
2.4 ByteBuf
ByteBuf是对Netty对Java NIO中ByteBuffer的扩展,相比较ByteBuffer。
它提供了更友好的API。
内存池技术
引用计数
Java NIO的ByteBuffer提供四个position指针,如:
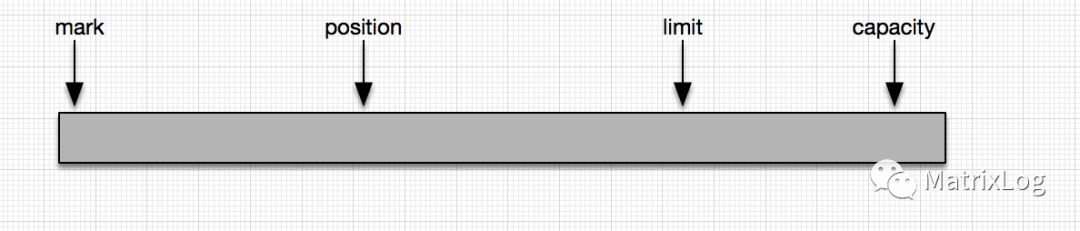
只有一个position指针标记读写的位置,在进行读写操作时要通过对应的接口调整好各个指针的位置,比如在写入完成以后如果要读取数据,需要调用flip调整position,mark,limit的指向。
而ByteBuf提供了独立的读写指针readerIndex与writerIndex,操作上更方便。
ByteBuf类型:
<1> 从内存在哪里分配看,分HeapByteBuf、DirectByteBuf以及组合两者的CompositeByteBuf;
严格来说应该是两种,Heap与Direct内存,CompositeByteBuf是前面两种类型的组合。在网络IO中,Direct内存有其天然的优势,Direct是直接操作内存区域,相比heap可以减少内存的拷贝动作。因此,默认情况下,只要系统支持,Netty采用的是Direct方式。
<2> 从是否使用内存池看,分Pooled与Unpooled;
我们可以使用不同的组合(配置参数见附录1)来测试ByteBuf的性能,如:
(指标包括gc与响应) |
pooled |
unpooled |
direct |
||
heap |
从理论上看,direct相比heap而言无论是性能还是gc应该都有提升(待验证,特别是GC方面,需要调整JVM参数来排除干扰)。而如果均采用direct的情况下,采用pooled的方式,则性能更好,因为direct方式下,频繁创建销毁direct内存开销较大(实验确实如此)。
引用计数:
从Netty4开始,Netty开始通过引用计数来管理ByteBuf对象的生命周期,当引用计数为0的时候则将对象返回给对象池或者直接释放。
谁负责释放对象?
第一原则是谁最后使用谁负责释放(通过ByteBuf的release或借助ReferenceCountUtil)。如果是在Inbound,则由ChannelHandler负责释放ByteBuf对象。在Outbound中则不同,ByteBuf最终应该由Netty负责释放,除非是你创建的临时ByteBuf对象。
另外,Netty也提供了内存泄漏的检测功能,通过配置参数-Dio.netty.leakDetectionLevel,可选配置参数有:
disabled:禁用检测
simple(默认):提示是否存在内存泄漏
advanced:提示那里存在泄漏
paranoid:提示那里存在泄漏,不过比前面的检测标准更严格,只要有一个buffer泄漏都不行。
2.5 编解码
当了解了IO数据流转,状态信息保存及ByteBuf的应用以后,实现协议的编码与解码就简单了。只需要记住一点,由于TCP是分段发送的,你不一定能一次性读到你想要的数据,因此在读数据之前要先判断ByteBuf中的数据是否准备好(长度符合?已有分隔符?)。
当然你可以借助Netty提供的一些现有的编解码工具类快速完成这些工作,如:
DelimiterBasedFrameDecoder(直接可用) |
如果你的协议是根据某个delimiter分隔。 |
FixedLengthFrameDecoder(直接可用) |
如果协议是长度固定。 |
ReplayingDecoder(辅助,用需要注意一些问题) |
提供简单的支持,让你可以放心大胆的读ByteBuf,而无需担心数据是否准备好。 |
2.6 网络配置
这个涉及的内容较多,需要通过TCP/IP协议三件套,Unix网络编程两件套来深入了解。
3. 参考资料
Netty Doc:http://netty.io/wiki/index.html,官方资料,想要的都有。
书籍:Netty in Action,TCP/IP协议三件套,Unix网络编程两件套。
以上是关于Netty使用的主要内容,如果未能解决你的问题,请参考以下文章